作者|Shraddha Anala
編譯|VK
來源|Towards Data Science
無論我們是誰,閱讀、理解、交流并最終產生新的內容是我們在職業生活中都要做的事情,
當涉及到從給定的文本體中提取有用的特征時,所涉及的程序與連續整數向量(詞袋)相比是根本不同的,這是因為句子或文本中的資訊是以結構化的順序編碼的,單詞的語意位置傳達了文本的意思,
因此,在保持文本的背景關系意義的同時,對資料進行適當表示的雙重要求促使我學習并實作了兩種不同的NLP模型來實作文本分類的任務,
詞嵌入是文本中單個單詞的密集表示,考慮到背景關系和其他與之相關的單詞,
與簡單的詞袋模型相比,該實值向量可以更有效地選擇維數,更有效地捕捉詞與詞之間的語意關系,
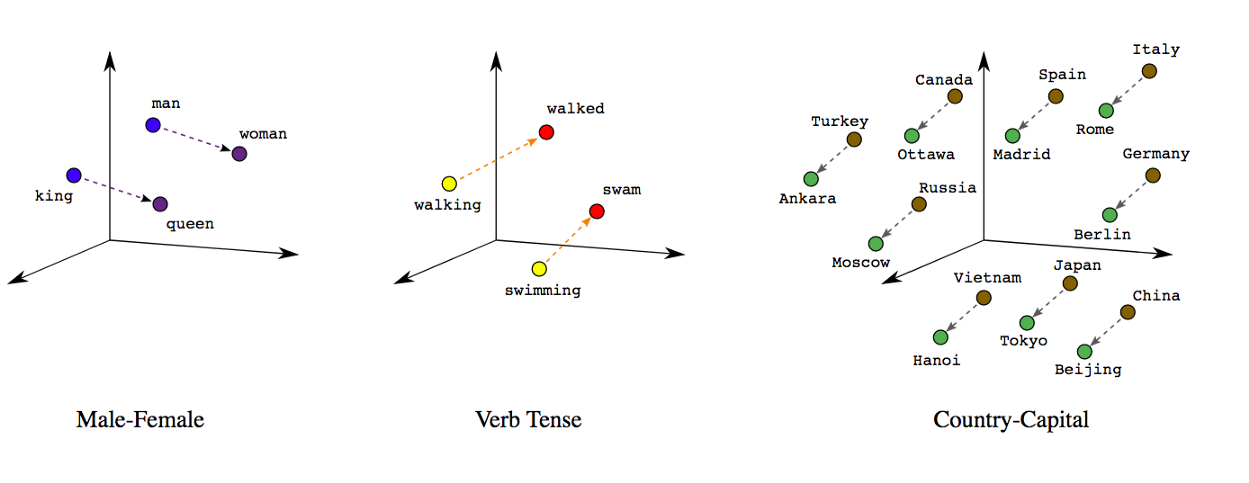
簡單地說,具有相似含義或經常出現在相似背景關系中的詞,將具有相似的向量表示,這取決于這些詞在其含義中的“接近”或“相距”有多遠,
在本文中,我將探討兩個詞的嵌入-
- 訓練我們自己的嵌入
- 預訓練的GloVe 詞嵌入
資料集
對于這個案例研究,我們將使用Kaggle的Stack Overflow 資料集(https://www.kaggle.com/imoore/60k-stack-overflow-questions-with-quality-rate),這個資料集包含了6萬個用戶在網站上提出的問題,主要任務是將問題分為3類,
現在讓我們看看這個多分類NLP專案的實際模型本身,
但是,在開始之前,請確保你已經安裝了這些包/庫,
pip install gensim # 用于NLP預處理任務
pip install keras # 嵌入層
1. 訓練詞嵌入
如果你希望跳過解釋,請訪問第一個模型的完整代碼:https://github.com/shraddha-an/nlp/blob/main/word_embedding_classification.ipynb
1) 資料預處理
在第一個模型中,我們將訓練一個神經網路來從我們的文本語料庫中學習嵌入,具體地說,我們將使用Keras庫為神經網路的嵌入層提供詞標識及其索引,
在訓練我們的網路之前,必須確定一些關鍵引數,這些包括詞匯的大小或語料庫中唯一單詞的數量以及嵌入向量的維數,
以下鏈接是用于訓練和測驗的資料集,現在我們將匯入它們,只保留問題和質量列以供分析:https://www.kaggle.com/imoore/60k-stack-overflow-questions-with-quality-rate
我還更改了列名并定義了一個函式text_clean來清理問題,
# 匯入庫
# 資料操作/處理
import pandas as pd, numpy as np
# 可視化
import seaborn as sb, matplotlib.pyplot as plt
# NLP
import re
from nltk.corpus import stopwords
from gensim.utils import simple_preprocess
stop_words = set(stopwords.words('english'))
# 匯入資料集
dataset = pd.read_csv('train.csv')[['Body', 'Y']].rename(columns = {'Body': 'question', 'Y': 'category'})
ds = pd.read_csv('valid.csv')[['Body', 'Y']].rename(columns = {'Body': 'question', 'Y': 'category'})
# 清理符號和HTML標簽
symbols = re.compile(pattern = '[/<>(){}\[\]\|@,;]')
tags = ['href', 'http', 'https', 'www']
def text_clean(s: str) -> str:
s = symbols.sub(' ', s)
for i in tags:
s = s.replace(i, ' ')
return ' '.join(word for word in simple_preprocess(s) if not word in stop_words)
dataset.iloc[:, 0] = dataset.iloc[:, 0].apply(text_clean)
ds.iloc[:, 0] = ds.iloc[:, 0].apply(text_clean)
# 訓練和測驗集
X_train, y_train = dataset.iloc[:, 0].values, dataset.iloc[:, 1].values.reshape(-1, 1)
X_test, y_test = ds.iloc[:, 0].values, ds.iloc[:, 1].values.reshape(-1, 1)
# one-hot編碼
from sklearn.preprocessing import OneHotEncoder as ohe
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer(transformers = [('one_hot_encoder', ohe(categories = 'auto'), [0])],
remainder = 'passthrough')
y_train = ct.fit_transform(y_train)
y_test = ct.transform(y_test)
# 設定引數
vocab_size = 2000
sequence_length = 100
如果你瀏覽原始資料集,你會發現HTML標記中包含的問題,例如,
…question
,此外,還有一些詞,如href,https等,在整個文本中都有,所以我要確保從文本中洗掉這兩組不需要的字符,Gensim的simple_preprocess方法回傳一個小寫的標記串列,去掉重音符號,
在這里使用apply方法將通過預處理函式迭代運行每一行,并在繼續下一行之前回傳輸出,對訓練和測驗資料集應用文本預處理功能,
因為在因變數向量中有3個類別,我們將應用one-hot編碼并初始化一些引數以備以后使用,
2) 標識化
接下來,我們將使用Keras Tokenizer類將單詞組成的問題轉換成一個陣列,用它們的索引表示單詞,
因此,我們首先必須使用fit_on_texts方法,從資料集中出現的單詞構建索引詞匯表,
在建立詞匯表之后,我們使用text_to_sequences方法將句子轉換成表示單詞的數字串列,
pad_sequences函式確保所有觀察值的長度相同,可以設定為任意數字或資料集中最長問題的長度,
我們先前初始化的vocab_size引數只是我們詞匯表的大小(用于學習和索引),
# Keras的標識器
from keras.preprocessing.text import Tokenizer
tk = Tokenizer(num_words = vocab_size)
tk.fit_on_texts(X_train)
X_train = tk.texts_to_sequences(X_train)
X_test = tk.texts_to_sequences(X_test)
# 用0填充所有
from keras.preprocessing.sequence import pad_sequences
X_train_seq = pad_sequences(X_train, maxlen = sequence_length, padding = 'post')
X_test_seq = pad_sequences(X_test, maxlen = sequence_length, padding = 'post')
3) 訓練嵌入層
最后,在這一部分中,我們將構建和訓練我們的模型,它由兩個主要層組成,一個嵌入層將學習上面準備的訓練檔案,以及一個密集的輸出層來實作分類任務,
嵌入層將學習單詞的表示,同時訓練神經網路,需要大量的文本資料來提供準確的預測,在我們的例子中,45000個訓練觀察值足以有效地學習語料庫并對問題的質量進行分類,我們將從指標中看到,
# 訓練嵌入層和神經網路
from keras.models import Sequential
from keras.layers import Embedding, Dense, Flatten
model = Sequential()
model.add(Embedding(input_dim = vocab_size, output_dim = 5, input_length = sequence_length))
model.add(Flatten())
model.add(Dense(units = 3, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
model.summary()
history = model.fit(X_train_seq, y_train, epochs = 20, batch_size = 512, verbose = 1)
# 完成訓練后保存模型
#model.save("model.h5")
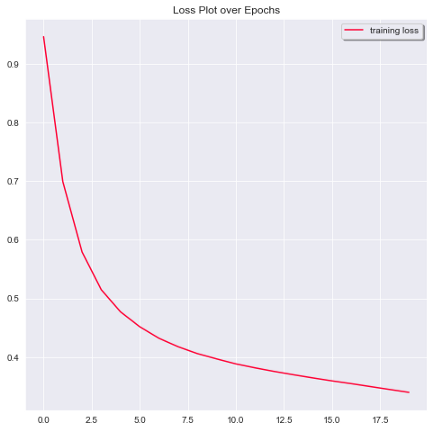
4) 評估和度量圖
剩下的就是評估我們的模型的性能,并繪制圖來查看模型的準確性和損失指標是如何隨時間變化的,
我們模型的性能指標顯示在下面的螢屏截圖中,

代碼與下面顯示的代碼相同,
# 在測驗集上評估模型的性能
loss, accuracy = model.evaluate(X_test_seq, y_test, verbose = 1)
print("\nAccuracy: {}\nLoss: {}".format(accuracy, loss))
# 畫出準確度和損失
sb.set_style('darkgrid')
# 1) 準確度
plt.plot(history.history['accuracy'], label = 'training', color = '#003399')
plt.legend(shadow = True, loc = 'lower right')
plt.title('Accuracy Plot over Epochs')
plt.show()
# 2) 損失
plt.plot(history.history['loss'], label = 'training loss', color = '#FF0033')
plt.legend(shadow = True, loc = 'upper right')
plt.title('Loss Plot over Epochs')
plt.show()
以下是訓練中準確度的提高

20個epoch的損失圖
2.預訓練的GloVe詞嵌入
如果你只想運行模型,這里有完整的代碼:https://github.com/shraddha-an/nlp/blob/main/pretrained_glove_classification.ipynb
代替訓練你自己的嵌入,另一個選擇是使用預訓練好的詞嵌入,比如GloVe或Word2Vec,在這一部分中,我們將使用在Wikipedia+gigaword5上訓練的GloVe詞嵌入;從這里下載:https://nlp.stanford.edu/projects/glove/
i) 選擇一個預訓練的詞嵌入,如果
你的資料集是由更“通用”的語言組成的,一般來說你沒有那么大的資料集,
由于這些嵌入已經根據來自不同來源的大量單詞進行了訓練,如果你的資料也是通用的,那么預訓練的模型可能會做得很好,
此外,通過預訓練的嵌入,你可以節省時間和計算資源,
ii)選擇訓練你自己的嵌入,如果
你的資料(和專案)是基于一個利基行業,如醫藥、金融或任何其他非通用和高度特定的領域,
在這種情況下,一般的詞嵌入表示法可能不適合你,并且一些單詞可能不在詞匯表中,
需要大量的領域資料來確保所學的詞嵌入能夠正確地表示不同的單詞以及它們之間的語意關系
此外,它需要大量的計算資源來瀏覽你的語料庫和建立詞嵌入,
最終,是根據已有的資料訓練你自己的嵌入,還是使用預訓練好的嵌入,將取決于你的專案,
顯然,你仍然可以試驗這兩種模型,并選擇一種精度更高的模型,但上面的教程只是一個簡化的教程,可以幫助你做出決策,
程序
前面的部分已經采取了所需的大部分步驟,只需進行一些調整,
我們只需要構建一個單詞及其向量的嵌入矩陣,然后用它來設定嵌入層的權重,
所以,保持預處理、標識化和填充步驟不變,
一旦我們匯入了原始資料集并運行了前面的文本清理步驟,我們將運行下面的代碼來構建嵌入矩陣,
以下決定要嵌入多少個維度(50、100、200),并將其名稱包含在下面的路徑變數中,
# # 匯入嵌入
path = 'Full path to your glove file (with the dimensions)'
embeddings = dict()
with open(path, 'r', encoding = 'utf-8') as f:
for line in f:
# 檔案中的每一行都是一個單詞外加50個數(表示這個單詞的向量)
values = line.split()
# 每一行的第一個元素是一個單詞,其余的50個是它的向量
embeddings[values[0]] = np.array(values[1:], 'float32')
# 設定一些引數
vocab_size = 2100
glove_dim = 50
sequence_length = 200
# 從語料庫中的單詞構建嵌入矩陣
embedding_matrix = np.zeros((vocab_size, glove_dim))
for word, index in word_index.items():
if index < vocab_size:
try:
# 如果給定單詞的嵌入存在,檢索它并將其映射到單詞,
embedding_matrix[index] = embeddings[word]
except:
pass
構建和訓練嵌入層和神經網路的代碼應該稍作修改,以允許將嵌入矩陣用作權重,
# 神經網路
from keras.models import Sequential
from keras.layers import Embedding, Dense, Flatten
model = Sequential()
model.add(Embedding(input_dim = vocab_size,
output_dim = glove_dim,
input_length = sequence))
model.add(Flatten())
model.add(Dense(units = 3, activation = 'softmax'))
model.compile(optimizer = 'adam', metrics = ['accuracy'], loss = 'categorical_crossentropy')
# 加載我們預訓練好的嵌入矩陣到嵌入層
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False # 訓練時權重不會被更新
# 訓練模型
history = model.fit(X_train_seq, y_train, epochs = 20, batch_size = 512, verbose = 1)
下面是我們預訓練的模型在測驗集中的性能指標,

結論
從兩個模型的性能指標來看,訓練嵌入層似乎更適合這個資料集,
一些原因可能是
1) 關于堆疊溢位的大多數問題都與IT和編程有關,也就是說,這是一個特定領域的場景,
2) 45000個樣本的大型訓練資料集為我們的嵌入層提供了一個很好的學習場景,
希望本教程對你有幫助,謝謝你的閱讀,下一篇文章再見,
原文鏈接:https://towardsdatascience.com/a-guide-to-word-embeddings-8a23817ab60f
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/200500.html
標籤:其他