上一節我們講了容器網路的模型,以及如何通過 NAT 的方式與物理網路進行互通,
每一臺物理機上面安裝好了 Docker 以后,都會默認分配一個 172.17.0.0/16 的網段,一臺機器上新創建的第一個容器,一般都會給 172.17.0.2 這個地址,當然一臺機器這樣玩玩倒也沒啥問題,但是容器里面是要部署應用的,就像上一節講過的一樣,它既然是集裝箱,里面就需要裝載貨物,
如果這個應用是比較傳統的單體應用,自己就一個行程,所有的代碼邏輯都在這個行程里面,上面的模式沒有任何問題,只要通過 NAT 就能訪問進來,
但是因為無法解決快速迭代和高并發的問題,單體應用越來越跟不上時代發展的需要了,
你可以回想一下,無論是各種網路直播平臺,還是共享單車,是不是都是很短時間內就要積累大量用戶,否則就會錯過風口,所以應用需要在很短的時間內快速迭代,不斷調整,滿足用戶體驗;還要在很短的時間內,具有支撐高并發請求的能力,
單體應用作為個人英雄主義的時代已經過去了,如果所有的代碼都在一個工程里面,開發的時候必然存在大量沖突,上線的時候,需要開大會進行協調,一個月上線一次就很不錯了,而且所有的流量都讓一個行程扛,怎么也扛不住啊!
沒辦法,一個字:拆!拆開了,每個子模塊獨自變化,減少相互影響,拆開了,原來一個行程扛流量,現在多個行程一起扛,所以,微服務就是從個人英雄主義,變成集團軍作戰,
容器作為集裝箱,可以保證應用在不同的環境中快速遷移,提高迭代的效率,但是如果要形成容器集團軍,還需要一個集團軍作戰的調度平臺,這就是 Kubernetes,它可以靈活地將一個容器調度到任何一臺機器上,并且當某個應用扛不住的時候,只要在 Kubernetes 上修改容器的副本數,一個應用馬上就能變八個,而且都能提供服務,
然而集團軍作戰有個重要的問題,就是通信,這里面包含兩個問題,第一個是集團軍的 A 部隊如何實時地知道 B 部隊的位置變化,第二個是兩個部隊之間如何相互通信,
第一個問題位置變化,往往是通過一個稱為注冊中心的地方統一管理的,這個是應用自己做的,當一個應用啟動的時候,將自己所在環境的 IP 地址和埠,注冊到注冊中心指揮部,這樣其他的應用請求它的時候,到指揮部問一下它在哪里就好了,當某個應用發生了變化,例如一臺機器掛了,容器要遷移到另一臺機器,這個時候 IP 改變了,應用會重新注冊,則其他的應用請求它的時候,還是能夠從指揮部得到最新的位置,
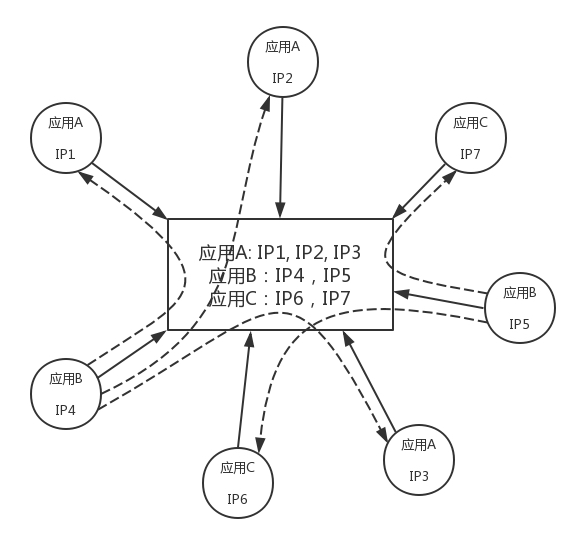
接下來是如何相互通信的問題,NAT 這種模式,在多個主機的場景下,是存在很大問題的,在物理機 A 上的應用 A 看到的 IP 地址是容器 A 的,是 172.17.0.2,在物理機 B 上的應用 B 看到的 IP 地址是容器 B 的,不巧也是 172.17.0.2,當它們都注冊到注冊中心的時候,注冊中心就是這個圖里這樣子,
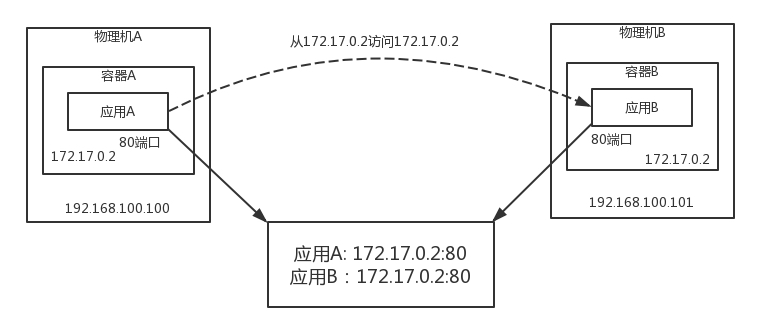
這個時候,應用 A 要訪問應用 B,當應用 A 從注冊中心將應用 B 的 IP 地址讀出來的時候,就徹底困惑了,這不是自己訪問自己嗎?
怎么解決這個問題呢?一種辦法是不去注冊容器內的 IP 地址,而是注冊所在物理機的 IP 地址,埠也要是物理機上映射的埠,
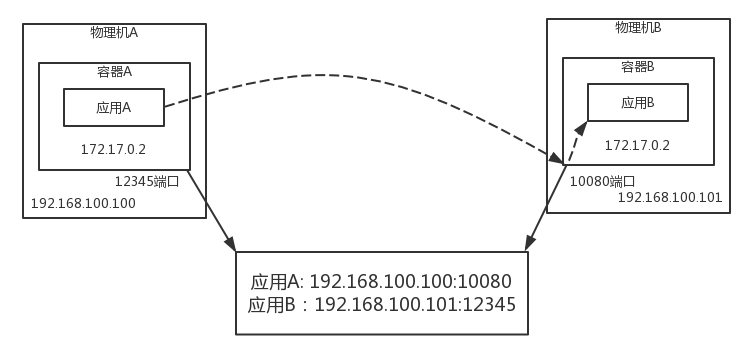
這樣存在的問題是,應用是在容器里面的,它怎么知道物理機上的 IP 地址和埠呢?這明明是運維人員配置的,除非應用配合,讀取容器平臺的介面獲得這個 IP 和埠,一方面,大部分分布式框架都是容器誕生之前就有了,它們不會適配這種場景;另一方面,讓容器內的應用意識到容器外的環境,本來就是非常不好的設計,
說好的集裝箱,說好的隨意遷移呢?難道要讓集裝箱內的貨物意識到自己傳的資訊?而且本來 Tomcat 都是監聽 8080 埠的,結果到了物理機上,就不能大家都用這個埠了,否則埠就沖突了,因而就需要隨機分配埠,于是在注冊中心就出現了各種各樣奇怪的埠,無論是注冊中心,還是呼叫方都會覺得很奇怪,而且不是默認的埠,很多情況下也容易出錯,
Kubernetes 作為集團軍作戰管理平臺,提出指導意見,說網路模型要變平,但是沒說怎么實作,于是業界就涌現了大量的方案,Flannel 就是其中之一,
對于 IP 沖突的問題,如果每一個物理機都是網段 172.17.0.0/16,肯定會沖突啊,但是這個網段實在太大了,一臺物理機上根本啟動不了這么多的容器,所以能不能每臺物理機在這個大網段里面,摳出一個小的網段,每個物理機網段都不同,自己看好自己的一畝三分地,誰也不和誰沖突,
例如物理機 A 是網段 172.17.8.0/24,物理機 B 是網段 172.17.9.0/24,這樣兩臺機器上啟動的容器 IP 肯定不一樣,而且就看 IP 地址,我們就一下子識別出,這個容器是本機的,還是遠程的,如果是遠程的,也能從網段一下子就識別出它歸哪臺物理機管,太方便了,
接下來的問題,就是物理機 A 上的容器如何訪問到物理機 B 上的容器呢?
你是不是想到了熟悉的場景?虛擬機也需要跨物理機互通,往往通過 Overlay 的方式,容器是不是也可以這樣做呢?
這里我要說 Flannel 使用 UDP 實作 Overlay 網路的方案,
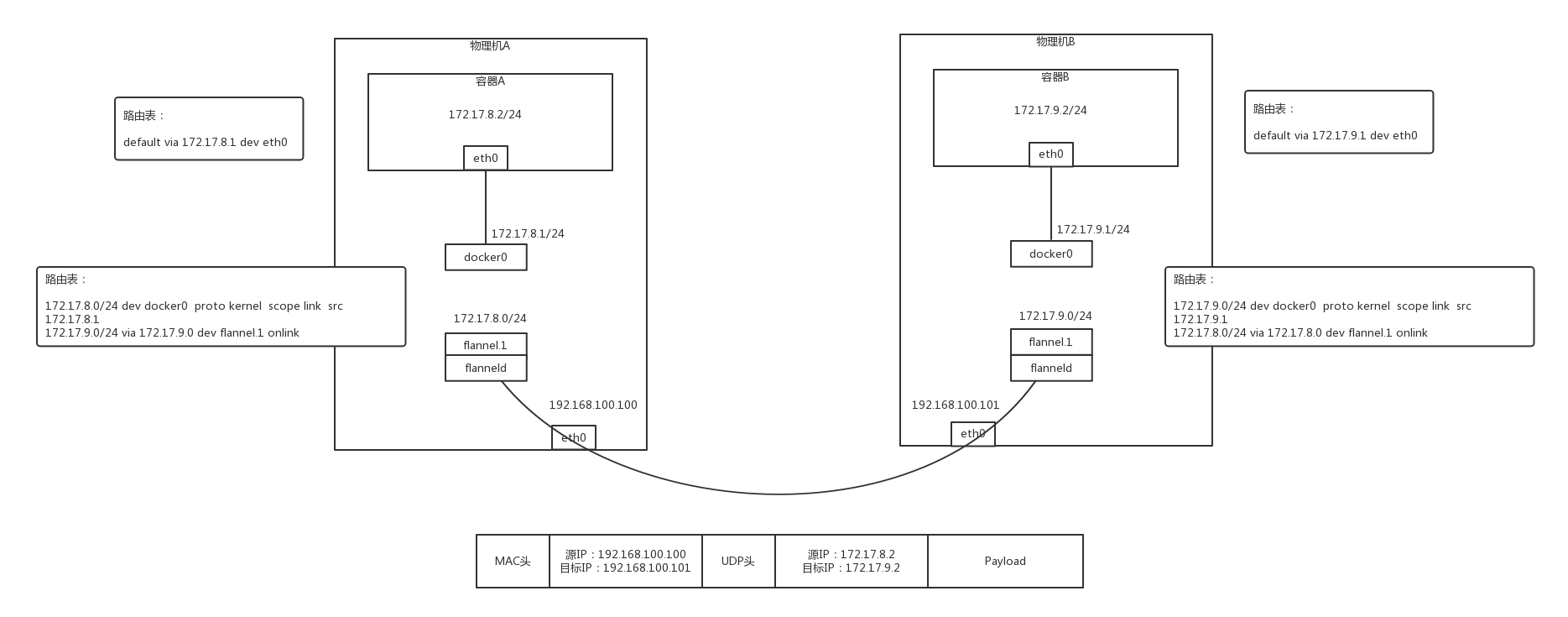
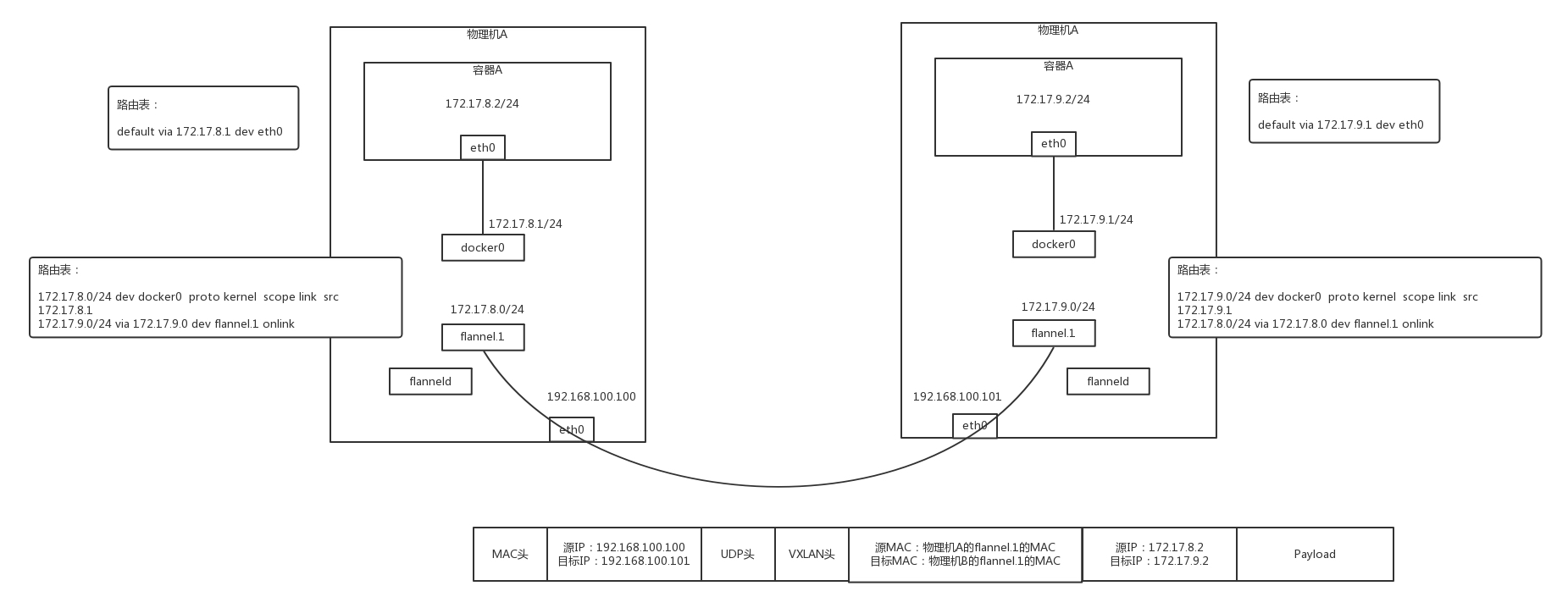
在物理機 A 上的容器 A 里面,能看到的容器的 IP 地址是 172.17.8.2/24,里面設定了默認的路由規則 default via 172.17.8.1 dev eth0,
如果容器 A 要訪問 172.17.9.2,就會發往這個默認的網關 172.17.8.1,172.17.8.1 就是物理機上面 docker0 網橋的 IP 地址,這臺物理機上的所有容器都是連接到這個網橋的,
在物理機上面,查看路由策略,會有這樣一條 172.17.0.0/24 via 172.17.0.0 dev flannel.1,也就是說發往 172.17.9.2 的網路包會被轉發到 flannel.1 這個網卡,
這個網卡是怎么出來的呢?在每臺物理機上,都會跑一個 flanneld 行程,這個行程打開一個 /dev/net/tun 字符設備的時候,就出現了這個網卡,
你有沒有想起 qemu-kvm,打開這個字符設備的時候,物理機上也會出現一個網卡,所有發到這個網卡上的網路包會被 qemu-kvm 接收進來,變成二進制串,只不過接下來 qemu-kvm 會模擬一個虛擬機里面的網卡,將二進制的串變成網路包,發給虛擬機里面的網卡,但是 flanneld 不用這樣做,所有發到 flannel.1 這個網卡的包都會被 flanneld 行程讀進去,接下來 flanneld 要對網路包進行處理,
物理機 A 上的 flanneld 會將網路包封裝在 UDP 包里面,然后外層加上物理機 A 和物理機 B 的 IP 地址,發送給物理機 B 上的 flanneld,
為什么是 UDP 呢?因為不想在 flanneld 之間建立兩兩連接,而 UDP 沒有連接的概念,任何一臺機器都能發給另一臺,
物理機 B 上的 flanneld 收到包之后,解開 UDP 的包,將里面的網路包拿出來,從物理機 B 的 flannel.1 網卡發出去,
在物理機 B 上,有路由規則 172.17.9.0/24 dev docker0 proto kernel scope link src 172.17.9.1,
將包發給 docker0,docker0 將包轉給容器 B,通信成功,
上面的程序連通性沒有問題,但是由于全部在用戶態,所以性能差了一些,
跨物理機的連通性問題,在虛擬機那里有成熟的方案,就是 VXLAN,那能不能 Flannel 也用 VXLAN 呢?
當然可以了,如果使用 VXLAN,就不需要打開一個 TUN 設備了,而是要建立一個 VXLAN 的 VTEP,如何建立呢?可以通過 netlink 通知內核建立一個 VTEP 的網卡 flannel.1,在我們講 OpenvSwitch 的時候提過,netlink 是一種用戶態和內核態通信的機制,
當網路包從物理機 A 上的容器 A 發送給物理機 B 上的容器 B,在容器 A 里面通過默認路由到達物理機 A 上的 docker0 網卡,然后根據路由規則,在物理機 A 上,將包轉發給 flannel.1,這個時候 flannel.1 就是一個 VXLAN 的 VTEP 了,它將網路包進行封裝,
內部的 MAC 地址這樣寫:源為物理機 A 的 flannel.1 的 MAC 地址,目標為物理機 B 的 flannel.1 的 MAC 地址,在外面加上 VXLAN 的頭,
外層的 IP 地址這樣寫:源為物理機 A 的 IP 地址,目標為物理機 B 的 IP 地址,外面加上物理機的 MAC 地址,
這樣就能通過 VXLAN 將包轉發到另一臺機器,從物理機 B 的 flannel.1 上解包,變成內部的網路包,通過物理機 B 上的路由轉發到 docker0,然后轉發到容器 B 里面,通信成功,
小結
- 基于 NAT 的容器網路模型在微服務架構下有兩個問題,一個是 IP 重疊,一個是埠沖突,需要通過 Overlay 網路的機制保持跨節點的連通性,
- Flannel 是跨節點容器網路方案之一,它提供的 Overlay 方案主要有兩種方式,一種是 UDP 在用戶態封裝,一種是 VXLAN 在內核態封裝,而 VXLAN 的性能更好一些,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/201750.html
標籤:其他