第五周作業進展報告
基于內容感知的視頻編解碼技術
基于內容感知的視頻編解碼技術的目的是降低視頻傳輸成本,節省帶寬,視頻內容特性是指其各個幀影像中的紋理特性和物體或者區域的運動特性,如圖1所示,影像的紋理特性與它的內容細節相關,例如:色彩豐富度、物體邊界銳利程度,物體形狀大小等,如圖2所示,物體運動特性與視頻內容的變化程度相關,例如:物體運動的快慢,物體運動的方向,前后幀內容變化或者場景切換的劇烈程度等,

圖1 影像的紋理特性

圖2 物體的運動特性
而目前在內容感知方面有兩種比較經典的解決方案,一個是顯著性圖預測,如圖3所示,它是利用人類視覺系統在面對所獲取的完整資訊中,只將注視焦點放在場景中關鍵的特定目標上,而顯著性圖是在影像中找到“引人注目”的內容,我們可以利用顯著性圖,提取視覺重點,讓視頻編碼器具有編碼權重分配的依據,

圖3 顯著性圖
在“基于深度神經網路的影像顯著性檢測”一文中,作者提出了顯著性圖預測網路,實驗使用到的資料集是開源的顯著性檢測資料集SALICOM、iSUN,如圖4所示,網路分成區域模塊和全域模塊,全域模塊的輸入影像是96x96x3的RGB影像,全域模塊使用的是3層卷積層做特征提取,區域模塊的輸入影像是96x96的灰度圖,使用預訓練的VGG-16模型的前5層卷積層嵌入到CNN網路中,CNN網路中包含了一個STN模塊和兩個卷積層,網路最后一個模塊是獲取兩種互補資訊之間的最佳組合值,包含一個拼接層(concat)、一個激活函式層(maxout)和一個全連接層(FC),最后輸出顯著性圖,
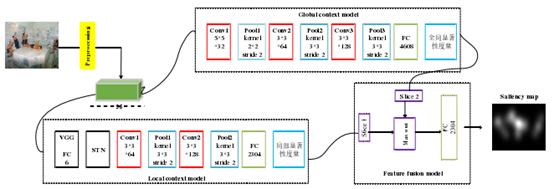
圖4 顯著性圖預測網路模型
而另一種解決內容感知問題的方法是語意分割,語意分割是在像素級別上的分類,屬于同一類的像素被歸為一類,如圖5所示,屬于人的像素被分為一類,屬于摩托車的像素被分為一類,我們同樣可以可利用語意分割,提取視覺重點,讓視頻編碼器具有編碼權重分配的依據,

圖 5 語意分割
在“Context-aware encoding for clothing parsing”一文中,提出了一個基于彩色時裝決議的語意分割模型,主干網路使用的是FCN模型和MobilelNet模型,經過預測、上采樣以及一個softmax激活函式,并在網路的邊分支建立一個輕量級的COE架構,用于提高特征提取能力和減少過擬合,網路最后輸出的是人和彩色時裝的語意分割圖,
對于視頻編解碼部分,在“面向動態自適應流視頻傳輸的碼率控制演算法研究”一文中,提出X264碼率控制的三種模式,分別是CBR(constant rate factor):固定碼率,輸出碼率是一個固定值,VBR(variable bit rate):可變位元率,簡單部分用低位元率編碼,復雜部分用高位元率編碼,但輸出碼流大小不可控,ABR(average bit rate):平均位元率,同樣可以動態調整位元率,而且一定時間內,平均碼率趨近于目標碼率,可以控制輸出檔案大小,我們可以將上述方法所獲得的人眼關注的影像部分結合ABR碼率控制演算法達到節省帶寬的目的,
總結:不足的地方:①缺少視頻評判標準②高速運動目標檢測(鏡頭高速運動會出現運動模糊,可適當降低碼率③目前找到的方法是基于影像而非視頻,針對視頻方面的方法還要考慮幀率等因素,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/190002.html
標籤:其他