作者|Conner Brew
編譯|VK
來源|Towards Data Science

介紹
在本文中,我們將創建一個基于戰爭研究所(ISW)的結構化檔案資料庫,ISW為外交和情報專業人員提供資訊產品,以加深對世界各地發生的沖突的了解,
要查看與本文相關聯的原始代碼和Notebook,請訪問以下鏈接:https://colab.research.google.com/drive/1pTrOXW3k5VQo1lEaahCo79AHpyp5ZdfQ?usp=sharing
要訪問Kaggle上托管的最終結構化資料集,請訪問以下鏈接:https://www.kaggle.com/connerbrew2/isw-web-scrape-and-nlp-enrichment
本文將是一個關于web抽取、自然語言處理(NLP)和命名物體識別(NER)的練習,對于NLP,我們將主要使用開源Python庫NLTK和Spacy,
本文旨在演示web提取和NLP的一個用例,而不是關于這兩種技術使用的全面初學者教程,如果你是NLP或web提取的新手,我建議你遵循不同的教程,或者瀏覽Spacy、BeautifulSoup和NLTK檔案頁面,
# 匯入庫
import requests
import nltk
import math
import re
import spacy
import regex as re
import pandas as pd
import numpy as np
import statistics as stats
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import json
# 你需要從NLTK下載一些包,
from bs4 import BeautifulSoup
from nltk import *
nltk.download('stopwords')
nltk.download('punkt')
from nltk.corpus import stopwords
# #在大多數環境中,你需要安裝NER-D,
!pip install ner-d
from nerd import ner
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.cluster import MiniBatchKMeans
from sklearn.feature_extraction.text import TfidfVectorizer
初始化變數
首先,我們將初始化最終結構化資料中需要的資料欄位,對于每個檔案,我要提取標題、發布日期、人名、地名和其他各種資訊,我們還將增強檔案中已經存在的資訊—例如,我們將使用檔案中的地名來獲取相關的坐標,這對于以后可視化資料非常有用,
# 初始化最終資料集的資料欄位
dates=[]
titles=[]
locations=[]
people=[]
key_countries=[]
content_text=[]
links=[]
coord_list=[]
mentioned_countries=[]
keywords=[]
topic_categories=[]
# 為后面的主題模型初始化簇變數
cluster_keywords=[]
cluster_number=[]
# 使用SPACY庫初始化NLP物件
nlp = spacy.load("en_core_web_sm")
提取href
我們將從ISW的生產庫中提取檔案,首先,我們將抓取“瀏覽”頁面以獲取每個產品的單獨href鏈接,然后我們將這些鏈接存盤在一個串列中,供提取函式稍后訪問,
# #從ISW瀏覽頁面獲取產品鏈接
urls=['http://www.understandingwar.org/publications?page={}'.format(i) for i in range(179)]
hrefs=[]
def get_hrefs(page,class_name):
page=requests.get(page)
soup=BeautifulSoup(page.text,'html.parser')
container=soup.find_all('div',{'class':class_name})
container_a=container[0].find_all('a')
links=[container_a[i].get('href') for i in range(len(container_a))]
for link in links:
if link[0]=='/':
hrefs.append('http://www.understandingwar.org'+link)
for url in urls:
get_hrefs(url,'view-content')
Web爬取
我們將要撰寫的前幾個函式是相當簡單的文本提取,本教程不是關于BeautifulSoup用法的教程,要了解Python中的web爬取,請查看這里的檔案:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
獲得日期
對于我們的第一個函式,我們將提取發布日期,它掃描從產品網頁中提取的html檔案,并找到一個類為“submitted”的欄位,這是我們的生產日期,
獲得標題
接下來,我們需要產品名稱,同樣,這個欄位被方便地標記為“title”類,
獲取所有文本
最后,我們將提取檔案的全文,當我提取文本時,我通常遵循“先提取,后過濾”的web提取方式,這意味著,在最初的文本提取中,我對文本執行最少的過濾和處理,我更愿意在以后的分析中進行處理,因為這是必要的,但是,如果你想更進一步,你可能希望對提取的文本進行比下面函式演示的更多的預處理,
對于我的get_contents函式,我堅持最基本的原則——我在黑名單中列出了一些不想被提取的文本,然后從頁面中提取所有文本并將其附加到一個臨時字串中,該字串又被附加到串列content_text中,
# 提取發布資料
def get_date(soup):
try:
data=https://www.cnblogs.com/panchuangai/archive/2020/10/29/soup.find('span',{'class':'submitted'})
content=data.find('span')
date=content.get('content')
dates.append(date)
except Exception:
dates.append('')
pass
# 提取產品標題
def get_title(soup):
try:
title=soup.find('h1',{'class':'title'}).contents
titles.append(title[0])
except Exception:
titles.append('')
pass
# 提取產品的文本內容
def get_contents(soup):
try:
parents_blacklist=['[document]','html','head',
'style','script','body',
'div','a','section','tr',
'td','label','ul','header',
'aside',]
content=''
text=soup.find_all(text=True)
for t in text:
if t.parent.name not in parents_blacklist and len(t) > 10:
content=content+t+' '
content_text.append(content)
except Exception:
content_text.append('')
pass
自然語言處理
接下來,我們將找出產品中參考了哪些國家,有很多API可以用于檢查國家的文本內容,但這里我們將使用一個簡單的方法:列出世界上所有國家的串列,這個串列來自維基百科:https://en.wikipedia.org/wiki/Lists_of_countries_and_territories
在函式得到all_mentioned_countries 后,它使用基本統計分析來確定哪些國家最突出——這些國家最有可能成為檔案敘述的焦點,為此,該函式計算整個檔案中提到一個國家的次數,然后查找比平均值提到次數多的國家,然后將這些國家追加到key_countries串列中,
# 在正文中參考所有國家的串列,
# 如果文本中的一個單詞與串列中的一個國家匹配,那么它將被添加到國家串列中,
def get_countries(content_list):
iteration=1
for i in range(len(content_list)):
print('Getting countries',iteration,'/',len(content_list))
temp_list=[]
for word in word_tokenize(content_list[i]):
for country in country_list:
if word.lower().strip() == country.lower().strip():
temp_list.append(country)
counted_countries=dict(Counter(temp_list))
temp_dict=dict.fromkeys(temp_list,0)
temp_list=list(temp_dict)
if len(temp_list)==0:
temp_list.append('Worldwide')
mentioned_countries.append(temp_list)
# 計算每個國家被提及的次數,然后對照平均值檢查每次計數,
# 如果一個國家被提及的次數超過了平均次數,它就會作為一個關鍵字被記錄,
keywords=[]
for key in counted_countries.keys():
if counted_countries[key] > np.mean(list(counted_countries.values())):
keywords.append(key)
if len(keywords) != 0:
key_countries.append(keywords)
else:
key_countries.append(temp_list)
iteration+=1
命名物體識別:地點
接下來,我們要豐富我們的資料,最終,結構化資料的目標通常是執行某種分析或可視化——在這種國際沖突資訊的情況下,將資訊按地理位置繪制出來是很有價值的,為此,我們需要與檔案對應的坐標,
找到地名
首先,我們將使用自然語言處理(NLP)和命名物體識別(NER)從文本中提取地名,
NLP是機器學習的一種形式,計算機演算法使用語法和語法規則來學習文本中單詞之間的關系,通過這種學習,NER能夠理解某些單詞在句子或段落中所起的作用,本教程并不打算全面介紹NLP—對于這樣的資源,請查看:https://medium.com/@ODSC/an-introduction-to-natural-language-processing-nlp-8e476d9f5f59
從外部API獲取坐標
為了找到地名的坐標,我們將使用 Open Cage API查詢坐標;你可以在這里創建一個免費帳戶并接收API密鑰,還有許多其他流行的地理api可供選擇,但通過反復試驗,我發現Open-Cage在中東地區有著最好的性能,
首先,我們迭代從檔案中檢索到的每個地名,并在Open Cage中查詢它,一旦完成這項作業,我們將對比Open Cage與先前創建的mentioned_countries 串列,這將確保我們檢索的查詢結果位于正確的位置,
# 使用NLP提取地名,然后查詢open-cage API以獲得繪圖所需的坐標
# 插入你自己的OpenCage API key:
geo_api_key='Insert Your API Key Here'
def get_coords(content_list):
iteration=1
for i in range(len(content_list)):
print('Getting coordinates',iteration,'/',len(content_list))
temp_list=[]
text=content_list[i]
# 應用一個NER演算法,從python庫'ner-d'中查找地名,
doc=nlp(text)
location=[X.text for X in doc.ents if X.label_ == 'GPE']
location_dict=dict.fromkeys(location,0)
location=list(location_dict)
# 查詢位置,
for l in location:
try:
request_url='https://api.opencagedata.com/geocode/v1/json?q={}&key={}'.format(l,geo_api_key)
page=requests.get(request_url)
data=https://www.cnblogs.com/panchuangai/archive/2020/10/29/page.json()
for n in range(len(data)):
# 這行代碼檢查查詢結果中的國家是否與mentioned_countries之一相匹配,如果不是,那么查詢結果很可能是假正例,
if data['results'][n]['components']['country'] in mentioned_countries[i]:
lat=data['results'][n]['geometry']['lat']
lng=data['results'][n]['geometry']['lng']
coordinates={'Location': l,
'Lat': lat,
'Lon': lng}
temp_list.append(coordinates)
break
else:
continue
except Exception:
continue
coord_list.append(temp_list)
iteration+=1
命名物體識別:人
接下來,我們將提取檔案中提到的人的姓名,為此,我們將再次使用NER-d python庫中的NER演算法,
獲取全名
在最終的結構化資料中,我只想要全名,只找到“Jack”或“John”的資料,會不會令人困惑?為此,我們將再次使用一些基本的統計資料,當提到全名時,函式將跟蹤全名,通常是在文本的開頭,
當后面提到部分名稱時,它將參考全名串列,以標識部分名稱參考的是誰,例如,如果一篇新聞文章是這樣寫的:“喬·拜登正在競選總統,喬是前總統奧巴馬的副總統,我們知道喬指的是拜登,因為他的全名在文中早些時候已經給出,此函式將以相同的方式運行,
重復的名字
如果出現了重復的情況,該函式將使用前面用于國家/地區函式的相同統計資料,它將測量一個名字被提及的次數,并將其作為最有可能的名字,例如:喬·拜登和他的兒子亨特·拜登都是受歡迎的美國政治家,喬·拜登是前副總統,拜登現在正在與現任總統唐納德·特朗普競選總統”,根據文本的統計重點,這篇文章顯然是關于喬·拜登,而不是亨特·拜登,
驗證名字
一旦函式計算出所有提到的全名,它將把它們添加到一個串列中,然后,它將查詢維基百科中的每個名字,以驗證它是否是值得包含在結構化資料中的有影響力的人的名字,
def get_people(content_list):
iteration=1
# 使用NER在文本中查找人名,
for i in range(len(content_list)):
print('Getting people',iteration,'/',len(content_list))
temp_list=[]
text=content_list[i]
doc=nlp(text)
persons=[X.text for X in doc.ents if X.label_ == 'PERSON']
persons_dict=dict.fromkeys(persons,0)
persons=list(persons_dict)
full_names=[]
for person in persons:
if len(word_tokenize(person)) >= 2:
string_name=re.sub(r"[^a-zA-Z0-9]+", ' ', person).strip()
full_names.append(string_name)
final_names=[]
for person in persons:
for name in full_names:
tokens=word_tokenize(name)
for n in range(len(tokens)):
if person==tokens[n]:
final_names.append(name)
for name in full_names:
final_names.append(name)
name_dict=dict.fromkeys(final_names,0)
final_names=list(name_dict)
valid_names=[]
for name in final_names:
page=requests.get('https://en.wikipedia.org/wiki/'+name)
if page.status_code==200:
valid_names.append(name)
people.append(valid_names)
iteration+=1
關鍵詞提取:TF-IDF
我們的下一個任務是從文本中提取關鍵字,最常見的方法是使用一種稱為TF-IDF的方法,TF-IDF模型測量單個檔案中單詞的使用頻率,然后將其與整個檔案語料庫中的平均使用率進行比較,
如果一個術語在單個檔案中頻繁使用,并且很少在整個檔案語料庫中使用,那么該術語很可能表示該特定檔案特有的關鍵字,這篇文章并不是一篇關于TF-IDF模型的全面概述,要了解更多資訊,請查看這篇關于Medium的文章:https://medium.com/datadriveninvestor/tf-idf-in-natural-language-processing-8db8ef4a7736
首先,我們的函式將創建通常所說的“詞袋”,這將跟蹤每個檔案中使用的每個單詞,然后,它將計算每個檔案中每個單詞的每次使用次數—單詞頻率(TF),然后,它計算逆檔案頻率(IDF),然后將這些值寫入矩陣中的坐標,然后對矩陣進行排序,以幫助我們找到最有可能表示檔案的單詞,
# 第一個函式通過降低字符大小寫和洗掉特殊字符對文本進行預處理,
def pre_process(text):
text=text.lower()
text=re.sub("</?.*?>"," <> ",text)
text=re.sub("(\\d|\\W)+"," ",text)
return text
# 這個函式將矩陣映射到坐標,TF-IDF函式將頻率分數映射到矩陣,然后需要對這些矩陣進行排序,以幫助我們找到關鍵字,
def sort_coo(coo_matrix):
tuples = zip(coo_matrix.col, coo_matrix.data)
return sorted(tuples, key=lambda x: (x[1], x[0]), reverse=True)
# 與上面一樣,這是一個幫助函式,一旦頻率映射到矩陣,它將幫助排序和選擇關鍵字,
# 這個函式專門幫助我們根據TF-IDF統計資料選擇最相關的關鍵字
def extract_topn_from_vector(feature_names, sorted_items, topn=10):
sorted_items = sorted_items[:topn]
score_vals = []
feature_vals = []
for idx, score in sorted_items:
fname = feature_names[idx]
score_vals.append(round(score, 3))
feature_vals.append(feature_names[idx])
results= {}
for idx in range(len(feature_vals)):
results[feature_vals[idx]]=score_vals[idx]
return results
#最后一個函式包含了上述helper函式,它對正文應用TF-IDF演算法,根據使用頻率查找關鍵字,
def get_keywords(content_list):
iteration=1
processed_text=[pre_process(text) for text in content_list]
stop_words=set(stopwords.words('english'))
cv=CountVectorizer(max_df=0.85,stop_words=stop_words)
word_count_vector=cv.fit_transform(processed_text)
tfidf_transformer=TfidfTransformer(smooth_idf=True,use_idf=True)
tfidf_transformer.fit(word_count_vector)
feature_names=cv.get_feature_names()
for i in range(len(processed_text)):
print('Getting Keywords',iteration,'/',len(content_list))
doc=processed_text[i]
tf_idf_vector=tfidf_transformer.transform(cv.transform([doc]))
sorted_items=sort_coo(tf_idf_vector.tocoo())
keys=extract_topn_from_vector(feature_names,sorted_items,10)
keywords.append(list(keys.keys()))
iteration+=1
主題模型
NLP中最常見的任務之一就是主題模型,這是一種聚類形式,它嘗試根據檔案的文本內容自動對檔案進行分類,在這個具體的例子中,我想一眼就知道ISW涉及哪些主題,通過根據文本內容對檔案進行分類,我可以輕松地對檔案的主要思想有一個大致的了解,
向量化
對于這個例子,我將使用k-means聚類演算法來進行主題建模,首先,我將再次使用TF-IDF演算法對每個檔案進行向量化,向量化是一個機器學習術語,指的是將非數字資料轉換成計算機可以用來執行機器學習任務的數字空間資料,
優化
一旦檔案被向量化,helper函式就會檢查簇的最佳數量,(k表示k-means的k),在本例中,最佳數目是50,一旦我找到了最佳的數字,在這個例子中,我注釋掉了這行代碼,并手動將引數調整為等于50,這是因為我正在分析的資料集不會經常更改,所以我可以期望隨著時間的推移,最佳簇的數量會保持不變,對于變化更頻繁的資料,你應該回傳最佳的簇數量作為變數-這將幫助你的聚類演算法自動設定其最佳引數,我在我的時間序列分析文章中展示了一個例子,
聚類
每個簇完成后,我將每個簇的編號(1–50)保存到簇編號的串列中,而組成每個簇的關鍵字保存到cluster_keywords的串列中,這些簇關鍵字稍后將用于向每個主題簇添加標題,
# 該函式根據各種“k”引數檢查聚類演算法,以找到“k”的最優值,
def find_optimal_clusters(data, max_k):
iters = range(2, max_k+1, 2)
sse = []
for k in iters:
sse.append(MiniBatchKMeans(n_clusters=k,
init_size=1024,
batch_size=2048,
random_state=20).fit(data).inertia_)
print('Fit {} clusters'.format(k))
f, ax = plt.subplots(1, 1)
ax.plot(iters, sse, marker='o')
ax.set_xlabel('Cluster Centers')
ax.set_xticks(iters)
ax.set_xticklabels(iters)
ax.set_ylabel('SSE')
ax.set_title('SSE by Cluster Center Plot')
# 從內容串列中獲取關鍵詞來幫助對主題模型的分類
def get_top_keywords(data, clusters, labels, n_terms):
df = pd.DataFrame(data.todense()).groupby(clusters).mean()
for i,r in df.iterrows():
cluster_keywords.append(','.join([labels[t] for t in np.argsort(r)[-n_terms:]]))
# 應用于主題建模的內容串列
def get_topics(content_list):
processed_text=[pre_process(text) for text in content_list]
stop_words=set(stopwords.words('english'))
cv=CountVectorizer(max_df=0.85,stop_words=stop_words)
word_count_vector=cv.fit_transform(processed_text)
tfidf_transformer=TfidfTransformer(smooth_idf=True,use_idf=True)
tfidf_transformer.fit(word_count_vector)
feature_names=cv.get_feature_names()
vector=tfidf_transformer.transform(cv.transform(processed_text))
#find_optimal_clusters(vector,50)
clusters = MiniBatchKMeans(n_clusters=50, init_size=1024, batch_size=2048, random_state=20).fit_predict(vector)
for cluster in clusters:
cluster_number.append(int(cluster))
get_top_keywords(vector, clusters, cv.get_feature_names(), 20)
放在一起
最后,我們將提取我們的資料,使用我們之前得到的href串列,現在是將所有提取函式應用于web內容的時候了,
# 遍歷從“browse”中提取的href,提取相關內容
iteration=1
# 前幾個函式依賴于原始提取的web內容作為引數,這些都是基本的web抓取技術,
for href in hrefs:
print('Web scraping: iteration',iteration,'/',len(hrefs))
page=requests.get(href)
soup=BeautifulSoup(page.text,'html.parser')
links.append(href)
get_date(soup)
get_title(soup)
get_contents(soup)
iteration+=1
# 下面這些函式依賴于文本主體作為引數,
# 這些是基于nlp的函式,
# 注意:由于查詢外部API,
# 需要一個超時來阻止服務器過載,
# 這部分代碼的運行時間很長,
get_countries(content_text)
get_coords(content_text)
get_people(content_text)
get_keywords(content_text)
get_topics(content_text)
豐富主題模型
我們的下一個問題是:我們的簇為我們提供了一個與每個簇相關聯的單詞串列,但是簇的名稱僅僅是數字,這使我們有機會繪制一個詞云或其他有趣的可視化圖,可以幫助我們理解每個簇,但對于結構化資料集中的一目了然的理解來說,它并沒有那么有用,另外,我認為有些檔案可能屬于多個主題類別,k-means不支持多重聚類,因此我必須手動識別這些檔案,首先,我將列印前幾行關鍵字,以了解我正在處理的資料,

與每個主題相關聯的一些關鍵字,我們將使用這些關鍵字將簇分類到預定義的類別中,
在對各種技術進行了大量實驗之后,我決定采用一種非常簡單的方法,我掃描了與每個簇相關的每個關鍵字串列,并在每個與特定主題相關的關鍵字中記錄了重要的關鍵字,在這個階段,領域知識是關鍵,例如,我知道,ISW檔案中的阿勒頗幾乎肯定提到了敘利亞內戰,對于你的資料,如果你缺乏適當的領域知識,你可能需要做進一步的研究,咨詢你團隊中的其他人,或者定義一個更高級的編程方法來命名簇,
然而,對于這個例子,簡單的方法很有效,在記錄了簇串列中存在的幾個重要關鍵字之后,我自己制作了幾個串列,其中包含了與結構化資料中我想要的最終主題類別相關聯的關鍵字,該函式簡單地將每個簇的關鍵字串列與我創建的串列進行比較,然后根據串列中的匹配項分配主題名稱,然后將這些最后的主題附加到主題類別串列中,
#搜索與主題對應的關鍵詞串列,與聚類詞庫交叉參考,為每篇文章分配一個主題類別,
oir=['OIR Iraq','yezidis','mosul','peshmerga','isis','iraq','sinjar','baghdad','maliki',
'daquq','anbar','isf','abadi','malaki','ramadi','iraqi','fallujah','dabiq']
terrorism=['Terrorism','jihadi','islamic','salafi','qaeda',
'caliphate','isis','terrorist','terrorism']
syrian_conflict=['Syrian Conflict','sana','syria','assad',
'idlib','afrin','aleppo']
russia=['Russia','russia','belarus','slavic','kremlin','russian',
'minsk','ukraine','putin']
iran=['Iran','iran','iranian','proxy','militias','militia','marjah']
turkey=['Turkey','erdogan','turkish','turkey']
ors=['ORS','kabul','ghani','pakistan','afghan','afghanistan',
'taliban','ansf','karzai','helmand']
africa=['Africa','libya','libyan','egypt','egyptian','africa','african']
cat_list=[oir,terrorism,syrian_conflict,russia,iran,turkey,ors,africa]
topic_dict={}
for i in range(len(cluster_keywords)):
temp_list=[]
for n in nltk.word_tokenize(cluster_keywords[i]):
for item in cat_list:
if n in item:
temp_list.append(item[0])
temp_dict=dict.fromkeys(temp_list,0)
temp_list=list(temp_dict)
topic_dict[i] = temp_list
for num in cluster_number:
topic_categories.append(topic_dict[num])
資料庫創建
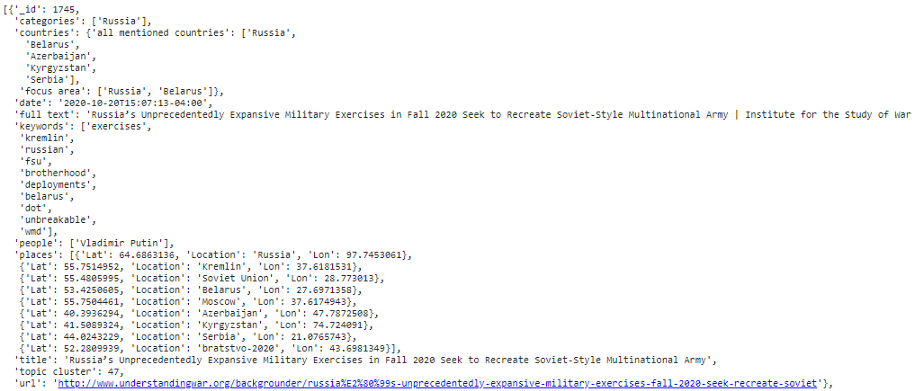
最后一步是將我們提取的所有資料集中起來,對于這些資料,我更喜歡JSON格式,這是因為我想以不同的方式組織某些型別的資料—例如,locations欄位將包含地名、緯度和經度的字典串列,在我看來,JSON格式是將這種格式化的資料存盤到本地磁盤的最有效的方法,我還在檔案資料庫MongoDB中備份了這個資料庫的副本,但這不是本文的重點,
#將一個空串列初始化
db=[]
for i in range(len(hrefs)):
countries={
'focus area': key_countries[i],
'all mentioned countries': mentioned_countries[i]
}
# 將函式中定義的所有串列添加到新的存盤串列中
doc={
'_id': len(hrefs) - i,
'title': titles[i],
'date': dates[i],
'places': coord_list[i],
'people': people[i],
'keywords': keywords[i],
'countries': countries,
'full text': content_text[i],
'url': links[i],
'topic cluster': cluster_number[i],
'categories': topic_categories[i]
}
db.append(doc)
# 將串列保存為谷歌驅動器內的.JSON資料存盤檔案(用于演示目的)
with open ('/content/drive/My Drive/Colab Notebooks/isw_products.json', 'w') as fout:
json.dump(db, fout)
摘要
現在我們結束了!我們從網頁中提取鏈接,然后使用這些鏈接從網站中提取更多內容,我們使用這些內容,然后使用外部api、ML簇演算法和NLP來提取和增強這些資訊,TF-IDF向量化、關鍵字提取和主題模型,這些是NLP的基石,如果你有更多問題或需要資訊,請聯系我們,祝你在未來的NLP中好運!
原文鏈接:https://towardsdatascience.com/something-from-nothing-use-nlp-and-ml-to-extract-and-structure-web-data-3f49b2f72b13
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/196036.html
標籤:其他
上一篇:電子郵件分類的最佳機器學習演算法
下一篇:神經網路簡史