上一節我們講了 Flannel 如何解決容器跨主機互通的問題,這個解決方式其實和虛擬機的網路互通模式是差不多的,都是通過隧道,但是 Flannel 有一個非常好的模式,就是給不同的物理機設定不同網段,這一點和虛擬機的 Overlay 的模式完全不一樣,
在虛擬機的場景下,整個網段在所有的物理機之間都是可以“飄來飄去”的,網段不同,就給了我們做路由策略的可能,
Calico 網路模型的設計思路
我們看圖中的兩臺物理機,它們的物理網卡是同一個二層網路里面的,由于兩臺物理機的容器網段不同,我們完全可以將兩臺物理機配置成為路由器,并按照容器的網段配置路由表,
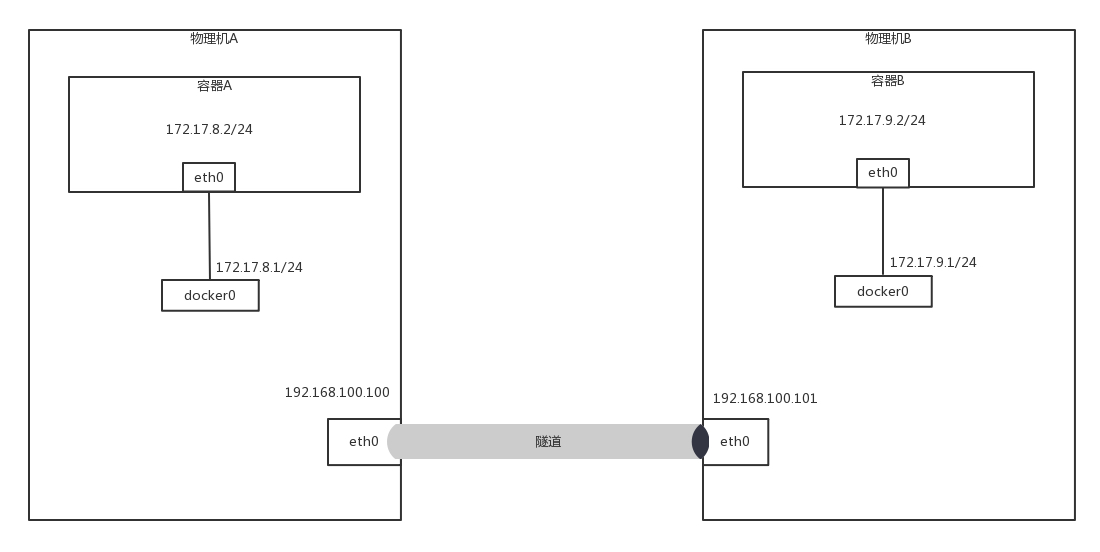
例如,在物理機 A 中,我們可以這樣配置:要想訪問網段 172.17.9.0/24,下一跳是 192.168.100.101,也即到物理機 B 上去,
這樣在容器 A 中訪問容器 B,當包到達物理機 A 的時候,就能夠匹配到這條路由規則,并將包發給下一跳的路由器,也即發給物理機 B,在物理機 B 上也有路由規則,要訪問 172.17.9.0/24,從 docker0 的網卡進去即可,
當容器 B 回傳結果的時候,在物理機 B 上,可以做類似的配置:要想訪問網段 172.17.8.0/24,下一跳是 192.168.100.100,也即到物理機 A 上去,
當包到達物理機 B 的時候,能夠匹配到這條路由規則,將包發給下一跳的路由器,也即發給物理機 A,在物理機 A 上也有路由規則,要訪問 172.17.8.0/24,從 docker0 的網卡進去即可,
這就是 Calico 網路的大概思路,即不走 Overlay 網路,不引入另外的網路性能損耗,而是將轉發全部用三層網路的路由轉發來實作,只不過具體的實作和上面的程序稍有區別,
首先,如果全部走三層的路由規則,沒必要每臺機器都用一個 docker0,從而浪費了一個 IP 地址,而是可以直接用路由轉發到 veth pair 在物理機這一端的網卡,同樣,在容器內,路由規則也可以這樣設定:把容器外面的 veth pair 網卡算作默認網關,下一跳就是外面的物理機,
于是,整個拓撲結構就變成了這個圖中的樣子,
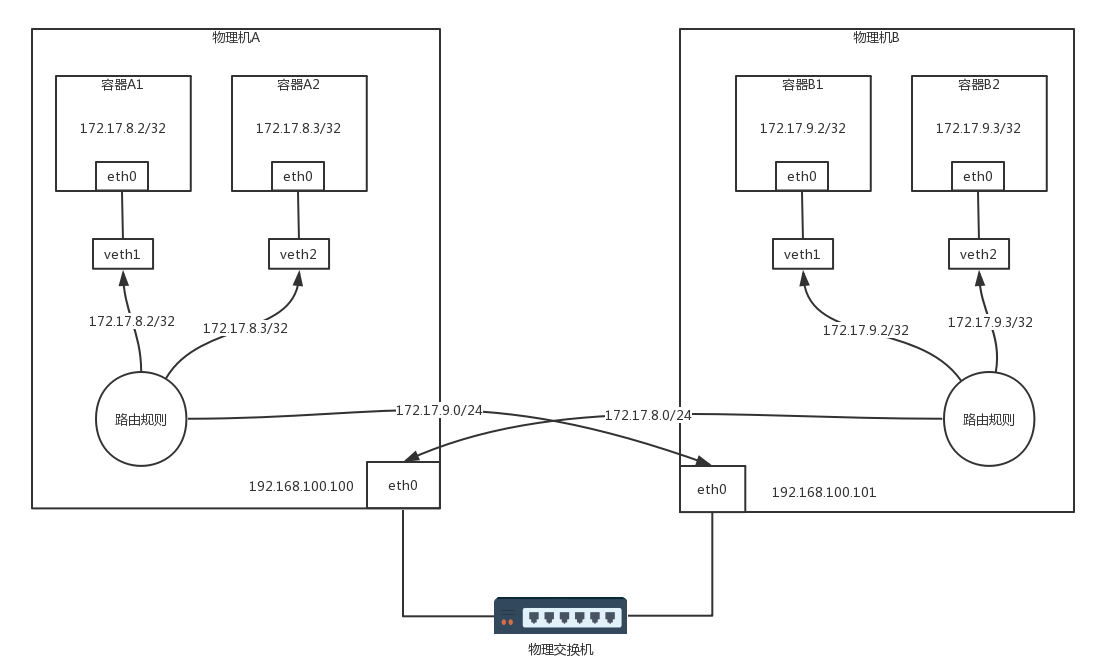
Calico 網路的轉發細節
我們來看其中的一些細節,
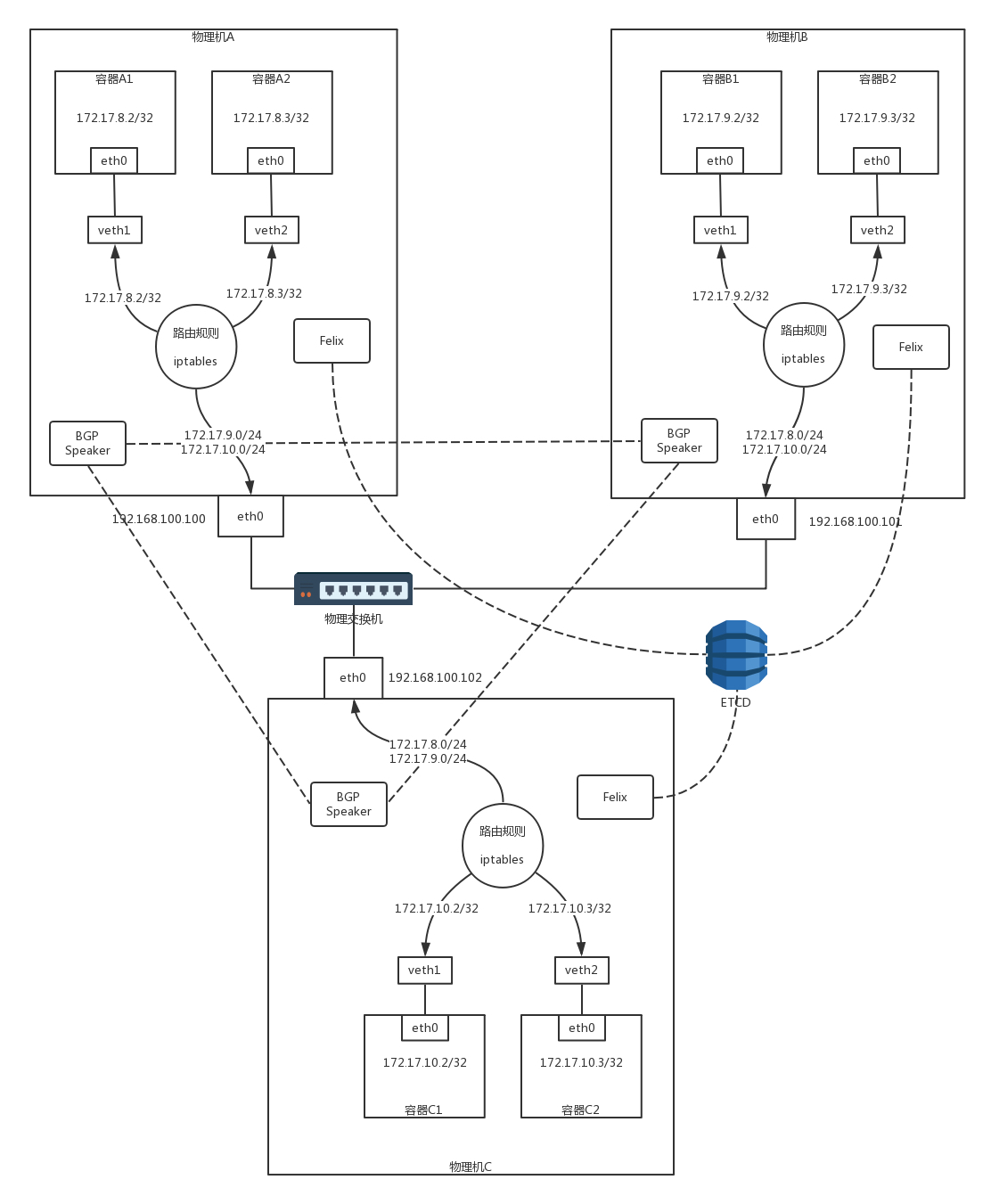
容器 A1 的 IP 地址為 172.17.8.2/32,這里注意,不是 /24,而是 /32,將容器 A1 作為一個單點的局域網了,
容器 A1 里面的默認路由,Calico 配置得比較有技巧,
default via 169.254.1.1 dev eth0 169.254.1.1 dev eth0 scope link
這個 IP 地址 169.254.1.1 是默認的網關,但是整個拓撲圖中沒有一張網卡是這個地址,那如何到達這個地址呢?
前面我們講網關的原理的時候說過,當一臺機器要訪問網關的時候,首先會通過 ARP 獲得網關的 MAC 地址,然后將目標 MAC 變為網關的 MAC,而網關的 IP 地址不會在任何網路包頭里面出現,也就是說,沒有人在乎這個地址具體是什么,只要能找到對應的 MAC,回應 ARP 就可以了,
ARP 本地有快取,通過 ip neigh 命令可以查看,
169.254.1.1 dev eth0 lladdr ee:ee:ee:ee:ee:ee STALE
這個 MAC 地址是 Calico 硬塞進去的,但是沒有關系,它能回應 ARP,于是發出的包的目標 MAC 就是這個 MAC 地址,
在物理機 A 上查看所有網卡的 MAC 地址的時候,我們會發現 veth1 就是這個 MAC 地址,所以容器 A1 里發出的網路包,第一跳就是這個 veth1 這個網卡,也就到達了物理機 A 這個路由器,
在物理機 A 上有三條路由規則,分別是去兩個本機的容器的路由,以及去 172.17.9.0/24,下一跳為物理機 B,
172.17.8.2 dev veth1 scope link 172.17.8.3 dev veth2 scope link 172.17.9.0/24 via 192.168.100.101 dev eth0 proto bird onlink
同理,物理機 B 上也有三條路由規則,分別是去兩個本機的容器的路由,以及去 172.17.8.0/24,下一跳為物理機 A,
172.17.9.2 dev veth1 scope link 172.17.9.3 dev veth2 scope link 172.17.8.0/24 via 192.168.100.100 dev eth0 proto bird onlink
如果你覺得這些規則過于復雜,我將剛才的拓撲圖轉換為這個更加容易理解的圖,
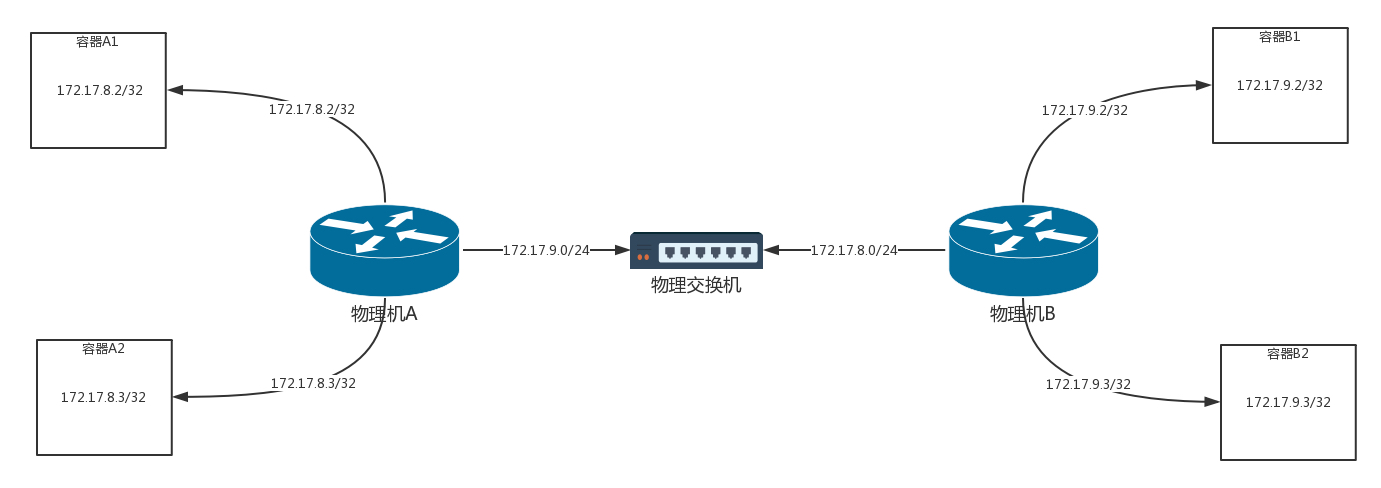
在這里,物理機化身為路由器,通過路由器上的路由規則,將包轉發到目的地,在這個程序中,沒有隧道封裝解封裝,僅僅是單純的路由轉發,性能會好很多,但是,這種模式也有很多問題,
Calico 的架構
路由配置組件 Felix
如果只有兩臺機器,每臺機器只有兩個容器,而且保持不變,我手動配置一下,倒也沒啥問題,但是如果容器不斷地創建、洗掉,節點不斷地加入、退出,情況就會變得非常復雜,
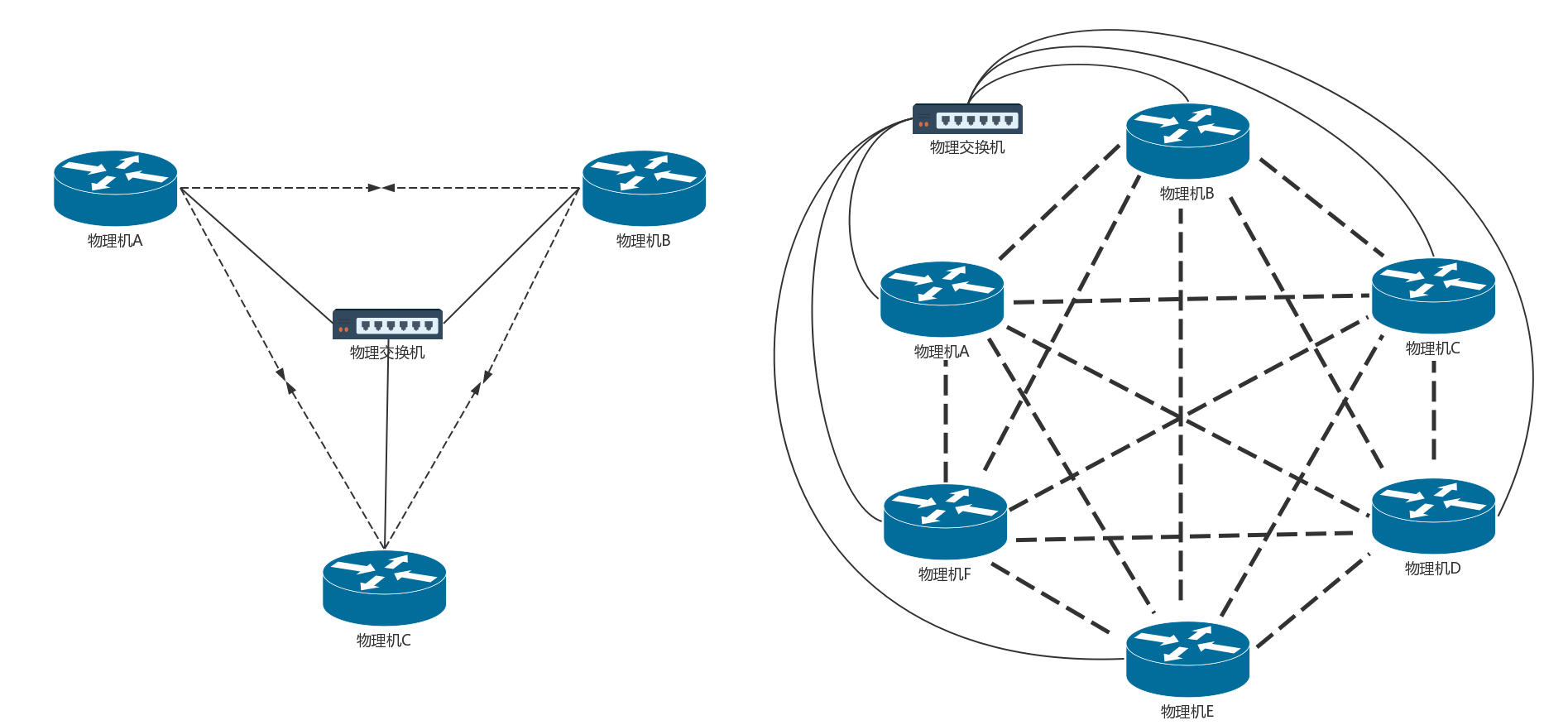
就像圖中,有三臺物理機,兩兩之間都需要配置路由,每臺物理機上對外的路由就有兩條,如果有六臺物理機,則每臺物理機上對外的路由就有五條,新加入一個節點,需要通知每一臺物理機添加一條路由,
這還是在物理機之間,一臺物理機上,每創建一個容器,也需要多配置一條指向這個容器的路由,如此復雜,肯定不能手動配置,需要每臺物理機上有一個 agent,當創建和洗掉容器的時候,自動做這件事情,這個 agent 在 Calico 中稱為 Felix,
路由廣播組件 BGP Speaker
當 Felix 配置了路由之后,接下來的問題就是,如何將路由資訊,也即將“如何到達我這個節點,訪問我這個節點上的容器”這些資訊,廣播出去,
能想起來嗎?這其實就是路由協議啊!路由協議就是將“我能到哪里,如何能到我”的資訊廣播給全網傳出去,從而客戶端可以一跳一跳地訪問目標地址的,路由協議有很多種,Calico 使用的是 BGP 協議,
在 Calico 中,每個 Node 上運行一個軟體 BIRD,作為 BGP 的客戶端,或者叫作 BGP Speaker,將“如何到達我這個 Node,訪問我這個 Node 上的容器”的路由資訊廣播出去,所有 Node 上的 BGP Speaker 都互相建立連接,就形成了全互連的情況,這樣每當路由有所變化的時候,所有節點就都能夠收到了,
安全策略組件
Calico 中還實作了靈活配置網路策略 Network Policy,可以靈活配置兩個容器通或者不通,這個怎么實作呢?
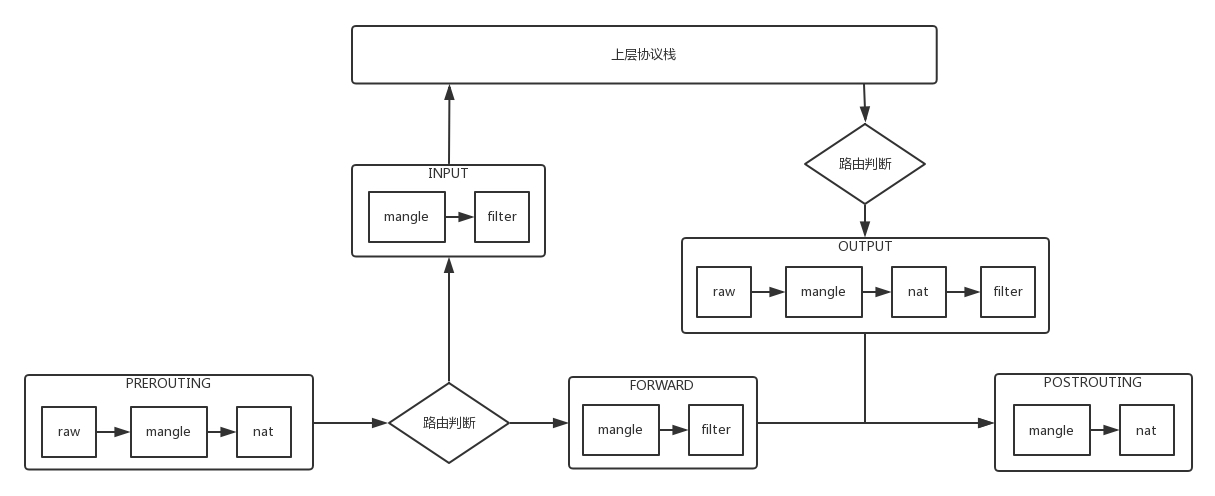
虛擬機中的安全組,是用 iptables 實作的,Calico 中也是用 iptables 實作的,這個圖里的內容是 iptables 在內核處理網路包的程序中可以嵌入的處理點,Calico 也是在這些點上設定相應的規則,
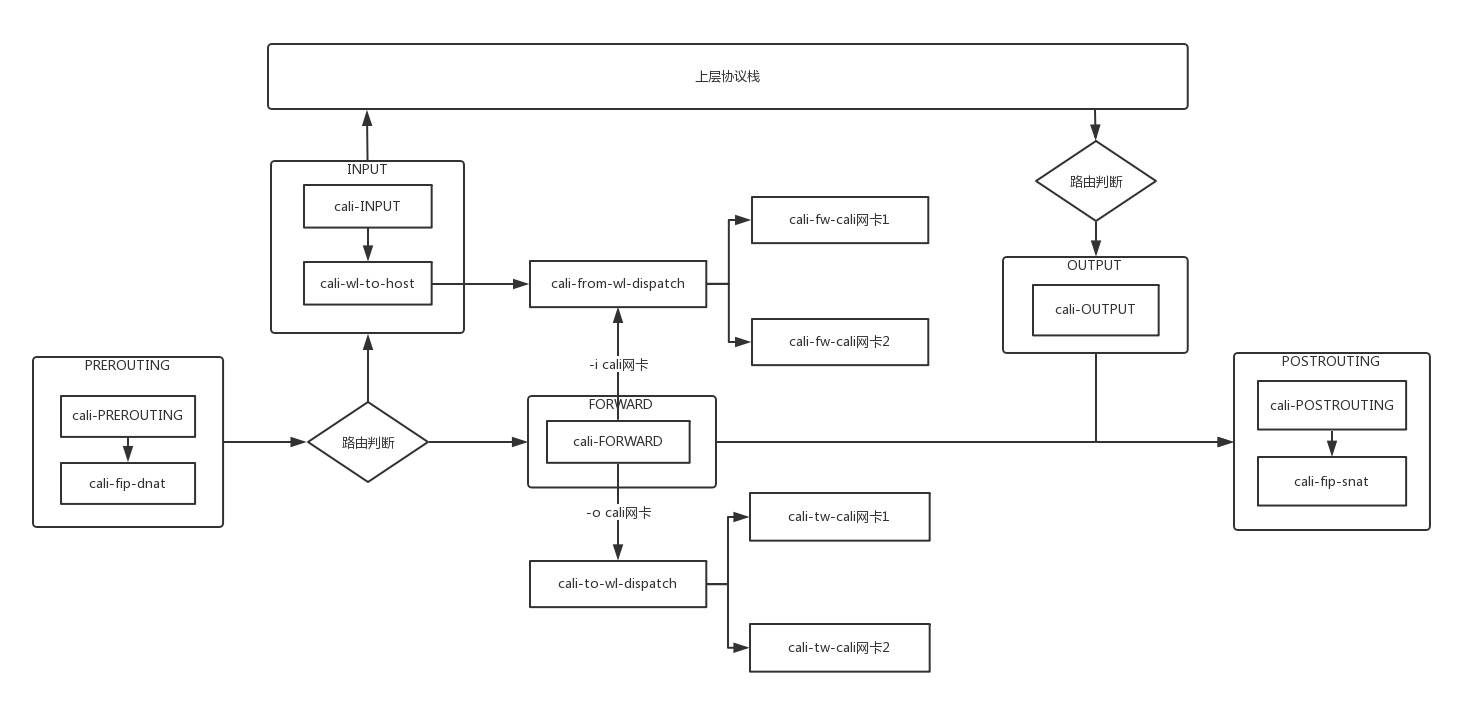
當網路包進入物理機上的時候,進入 PREOUTING 規則,這里面有一個規則是 cali-fip-dnat,這是實作浮動 IP(Floating IP)的場景,主要將外網的 IP 地址 dnat 作為容器內的 IP 地址,在虛擬機場景下,路由器的網路 namespace 里面有一個外網網卡上,也設定過這樣一個 DNAT 規則,
接下來可以根據路由判斷,是到本地的,還是要轉發出去的,
如果是本地的,走 INPUT 規則,里面有個規則是 cali-wl-to-host,wl 的意思是 workload,也即容器,也即這是用來判斷從容器發到物理機的網路包是否符合規則的,這里面內嵌一個規則 cali-from-wl-dispatch,也是匹配從容器來的包,如果有兩個容器,則會有兩個容器網卡,這里面內嵌有詳細的規則“cali-fw-cali 網卡 1”和“cali-fw-cali 網卡 2”,fw 就是 from workload,也就是匹配從容器 1 來的網路包和從容器 2 來的網路包,
如果是轉發出去的,走 FORWARD 規則,里面有個規則 cali-FORWARD,這里面分兩種情況,一種是從容器里面發出來,轉發到外面的;另一種是從外面發進來,轉發到容器里面的,
第一種情況匹配的規則仍然是 cali-from-wl-dispatch,也即 from workload,第二種情況匹配的規則是 cali-to-wl-dispatch,也即 to workload,如果有兩個容器,則會有兩個容器網卡,在這里面內嵌有詳細的規則“cali-tw-cali 網卡 1”和“cali-tw-cali 網卡 2”,tw 就是 to workload,也就是匹配發往容器 1 的網路包和發送到容器 2 的網路包,
接下來是匹配 OUTPUT 規則,里面有 cali-OUTPUT,接下來是 POSTROUTING 規則,里面有一個規則是 cali-fip-snat,也即發出去的時候,將容器網路 IP 轉換為浮動 IP 地址,在虛擬機場景下,路由器的網路 namespace 里面有一個外網網卡上,也設定過這樣一個 SNAT 規則,
至此為止,Calico 的所有組件基本湊齊,來看看我匯總的圖,
全連接復雜性與規模問題
這里面還存在問題,就是 BGP 全連接的復雜性問題,
你看剛才的例子里只有六個節點,BGP 的互連已經如此復雜,如果節點資料再多,這種全互連的模式肯定不行,到時候都成蜘蛛網了,于是多出了一個組件 BGP Route Reflector,它也是用 BIRD 實作的,有了它,BGP Speaker 就不用全互連了,而是都直連它,它負責將全網的路由資訊廣播出去,
可是問題來了,規模大了,大家都連它,它受得了嗎?這個 BGP Router Reflector 會不會成為瓶頸呢?
所以,肯定不能讓一個 BGP Router Reflector 管理所有的路由分發,而是應該有多個 BGP Router Reflector,每個 BGP Router Reflector 管一部分,
多大算一部分呢?咱們講述資料中心的時候,說服務器都是放在機架上的,每個機架上最頂端有個 TOR 交換機,那將機架上的機器連在一起,這樣一個機架是不是可以作為一個單元,讓一個 BGP Router Reflector 來管理呢?如果要跨機架,如何進行通信呢?這就需要 BGP Router Reflector 也直接進行路由交換,它們之間的交換和一個機架之間的交換有什么關系嗎?
有沒有覺得在這個場景下,一個機架就像一個資料中心,可以把它設定為一個 AS,而 BGP Router Reflector 有點兒像資料中心的邊界路由器,在一個 AS 內部,也即服務器和 BGP Router Reflector 之間使用的是資料中心內部的路由協議 iBGP,BGP Router Reflector 之間使用的是資料中心之間的路由協議 eBGP,
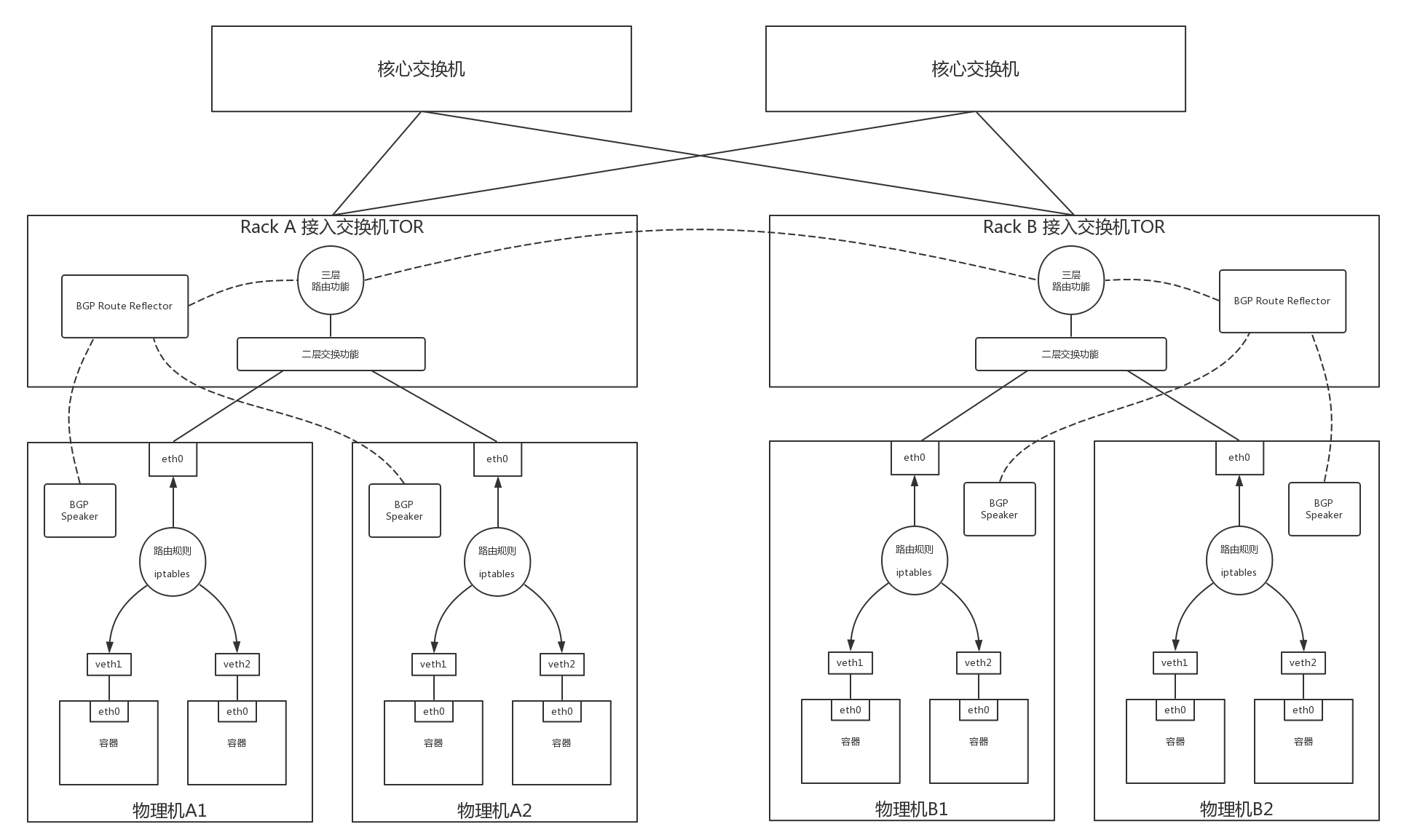
這個圖中,一個機架上有多臺機器,每臺機器上面啟動多個容器,每臺機器上都有可以到達這些容器的路由,每臺機器上都啟動一個 BGP Speaker,然后將這些路由規則上報到這個 Rack 上接入交換機的 BGP Route Reflector,將這些路由通過 iBGP 協議告知到接入交換機的三層路由功能,
在接入交換機之間也建立 BGP 連接,相互告知路由,因而一個 Rack 里面的路由可以告知另一個 Rack,有多個核心或者匯聚交換機將接入交換機連接起來,如果核心和匯聚起二層互通的作用,則接入和接入之間之間交換路由即可,如果核心和匯聚交換機起三層路由的作用,則路由需要通過核心或者匯聚交換機進行告知,跨網段訪問問題
跨網段訪問問題
上面的 Calico 模式還有一個問題,就是跨網段問題,這里的跨網段是指物理機跨網段,
前面我們說的那些邏輯成立的條件,是我們假設物理機可以作為路由器進行使用,例如物理機 A 要告訴物理機 B,你要訪問 172.17.8.0/24,下一跳是我 192.168.100.100;同理,物理機 B 要告訴物理機 A,你要訪問 172.17.9.0/24,下一跳是我 192.168.100.101,
之所以能夠這樣,是因為物理機 A 和物理機 B 是同一個網段的,是連接在同一個交換機上的,那如果物理機 A 和物理機 B 不是在同一個網段呢?
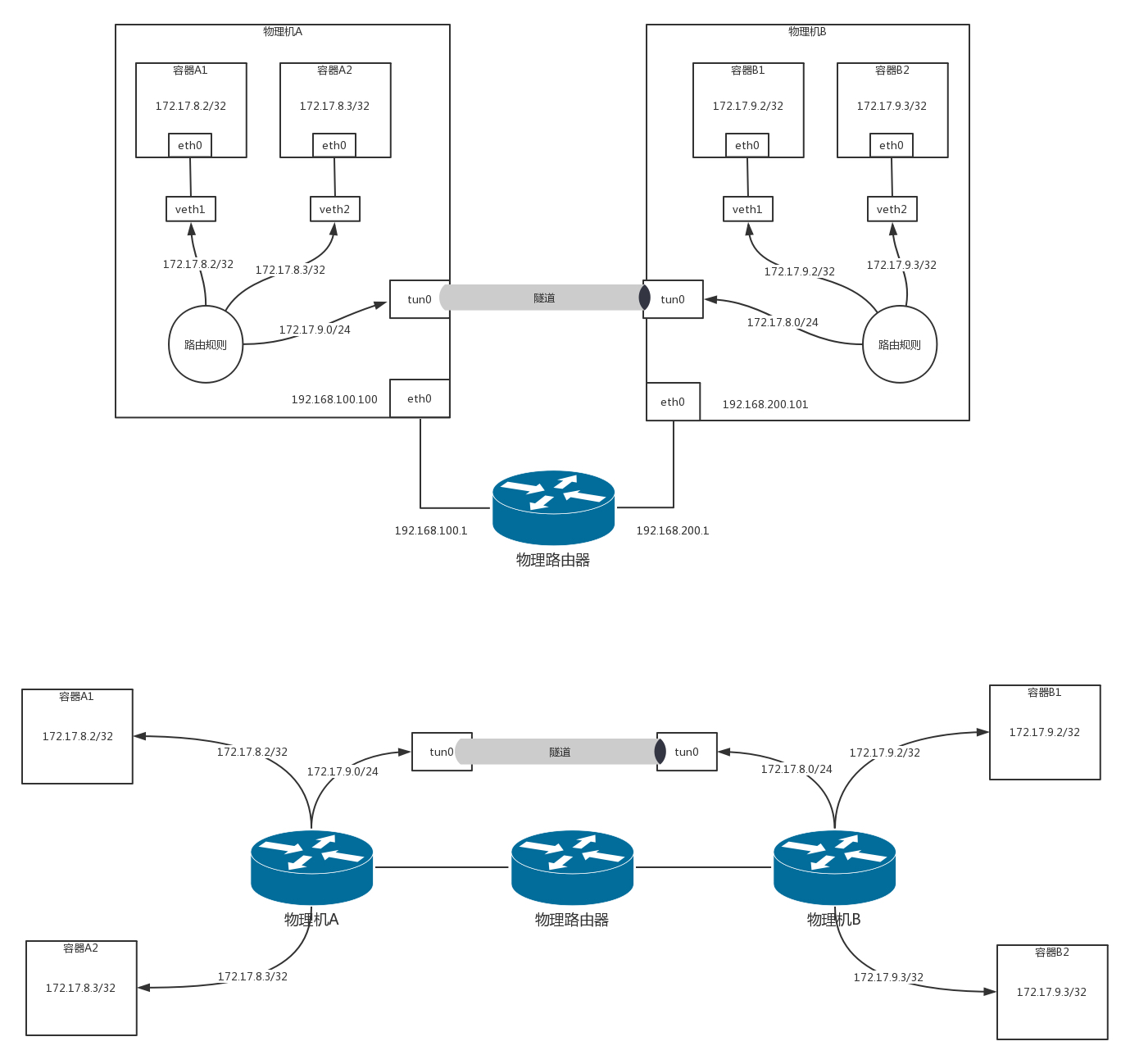
例如,物理機 A 的網段是 192.168.100.100/24,物理機 B 的網段是 192.168.200.101/24,這樣兩臺機器就不能通過二層交換機連接起來了,需要在中間放一臺路由器,做一次路由轉發,才能跨網段訪問,
本來物理機 A 要告訴物理機 B,你要訪問 172.17.8.0/24,下一跳是我 192.168.100.100 的,但是中間多了一臺路由器,下一跳不是我了,而是中間的這臺路由器了,這臺路由器的再下一跳,才是我,這樣之前的邏輯就不成立了,
我們看剛才那張圖的下半部分,物理機 B 上的容器要訪問物理機 A 上的容器,第一跳就是物理機 B,IP 為 192.168.200.101,第二跳是中間的物理路由器右面的網口,IP 為 192.168.200.1,第三跳才是物理機 A,IP 為 192.168.100.100,
這是咱們通過拓撲圖看到的,關鍵問題是,在系統中物理機 A 如何告訴物理機 B,怎么讓它才能到我這里?物理機 A 根本不可能知道從物理機 B 出來之后的下一跳是誰,況且現在只是中間隔著一個路由器這種簡單的情況,如果隔著多個路由器呢?誰能把這一串的路徑告訴物理機 B 呢?
我們能想到的第一種方式是,讓中間所有的路由器都來適配 Calico,本來它們互相告知路由,只互相告知物理機的,現在還要告知容器的網段,這在大部分情況下,是不可能的,
第二種方式,還是在物理機 A 和物理機 B 之間打一個隧道,這個隧道有兩個端點,在端點上進行封裝,將容器的 IP 作為乘客協議放在隧道里面,而物理主機的 IP 放在外面作為承載協議,這樣不管外層的 IP 通過傳統的物理網路,走多少跳到達目標物理機,從隧道兩端看起來,物理機 A 的下一跳就是物理機 B,這樣前面的邏輯才能成立,
這就是 Calico 的 IPIP 模式,使用了 IPIP 模式之后,在物理機 A 上,我們能看到這樣的路由表:
172.17.8.2 dev veth1 scope link 172.17.8.3 dev veth2 scope link 172.17.9.0/24 via 192.168.200.101 dev tun0 proto bird onlink
這和原來模式的區別在于,下一跳不再是同一個網段的物理機 B 了,IP 為 192.168.200.101,并且不是從 eth0 跳,而是建立一個隧道的端點 tun0,從這里才是下一跳,
如果我們在容器 A1 里面的 172.17.8.2,去 ping 容器 B1 里面的 172.17.9.2,首先會到物理機 A,在物理機 A 上根據上面的規則,會轉發給 tun0,并在這里對包做封裝:
- 內層源 IP 為 172.17.8.2;
- 內層目標 IP 為 172.17.9.2;
- 外層源 IP 為 192.168.100.100;
- 外層源 IP 為 192.168.100.100;
將這個包從 eth0 發出去,在物理網路上會使用外層的 IP 進行路由,最終到達物理機 B,在物理機 B 上,tun0 會解封裝,將內層的源 IP 和目標 IP 拿出來,轉發給相應的容器,
小結
- Calico 推薦使用物理機作為路由器的模式,這種模式沒有虛擬化開銷,性能比較高,
- Calico 的主要組件包括路由、iptables 的配置組件 Felix、路由廣播組件 BGP Speaker,以及大規模場景下的 BGP Route Reflector,
- 為解決跨網段的問題,Calico 還有一種 IPIP 模式,也即通過打隧道的方式,從隧道端點來看,將本來不是鄰居的兩臺機器,變成相鄰的機器,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/201752.html
標籤:其他