對于云平臺中的隔離問題,前面咱們用的策略一直都是 VLAN,但是我們也說過這種策略的問題,VLAN 只有 12 位,共 4096 個,當時設計的時候,看起來是夠了,但是現在絕對不夠用,怎么辦呢?
一種方式是修改這個協議,這種方法往往不可行,因為當這個協議形成一定標準后,千千萬萬設備上跑的程式都要按這個規則來,現在說改就放,誰去挨個兒告訴這些程式呢?很顯然,這是一項不可能的工程,
另一種方式就是擴展,在原來包的格式的基礎上擴展出一個頭,里面包含足夠用于區分租戶的 ID,外層的包的格式盡量和傳統的一樣,依然兼容原來的格式,一旦遇到需要區分用戶的地方,我們就用這個特殊的程式,來處理這個特殊的包的格式,
這個概念很像咱們第 22 講講過的隧道理論,還記得自駕游通過擺渡輪到海南島的那個故事嗎?在那一節,我們說過,擴展的包頭主要是用于加密的,而我們現在需要的包頭是要能夠區分用戶的,
底層的物理網路設備組成的網路我們稱為 Underlay 網路,而用于虛擬機和云中的這些技術組成的網路稱為 Overlay 網路,這是一種基于物理網路的虛擬化網路實作,這一節我們重點講兩個 Overlay 的網路技術,
GRE
第一個技術是 GRE,全稱 Generic Routing Encapsulation,它是一種 IP-over-IP 的隧道技術,它將 IP 包封裝在 GRE 包里,外面加上 IP 頭,在隧道的一端封裝資料包,并在通路上進行傳輸,到另外一端的時候解封裝,你可以認為 Tunnel 是一個虛擬的、點對點的連接,
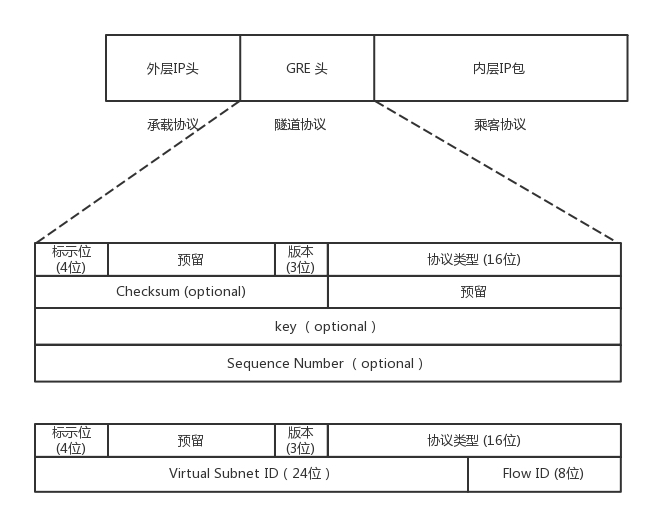
從這個圖中可以看到,在 GRE 頭中,前 32 位是一定會有的,后面的都是可選的,在前 4 位標識位里面,有標識后面到底有沒有可選項?這里面有個很重要的 key 欄位,是一個 32 位的欄位,里面存放的往往就是用于區分用戶的 Tunnel ID,32 位,夠任何云平臺喝一壺的了!
下面的格式型別專門用于網路虛擬化的 GRE 包頭格式,稱為 NVGRE,也給網路 ID 號 24 位,也完全夠用了,
除此之外,GRE 還需要有一個地方來封裝和解封裝 GRE 的包,這個地方往往是路由器或者有路由功能的 Linux 機器,
使用 GRE 隧道,傳輸的程序就像下面這張圖,這里面有兩個網段、兩個路由器,中間要通過 GRE 隧道進行通信,當隧道建立之后,會多出兩個 Tunnel 埠,用于封包、解封包,
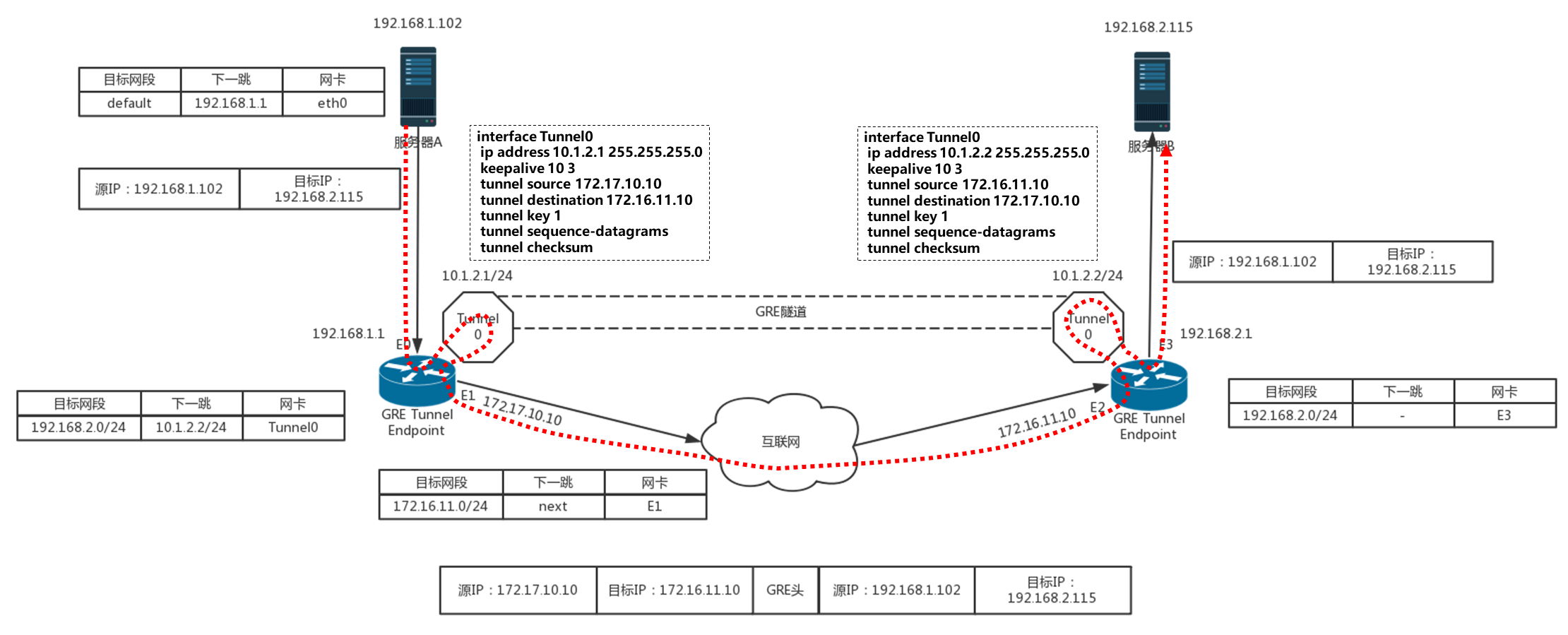
- 主機 A 在左邊的網路,IP 地址為 192.168.1.102,它想要訪問主機 B,主機 B 在右邊的網路,IP 地址為 192.168.2.115,于是發送一個包,源地址為 192.168.1.102,目標地址為 192.168.2.115,因為要跨網段訪問,于是根據默認的 default 路由表規則,要發給默認的網關 192.168.1.1,也即左邊的路由器,
- 根據路由表,從左邊的路由器,去 192.168.2.0/24 這個網段,應該走一條 GRE 的隧道,從隧道一端的網卡 Tunnel0 進入隧道,
- 在 Tunnel 隧道的端點進行包的封裝,在內部的 IP 頭之外加上 GRE 頭,對于 NVGRE 來講,是在 MAC 頭之外加上 GRE 頭,然后加上外部的 IP 地址,也即路由器的外網 IP 地址,源 IP 地址為 172.17.10.10,目標 IP 地址為 172.16.11.10,然后從 E1 的物理網卡發送到公共網路里,
- 在公共網路里面,沿著路由器一跳一跳地走,全部都按照外部的公網 IP 地址進行,
- 當網路包到達對端路由器的時候,也要到達對端的 Tunnel0,然后開始解封裝,將外層的 IP 頭取下來,然后根據里面的網路包,根據路由表,從 E3 口轉發出去到達服務器 B,
從 GRE 的原理可以看出,GRE 通過隧道的方式,很好地解決了 VLAN ID 不足的問題,但是,GRE 技術本身還是存在一些不足之處,
首先是 Tunnel 的數量問題,GRE 是一種點對點隧道,如果有三個網路,就需要在每兩個網路之間建立一個隧道,如果網路數目增多,這樣隧道的數目會呈指數性增長,
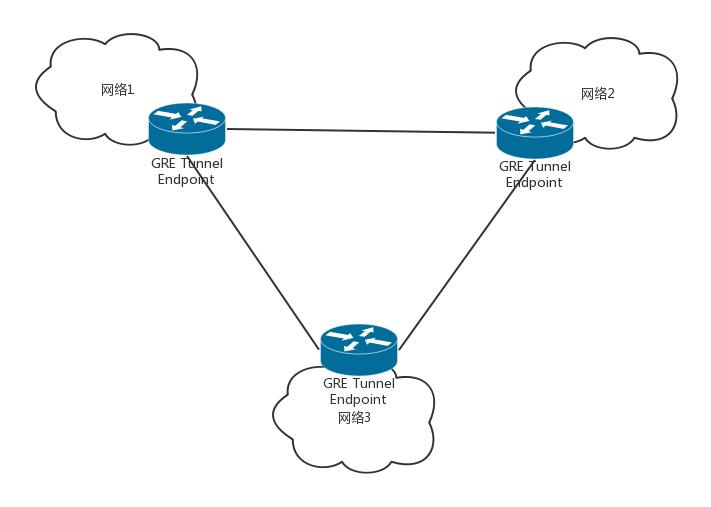
其次,GRE 不支持組播,因此一個網路中的一個虛機發出一個廣播幀后,GRE 會將其廣播到所有與該節點有隧道連接的節點,
另外一個問題是目前還是有很多防火墻和三層網路設備無法決議 GRE,因此它們無法對 GRE 封裝包做合適地過濾和負載均衡,
VXLAN
第二種 Overlay 的技術稱為 VXLAN,和三層外面再套三層的 GRE 不同,VXLAN 則是從二層外面就套了一個 VXLAN 的頭,這里面包含的 VXLAN ID 為 24 位,也夠用了,在 VXLAN 頭外面還封裝了 UDP、IP,以及外層的 MAC 頭,
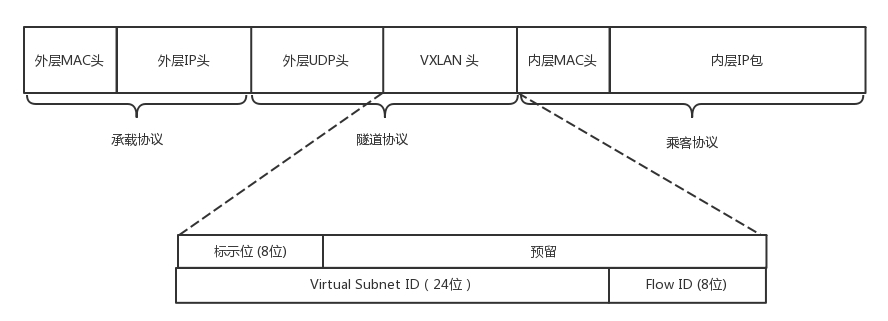
VXLAN 作為擴展性協議,也需要一個地方對 VXLAN 的包進行封裝和解封裝,實作這個功能的點稱為 VTEP(VXLAN Tunnel Endpoint),
VTEP 相當于虛擬機網路的管家,每臺物理機上都可以有一個 VTEP,每個虛擬機啟動的時候,都需要向這個 VTEP 管家注冊,每個 VTEP 都知道自己上面注冊了多少個虛擬機,當虛擬機要跨 VTEP 進行通信的時候,需要通過 VTEP 代理進行,由 VTEP 進行包的封裝和解封裝,
和 GRE 端到端的隧道不同,VXLAN 不是點對點的,而是支持通過組播的來定位目標機器的,而非一定是這一端發出,另一端接收,
當一個 VTEP 啟動的時候,它們都需要通過 IGMP 協議,加入一個組播組,就像加入一個郵件串列,或者加入一個微信群一樣,所有發到這個郵件串列里面的郵件,或者發送到微信群里面的訊息,大家都能收到,而當每個物理機上的虛擬機啟動之后,VTEP 就知道,有一個新的 VM 上線了,它歸我管,
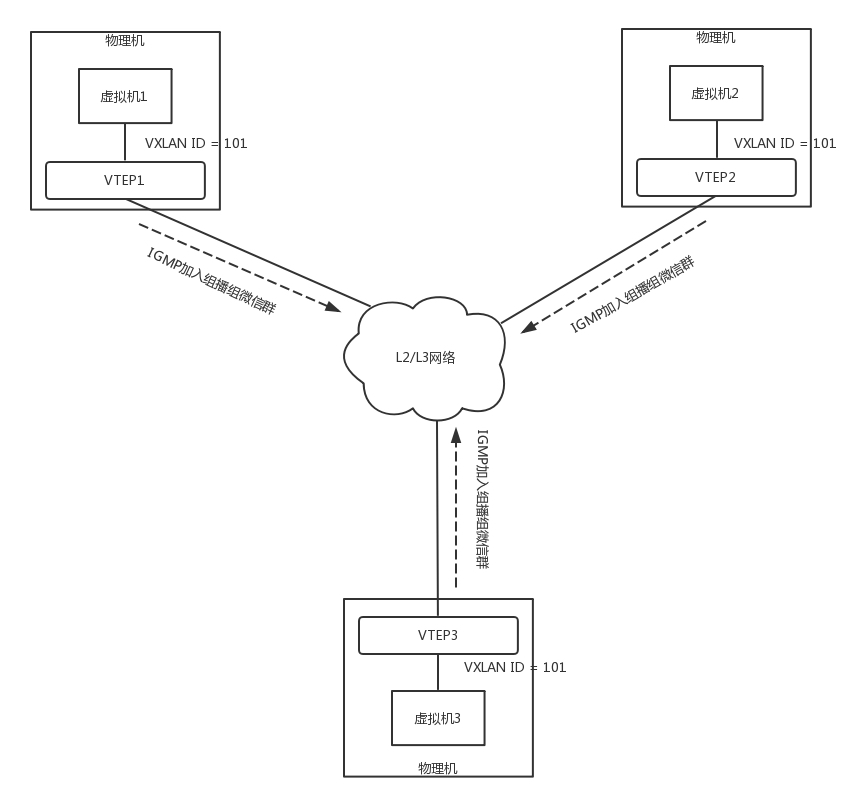
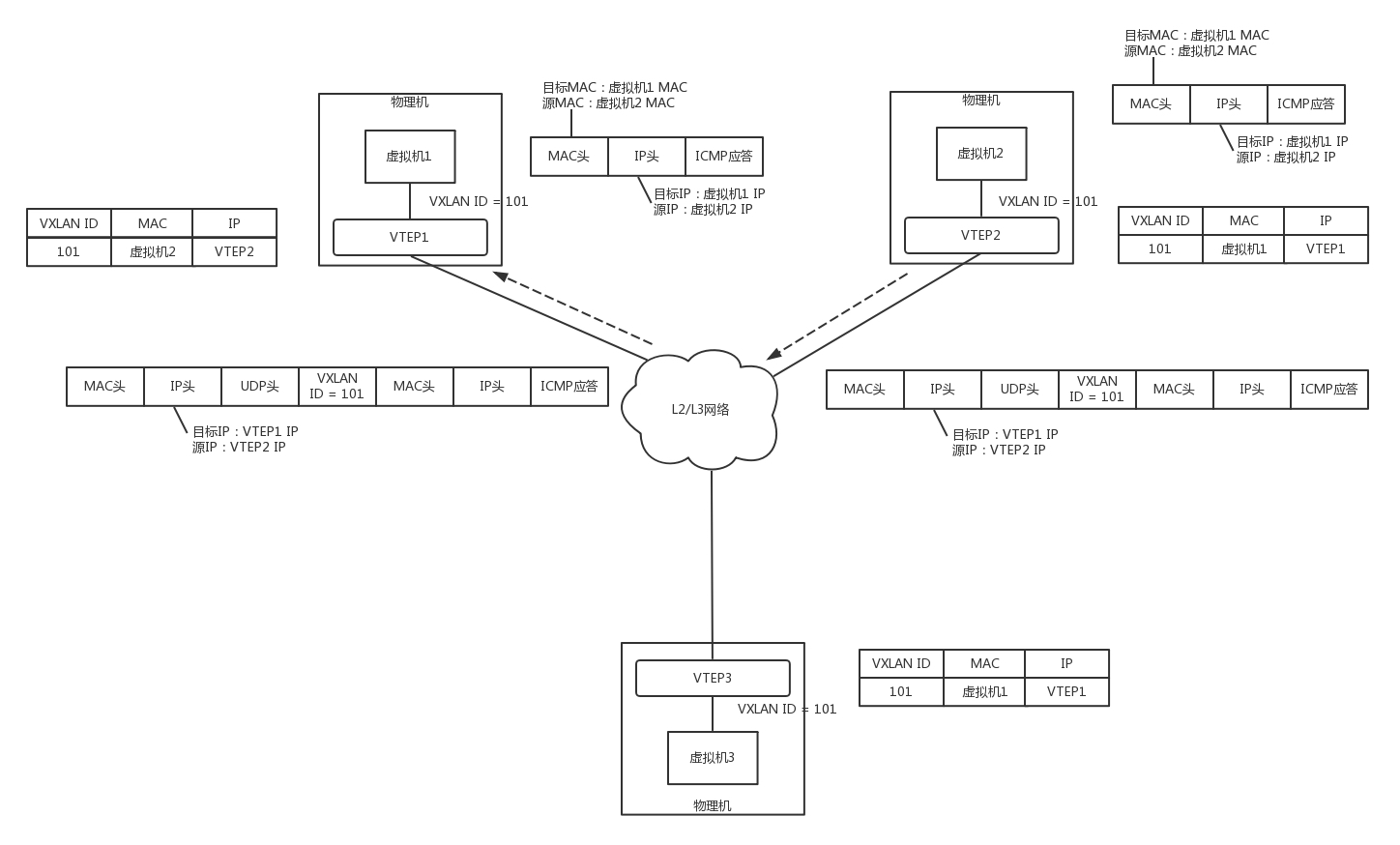
如圖,虛擬機 1、2、3 屬于云中同一個用戶的虛擬機,因而需要分配相同的 VXLAN ID=101,在云的界面上,就可以知道它們的 IP 地址,于是可以在虛擬機 1 上 ping 虛擬機 2,
虛擬機 1 發現,它不知道虛擬機 2 的 MAC 地址,因而包沒辦法發出去,于是要發送 ARP 廣播,
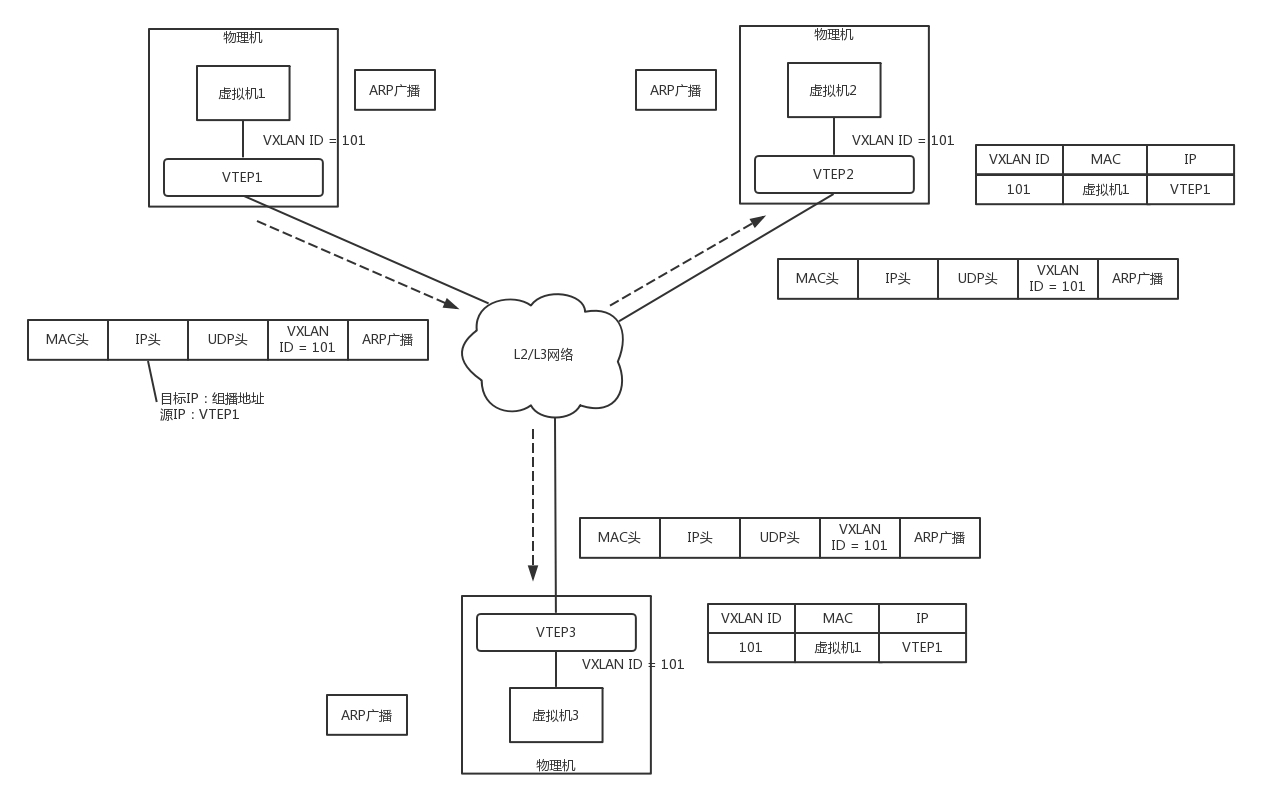
ARP 請求到達 VTEP1 的時候,VTEP1 知道,我這里有一臺虛擬機,要訪問一臺不歸我管的虛擬機,需要知道 MAC 地址,可是我不知道啊,這該咋辦呢?
VTEP1 想,我不是加入了一個微信群么?可以在里面 @all 一下,問問虛擬機 2 歸誰管,于是 VTEP1 將 ARP 請求封裝在 VXLAN 里面,組播出去,
當然在群里面,VTEP2 和 VTEP3 都收到了訊息,因而都會解開 VXLAN 包看,里面是一個 ARP,
VTEP3 在本地廣播了半天,沒人回,都說虛擬機 2 不歸自己管,
VTEP2 在本地廣播,虛擬機 2 回了,說虛擬機 2 歸我管,MAC 地址是這個,通過這次通信,VTEP2 也學到了,虛擬機 1 歸 VTEP1 管,以后要找虛擬機 1,去找 VTEP1 就可以了,
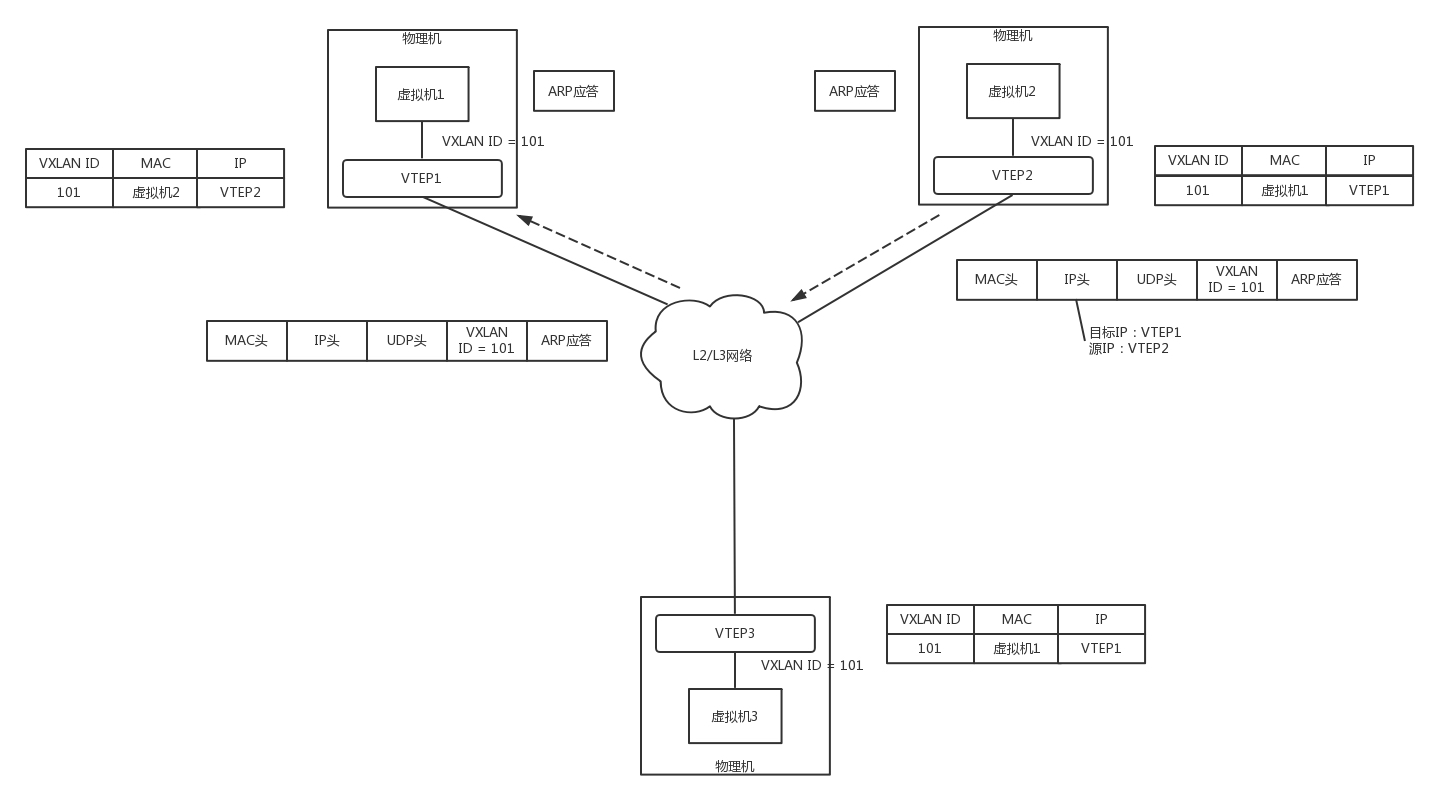
VTEP2 將 ARP 的回復封裝在 VXLAN 里面,這次不用組播了,直接發回給 VTEP1,
VTEP1 解開 VXLAN 的包,發現是 ARP 的回復,于是發給虛擬機 1,通過這次通信,VTEP1 也學到了,虛擬機 2 歸 VTEP2 管,以后找虛擬機 2,去找 VTEP2 就可以了,
虛擬機 1 的 ARP 得到了回復,知道了虛擬機 2 的 MAC 地址,于是就可以發送包了,
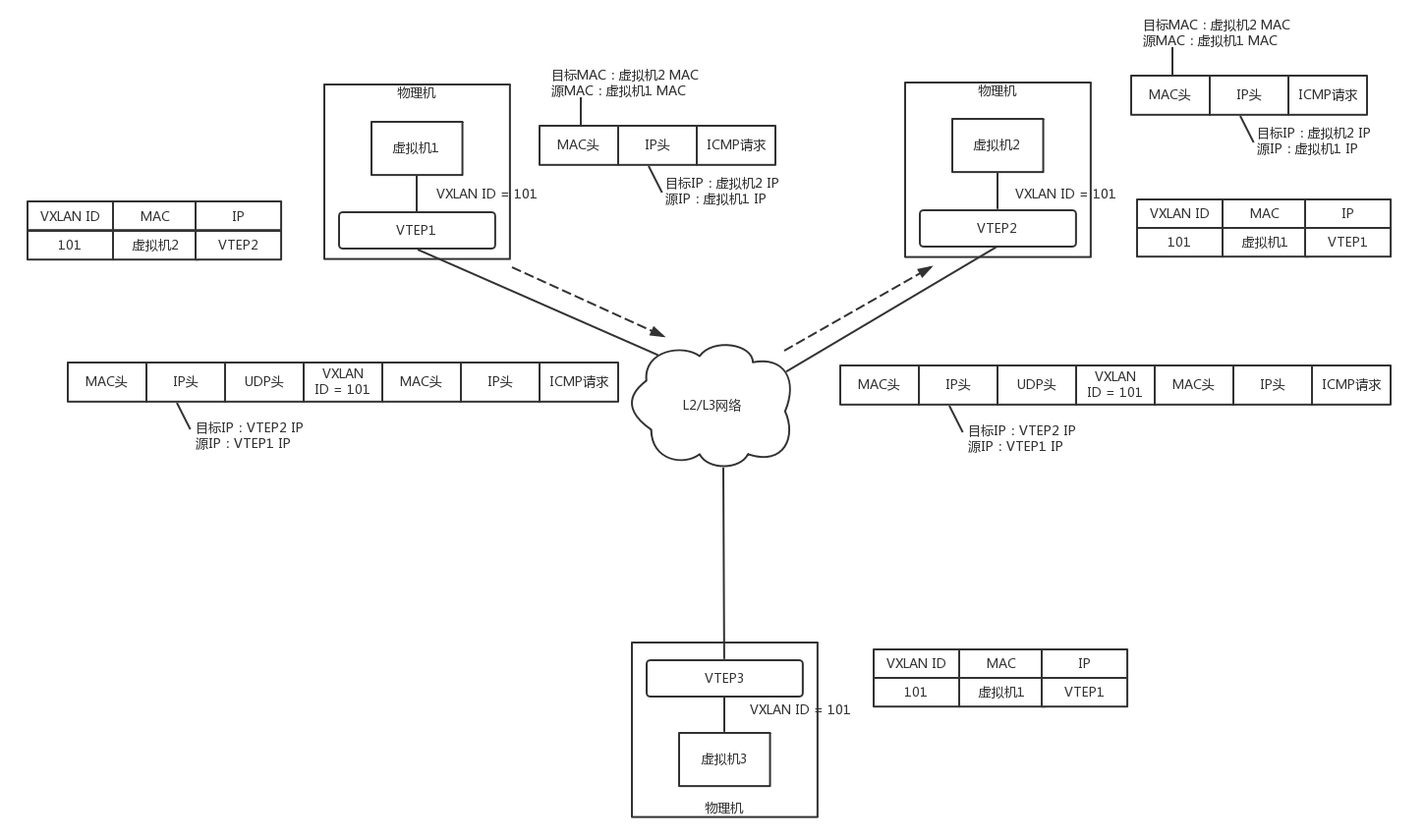
虛擬機 1 發給虛擬機 2 的包到達 VTEP1,它當然記得剛才學的東西,要找虛擬機 2,就去 VTEP2,于是將包封裝在 VXLAN 里面,外層加上 VTEP1 和 VTEP2 的 IP 地址,發送出去,
網路包到達 VTEP2 之后,VTEP2 解開 VXLAN 封裝,將包轉發給虛擬機 2,
虛擬機 2 回復的包,到達 VTEP2 的時候,它當然也記得剛才學的東西,要找虛擬機 1,就去 VTEP1,于是將包封裝在 VXLAN 里面,外層加上 VTEP1 和 VTEP2 的 IP 地址,也發送出去,
網路包到達 VTEP1 之后,VTEP1 解開 VXLAN 封裝,將包轉發給虛擬機 1,
有了 GRE 和 VXLAN 技術,我們就可以解決云計算中 VLAN 的限制了,那如何將這個技術融入云平臺呢?
還記得將你宿舍里面的情況,所有東西都搬到一臺物理機上那個故事嗎?
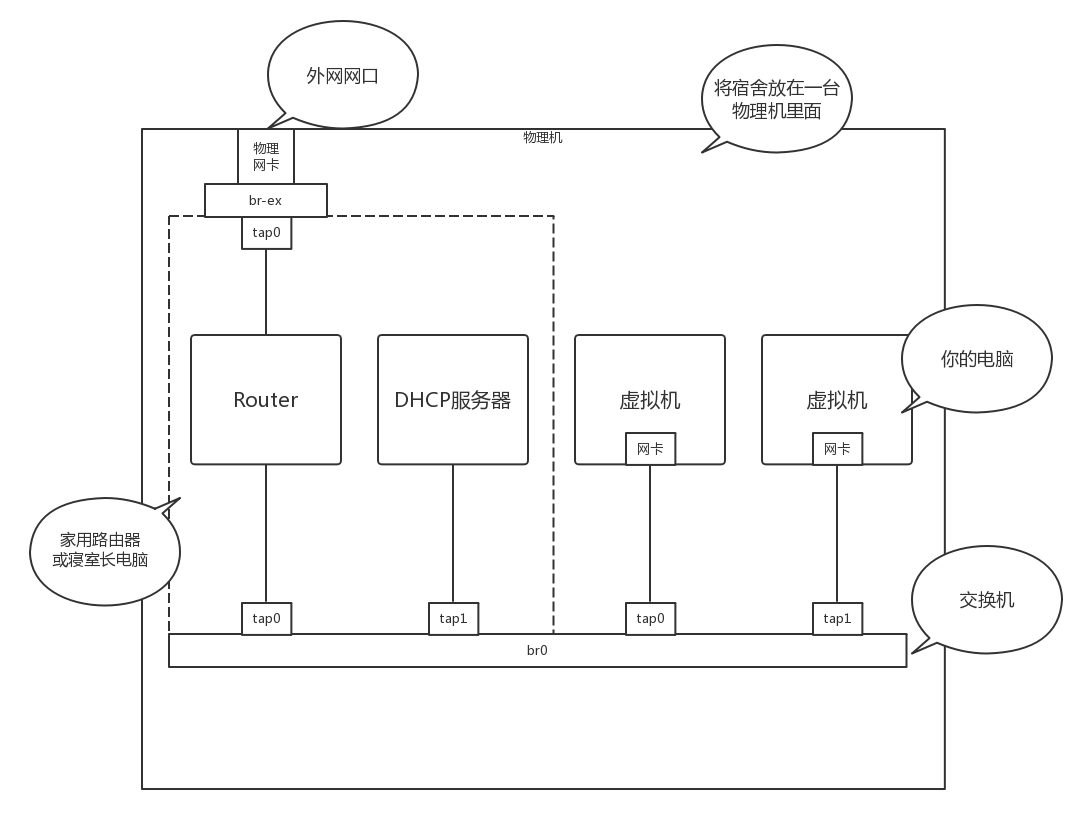
虛擬機是你的電腦,路由器和 DHCP Server 相當于家用路由器或者寢室長的電腦,外網網口訪問互聯網,所有的電腦都通過內網網口連接到一個交換機 br0 上,虛擬機要想訪問互聯網,需要通過 br0 連到路由器上,然后通過路由器將請求 NAT 后轉發到公網,
接下來的事情就慘了,你們宿舍鬧矛盾了,你們要分成三個宿舍住,對應上面的圖,你們寢室長,也即路由器單獨在一臺物理機上,其他的室友也即 VM 分別在兩臺物理機上,這下把一個完整的 br0 一刀三斷,每個宿舍都是單獨的一段,
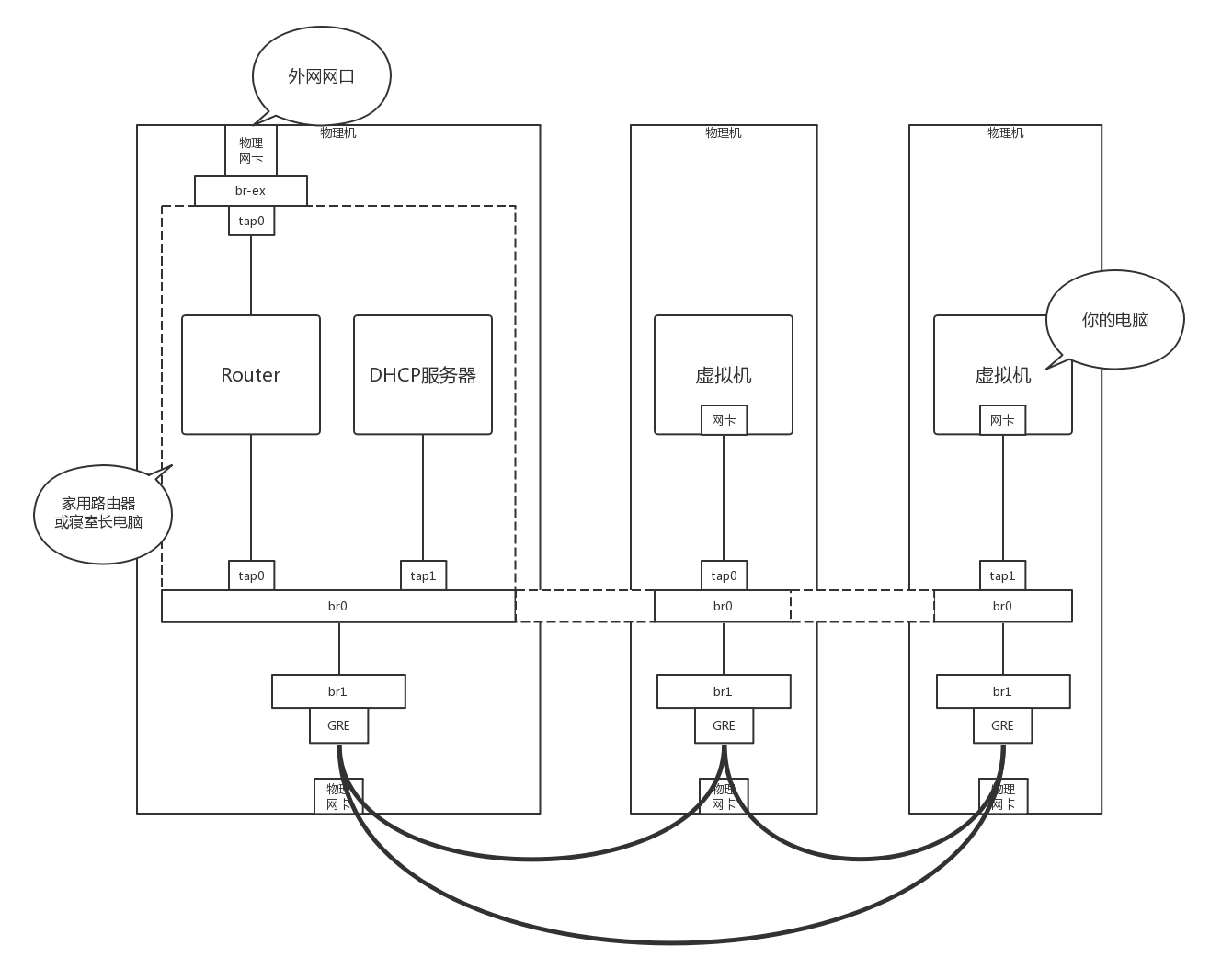
可是只有你的寢室長有公網口可以上網,于是你偷偷在三個宿舍中間打了一個隧道,用網線通過隧道將三個宿舍的兩個 br0 連接起來,讓其他室友的電腦和你寢室長的電腦,看起來還是連到同一個 br0 上,其實中間是通過你隧道中的網線做了轉發,
為什么要多一個 br1 這個虛擬交換機呢?主要通過 br1 這一層將虛擬機之間的互聯和物理機機之間的互聯分成兩層來設計,中間隧道可以有各種挖法,GRE、VXLAN 都可以,
使用了 OpenvSwitch 之后,br0 可以使用 OpenvSwitch 的 Tunnel 功能和 Flow 功能,
OpenvSwitch 支持三類隧道:GRE、VXLAN、IPsec_GRE,在使用 OpenvSwitch 的時候,虛擬交換機就相當于 GRE 和 VXLAN 封裝的端點,
我們模擬創建一個如下的網路拓撲結構,來看隧道應該如何作業,
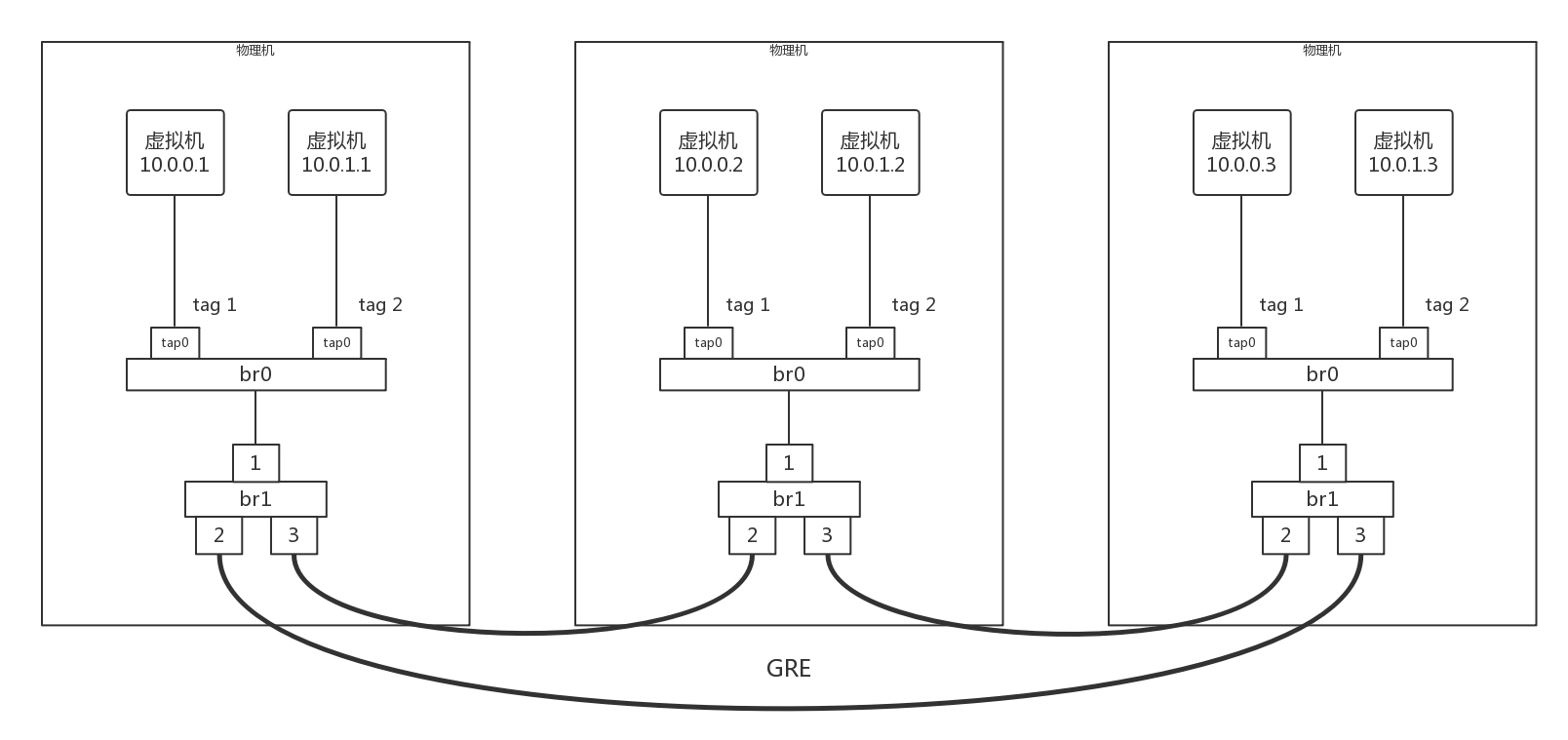
三臺物理機,每臺上都有兩臺虛擬機,分別屬于兩個不同的用戶,因而 VLAN tag 都得打地不一樣,這樣才不能相互通信,但是不同物理機上的相同用戶,是可以通過隧道相互通信的,因而通過 GRE 隧道可以連接到一起,
接下來,所有的 Flow Table 規則都設定在 br1 上,每個 br1 都有三個網卡,其中網卡 1 是對內的,網卡 2 和 3 是對外的,
下面我們具體來看 Flow Table 的設計,
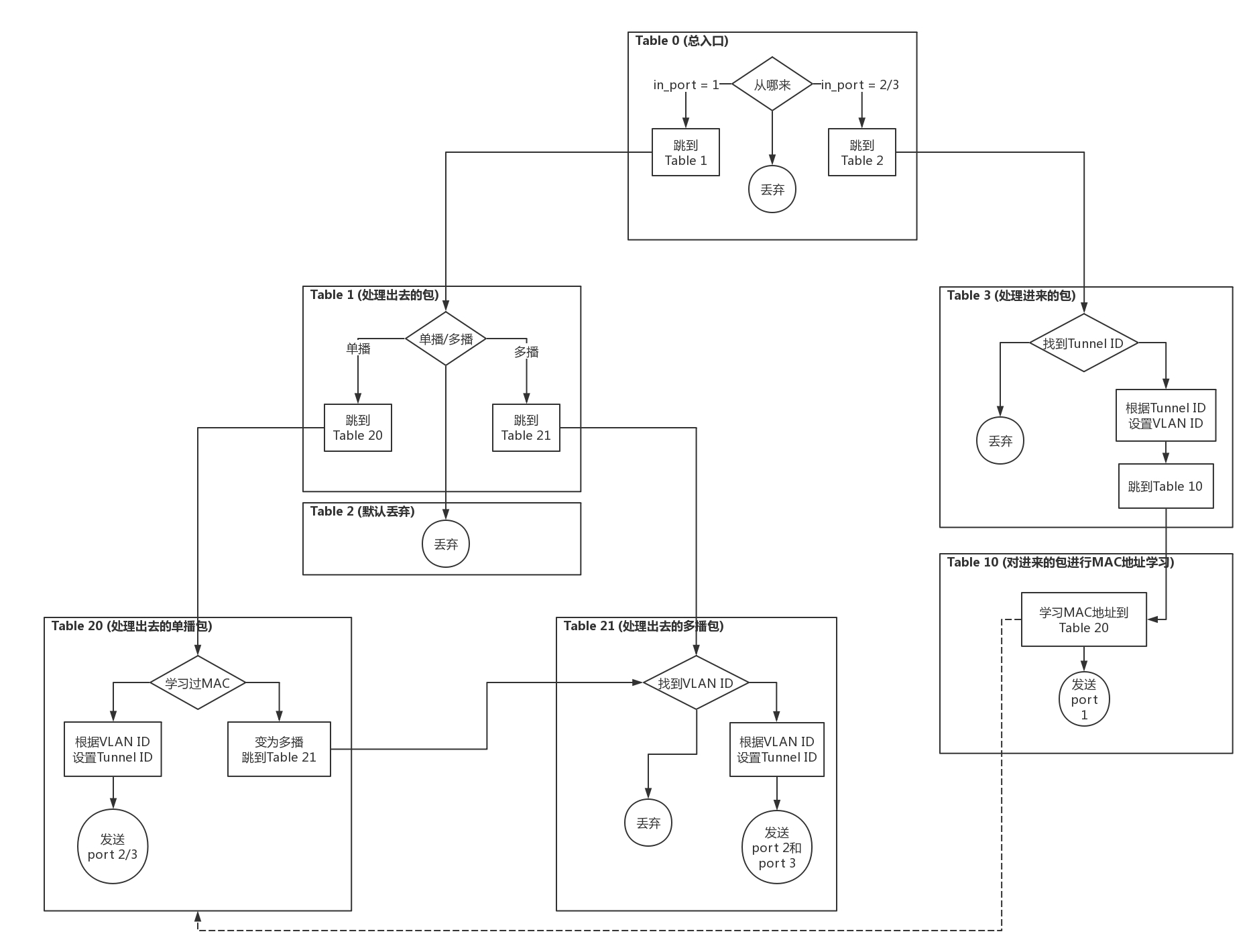
1.Table 0 是所有流量的入口,所有進入 br1 的流量,分為兩種流量,一個是進入物理機的流量,一個是從物理機發出的流量,
從 port 1 進來的,都是發出去的流量,全部由 Table 1 處理,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 in_port=1 actions=resubmit(,1)"
從 port 2、3 進來的,都是進入物理機的流量,全部由 Table 3 處理,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 in_port=2 actions=resubmit(,3)" ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 in_port=3 actions=resubmit(,3)"
如果都沒匹配上,就默認丟棄,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 actions=drop"
2.Table 1 用于處理所有出去的網路包,分為兩種情況,一種是單播,一種是多播,
對于單播,由 Table 20 處理,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=1 dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20)"
對于多播,由 Table 21 處理,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=1 dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,21)"
3.Table 2 是緊接著 Table1 的,如果既不是單播,也不是多播,就默認丟棄,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=2 actions=drop"
4.Table 3 用于處理所有進來的網路包,需要將隧道 Tunnel ID 轉換為 VLAN ID,
如果匹配不上 Tunnel ID,就默認丟棄,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=3 actions=drop"
如果匹配上了 Tunnel ID,就轉換為相應的 VLAN ID,然后跳到 Table 10,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=3 tun_id=0x1 actions=mod_vlan_vid:1,resubmit(,10)" ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1 table=3 tun_id=0x2 actions=mod_vlan_vid:2,resubmit(,10)"
5. 對于進來的包,Table 10 會進行 MAC 地址學習,這是一個二層交換機應該做的事情,學習完了之后,再從 port 1 發出去,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority= table=10 actions=learn(table=20,priority=1,hard_timeout=300,NXM_OF_VLAN_TCI[0..11], NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[], load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]),output:1"
Table 10 是用來學習 MAC 地址的,學習的結果放在 Table 20 里面,Table20 被稱為 MAC learning table,
NXM_OF_VLAN_TCI 是 VLAN tag,在 MAC learning table 中,每一個 entry 都僅僅是針對某一個 VLAN 來說的,不同 VLAN 的 learning table 是分開的,在學習結果的 entry 中,會標出這個 entry 是針對哪個 VLAN 的,
NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[]表示,當前包里面的 MAC Source Address 會被放在學習結果的 entry 里的 dl_dst 里,這是因為每個交換機都是通過進入的網路包來學習的,某個 MAC 從某個 port 進來,交換機就應該記住,以后發往這個 MAC 的包都要從這個 port 出去,因而源 MAC 地址就被放在了目標 MAC 地址里面,因為這是為了發送才這么做的,
load:0->NXM_OF_VLAN_TCI[]是說,在 Table20 中,將包從物理機發送出去的時候,VLAN tag 設為 0,所以學習完了之后,Table 20 中會有 actions=strip_vlan,
load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[]的意思是,在 Table 20 中,將包從物理機發出去的時候,設定 Tunnel ID,進來的時候是多少,發送的時候就是多少,所以學習完了之后,Table 20 中會有 set_tunnel,
output:NXM_OF_IN_PORT[]是發送給哪個 port,例如是從 port 2 進來的,那學習完了之后,Table 20 中會有 output:2,
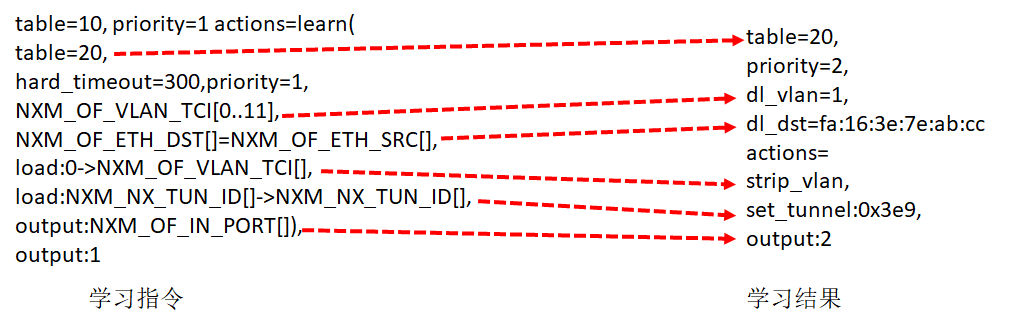
所以如圖所示,通過左邊的 MAC 地址學習規則,學習到的結果就像右邊的一樣,這個結果會被放在 Table 20 里面,
6.Table 20 是 MAC Address Learning Table,如果不為空,就按照規則處理;如果為空,就說明沒有進行過 MAC 地址學習,只好進行廣播了,因而要交給 Table 21 處理,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=20 actions=resubmit(,21)"
7.Table 21 用于處理多播的包,
如果匹配不上 VLAN ID,就默認丟棄,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=0 table=21 actions=drop"
如果匹配上了 VLAN ID,就將 VLAN ID 轉換為 Tunnel ID,從兩個網卡 port 2 和 port 3 都發出去,進行多播,
ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1table=21dl_vlan=1 actions=strip_vlan,set_tunnel:0x1,output:2,output:3" ovs-ofctl add-flow br1 "hard_timeout=0 idle_timeout=0 priority=1table=21dl_vlan=2 actions=strip_vlan,set_tunnel:0x2,output:2,output:3"
-
小結
- 要對不同用戶的網路進行隔離,解決 VLAN 數目有限的問題,需要通過 Overlay 的方式,常用的有 GRE 和 VXLAN,
- GRE 是一種點對點的隧道模式,VXLAN 支持組播的隧道模式,它們都要在某個 Tunnel Endpoint 進行封裝和解封裝,來實作跨物理機的互通,
- OpenvSwitch 可以作為 Tunnel Endpoint,通過設定流表的規則,將虛擬機網路和物理機網路進行隔離、轉換,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/195997.html
標籤:其他
上一篇:熱門技術中的應用-云計算中的網路4-云中網路QoS:鄰居瘋狂下電影,我該怎么辦?
下一篇:Git Unknown SSL protocol error in connection to github.com:443