我想爬求梨視頻中的一個視頻,以下是網址
https://www.pearvideo.com/video_1703247
這個視頻是應該是動態加載的。通過抓包工具,在XHR找到一個資料包,這里的Response里面應該有視頻的真正地址。
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://www.pearvideo.com/videoStatus.jsp?contId=1703247&mrd=0.9431604561367266'
data = requests.get(url=url, headers=headers).json()
print(data)
但是爬下來的不是下面截圖的這個。請問我應該怎么樣才能找到視頻的真正地址?
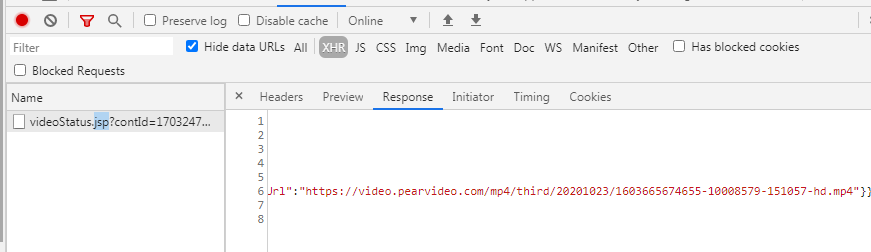
PS. 小白是自學某個爬蟲教程,但這個教程的代碼已經掛了,所以小白自己寫。現在還沒學到selenium,所以大佬不要講得太高級。我只學了BS4, XPATH, 正則。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/192887.html
上一篇:5分鐘學會Hadoop的集群部署