Hadoop集群部署
- 前言
- 一、虛擬環境安裝配置
- 二、虛擬機中的網路配置
- 步驟一:本地網路配置查看
- 步驟二:設定虛擬機網路環境
- 三、Hadoop偽分布環境安裝與配置
- 任務1:Java JDK-8u181版本下載與安裝
- 任務2:Java JDK-8u181版本環境變數配置
- 任務3:Hadoop-2.10.0版本下載與安裝
- 任務4:Hadoop-2.10.0版本環境變數配置
- 任務5:Hadoop-2.10.0版本核心組態檔配置
- 任務6:格式化DFS分布式檔案系統
- 任務7:啟動hadoop-2.10.0服務
- 任務8:Hadoop HDFS檔案系統操作
- 四、使用Ambria安裝部署Hadoop集群
- 總結
前言
實驗背景:校園社區網站資料分析平臺,
本專案,我們將由淺入深,從虛擬環境下Linux作業系統安裝配置開始,逐步學習大資料分析平臺的集群部署,
一、虛擬環境安裝配置
(1)安裝Xshell和Xftp, Xshell的版本:Xshell-6.0.0189p,Xftp的版本:Xftp-6.0.0185p,
此軟體的安裝程序請看博客:安裝Xshell和Xftp
(2)安裝虛擬機及centos作業系統 VM的版本:VMware 15.5.0,光碟映像檔案版本:CentOS-7-x86_64-DVD-1611
此軟體的安裝程序請看博客:安裝虛擬機及centos作業系統
(3)jdk-8u181-linux-x64.tar以及hadoop-2.10.0.tar兩個壓縮檔案
二、虛擬機中的網路配置
步驟一:本地網路配置查看
記錄下本地的: (1)MAC地址 (2)IP地址 (3)子網掩碼 (4)默認網關
Win+R 打開運行視窗輸入cmd
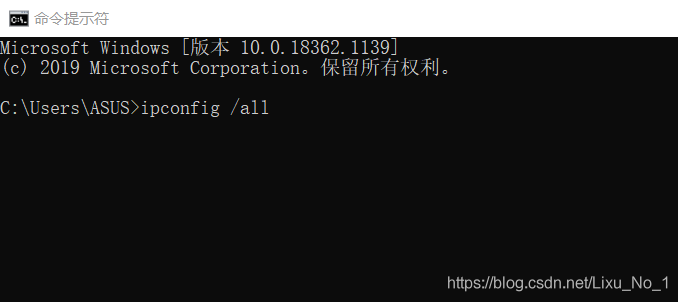
輸入ipconfig /all 即可查看所有網路,找到所連接的網路即可
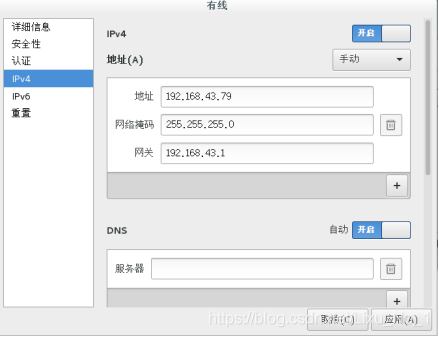
步驟二:設定虛擬機網路環境
這邊是我的配置:
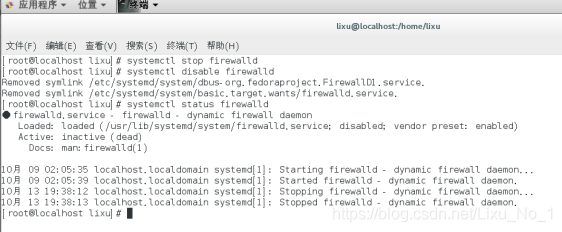
(1)關閉防火墻
[root@localhost lixu]# systemctl stop firewalld //停止firewalld防火墻
[root@localhost lixu]# systemctl disable firewalld //disable防火墻
[root@localhost lixu]# systemctl status firewalld //查看firewalld是否已經關閉
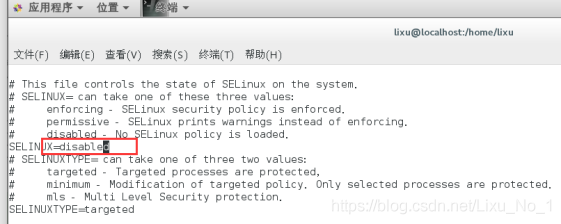
(2)進入到selinux檔案中將enable的修改成disabled
vi /etc/sysconfig/selinux
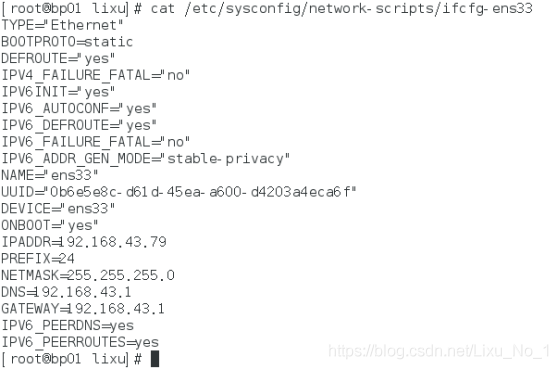
(3)配置并查看網卡檔案
BOOTPROTO="static" //將DHCP改為static
IPADDR=192.168.43.79 //根據自己的當前局域網進行設定
NETMASK=255.255.255.0 //根據自己的當前局域網進行設定
DNS=192.168.43.1 //根據自己的當前局域網進行設定
GATEWAY=192.168.43.1 //根據自己的當前局域網進行設定
(4)設定主機名
hostnamectl set-hostname bp01
hostname

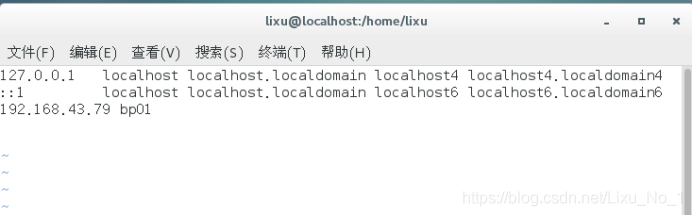
(5)設定主機名與IP地址映射
vi /etc/hosts
(6)重啟網路服務
service network restart
(7)Xshell連接到虛擬機:
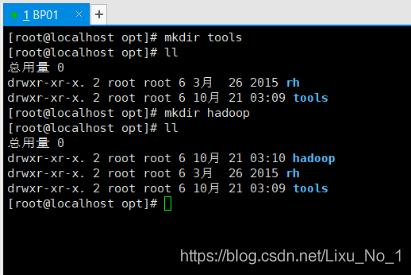
a:xshell登錄79主機
b:創建/opt/tools目錄
cd /opt
mkdir tools
c:創建/opt/hadoop目錄
cd /opt
mkdir hadoop
三、Hadoop偽分布環境安裝與配置
任務1:Java JDK-8u181版本下載與安裝
1、Java JDK-8u171版本下載地址
Java JDK-8u181下載,自行選擇需要安裝的版本,選擇其它的也可以,將Java JDK-8u181安裝包放到/opt/tools目錄下
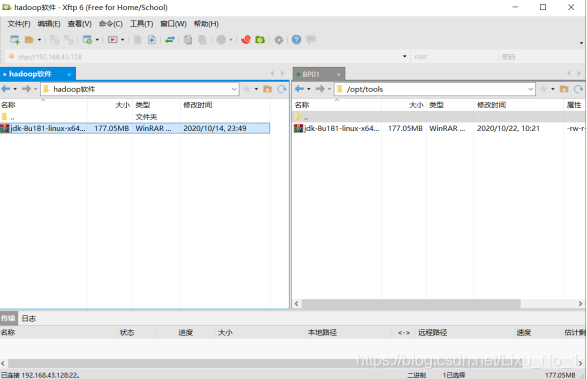
任務2:Java JDK-8u181版本環境變數配置
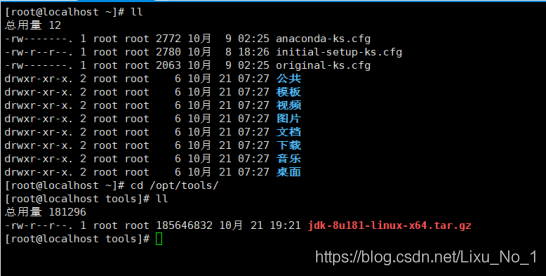
1、創建/opt/hadoop/java目錄
su root
cd /opt/hadoop
mkdir java
2、復制安裝介質
cp /opt/tools/jdk-8u181-linux-x64.tar.gz /opt/hadoop/java/

3、檔案解壓縮
tar -xvf /opt/hadoop/java/jdk-8u181-linux-x64.tar.gz
4.配置Java環境變數
su root
vi /etc/profile
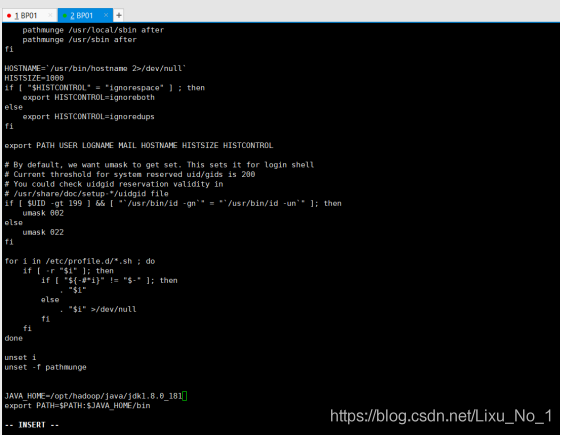
profile檔案中加入以下兩條
JAVA_HOME=/opt/hadoop/java/jdk1.8.0_181 //根據自己的環境設定
export PATH=$PATH:$JAVA_HOME/bin //統一必須怎么寫
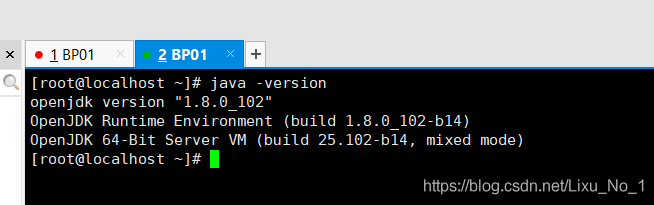
5. 驗證JAVA環境
su root
java -version
任務3:Hadoop-2.10.0版本下載與安裝
Hadoop-2.10.0下載地址
1、Hadoop-210.0版本解壓縮
su root
cd /opt/tools/
cp hadoop-2.10.0.tar.gz /opt/hadoop/
cd /opt/hadoop/
tar -xvf hadoop-2.10.0.tar.gz
任務4:Hadoop-2.10.0版本環境變數配置
1.配置Hadoop環境變數
vi /etc/profile
source /etc/profile
profile檔案中輸入以下兩句既可
HADOOP_HOME=/opt/hadoop/hadoop-2.10.0//根據自己實際的情況進行配置
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
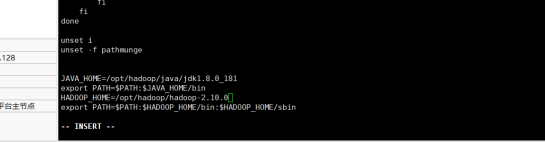
接下來開始配置Hdoop的核心組態檔
hadoop.env.sh
core-site.xml
hdfs-site.xml
mapped-site.xml
yarn-site.xml
任務5:Hadoop-2.10.0版本核心組態檔配置
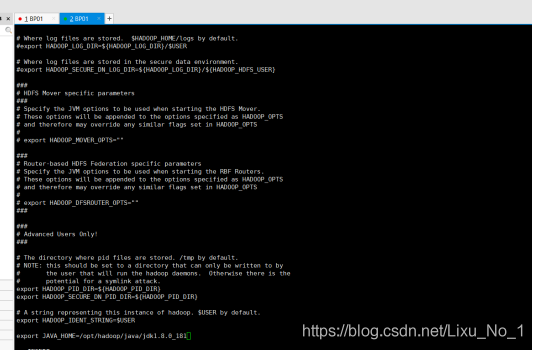
(1)hadoop.env.sh
說明:該檔案為Hadoop的運行環境組態檔,Hadoop的運行需要依賴JDK,我們將其中的export JAVA_HOME的值修改為我們安裝的JDK路徑
cd /opt/hadoop/hadoop-2.10.0/etc/hadoop
vi hadoop-env.sh
hadoop-env.sh檔案中輸入以下即可:
export JAVA_HOME=/opt/hadoop/java/jdk1.8.0_181
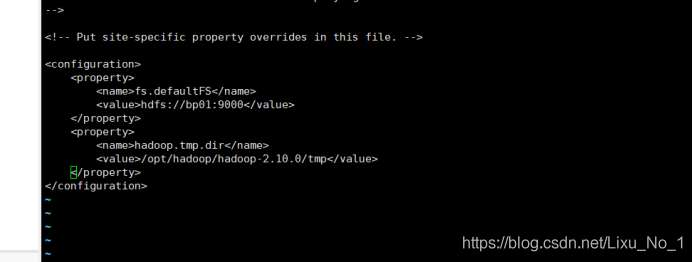
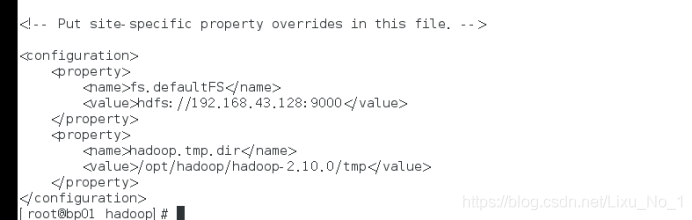
(2)core-site.xml【Hadoop的核心組態檔】
cd /opt/hadoop/hadoop-2.10.0/etc/hadoop
vi core-site.xml
core-site.xml檔案中輸入以下即可:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bp01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.10.0/tmp</value>
</property>
</configuration>
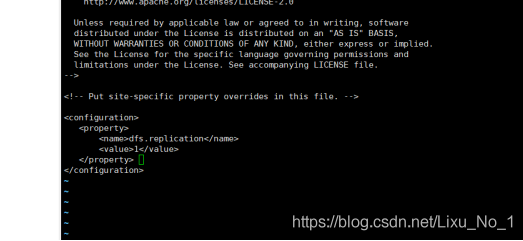
(3)hdfs-site.xml【HDFS核心組態檔】
cd /opt/hadoop/hadoop-2.10.0/etc/hadoop
vi hdfs-site.xml
hdfs-site.xml檔案中輸入以下即可:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
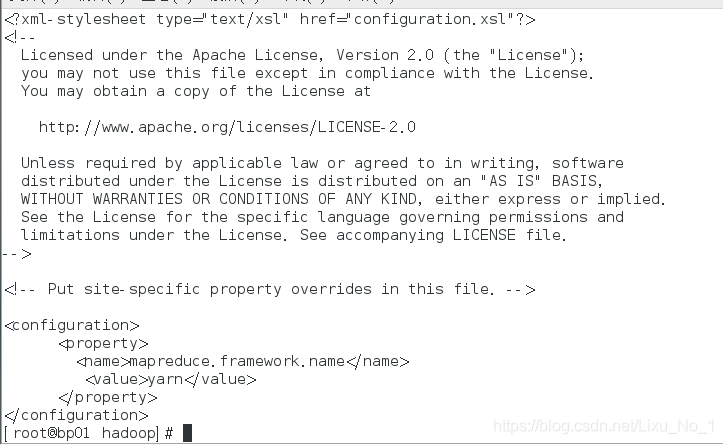
(4)mapred-site.xml
cd /opt/hadoop/hadoop-2.10.0/etc/hadoop
vi mapred-site.xml
mapred-site.xml檔案中輸入以下即可:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
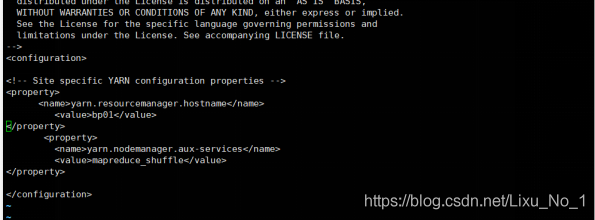
(5)yarn-site.xml【Yarn框架組態檔】
cd /opt/hadoop/hadoop-2.10.0/etc/hadoop
vi yarn-site.xml
yarn-site.xml檔案中輸入以下即可:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bp01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
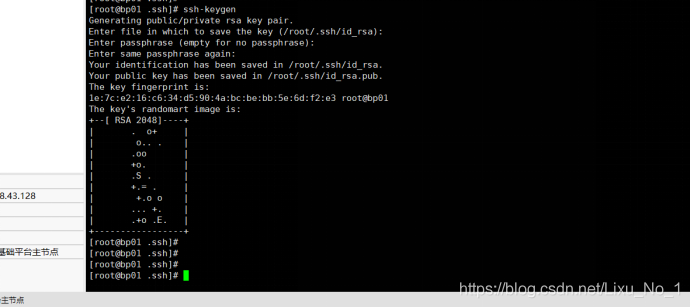
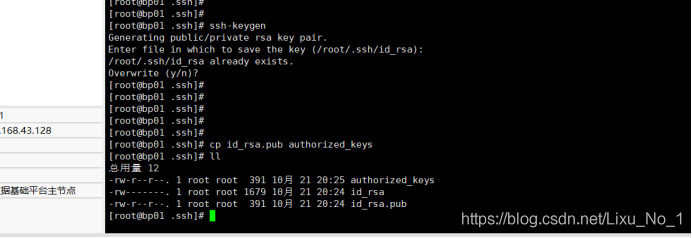
(6)配置SSH免密碼登錄
1)進入hadoop目錄下的.ssh目錄
2)運行ssh-keygen,根據本機密鑰,產生訪問本機的公鑰
3)運行cp id_rsa.pub authorized_keys,
將本機公鑰添加到本機的可信串列中,沒有ssh目錄就新建一個
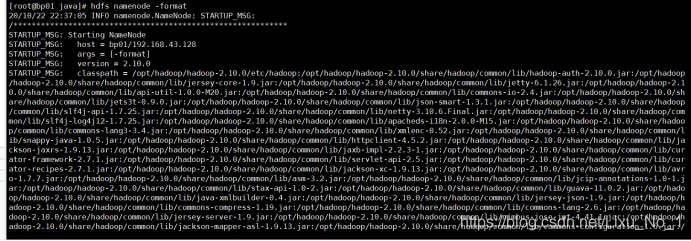
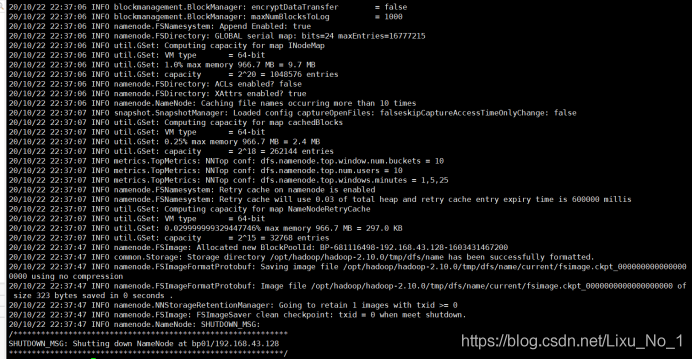
任務6:格式化DFS分布式檔案系統
hdfs namenode -format
如果在格式化的日志中看到succefully format字樣,就證明格式化成功,反之,失敗
任務7:啟動hadoop-2.10.0服務
啟動DFS及resourcemanager
cd /opt/hadoop/hadoop-2.10.0/sbin
vim start-dfs.sh
vim start-yarn.sh
start-dfs.sh頭部添加:
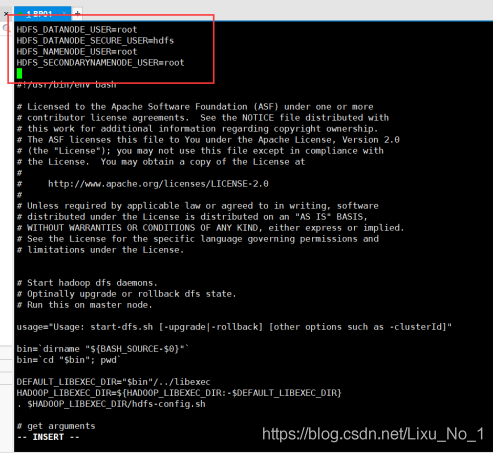
start-yarn.sh頭部添加:
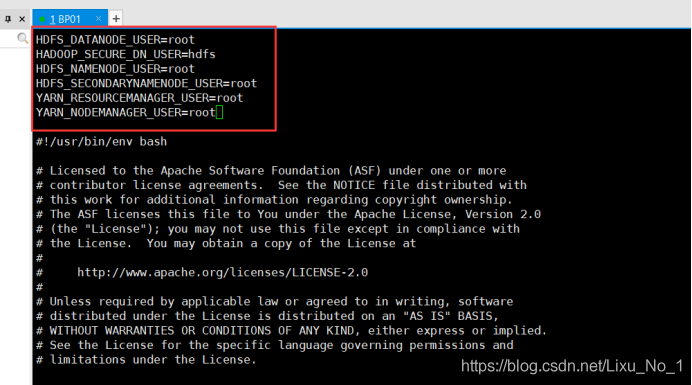
注意:這里重啟兩個組態檔出現了錯誤,在瀏覽器中輸入ip訪問不到網頁 于是在core-site.xml【Hadoop的核心組態檔】中將bp01改為192.168.43.128,因為在配置實驗的程序中網路發生了改變 所以這邊是192.168.43.128,操作:先輸入如下命令將兩個行程關閉,修改完成之后重啟


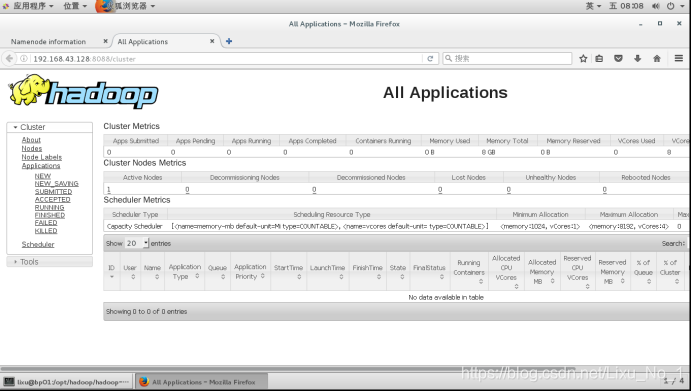
完成之后:MapReduce管理界面
http://192.168.43.128:8088
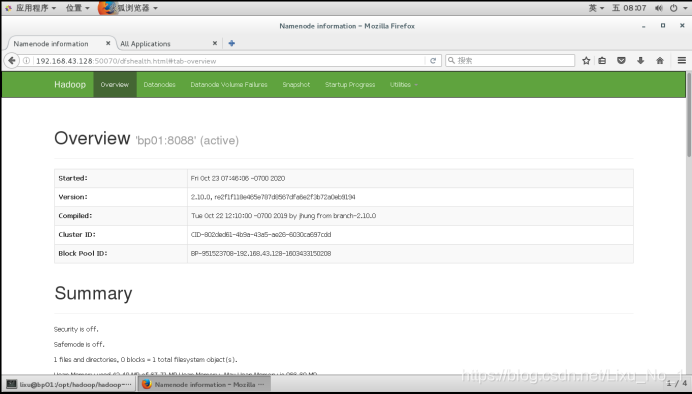
Hadoop管理界面
http://192.168.43.128:50070
任務8:Hadoop HDFS檔案系統操作
參考檔案地址:
Hadoop HDFS檔案系統Shell命令:檔案系統(FS)shell包括各種shell命令,這些命令直接與Hadoop分布式檔案系統(HDFS)以及Hadoop支持的其他檔案系統進行互動,例如本地FS、WebHDFS、S3fs等,
查看檔案系統幫助檔案
hadoop fs -help

1.查看檔案系統剩余空間
語法:hadoop fs -df [-h] URI [URI …]
-H選項將以“人類可讀”的方式格式化檔案大小(例如,64.0M而不是67108864),
查看整個檔案系統剩余空間
hadoop fs -df -h /

2.創建檔案目錄
語法:hadoop fs -mkdir [-p] --p選項行為類似于UNIX MKDIR -P,沿著路徑創建父目錄,
注意:是這個路徑
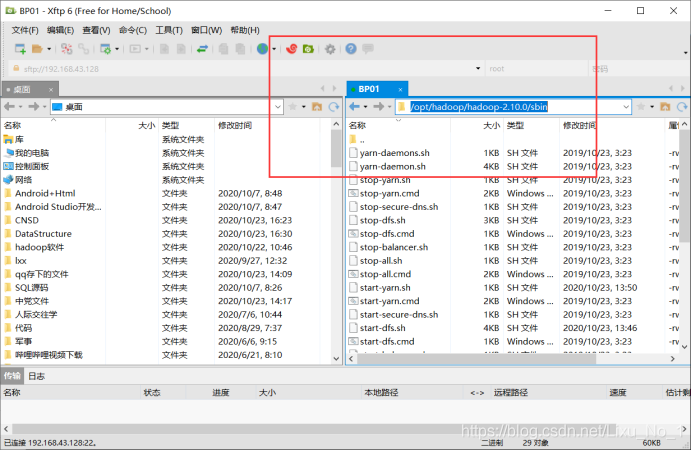

3.上傳航空FOC資料檔案
語法: hadoop fs -put [-f] [-p] [-l] [-d] [ - | … ].
-p:保存訪問和修改時間、所有權和權限,(假設權限可以跨檔案系統傳播)
-F:如果目標已經存在,則覆寫它,
-L:允許資料節點延遲保存到磁盤,強制復制因子為1,這個標志將導致耐久性降低,小心使用,
-D:用后綴跳過臨時檔案的創建,
創建/1824113/FOC子目錄

上傳T2020.csv檔案到/1824113/FOC目錄中
vi T2020.csv
hadoop fs -put T2020.csv /1824113/FOC

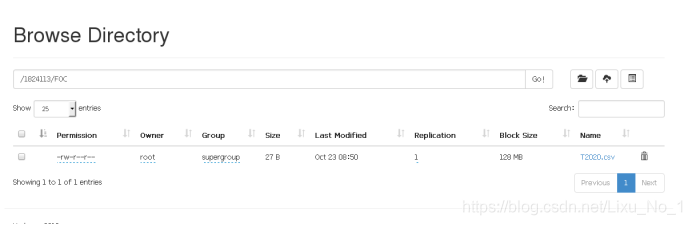
4.查找航空FOC資料檔案
語法: hadoop fs -find
hadoop fs -find / -name T2020.csv -print

5.下載航空FOC資料檔案
語法:hadoop fs -get [-ignorecrc] [-crc] [-p] [-f]
hadoop fs -get /T00/FOC/T2020.csv T2020.dat
將T2020.csv下載到本地命名為T2020.dat
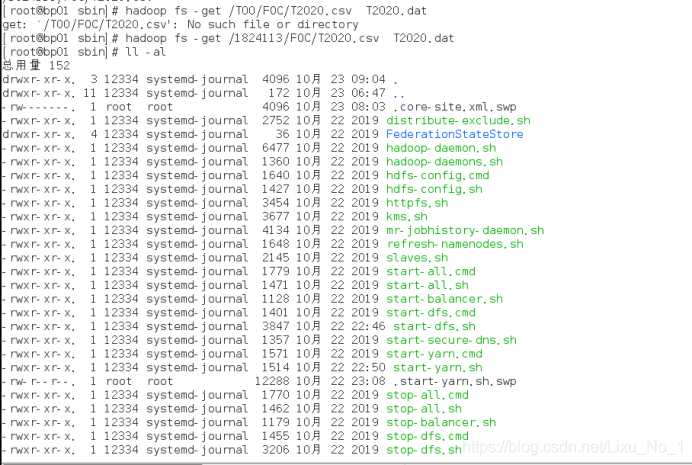
6.查看航空FOC資料檔案訪問權限
語法:hadoop fs -getfacl [-R]
hadoop fs -getfacl -R /
查看檔案系統根目錄下所有檔案及目錄的權限

7.查看航空FOC資料檔案大小
語法:hadoop fs -du [-s] [-h] [-v] [-x] URI [URI …]
-S選項將導致顯示檔案長度的匯總,而不是單個檔案,在沒有-S選項的情況下,計算是通過從給定路徑深入1級來完成的,
-H選項將以“人類可讀”的方式格式化檔案大小(例如,64.0M而不是67108864),
-V選項會將列的名稱顯示為標題行,
-x選項將排除結果計算中的快照,沒有-x選項(默認),結果總是從所有的iNoD中計算出來,包括給定路徑下的所有快照,

這邊是27位元組
8.航空FOC資料檔案拷貝
語法:hadoop fs -cp [-f] [-p | -p[topax]] URI [URI …]
-f選項將覆寫目的地,如果它已經存在,
-p選項將保存檔案屬性[Topx](時間戳、所有權、權限、ACL、XAttr),如果-p被指定為沒有ARG,則保留時間戳、所有權、權限,如果指定了-PA,則保留ACCEL也是因為ACL是一個超級權限集,是否保留原始命名空間擴展屬性的確定與-P標志無關,

9.驗證FOC資料檔案是否變更過
語法: hadoop fs -checksum URI
回傳檔案的checksum資訊

10.FOC資料檔案添加
語法: hadoop fs -appendToFile …
將本地的資料檔案添加【資料添加到檔案末尾】到HDFS檔案系統資料檔案中,可以同時將本地多個檔案添加到HDFS檔案中,
hadoop fs -appendToFile T2001.dat /T00/FOC/T2001.dat
hadoop fs -du -s -h /T00/FOC/T2001.dat

11.FOC資料檔案合并下載
語法: hadoop fs -getmerge [-nl]
將源目錄和目標檔案作為輸入,并將SRC中的檔案連接到目的地本地檔案,可選地,可以設定NL,以便在每個檔案的末尾添加新行字符(LF),跳過空檔案可用于避免在空檔案的情況下不需要的換行符,
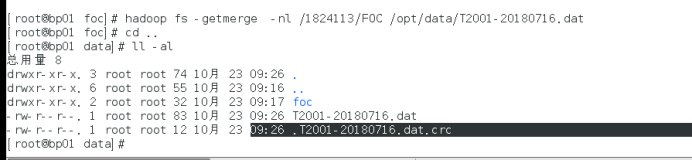
12.FOC資料檔案移動
語法: hadoop fs -mv URI [URI …]
將檔案從源移動到目的地,這個命令允許多個源,在這種情況下,目的地需要是一個目錄,不允許跨檔案系統移動檔案,
hadoop fs -mv /T00/FOC/T2001.csv /T00/FOC/T2001-20180716.dat
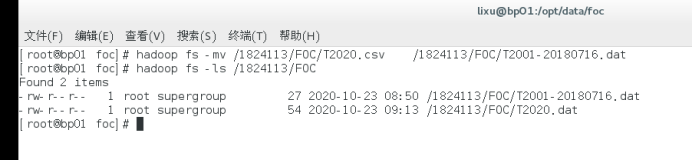
MapReduce測驗
cd /opt/hadoop/hadoop-2.10.0/share/hadoop/mapreduce
上傳至HDFS中,輸入如下指令:
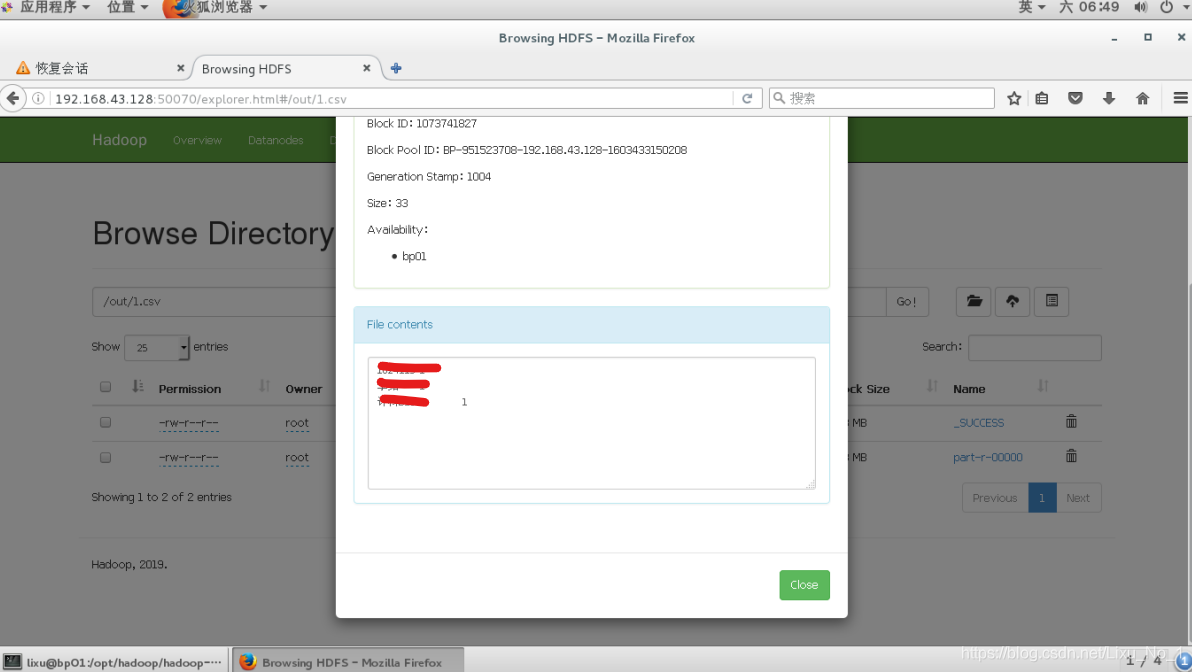
Hadoop jar hadoop-mapreduce-examples-2.10.0.jar wordcount /1824113/FOC/T2020.dat /out/1.csv
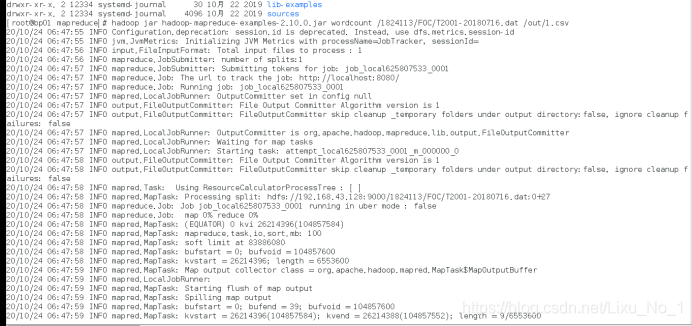
查看結果:
四、使用Ambria安裝部署Hadoop集群
1、安裝Ambria服務
2、使用Ambria安裝配置Hadoop集群
這一點小編還在抓緊趕制中…
總結
1、虛擬環境安裝配置
2、虛擬機中的網路配置
3、Hadoop偽分布環境安裝與配置
4、使用Ambria安裝部署Hadoop集群
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/192886.html
標籤:其他
上一篇:大資料虛擬機