作者|Kelvin Lee
編譯|Flin
來源|towardsdatascience
獲得對正則化的直觀認識
在機器學習中,正則化是一種用來對抗高方差的方法——換句話說,就是模型學習再現資料的問題,而不是關于問題的潛在語意,與人類學習類似,我們的想法是構建家庭作業問題來測驗和構建知識,而不是簡單的死記硬背:例如,學習乘法表,而不是學習如何乘,
這種現象在神經網路學習中尤為普遍——學習能力越強,記憶的可能性就越大,這取決于我們這些實踐者如何引導深度學習模型來吸收我們的問題,而不是我們的資料,你們中的許多人在過去都曾遇到過這些方法,并且可能已經對不同的正則化方法如何影響結果形成了自己的直觀認識,為你們中那些不知道的人(甚至為那些知道的人!)本文為正則化神經網路引數的形成提供了直觀的指導,將這些方面可視化是很重要的,因為人們很容易將許多概念視為理所當然;本文中的圖形和它們的解釋將幫助你直觀地了解,當你增加正則化時,模型引數的實際情況,
在本文中,我將把 L2 和 dropouts 作為正則化的標準形式,我不會討論其他方法(例如收集更多資料)如何改變模型的作業方式,
所有的圖形和模型都是用標準的科學Python堆疊制作的:numpy、matplotlib、scipy、sklearn,而神經網路模型則是用PyTorch構建的,
開發復雜函式
深度學習的核心原則之一是深度神經網路作為通用函式逼近的能力,無論你感興趣的是什么,疾病傳播,自動駕駛汽車,天文學等,都可以通過一個自學習模型來壓縮和表達,這種想法絕對是令人驚奇的!盡管你感興趣的問題實際上是是否可以用決議函式f來表示這些問題,但當你通過訓練來調整機器學習模型時,該模型采用的引數θ允許模型近似地學習 f*,
出于演示的目的,我們將查看一些相對簡單的資料:理想情況下,一維中的某些資料足夠復雜,足以使老式曲線擬合變得痛苦,但還不足以使抽象和理解變得困難,我要創建一個復雜的函式來模擬周期信號,但是要加入一些有趣的東西,下面的函式實作如下方程:
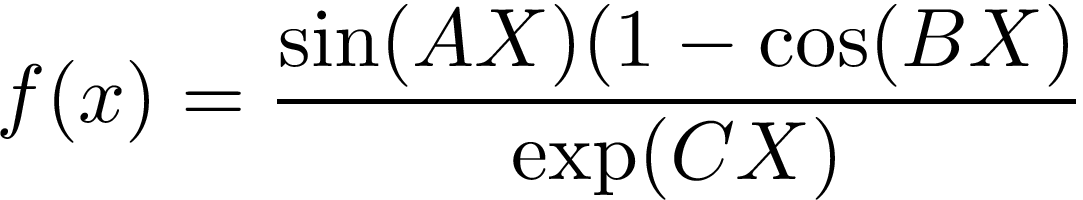
其中A,B,C是從不同高斯分布中采樣的亂數,這些值的作用是在非常相似的函式之間加上滯后,使得它們隨機地加在一起產生非常不同的f值,我們還將在資料中添加白色(高斯)噪聲,以模擬所收集資料的效果,
讓我們將隨機生成的資料樣本可視化:在本文的其余部分中,我們將使用一個小的神經網路來重現這條曲線,
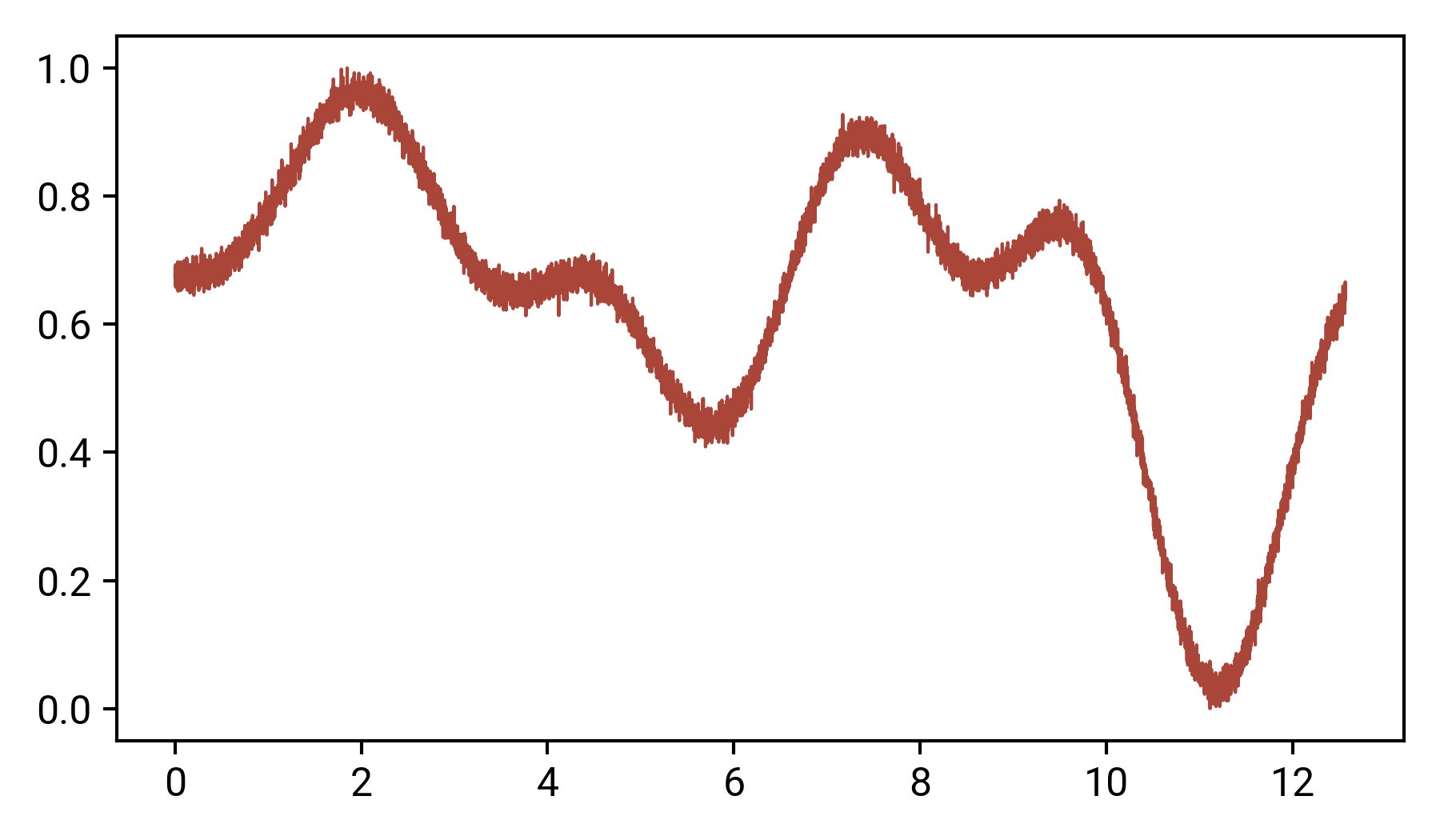
為了進行我們的模型訓練,我們將把它分成訓練/驗證集,為此,我將在sklearn.model_selection中使用極其方便的train_test_split功能,讓我們設計訓練和驗證集:
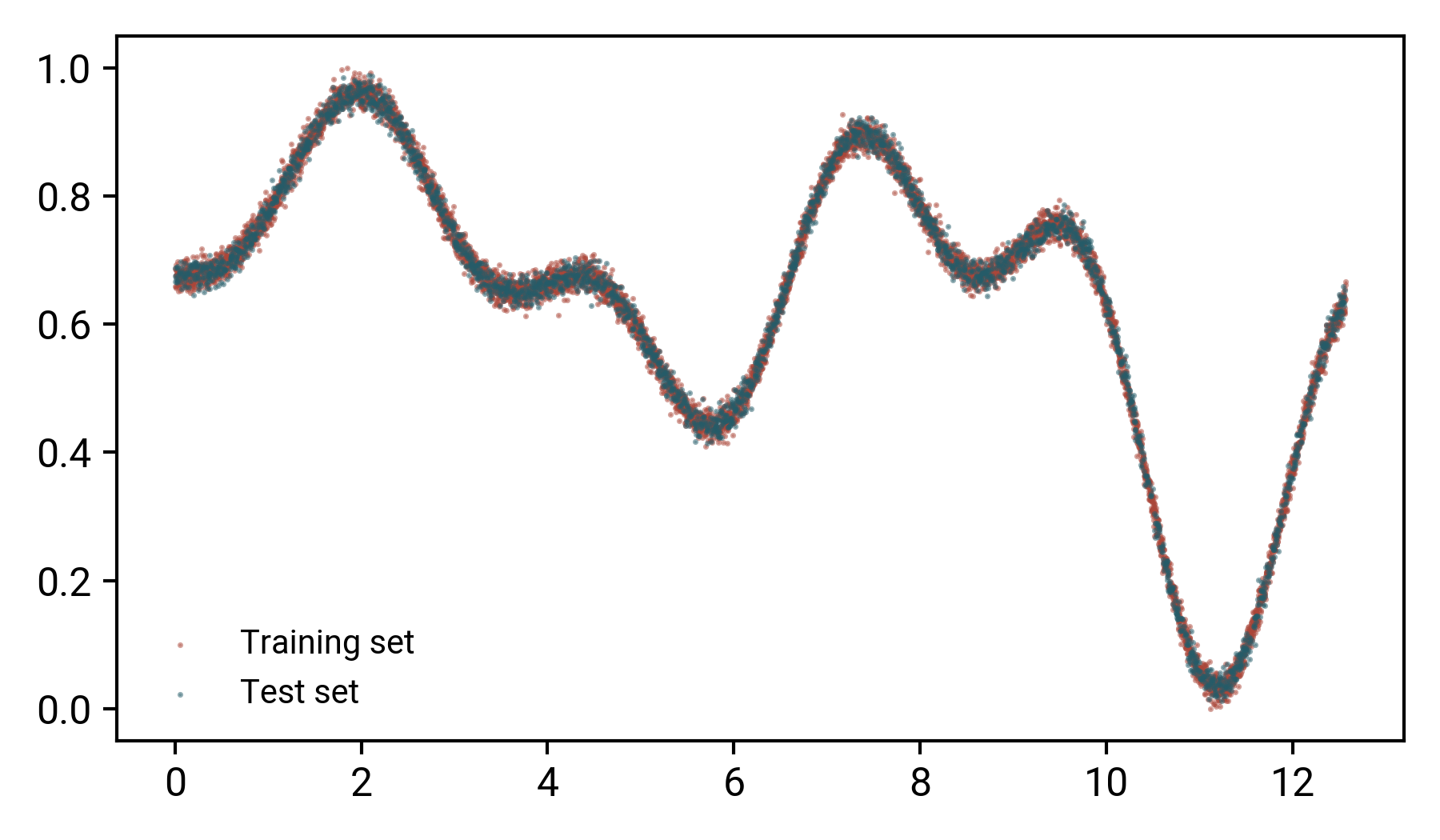
正如我們在圖中看到的,這兩個集合在表示整個曲線方面都做得相當好:如果我們洗掉其中一個,我們可以或多或少地收集到資料表示的相同圖片,這是交叉驗證的一個非常重要的方面!
開發我們的模型
現在我們有了一個資料集,我們需要一個相對簡單的模型來嘗試復制它,為了達到這個目的,我們將要處理一個四層的神經網路,它包含三個隱藏層的單個輸入和輸出值,每個隱藏層64個神經元,
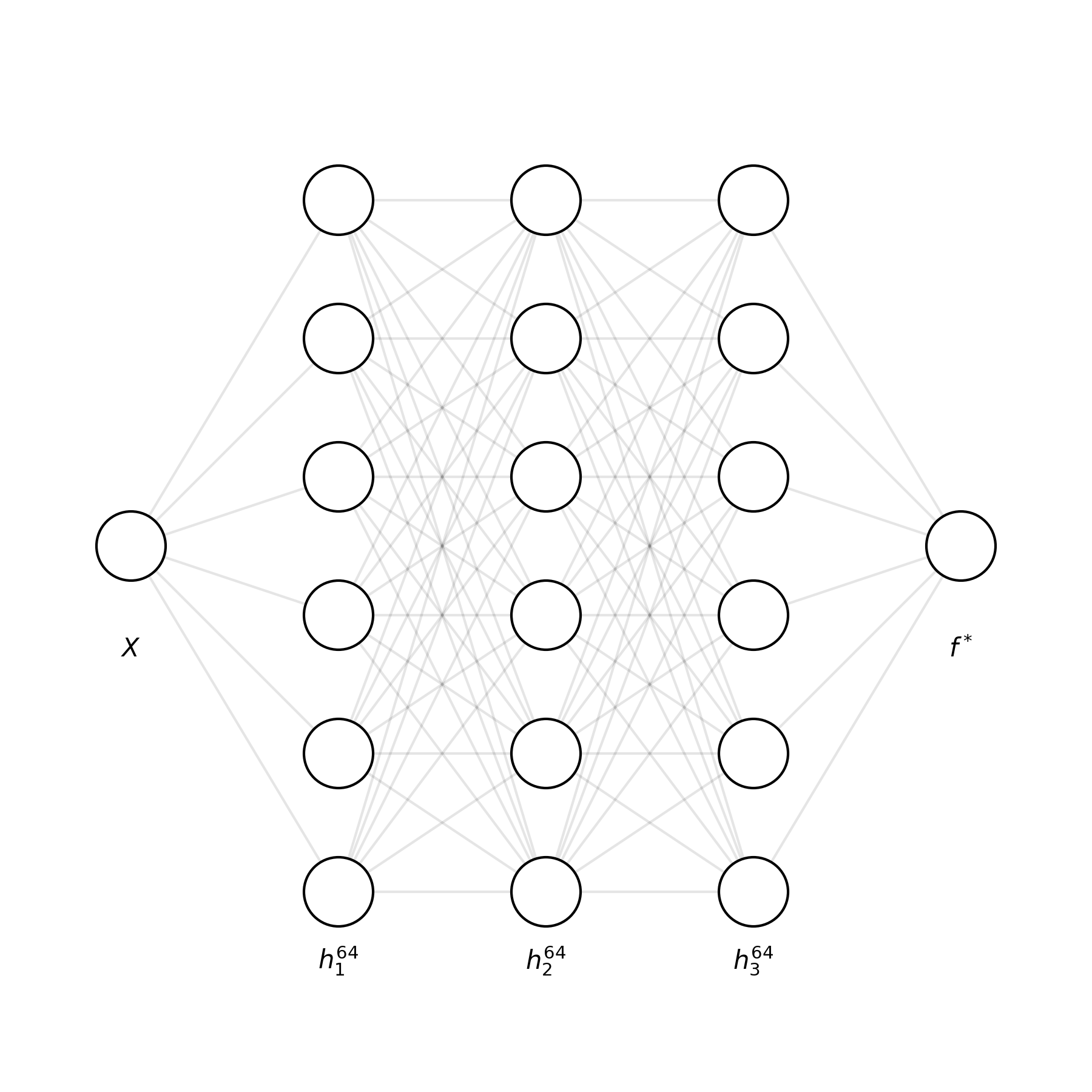
為了方便起見,每個隱藏層都有一個LeakyReLU激活,輸出上有ReLU激活,原則上,這些應該不那么重要,但是在測驗程序中,模型有時無法學習一些“復雜”的功能,特別是當使用像tanh和sigmoid這樣容易飽和的激活函式時,在本文中,這個模型的細節并不重要:重要的是它是一個完全連接的神經網路,它有能力學習逼近某些函式,
為了證明模型的有效性,我使用均方誤差(MSE)損失和ADAM優化器執行了通常的訓練/驗證周期,沒有任何形式的正則化,最后得到了以下結果:
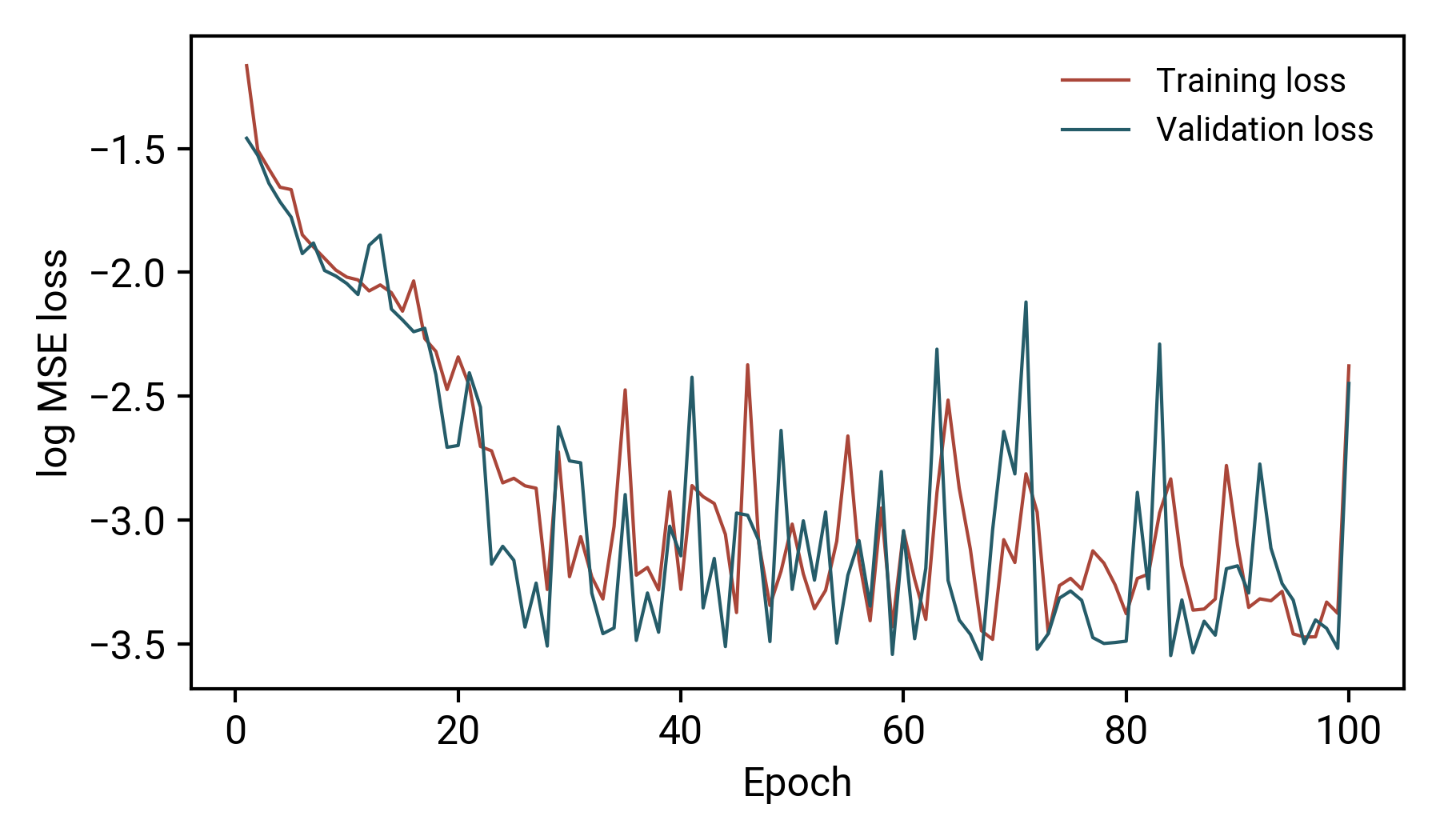
當我們使用此模型來預測:
除了曲率變化很快的區域(接近x=11)之外,這個模型很好地再現了我們的“復雜”函式!
現在,我可以聽到你在問:如果模型運行良好,我為什么要做任何正則化?在本演示中,我們的模型是否過擬合并不重要:我想要理解的是正則化如何影響一個模型;在我們的例子中,它甚至會對一個完美的作業模型產生不利影響,在某種意義上,你可以把這理解為一個警告:當你遇到過度擬合時要處理它,但在此之前不要處理,用Donald Knuth的話說,“不成熟的優化是萬惡之源”,
正則化如何影響引數
現在我們已經完成了所有的樣板檔案,我們可以進入文章的核心了!我們的重點是建立對正則化的直觀認識,即不同的正則化方法如何從三個角度影響我們的簡單模型:
-
訓練/驗證的損失會怎樣?
-
我們的模型性能會發生什么變化?
-
實際的引數會怎樣呢?
雖然前兩點很簡單,但是很多人可能不熟悉如何量化第三點,在這個演示中,我將使用核密度評估來測量引數值的變化:對于那些熟悉Tensorboard的人來說,你將看到這些圖;對于那些不知道的人,可以把這些圖看作是復雜的直方圖,目標是可視化我們的模型引數如何隨正則化而變化,下圖顯示了訓練前后θ分布的差異:
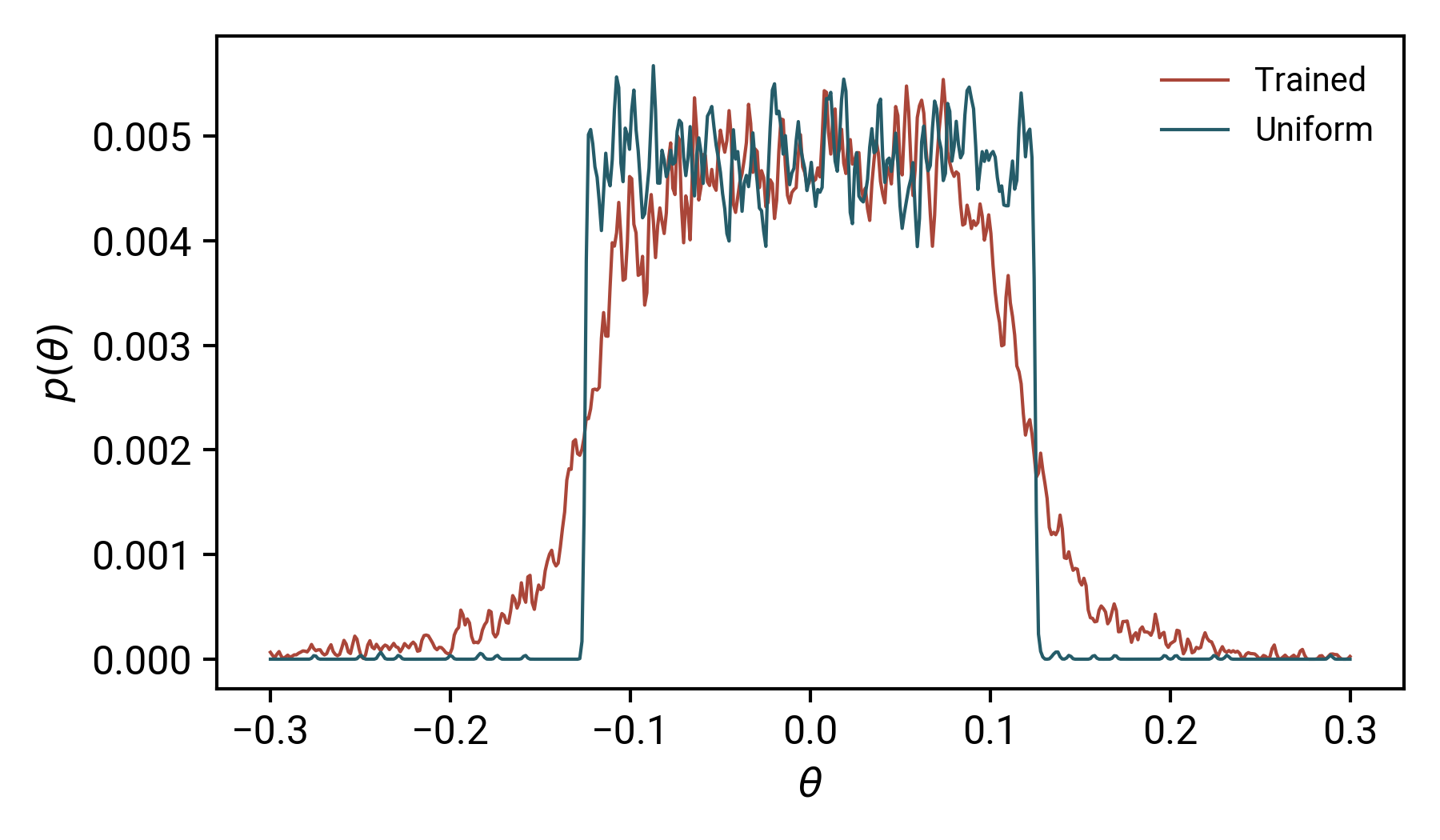
藍色曲線被標記為“均勻的”,因為它代表了我們用均勻分布初始化的模型引數:你可以看到這基本上是一個頂帽函式,在中心具有相等的概率,這與訓練后的模型引數形成了鮮明的對比:經過訓練,模型需要不均勻的θ值才能表達我們的功能,
L2正則化
正則化最直接的方法之一是所謂的L2正則化:L2指的是使用引數矩陣的L2范數,由線性代數可知,矩陣的范數為:
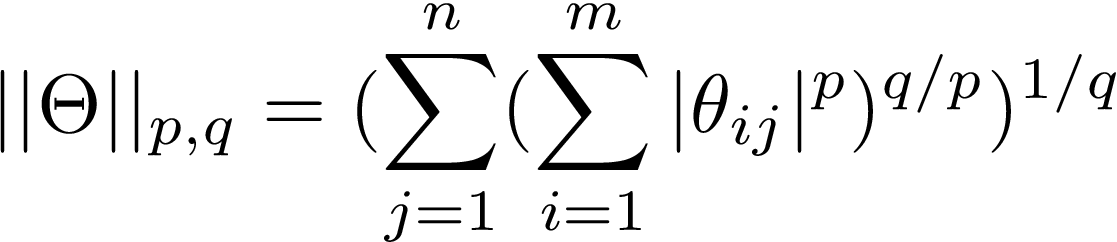
在前神經網路機器學習中,引數通常用向量而不是矩陣/張量來表示,這就是歐幾里得范數,在深度學習中,我們通常處理的是矩陣/高維張量,而歐幾里德范數并不能很好地擴展(超越歐幾里德幾何),L2范數實際上是上述方程的一個特例,其中p=q=2被稱為Frobenius或Hilbert-schmidt范數,它可以推廣到無限維度(即Hilbert空間),
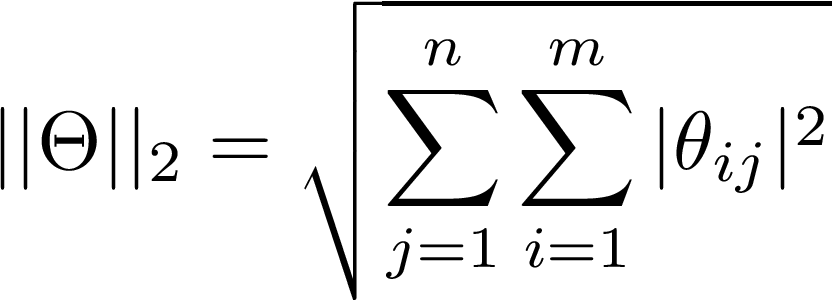
在深度學習應用中,應用這種L2正則化的一般形式是在代價函式J的末尾附加一個“懲罰”項:
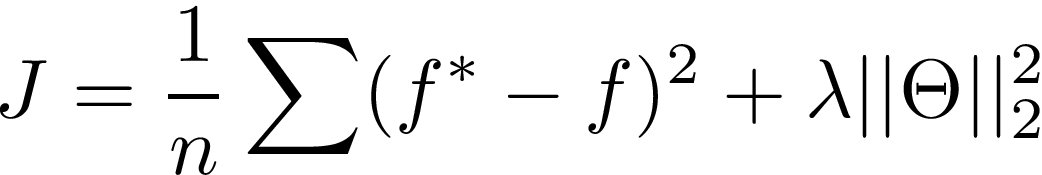
很簡單,這個方程定義了代價函式J為MSE損失,以及L2范數,L2范數的影響代價乘以這個前因子λ;這在許多實作中被稱為“權值衰減”超引數,通常在0到1之間,因為它控制了正則化的數量,所以我們需要了解這對我們的模型有什么影響!
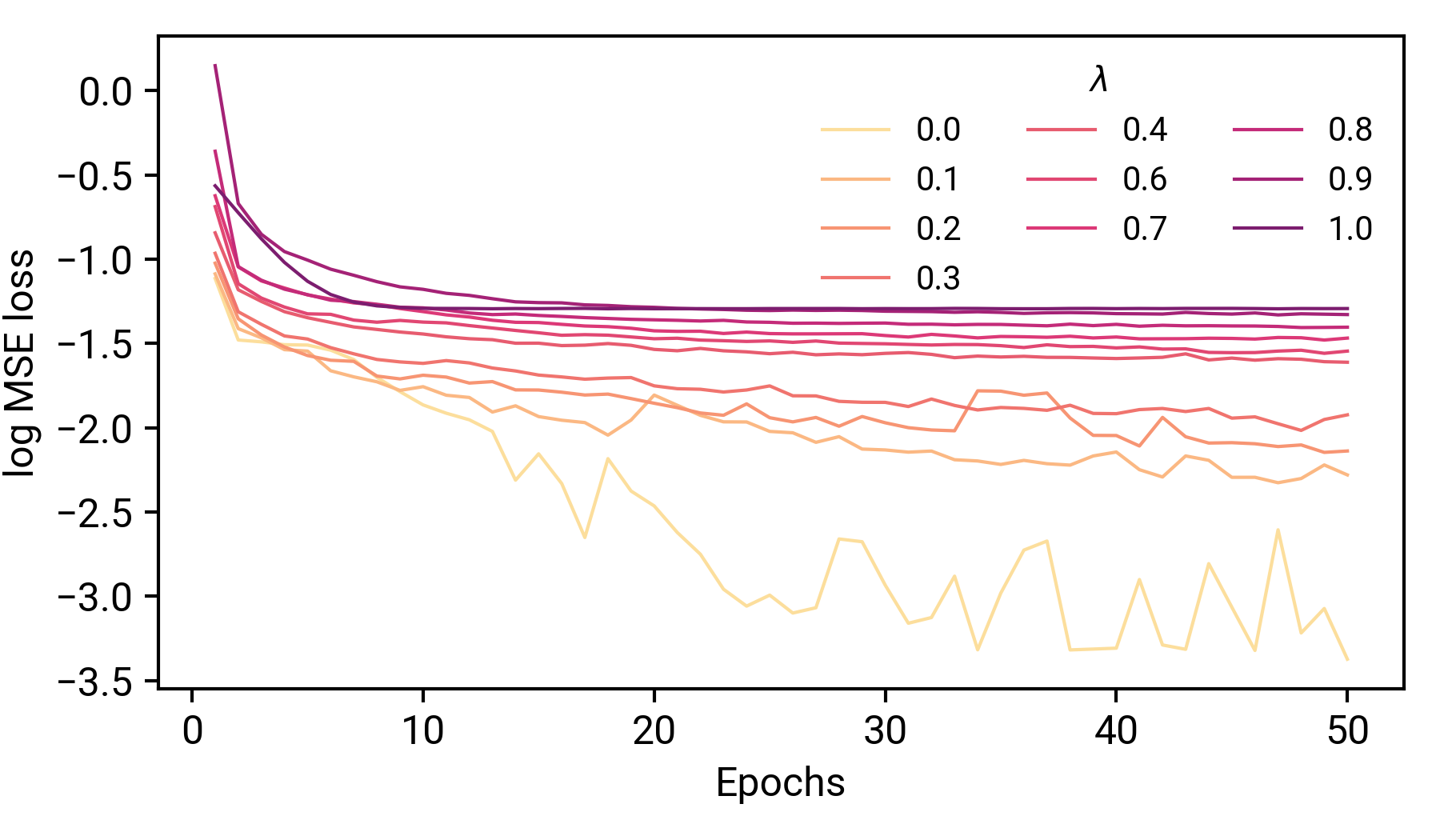
在一系列的實驗中,我們將重復與之前相同的訓練/驗證/可視化周期,但是這是在一系列的λ值上,首先,它是如何影響我們的訓練的?
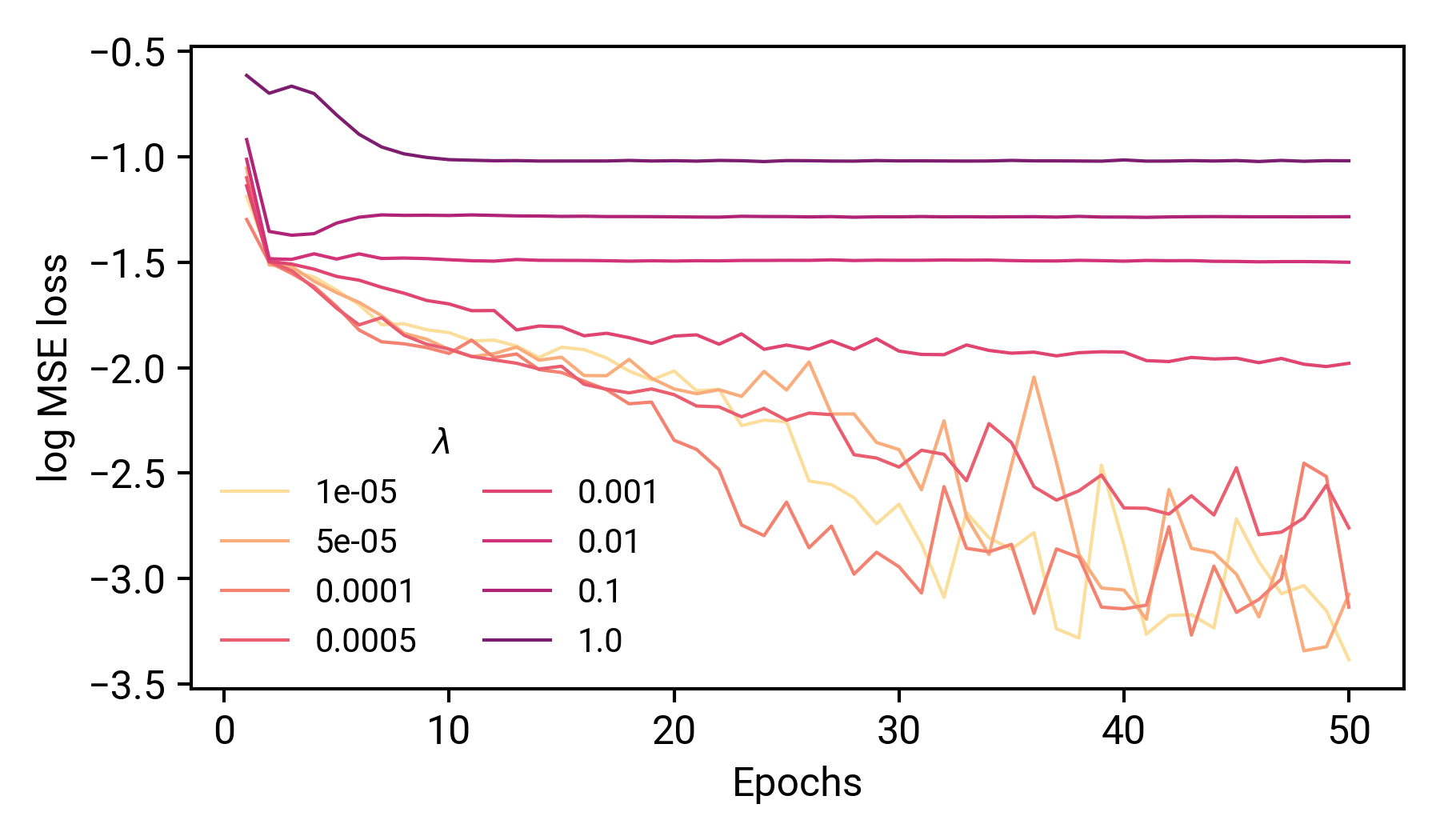
讓我們來分析一下,更深的紅色對應于更大的λ值(盡管這不是一個線性映射!),將訓練損失的痕跡顯示為MSE損失的日志,記住,在我們的非正則化模型中,這些曲線是單調遞減的,在這里,當我們增加λ的值,最終訓練誤差大大增加,并且早期損失的減少也沒有那么顯著,當我們試圖使用這些模型來預測我們的功能時,會發生什么?
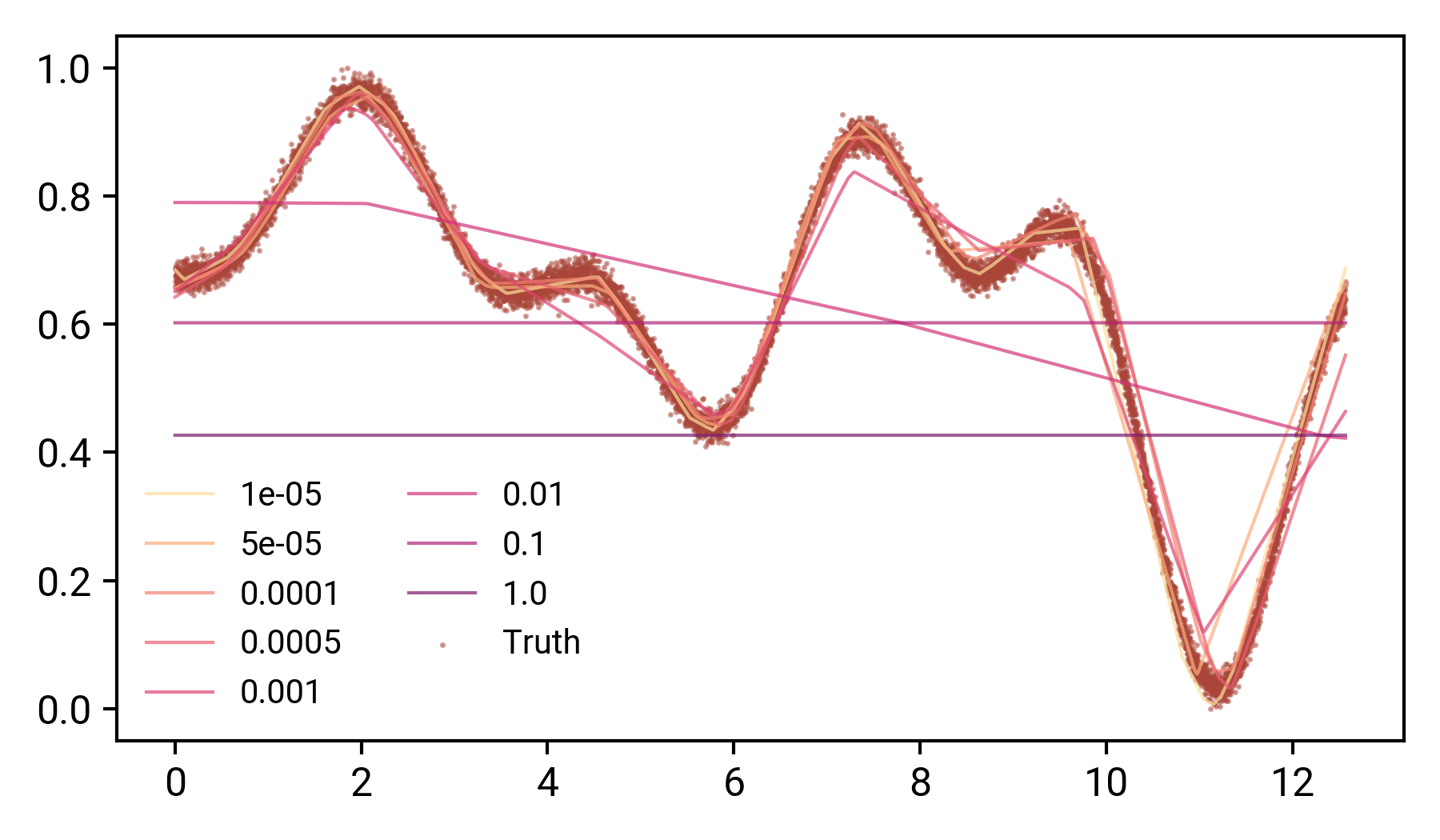
我們可以看到,當λ值很小時,函式仍然可以很好地表達,轉折點似乎在λ=0.01附近,在這里,曲線的定性形狀被再現,但不是實際的資料點,從λ>0.01,模型只是預測整個資料集的平均值,如果我們把這些解釋為我們在訓練上的損失,那么損失就會停止,這也就不足為奇了,
那么引數的分布呢?
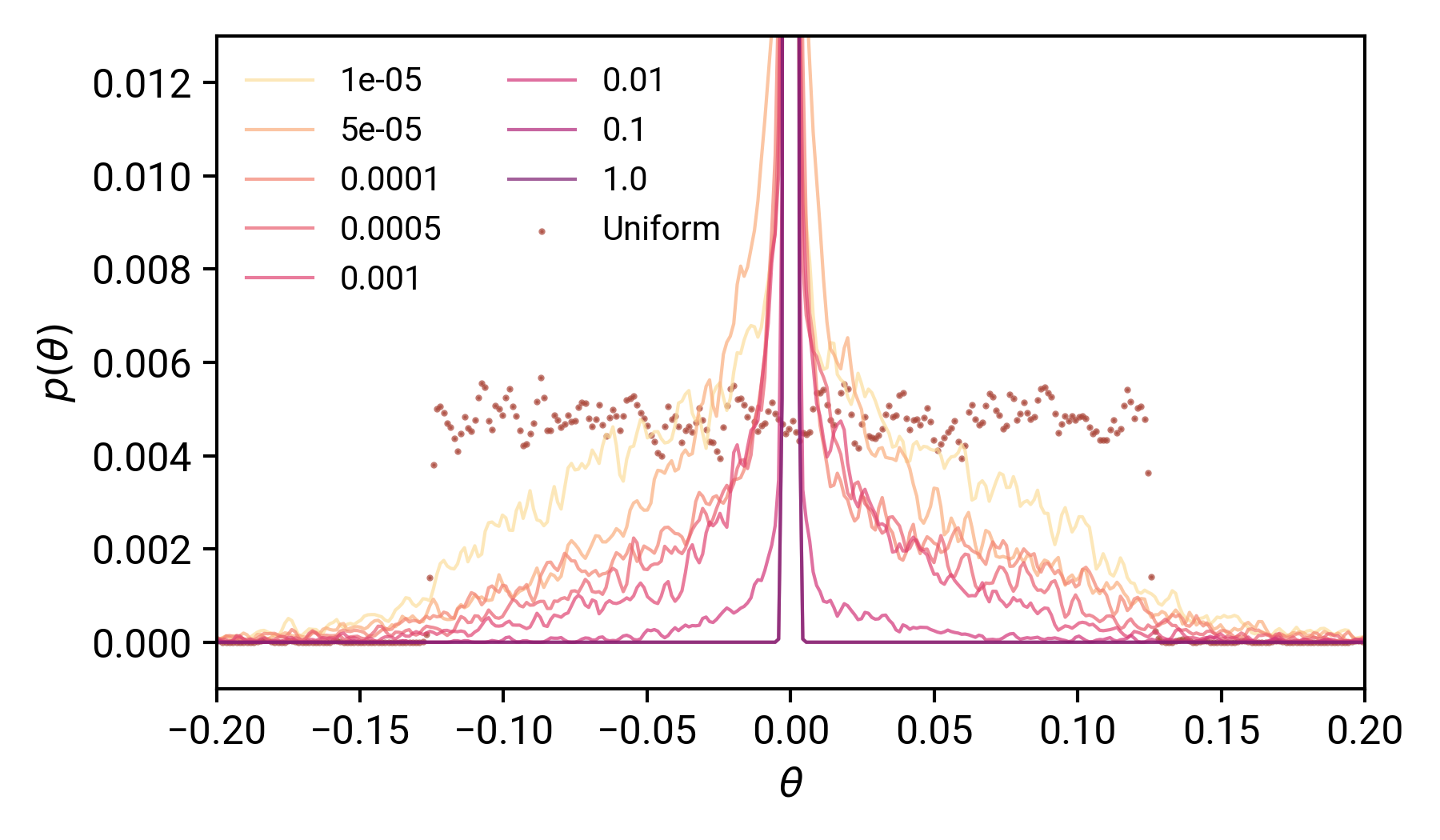
我們看到,引數值的傳播大大受阻,正如我們的 λ 從低到高,與均勻分布相比,引數值的擴展越來越接近于零,λ=1.0時,θ的分布看起來就像一個在0處的狄拉克δ函式,由此,我們可以消除L2正則化作用于約束引數空間——強制θ非常稀疏并且接近零,
dropouts呢?
另一種流行且成本高效的正則化方法是在模型中包含dropouts,這個想法是,每次模型通過時,一些神經元通過根據概率p將它們的權值設定為0來失活,換句話說,我們對引數應用一個布爾掩碼,每次資料通過不同的單元時都被激活,這背后的基本原理是將模型學習分布在整個網路中,而不是特定的一層或兩層/神經元,
在我們的實驗中,我們將在每個隱藏層之間加入dropout層,并將dropout概率p從0調整為1,在前一種情況下,我們應該有一個非正則化的模型,而在后一種情況下,我們各自的學習能力應該有所下降,因為每一個隱藏層都被停用了,
我們看到了與L2正則化非常相似的效果:總體而言,模型的學習能力下降,并且隨著dropout概率值的增大,最終損失的比例也增大,
當我們試圖使用這些模型來預測我們的功能時:
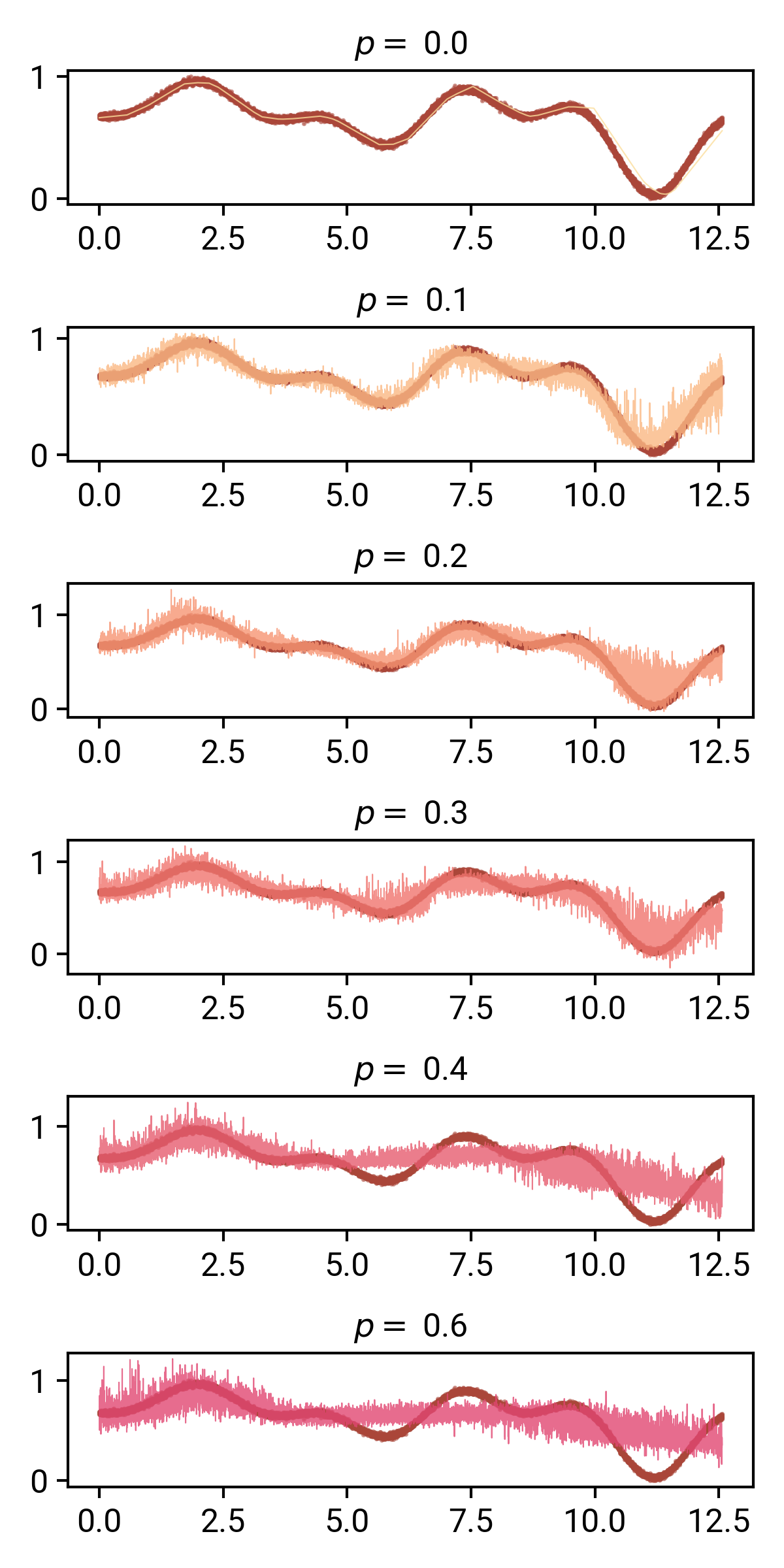
如圖,我們逐步增加了dropout概率,從p=0.1開始,我們可以看到我們的模型對于它的預測開始變得相當不可靠:最有趣的是,它似乎近似地跟蹤了我們的資料,包括噪音!
在p=0.2和0.3時,這一點在x=11時更加明顯——回想一下,我們的非正則化模型很難得到正確的函式區域,我們看到,帶dropout的預測實際上使這一區域難以置信的模糊,這幾乎就像模型告訴我們,它是不確定的!(后面會詳細介紹),
從p=0.4開始,模型的能力似乎受到了極大的限制,除了第一部分之外,它幾乎無法再現曲線的其他部分,在p=0.6時,預測結果似乎接近資料集的平均值,這似乎也發生在L2正則化的大值上,
我們的模型引數呢?
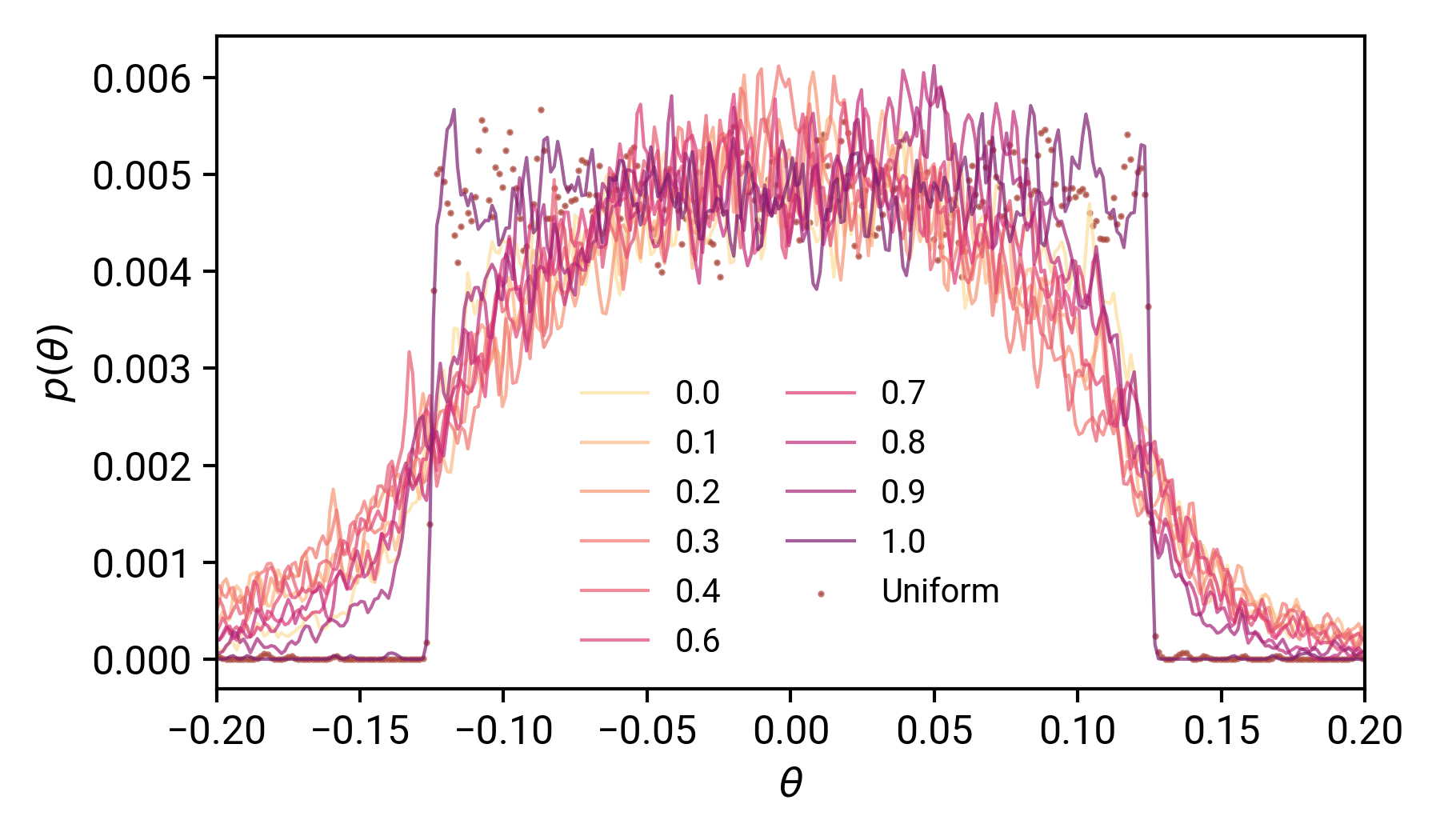
將此結果與我們的L2范數結果進行比較:對于dropout,我們的引數分布更廣,這增加了我們的模型表達的能力,除p=1.0外,dropout概率的實際值對引數的分布影響不大,如果有影響的話,在p=1.0時,我們的模型沒有學到任何東西,只是類似于均勻分布,在p值降低時,盡管速度降低了,模型仍然能夠學習,
最后
從我們簡單的實驗中,我希望你已經從我們探索的三個角度,對這兩種正則化方法如何影響神經網路模型形成了一些直觀認識,
L2正則化非常簡單,只需要調整一個超引數,當我們增加L2懲罰的權重時,因為引數空間的變化,對于大的值(0.01-1),模型容量下降得非常快,對于較小的值,你甚至可能不會看到模型預測有什么變化,
Dropouts是一種更復雜的正則化方法,因為現在必須處理另一層超引數復雜性(p可以為不同的層提供不同的值),盡管如此,這實際上可以提供模型表達的另一個維度:模型不確定性的形式,
在這兩種方法中,我們看到正則化增加了最終的訓練損失,這些人工形式的正則化(與獲取更多的訓練資料相反)的代價是它們會降低模型的容量: 除非你確定你的模型需要正則化,否則在這樣的結果下,你不會希望正則化,但是,通過本指南,你現在應該知道這兩種形式如何影響你的模型!
如果你感興趣,可以在Binder上(https://mybinder.org/v2/gh/laserkelvin/understanding-ml/master) 運行一些代碼,我不需要運行torch模型(這會耗盡它們的資源),但是你可以使用它在notebook中查看代碼,
原文鏈接:https://towardsdatascience.com/a-visual-intuition-for-regularization-in-deep-learning-fe904987abbb
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/194793.html
標籤:其他
下一篇:機器為什么能夠學習?