文章目錄
- 1. elasticsearch 分布式
- 1.1 分布式系統的可用性與擴展性
- 1.2 分布式特性
- 2. 節點
- 2.1 Master-eligible nodes和Master Node
- 2.2 Data Node & Coordinate Node
- 2.2.1 Data Node
- 2.2.2 Coordinate Node
- 2.3 其他的節點型別
- 2.3.1 Hot & Warm Node
- 2.3.2 Machine Learning Node
- 2.3.3 Tribe Node
- 2.4 配置節點型別
- 3. 分片(Primary Shard & Replica Shard)
- 3.1 分片的設定
- 4. 操作示例
1. elasticsearch 分布式
1.1 分布式系統的可用性與擴展性
高可用性
- 服務可用性-允許有節點停止服務
- 資料可用性-部分節點丟失,不會丟失資料
可擴展性
- 請求量提升/資料的不斷增長(將資料分布到所有節點上)
1.2 分布式特性
elasticsearch的分布式架構好處
- 存盤的水平擴容
- 提高系統的可用性,部分節停止服務,整個集群的服務不受影響
ElasticSearch的分布式架構
- 不同的集群通過不同的名字來區分,默認名字”elasticsearch“
- 通過組態檔修改,或者在命令列中 -E cluster.name=cluster1進行設定
- 一個集群可以用多個節點
2. 節點
- 是一個elasticsearch的實體,本質上是一個java行程,一臺機器上可以運行多個elasticsearch行程,但是生產環境一般建議一臺機器上運行一個elasticsearch實體
- 每一個節點都有名字,通過組態檔配置,或者啟動時候 -E node.name=node1 指定
- 每一個節點在啟動之后,會分配一個UID,保存在data目錄下
不同的節點承擔了不同的角色
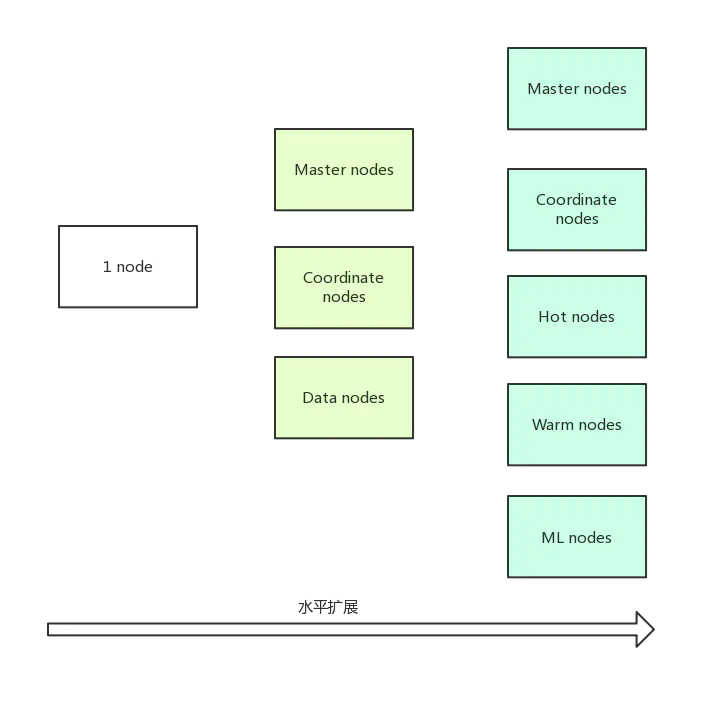
2.1 Master-eligible nodes和Master Node
- 每個節點啟動后,默認就是一個Master eligible節點,可以設定node.master:false禁止
- Master-eligible節點可以參加選主流程,成為master節點
- 當第一個節點啟動時候,它會將自己選舉成Master節點
- 每個節點上保存了集群的狀態,只有master節點才能修改集群的狀態資訊
集群狀態(Cluster State),維護了一個集群中,必要的資訊:
所有的節點資訊;
所有的索引和其相關的Mapping與Setting資訊;
分片的路由資訊; - 任意節點都能修改資訊會導致資料的不一致性
2.2 Data Node & Coordinate Node
2.2.1 Data Node
可以保存資料的節點,叫做Data Node,負責保存分片資料,在資料擴展上起到了至關重要的作用
2.2.2 Coordinate Node
負責接受Client的請求,將請求分發到合適的節點,最終將結果匯集到一起
每個節點默認起到了Coordinate Node的職責
2.3 其他的節點型別
2.3.1 Hot & Warm Node
不同硬體配置的Data Node,用來實作Hot & Warm架構,降低集群部署的成本
2.3.2 Machine Learning Node
負責跑機器學習的 Job,用來做例外檢測
2.3.3 Tribe Node
5.3開始使用Cross Cluster Search ,Tribe Node連接到不同的Elasticsearch集群,并且支持將這些集群當成一個單獨的集群處理
2.4 配置節點型別
| 節點型別 | 配置引數 | 默認值 |
|---|---|---|
| master | eligible.node.master | TRUE |
| data | node.data | TRUE |
| ingest | node.ingest | TRUE |
| coordinatingonly | 無 | 每個節點默認都是coordinate節點設定其他型別為false |
| machine learning | node.ml | true(需設定enablex-pack) |
3. 分片(Primary Shard & Replica Shard)
- 主分片,用以解決資料水平擴展的問題,通過主分片,可以將資料分布到集群內的所有節點之上
1.一個分片是一個運行的 Lucene 的實體
2.主分片數在索引創建時指定,后續不允許修改,除非 通過Reindex方式進行 - 副本,用以解決資料高可用的問題,分片是主分片的拷貝
1.副本分片數,可以動態調整
2.增加副本數,還可以在一定程度上提高服務的可用性(讀取的吞吐) - 一個三節點的集群中,blogs索引的分片分布情況
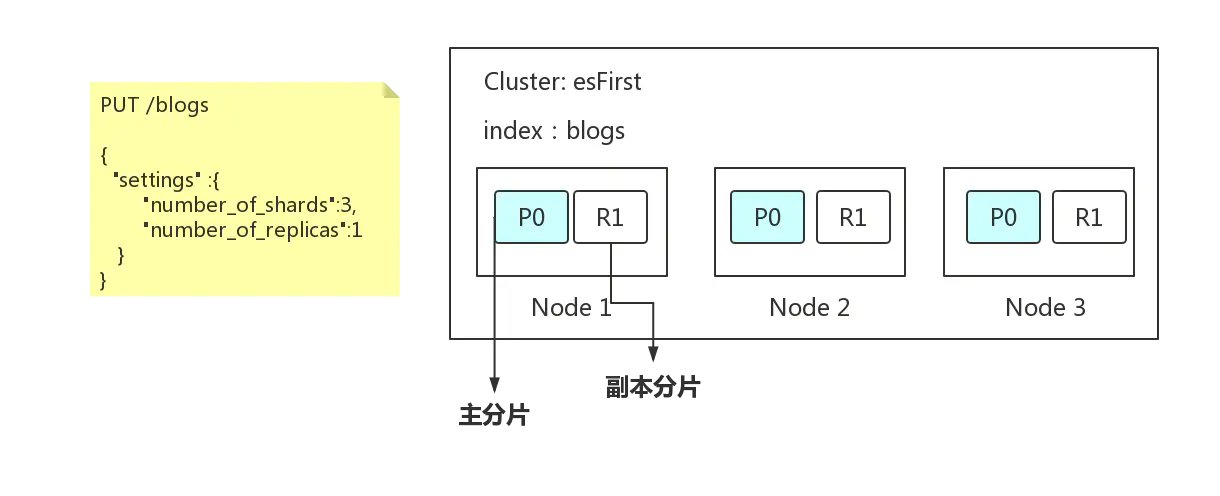
一個主分片分散到三個節點上,每個節點存在一個副本分片
3.1 分片的設定
對于生成環境分片的設定,需要提前做好容量規劃
- 分片數設定過小:
1.導致后續無法增加節點實作水平擴展
2.單個分片的資料量太大,導致資料重新分配耗時 - 分片數設定過大,7.0開始,默認主分片設定為1,解決了over-sharding的問題:
1.影響搜索結果的相關性打分,影響統計結果的準確性
2.單個節點上過多的分片,會導致資源浪費,同時也會影響性能
查看集群的健康狀況
GET _cluster/health
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 6,
"active_shards" : 6,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 1,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 85.71428571428571
}
- Green-主分片與副本都正常分配
- Yellow-主分片全部正常分配,副本分片未能正常分配
- Red-有主分片未能分配
例如,當服務器的磁盤容量超過85%時,去創建一個新的索引
4. 操作示例
get _cat/nodes?v
GET /_nodes/es7_01,es7_02
GET /_cat/nodes?v
GET /_cat/nodes?v&h=id,ip,port,v,m
GET _cluster/health
GET _cluster/health?level=shards
GET /_cluster/health/kibana_sample_data_ecommerce,kibana_sample_data_flights
GET /_cluster/health/kibana_sample_data_flights?level=shards
#### cluster state
The cluster state API allows access to metadata representing the state of the whole cluster. This includes information such as
GET /_cluster/state
#cluster get settings
GET /_cluster/settings
GET /_cluster/settings?include_defaults=true
GET _cat/shards
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
參考資料:
極客時間:Elasticsearch核心技術與實戰
相關閱讀:
初學elasticsearch入門
Elasticsearch本地安裝與簡單配置
docker-compose安裝elasticsearch集群
Elasticsearch 7.X之檔案、索引、REST API詳解
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/201678.html
標籤:其他