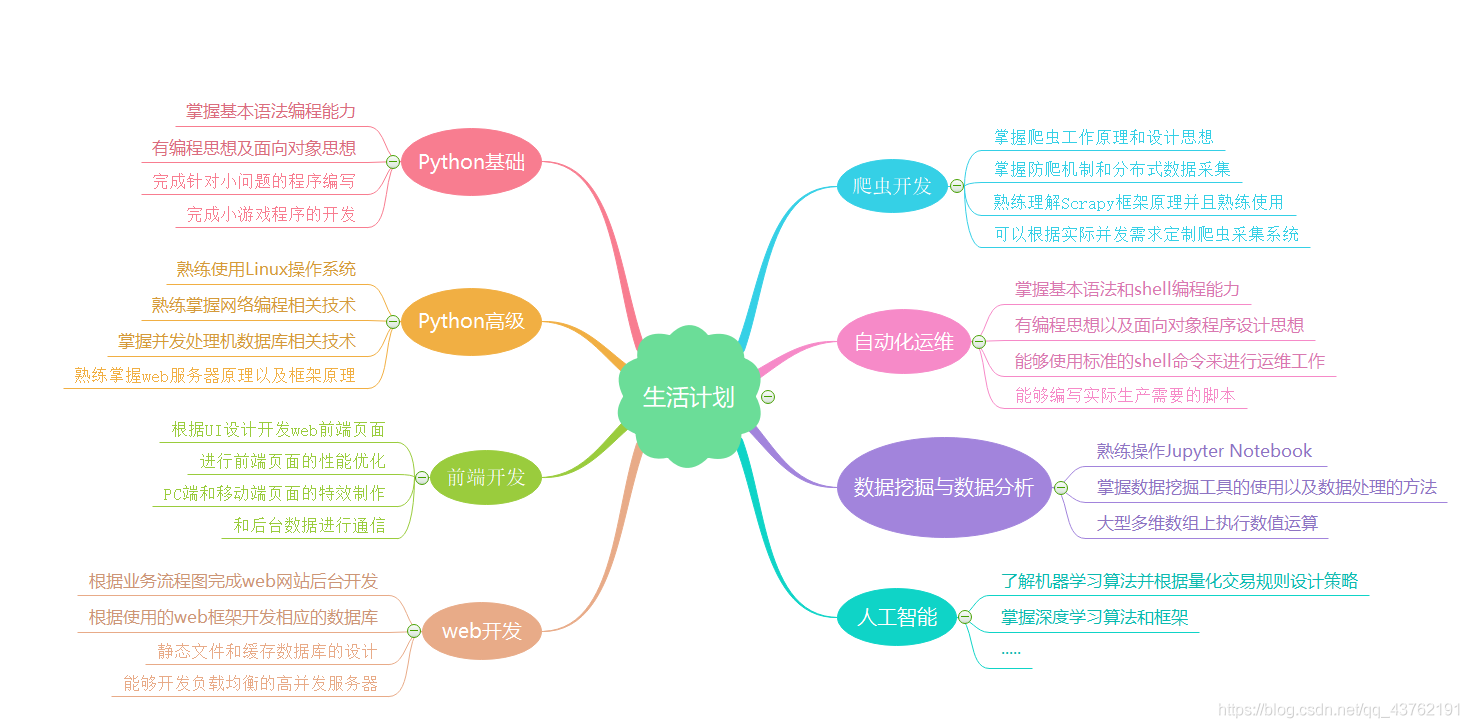
標題無意冒犯,就是覺得這個廣告挺好玩的
上面這張思維導圖喜歡就拿走,反正我也學不了這么多
文章目錄
- 前言
- 歡迎來到我們的圈子
- HTML基礎
- HTML是什么?
- 查看網頁的HTML代碼
- 我們看了個啥玩意兒啊?
- 標簽和元素
- HTML基本結構
- HTML屬性
- 爬取網頁文本
- 前情回顧
- BeautifulSoup
- 網頁資料決議
- res = BeautifulSoup('要決議的資料','決議器')
- 提取資料
- tag物件
- 回顧
前言
前期回顧:我要偷偷學Python(第七天)
上一篇呢,我們初見爬蟲,其實近距離接觸之后,發現也不是學不會的嘛,雖然我們只是爬取了小圖片,爬網頁還比較吃力,一下用例過猛把人家的源代碼都給爬過來了,
那怎么辦呢?我們看別人的爬蟲效果,好像沒有那么凌亂的源代碼啊,這就需要做網頁決議了,好,今天我們就來決議一下網頁,然后把里面的有效的字提取出來,
注意哦,我們并不能教你去做前端,只是簡單的了解一下網頁結構,以便我們的爬蟲定位,
插播一條推送:(如果是小白的話,可以看一下下面這一段)
歡迎來到我們的圈子
我建了一個Python學習答疑群,有興趣的朋友可以了解一下:這是個什么群
群里已經有兩百多個小伙伴了哦!!!
直通群的傳送門:傳送門
本系列文默認各位有一定的C或C++基礎,因為我是學了點C++的皮毛之后入手的Python,這里也要感謝齊鋒學長送來的支持,
本系列文默認各位會百度,學習‘模塊’這個模塊的話,還是建議大家有自己的編輯器和編譯器的,上一篇已經給大家做了推薦啦?
我要的不多,點個關注就好啦
然后呢,本系列的目錄嘛,說實話我個人比較傾向于那兩本 Primer Plus,所以就跟著它們的目錄結構吧,
本系列也會著重培養各位的自主動手能力,畢竟我不可能把所有知識點都給你講到,所以自己解決需求的能力就尤為重要,所以我在文中埋得坑請不要把它們看成坑,那是我留給你們的鍛煉機會,請各顯神通,自行解決,
HTML基礎
HTML是什么?
HTML(Hyper Text Markup Language)是用來描述網頁的一種語言,也叫超文本標記語言 ,
它是什么在這邊已經不重要了,咱重點來看它,在座的各位,應該都不排斥陌生語言了吧,這是個大前提,
查看網頁的HTML代碼
來我們隨便打開個網頁吧,比如說就第七天的吧:https://blog.csdn.net/qq_43762191/article/details/109320746
在網頁空白區域右擊,顯示網頁源代碼,
代碼太長了我就不拷貝過來了啊,吶,網址在這里:view-source:https://blog.csdn.net/qq_43762191/article/details/109320746
找不到源代碼的可以直接從網址進,
還有一種辦法:右擊->檢查,這種方法可以讓源代碼和網頁同屏出現,
就看個人喜好啦,各有千秋,
我們看了個啥玩意兒啊?
標簽和元素
好,來先看HTML檔案,可以看到很多夾在尖括號<>中間的字母,它們叫做【標簽】,
標簽通常是成對出現的:前面的是【開始標簽】,比如;后面的是【結束標簽】,如,
不過,也有標簽是形單影只地出現,比如HTML代碼的第五行(定義網頁編碼格式為 utf-8),就是此類,這些你知道就好,大部分情況下用的都是成雙成對出現的標簽,

事實上,開始標簽+結束標簽+中間的所有內容,它們在一起就組成了【元素】,
下面的表格列出了幾個常見元素:
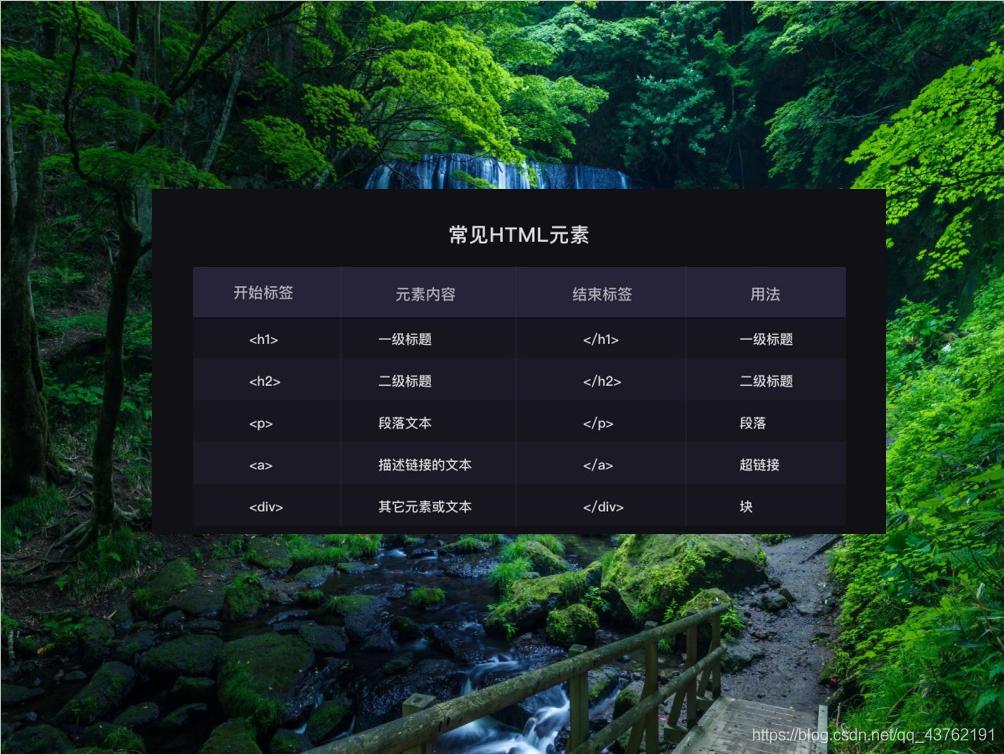
現在再回去看那份網頁源代碼,雖然沒這個表格也能猜個八九不離十的,
是不是清晰了很多!!!
HTML基本結構
要是覺得還不夠看,那再來一張:

HTML屬性
你還會發現,代碼里面還有一些諸如“class”之類的東西反復出現,跟在body后面,這些被稱為“屬性”,我們來看看:

至此,我們就講完了HTML的組成:標簽、元素、結構(網頁頭和網頁體)、屬性,
好,現在再直觀的看一下網頁的源代碼,直到感覺沒有壓力了,咱再往下,
爬取網頁文本
前情回顧
前一天,我們給大家留下了一個只能爬取網頁原始碼的遺憾,但是那其實是第一步,接下來我們將那段網頁代碼決議出來,提取出我們想要的內容,
當時的代碼是這樣的:
import requests #呼叫requests庫
res = requests.get('https://blog.csdn.net/qq_43762191') #爬我自己的主頁
#獲取網頁源代碼,得到的res是Response物件
html=res.text
#把res的內容以字串的形式回傳
print('回應狀態碼:',res.status_code) #檢查請求是否正確回應
print(html) #列印網頁源代碼
BeautifulSoup
這里要介紹一個模塊,BeautifulSoup,名字還不錯嘛,美麗的靈魂,
在我的pycharm里面是下載不了這個的,不知道是不是因為我用Python3.9的緣故,還是說它沒辦法單獨下載,像我之前做詞云那樣,不過我可以下載beautifulsoup4,反正不管你下載的是什么,只要確定下載之后能找到bs4這個包就行了,
網頁資料決議
res = BeautifulSoup(‘要決議的資料’,‘決議器’)
引數釋義:
第一個是要被決議的文本,注意了,它必須是字串,
第二個引數用來標識決議器,我們要用的是一個Python內置庫:html.parser,(它不是唯一的決議器,但是比較簡單的)
好,我們再看:
import requests
from bs4 import BeautifulSoup
res = requests.get('https://blog.csdn.net/qq_43762191')
soup = BeautifulSoup( res.text,'html.parser')
print(type(soup)) #查看soup的型別
wt = open('test4.txt','w',encoding='utf-8')
wt.write(res.text)
wt.close()
好,你去試一下,你會發現CSDN不讓你這么容易得逞,真好,雖然照樣被爬,
那我們換個網址吧,
https://mp.weixin.qq.com/s?__biz=MzI4NDY5Mjc1Mg==&mid=2247489783&idx=1&sn=09d76423b700620f80c9da9e4d8a8536&chksm=ebf6c088dc81499e3d5a0febeb67fec27ba52f233b6a0e6fda37221a2c497dee82f2de29e567&scene=21#wechat_redirect
這篇有亮點哦,不過,自己爬下來看,當初看完之后我還特地研究了一下午,當然,我是為了安全,對,我是好人,
看看運行結果,soup的資料型別是<class ‘bs4.BeautifulSoup’>,說明soup是一個BeautifulSoup物件,
提取資料
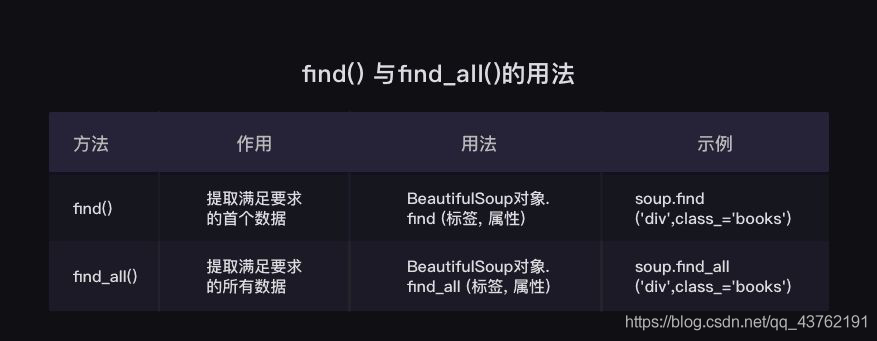
這一步,又可以分為兩部分知識:find()與find_all(),以及Tag物件,
import requests
from bs4 import BeautifulSoup
res = requests.get('https://mp.weixin.qq.com/s?__biz=MzI4NDY5Mjc1Mg==&mid=2247489783&idx=1&sn=09d76423b700620f80c9da9e4d8a8536&chksm=ebf6c088dc81499e3d5a0febeb67fec27ba52f233b6a0e6fda37221a2c497dee82f2de29e567&scene=21#wechat_redirect') #好像只能爬取以.html結尾的網址,連我的博客主頁都沒辦法爬
soup = BeautifulSoup( res.text,'html.parser')
item = soup.find('div')
#item = soup.find_all('div')
print(type(item)) #查看soup的型別
wt = open('test6.txt','w',encoding='utf-8')
wt.write(str(item))
wt.close()
print(item)
事實證明啊,紙上得來終覺淺,絕知此事要躬行啊,差點就信了上面那張圖的鬼話,
(其實你再回頭認真研究一下,又會有新的發現)
括號中的引數:標簽和屬性可以任選其一,也可以兩個一起使用,這取決于我們要在網頁中提取的內容,
icon
如果只用其中一個引數就可以準確定位的話,就只用一個引數檢索,如果需要標簽和屬性同時滿足的情況下才能準確定位到我們想找的內容,那就兩個引數一起使用,
tag物件
各位有沒有覺得勝利在望了,然后執行下來發現又是鏡花水月一場空,別急嘛,我們繼續往下看,看不到吃虧哦:
我們前面忙活了大半天,又是提出了一堆的源代碼出來,tony帶水,但是真的沒有一點改變嗎?不要相信你的眼睛,眼睛有時候會騙人的,各位不妨把每次回傳的回傳值列印出屬性來看看,其實屬性一直在往有利于我們的方向發展著,
我們看到它們的資料型別是<class ‘bs4.element.Tag’>,是Tag物件
還記得我們前邊說,提取資料分為那啥和tag嗎?現在就到了最后沖刺的時刻了,沒有錯,沖吶!!!


首先,Tag物件可以使用find()與find_all()來繼續檢索,
res = requests.get('https://mp.weixin.qq.com/s?__biz=MzI4NDY5Mjc1Mg==&mid=2247489783&idx=1&sn=09d76423b700620f80c9da9e4d8a8536&chksm=ebf6c088dc81499e3d5a0febeb67fec27ba52f233b6a0e6fda37221a2c497dee82f2de29e567&scene=21')#wechat_redirect') #好像只能爬取以.html結尾的網址,連我的博客主頁都沒辦法爬')
# 回傳一個response物件,賦值給res
html = res.text
# 把res的內容以字串的形式回傳
soup = BeautifulSoup( html,'html.parser')
# 把網頁決議為BeautifulSoup物件
items = soup.find_all('div') # 通過定位標簽和屬性提取我們想要的資料
for item in items:
kind = item.find(class_='rich_media_area_primary') # 在串列中的每個元素里,匹配標簽<h2>提取出資料
print(kind,'\n') # 列印提取出的資料
print(type(kind)) # 列印提取出的資料型別
我們用Tag.text提出Tag物件中的文字,用Tag[‘href’]提取出URL,
import requests # 呼叫requests庫
from bs4 import BeautifulSoup # 呼叫BeautifulSoup庫
res =requests.get('https://mp.weixin.qq.com/s?__biz=MzI4NDY5Mjc1Mg==&mid=2247489783&idx=1&sn=09d76423b700620f80c9da9e4d8a8536&chksm=ebf6c088dc81499e3d5a0febeb67fec27ba52f233b6a0e6fda37221a2c497dee82f2de29e567&scene=21#wechat_redirect')
# 回傳一個response物件,賦值給res
html=res.text
# 把res決議為字串
soup = BeautifulSoup( html,'html.parser')
# 把網頁決議為BeautifulSoup物件
items = soup.find_all(class_='rich_media') # 通過匹配屬性class='rich_media'提取出我們想要的元素
for item in items: # 遍歷串列items
kind = item.find('h2') # 在串列中的每個元素里,匹配標簽<h2>提取出資料
title = item.find(class_='profile_container') # 在串列中的每個元素里,匹配屬性class_='profile_container'提取出資料
print(kind.text,'\n',title.text) # 列印書籍的型別、名字、鏈接和簡介的文字
回顧
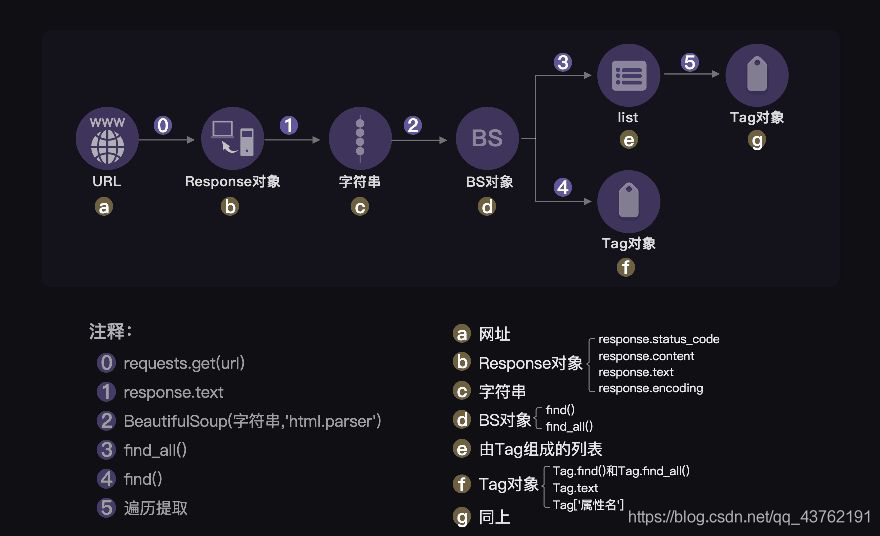
其實說白了,從最開始用requests庫獲取資料,到用BeautifulSoup庫來決議資料,再繼續用BeautifulSoup庫提取資料,不斷經歷的是我們操作物件的型別轉換,
請看下圖:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/202027.html
標籤:其他