作者|Mahnoor Javed
編譯|VK
來源|Towards Data Science
電子郵件分類是一個機器學習問題,屬于監督學習范疇,

這個電子郵件分類的小專案的靈感來自J.K.Rowling以筆名出版的一本書,Udacity的“機器學習簡介”提供了演算法和專案的全面研究:https://www.udacity.com/course/intro-to-machine-learning--ud120
幾年前,羅琳寫了一本書《布谷鳥的呼喚》,作者名是羅伯特·加爾布雷思,這本書受到了一些好評,但是沒有人關注它,直到Twitter上的一位匿名線人說這是J.K.羅琳,倫敦《星期日泰晤士報》邀請了兩位專家,將“布谷鳥”的語言模式與羅琳的《臨時空缺》以及其他幾位作者的著作進行了比較,在他們的分析結果強烈指向羅琳是作者之后,《泰晤士報》直接詢問出版商他們是否是同一個人,出版商證實了這一點,這本書一夜之間大受歡迎,
電子郵件分類作業在相同的基本概念上,通過瀏覽電子郵件的文本,我們將使用機器學習演算法來預測電子郵件是由一個人寫的還是另一個人寫的,
資料集
資料集可以從以下GitHub存盤庫獲取:https://github.com/MahnoorJaved98/Email-Classification
在這個資料集中,我們有一組電子郵件,其中一半由同一公司的一個人(Sara)撰寫,另一半由另一個人(Chris)撰寫,資料基于字串串列,每個字串都是電子郵件的文本,經過一些基本的預處理,
我們將根據郵件的文本對郵件進行分類,我們將逐一使用以下演算法:樸素貝葉斯、支持向量機、決策樹、隨機森林、KNN和AdaBoost分類器,
存盤庫有2個pickle檔案:word_data 和email_authors,
email_preprocess python檔案用于處理pickles檔案中的資料,它將資料拆分為10%測驗資料和90%的訓練資料,
樸素貝耶斯
樸素貝耶斯方法是一組基于Bayes定理的有監督學習演算法,在給定類變數值的情況下,假設每對特征之間條件獨立且貢獻相等,Bayes定理是計算條件概率的一個簡單的數學公式,
高斯樸素貝葉斯是一種樸素貝葉斯,其中特征的可能性被假定為高斯,假設與每個特征相關聯的連續值按照高斯分布進行分布,在繪制時,它給出了一條關于特征值平均值對稱的鐘形曲線,

我們將使用scikit學習庫中的Gaussian-naivebayes演算法對兩位作者的郵件進行分類,
下面是你可以在任何python的ide上實作的python代碼,確保你的系統上安裝了所需的庫,
import sys
from time import time
sys.path.append("C:\\Users\\HP\\Desktop\\ML Code\\")
from email_preprocess import preprocess
import numpy as np
# 利用高斯貝葉斯演算法對郵件進行分類
# 演算法是從sklearn庫匯入的
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 初始化測驗和訓練集
# 函式preprocess是從email_preprocess.py匯入的
features_train, features_test, labels_train, labels_test = preprocess()
# 定義分類器
clf = GaussianNB()
# 訓練和測驗時間的預測
t0 = time()
clf.fit(features_train, labels_train)
print("\nTraining time:", round(time()-t0, 3), "s\n")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s\n")
# 計算并列印演算法的準確度
print("Accuracy of Naive Bayes: ", accuracy_score(pred,labels_test))
運行該代碼將得到以下結果:
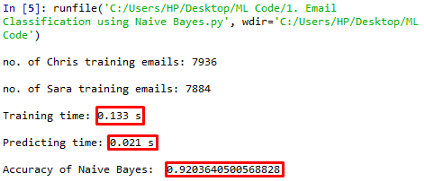
0.9203的準確度,不錯吧?即使是演算法的訓練次數和預測次數也相當合理,
支持向量機
支持向量機也是一種用于分類、回歸和例外檢測的有監督學習,通過一個平面將資料點劃分為兩類,利用SVM演算法將資料點分類為2類,SVM具有一個直接的決策邊界,SVM演算法具有通用性,可為決策函式指定不同的核函式,
SVM演算法是基于超平面的兩類分離,間隔越大,分類越好(也稱為間隔最大化),
我們的分類器是線性核的C支持向量分類,值為C=1
import sys
from time import time
sys.path.append("C:\\Users\\HP\\Desktop\\ML Code\\")
from email_preprocess import preprocess
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是訓練集和測驗集的特征
### labels_train 和 labels_test是對應的標簽
features_train, features_test, labels_train, labels_test = preprocess()
# 定義分類器
clf = SVC(kernel = 'linear', C=1)
# 訓練和測驗時間的預測
t0 = time()
clf.fit(features_train, labels_train)
print("\nTraining time:", round(time()-t0, 3), "s\n")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s\n")
# 計算并列印演算法的準確度
print("Accuracy of SVM Algorithm: ", clf.score(features_test, labels_test))
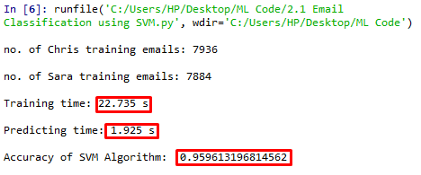
SVM演算法的準確度為0.9596,我們可以看到在準確性和訓練時間之間有明顯的折衷,演算法的準確性提高是訓練時間較長(22.7s,樸素貝葉斯是0.13s)的結果,我們可以減少訓練資料,這樣可以在較少的訓練時間內獲得很好的準確率!
我們將首先將訓練資料集分割到原始大小的1%,以釋放99%的訓練資料,在代碼的其余部分不變的情況下,我們可以看到訓練時間顯著縮短,但是降低了準確性,
使用以下代碼將訓練資料分割為1%:
features_train = features_train[:len(features_train)//100]
labels_train = labels_train[:len(labels_train)//100]
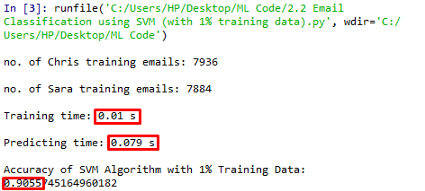
可見,在1%的訓練資料下,演算法的訓練時間縮短到0.01s,精度降低到0.9055,
10%的訓練資料,訓練時間0.47s,準確度為0.9550,
我們也可以改變scikit-learn的C和核,
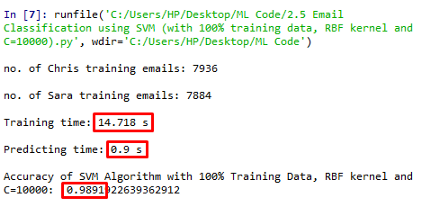
在訓練資料100%,RBF核,C值為10000的情況下,訓練時間為14.718s,得到了0.9891的精度,
決策樹
決策樹是一種用于分類和回歸的非引數監督學習方法,決策樹可以在資料集上執行多類分類,利用從資料特征推斷出的決策規則,對每個節點上的資料進行逐步分類,決策樹很容易可視化,我們可以通過可視化資料集通過樹來理解演算法,并在各個節點做出決定,
讓我們看看這個演算法是如何在我們的資料集上作業的,
import sys
from time import time
sys.path.append("C:\\Users\\HP\\Desktop\\ML Code\\")
from email_preprocess import preprocess
from sklearn import tree
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是訓練集和測驗集的特征
### labels_train 和 labels_test是對應的標簽
features_train, features_test, labels_train, labels_test = preprocess()
# 定義分類器
clf = tree.DecisionTreeClassifier()
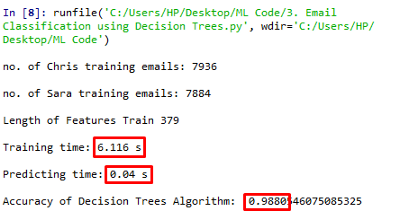
print("\nLength of Features Train", len(features_train[0]))
# 訓練和測驗時間的預測
t0 = time()
clf.fit(features_train, labels_train)
print("\nTraining time:", round(time()-t0, 3), "s\n")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s\n")
# 計算并列印演算法的準確度
print("Accuracy of Decision Trees Algorithm: ", accuracy_score(pred,labels_test))
運行上述代碼,我們的準確度為0.9880,訓練時間為6.116s,這是一個非常好的準確性分數,不是嗎?我們有100%的訓練資料用于訓練模型,
隨機森林

隨機森林是一種基于決策樹的集成監督學習演算法,隨機森林用于回歸和分類任務,該演算法的名字來源于隨機選擇的特征,
我們可以在我們的資料集上使用sklearn庫中的隨機森林演算法:RandomForestClassifier,
下面是在我們的電子郵件分類問題上運行隨機森林演算法的代碼,
import sys
from time import time
sys.path.append("C:\\Users\\HP\\Desktop\\ML Code\\")
from email_preprocess import preprocess
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是訓練集和測驗集的特征
### labels_train 和 labels_test是對應的標簽
features_train, features_test, labels_train, labels_test = preprocess()
# 定義分類器
clf = RandomForestClassifier(max_depth=2, random_state=0)
# 訓練和測驗時間的預測
t0 = time()
clf.fit(features_train, labels_train)
print("\nTraining time:", round(time()-t0, 3), "s\n")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s\n")
# 計算并列印演算法的準確度
print("Accuracy of Random Forest Algorithm: ", accuracy_score(pred,labels_test))
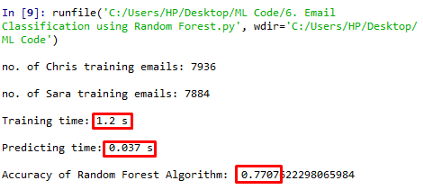
該演算法的精度很低,即0.7707,訓練時間是1.2秒,這是合理的,但總的來說,它并不是解決我們問題的好工具,特征選擇的隨機性是造成精度低的原因,而隨機是隨機森林的一種特性,
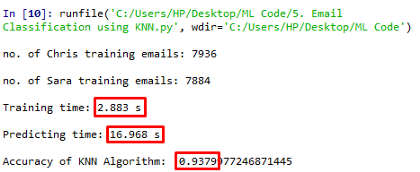
KNN
K近鄰是一種有監督的機器學習演算法,可用于分類和回歸預測問題,KNN是懶惰學習,它依賴于距離進行分類,因此對訓練資料進行規范化可以大大提高分類精度,
讓我們看看使用sklearn庫的KNeighborsClassifier的KNN演算法對電子郵件進行分類的結果,該演算法有5個最近鄰和使用歐幾里德度量,
import sys
from time import time
sys.path.append("C:\\Users\\HP\\Desktop\\ML Code\\")
from email_preprocess import preprocess
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是訓練集和測驗集的特征
### labels_train 和 labels_test是對應的標簽
features_train, features_test, labels_train, labels_test = preprocess()
# 定義分類器
clf = KNeighborsClassifier(n_neighbors=5, metric='euclidean')
# 訓練和測驗時間的預測
t0 = time()
clf.fit(features_train, labels_train)
print("\nTraining time:", round(time()-t0, 3), "s\n")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s\n")
# 計算并列印演算法的精度
print("Accuracy of KNN Algorithm: ", accuracy_score(pred,labels_test))
該演算法的精度為0.9379,訓練時間為2.883s,但是可以注意到,模型工具預測類的時間要長得多,
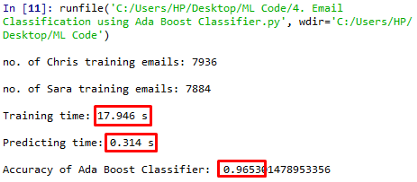
AdaBoost分類器

Ada-boost或自適應Boosting也是一種集成Boosting分類器,它是一種元估計器,首先在原始資料集上擬合一個分類器,然后在同一個資料集上擬合該分類器的附加副本,但是在這種情況下,錯誤分類實體的權重被調整,以便后續分類器更關注困難的情況,
我們將使用scikit庫中的分類器,代碼如下:
import sys
from time import time
sys.path.append("C:\\Users\\HP\\Desktop\\ML Code\\")
from email_preprocess import preprocess
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是訓練集和測驗集的特征
### labels_train 和 labels_test是對應的標簽
features_train, features_test, labels_train, labels_test = preprocess()
# 定義分類器
clf = AdaBoostClassifier(n_estimators=100, random_state=0)
# 訓練和測驗時間的預測
t0 = time()
clf.fit(features_train, labels_train)
print("\nTraining time:", round(time()-t0, 3), "s\n")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s\n")
# 計算并列印演算法的精度
print("Accuracy of Ada Boost Classifier: ", accuracy_score(pred,labels_test))
該分類器的訓練時間為17.946s,精度為0.9653,但訓練時間稍長,
結論
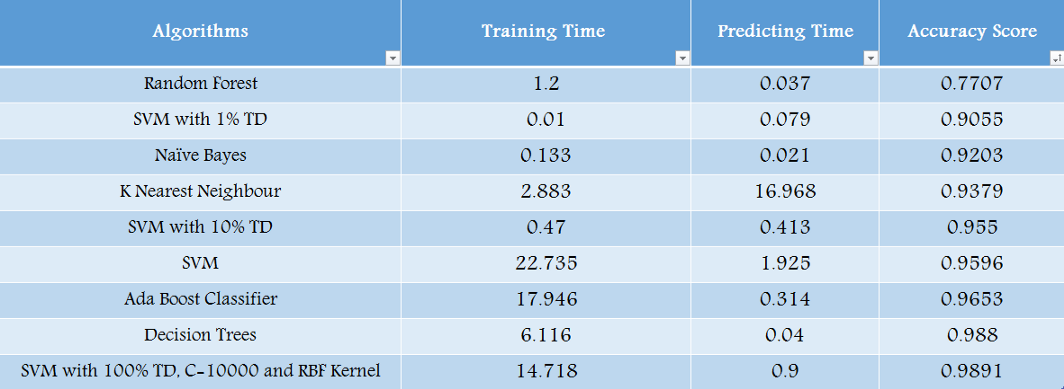
在本文中,我們使用了幾種機器學習演算法來對Chris和Sara之間的電子郵件進行分類,這些演算法在0.77-0.98的范圍內產生了不同的準確度得分,從下表中可以看出,模型是通過提高準確度排列的:
-
隨機森林演算法的準確度得分最低
-
支持向量機演算法訓練時間最長
-
引數優化為C=10000和RBF核的支持向量機演算法的精度得分最高
-
naivebayes演算法的預測時間最快
雖然有許多其他分類演算法可用于我們的任務,但通過對資料集上運行的基本演算法的比較得出結論,對于我們的特定問題,支持向量機是最準確的,因為它的引數是根據我們所處理的任務優化的,
原文鏈接:https://towardsdatascience.com/the-best-machine-learning-algorithm-for-email-classification-39888e7b1846
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/196035.html
標籤:其他
上一篇:神經網路簡史