具有區域潛在語意相關性的多標簽影像分類
??來自2017年的CVPR
摘要
??深度卷積神經網路(CNN)在單標簽影像分類方面表現出了先進的性能,在多標簽影像分類方面也取得了長足的進展,多標簽影像分類需要在一個鏡頭中標注物體、屬性、場景類別等.目前的多標簽影像分類方法利用了影像中標簽的相關性,在全域范圍內極大地提高了標簽的能力,然而,由于對全域視覺特征的識別有限,預測小物體和視覺概念仍然是一個挑戰.在本文中,我們提出了一個區域潛在語意依賴模型(RLSD)來解決這個問題,所使用的模型包括一個完全卷積的定位架構來定位可能包含多個高度依賴標簽的區域.區域區域被進一步發送到遞回神經網路(RNN)來表征區域層次上潛在的語意依賴.在幾個基準資料集上的實驗結果表明,我們提出的模型取得了最好的性能相比于最新的模型,特別是用于預測影像中出現的小物體.此外,我們在訓練程序中利用邊界盒坐標建立上界模型(RLSD+ft-RPN),實驗結果也表明,我們的RLSD可以在不使用邊界盒標注的情況下接近上界,在現實世界中更加真實
1.介紹
??由于網路訪問的便利和數字設備的廣泛使用,大尺度影像已變得廣泛可用,這為研究人員了解這些影像提供了各種機會,影像分類作為一項傳統的任務,已經進行了幾十年的全面研究,特別是對于單標簽分類問題,已經取得了各種進展,而在現實世界中,影像通常包含著豐富的語意資訊,如物體、屬性、動作、場景等.通過給影像分配多個標簽,可以將視覺資訊轉化為語言,便于理解,并可用于影像檢索和語意分割等其他可視化應用.
??此任務背后的關鍵問題是彌合影像可視內容和多個標簽之間存在的語意差距.圖1給出了多標簽影像的示例.隨著大規模資料集的可用和資料標注的豐富,多標簽影像分類引起了人們的廣泛關注,受到深度神經網路,特別是卷積神經網路先進性能的啟發,人們在將神經網路應用于多標簽分類問題上做出了各種努力,
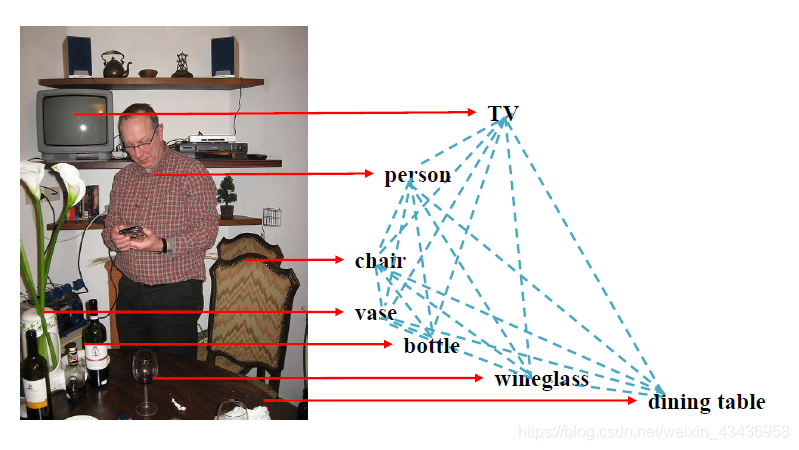 ??圖一:多標簽影像的一個例子,紅色箭頭表示影像內容和標簽之間的視覺相關性,藍色點線表示標簽之間存在語意依賴性,
??圖一:多標簽影像的一個例子,紅色箭頭表示影像內容和標簽之間的視覺相關性,藍色點線表示標簽之間存在語意依賴性,
??最直接的方法是將多標簽影像分類問題視為幾個單獨的單標簽分類問題,并使用交叉熵或排名損失來訓練每個標簽的獨立分類器,weet 提供了一個區域解決方案,允許在區域級別上獨立地預測標簽,但是,他們很難建立不同標簽之間的標簽依賴的模型,直觀上看,多標簽的影像中標簽之間的相關性很強,例如ocean和ship通常出現在同一幅影像中,而ocean和cat通常不會同時出現,為了方便地探索標簽依賴關系,在以往的作業中通常采用概率圖形模型(PGM)
??最近,Wang等證明了遞回神經網路(RNN)可以有效地捕獲高階標簽依賴關系,他們將CNN和RNN統一為一個框架,在全域層面上挖掘標簽依賴,極大地提高了標簽的能力,然而,由于對全域視覺特征的識別有限,預測小物體和屬性對于這些作業來說仍然是一個挑戰,
??在本文中,我們的主要貢獻是提出了一個用于多標簽影像分類的區域潛在語意依賴(RLSD)模型,該模型有效地捕獲了區域層面上的潛在語意依賴,該模型結合了區域特征的優點和基于RNN的標簽共現模型的優點,與目前最先進的多標簽分類模型相比,在多個基準資料集上取得了最好的性能,特別是在預測小目標和視覺概念方面,圖2顯示了我們提出的RLSD模型與基線模型的示例輸出,我們可以看到,在Multi-CNN和CNN+LSTM中,由于圖片中的“瓶子”、“花瓶”和“酒杯”體積較小,所以沒能預測出它們,而我們的模型有效地預測了它們和其他大型物體,
 ??圖2:不同模型多標簽預測實體結果,左邊是ground-truth,中間的一列是來自基線模型、Multi-CNN和CNN+LSTM的結果,右列顯示我們提出的RLSD模型的輸出,包括預測的多個標簽和選定的區域,與基線方法相比,我們的模型預測效果更加豐富,尤其擅長預測小物體,如瓶子、酒杯、花瓶等,
??圖2:不同模型多標簽預測實體結果,左邊是ground-truth,中間的一列是來自基線模型、Multi-CNN和CNN+LSTM的結果,右列顯示我們提出的RLSD模型的輸出,包括預測的多個標簽和選定的區域,與基線方法相比,我們的模型預測效果更加豐富,尤其擅長預測小物體,如瓶子、酒杯、花瓶等,
??所提模型的框架如圖3所示,首先通過CNN對輸入影像進行處理,提取卷積特征,然后將其發送到RPN-like (Regional Proposal Network)定位層,與傳統的目標檢測框架中的RPN(如faster R-CNN)不同,RPN試圖用一個單一的目標來預測提案,我們的定位層被設計用于定位影像中可能包含多個語意依賴標簽的區域,利用全連接神經網路對這些區域進行編碼,再將其發送給RNN, RNN在區域層面捕獲潛在的語意依賴關系,RNN單元根據定位層的輸出和先前的遞回神經元的輸出順序輸出多類預測.最后,執行最大池化操作以融合所有區域輸出作為最終預測,
??此外,我們還建立了一個上界模型(RLSD+ft-RPN),利用物件限定框坐標進行訓練,我們的實驗結果表明,我們的模型可以達到這個上限,而不涉及額外的限定框注釋,這在現實世界中更加真實,
2.相關作業
??在過去的幾年中,人們對多標簽影像分類進行了大量的研究,基于強大的深度卷積神經網路,在影像分類方面取得了最新進展,該網路嘗試通過使用由多個非線性變換組成的架構來對視覺資料的高級抽象進行建模,已有幾種方法將單標簽分類網路擴展到多標簽問題,Gong等人結合top-k排名目標與CNN架構來解決這個問題,通過為成對排序標簽定義權重函式,使損失函式最小化,使正標簽的排序高于負標簽,weet al.提供了一個區域解決方案,允許在區域級別上獨立地預測標簽,他們使用BING生成物件建議,并進一步將其發送到CNN來計算多類得分,應用最大池化操作將區域得分融合在一起作為最終分類結果,我們還使用了區域特征和最大池融合,然而,我們考慮區域潛在語意依賴,這允許我們聯合預測多個標簽,
??還有一些研究通過設計多模態表示方法來解決多標簽分類問題,通過學習影像視覺內容和標簽的表示方法來彌合影像和標簽之間的語意鴻溝,通常采用典型相關分析(CCA)和核典型相關分析(KCCA)構建潛在語意空間來解決多標簽影像標注和檢索問題,這些方法側重于挖掘標簽豐富的語意資訊,而忽視了標簽之間的依賴關系,
??為了建立標簽依賴的模型,提出了幾種方法,在之前的作業中,對影像特征標簽聯合分布進行建模.有幾種不同的圖結構可以實作這一目的.基于圖的方法的一個局限性是,標簽語意資訊越豐富,圖就越復雜,計算復雜度高,效率低.此外,上述所有方法都只在全域層次上對標簽依賴進行建模
??遞回神經網路(RNN)已被證明能夠有效地建立一個序列的時間依賴性模型,并已成功地應用于多個序列對序列的問題.Wang等表明,RNN可以有效地捕獲高階標簽依賴關系,他們將CNN和RNN統一為一個框架,在全域層面上利用標簽依賴性,極大地提高了標簽的能力,我們也應用RNN來捕獲標簽的依賴關系,但與上述不同的是,我們的區域潛在語意依賴模型考慮了區域層面上的標簽依賴,使我們能夠預測小尺寸物體和視覺概念
??我們提出利用區域建議網路、全連接識別網路和RNN共同提取具有豐富語意資訊的影像區域,同時探索潛在的語意依賴關系
3. RLSD模型
??a)框架概述:該模型的關鍵特征是能夠捕獲區域語意標簽的依賴關系,其新穎之處在于,這是由一個本地化體系結構實作的,然后是一些LSTMs(長-短期記憶體),定位層的目的是定位包含多個高度依賴標簽的區域,而LSTMs被用來按順序描述潛在語意標簽依賴關系,執行一個max-pooling操作以最終融合所有區域輸出,圖3顯示了我們提出的模型的整個網路:
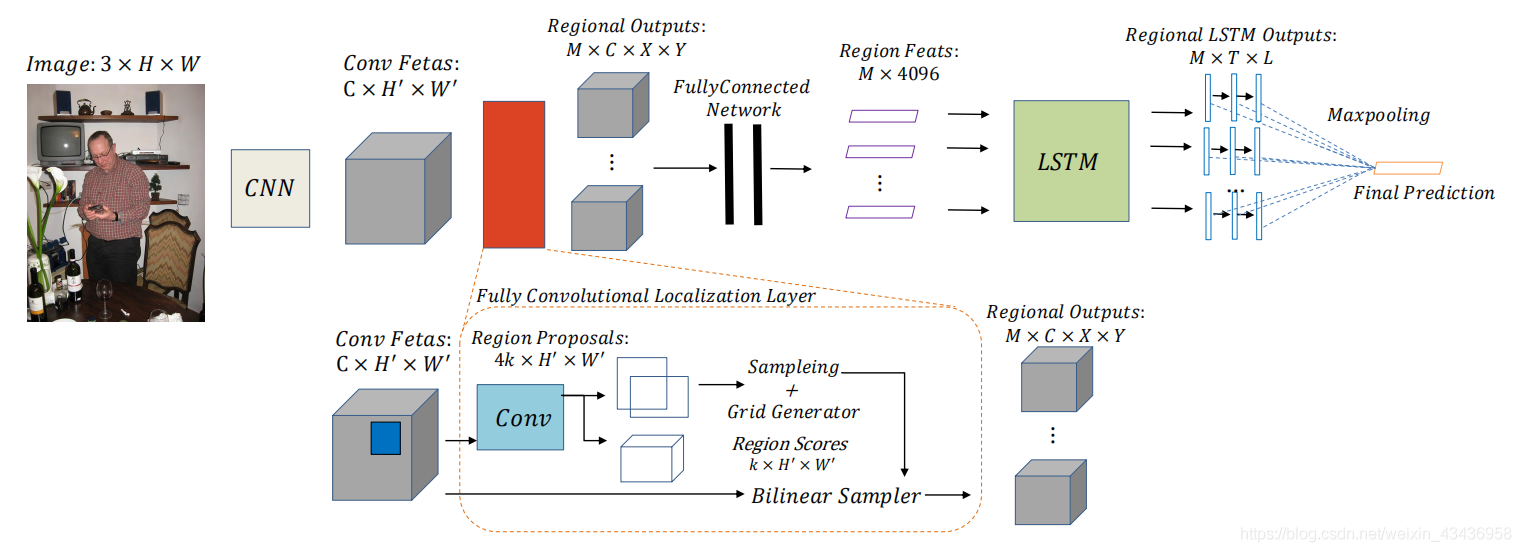
??圖3:我們提出的區域潛在語意依賴模型,首先通過CNN對輸入影像進行處理,提取卷積特征,然后將其發送給類似于RPN的全卷積定位層,定位層定位影像中可能包含多個高度依賴標簽的區域,用全連接神經網路對這些區域進行編碼,并發送到區域LSTM中,最后進行max-pooling操作,融合所有區域輸出作為最終預測
??接下來的章節III-A首先介紹了定位層,章節III-B描述了基于LSTM的標簽序列預測模型,最大池化操作和損失函式概述在第III-C節,模型初始化和一些訓練細節在章節III-D 節給出
A.本地化多標簽區域
??為了在區域層次上探索影像,我們需要生成可能包含多個物件和視覺概念的區域,因此,我們提出的模型的第一個組成部分是定位這些區域,傳統的目標建議演算法(如選擇性搜索,Objectness, BING和MCG等)被排除,因為這些方法只關注預測單一候選目標,這意味著一個候選區域通常只包含一個單一的目標,Johnson等人提出了一種全卷積神經網路,它是在候選區域網路(RPN)[14]的基礎上擴展而來的,用于定位可以用一句話而不是單個標簽來描述的區域,因此,提出的區域通常具有較大的標簽密度和標簽復雜度,受他們作業的啟發,我們開發了一種針對多標簽影像分類的候選區域生成方法,
??1)卷積特征作為輸入:由于CNN的卷積層仍然保留了影像的空間資訊,這是我們探索區域層面上的語意依賴關系所必需的,所以我們使用它來提取影像特征,具體來說,我們使用VGGNet卷積層配置,它由13個卷積層(具有3×3的內核大小)和5個最大池層(具有2×2的內核大小)組成,最后一個卷積層的輸出作為影像特征,給定一個大小為
3
×
H
×
W
3×H×W
3×H×W的輸入影像,卷積特征為
C
×
H
′
×
W
′
C×H'×W'
C×H′×W′,其中
H
′
=
H
/
16
,
W
=
W
/
16
,
C
=
512
H' = H/16,W = W/16 ,C = 512
H′=H/16,W=W/16,C=512,與VGGNet設定相同,卷積特征被進一步發送到定位層,以生成我們感興趣的候選區域,
??2)全卷積定位層:定位層的輸入是最后一步提取的卷積特征,而輸出是感興趣的空間區域的數量,每個區域都有固定大小的表示
??a)錨點與回歸:我們通過回歸一組生成錨點的偏移量來預測候選區域,具體來說,將卷積特征圖內部的每個點投影回原始影像(H×W),并以其為中心生成k個不同高寬比的錨盒(框),每個錨框被送到一個全卷積的網路中,以產生預測的盒標度和置信分數,全卷積網路由256個核大小為3×3的卷積濾波器,一個ReLU層,最后一個帶有
(
4
+
1
)
×
k
(4 + 1)×k
(4+1)×k個濾波器的卷積層組成,其中4為盒標量的數目,1為置信分數,在我們提出的模型中,我們設k = 12.我們在錨框上應用對數空間縮放變換,這意味著給定錨框的引數
(
a
x
,
a
y
,
a
w
,
a
h
)
(a_x,a_y,a_w,a_h)
(ax?,ay?,aw?,ah?),其中
(
a
x
,
a
y
)
(a_x,a_y)
(ax?,ay?)是錨框的中心,
a
w
,
a
h
a_w,a_h
aw?,ah?分別表示錨框的寬度和高度,我們通過以下公式生成區域坐標
b
=
(
b
x
,
b
y
,
b
w
,
b
h
)
b = (b_x,b_y,b_w,b_h)
b=(bx?,by?,bw?,bh?):
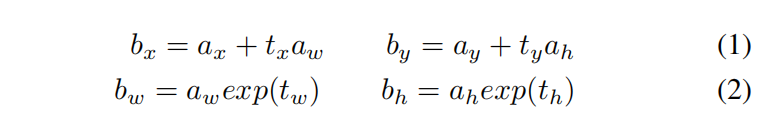
??我們的模型預測了標量
t
x
,
t
y
,
t
w
,
t
h
t_x,t_y,t_w,t_h
tx?,ty?,tw?,th?,采用光滑L1范數作為損失函式來回歸區域位置,給定真坐標
g
=
(
g
x
,
g
y
,
g
w
,
g
h
)
g = (g_x,g_y,g_w,g_h)
g=(gx?,gy?,gw?,gh?),損耗函式定義為:
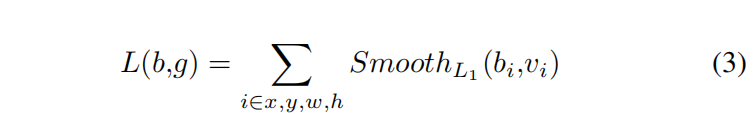
其中:
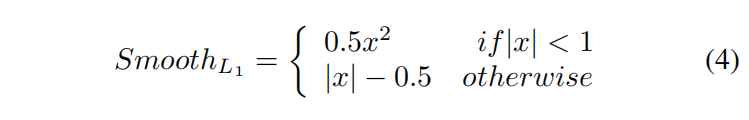
??b)盒采樣和雙線性插值:這里采用了一種采樣機制對生成的候選區域進行子采樣,因為將所有候選區域發送到進一步的基于LSTM的標簽生成步驟是非常昂貴的,采樣一個
M
=
256
M = 256
M=256大小的小批量,M/2置信度最高的區域為正樣本,M/2最低的區域為負樣本,我們還限制了在一個小批中大部分盒子(框)是正樣本,另一半是負樣本,在測驗階段,采用非最大抑制來選擇最優的M個方案
??為了保證候選區域特征能被全連通層接受,梯度能被反向傳播到輸入特征和盒坐標,使用雙線性插值代替ROI池化層,我們參考雙線性采樣操作,對于頂部的M區域候選,得到
M
×
C
×
X
×
Y
M×C×X×Y
M×C×X×Y特征圖,其中
C
=
512
C = 512
C=512為VGGNet卷積特征圖大小,
X
,
Y
X, Y
X,Y為雙線性采樣網格大小,在我們的例子中,我們設
X
=
Y
=
7
X = Y = 7
X=Y=7.
??3)全連接網路編碼:得到區域特征
M
×
C
×
X
×
Y
M×C×X×Y
M×C×X×Y后,將其發送到由兩個4096-d全連接層組成的基于dropout正則化的全連接網路中,每個區域的特征被扁平化成一個向量,并通過這個全連接網路,因此,每個候選區域被編碼為4096維的特征向量
v
v
v.所有區域全連接特征形成一個小批量
V
=
[
v
1
,
v
2
,
…
v
i
,
…
…
v
M
]
V = [v_1,v_2,…v_i,……v_M]
V=[v1?,v2?,…vi?,……vM?],大小為
M
×
4096
M×4096
M×4096,其中
i
i
i表示第
i
i
i個候選區域.
??圖4顯示了我們的定位層提出的區域和MCG產生的候選區域之間比較結果的一些例子,由我們的模型生成的邊界盒通常更大,其中一些包含多個物件,因此,我們的模型不僅可以探索足夠的標簽依賴,而且在預測小物體和視覺概念方面優于現有的方法,為了顯示定位層的有效性,我們設定了一個基線模型,使用MCG[45]來代替我們的多標簽區域定位層,用于進一步的多標簽分類,

??圖4:MCG生成的前15個區域(左)與我們的定位層(右)對比結果,我們生成的一些區域包含多個物件,例如,生成的區域包含烤箱/微波爐/廚具、人/網球拍、人/風箏/車等物件
B.一個基于LSTM的多標簽生成器
??為了捕獲這些區域中潛在的語意依賴關系,我們使用LSTMs生成每個區域上的標簽概率分布序列,LSTM是一種記憶單元,它在每一個時間步長對所觀察到的輸入資訊進行編碼,圖5給出了LSTM的基本結構,我們讓
σ
σ
σ是sigmoid非線性,LSTM更新的時間步長
t
t
t,給定輸入
x
t
,
h
t
?
1
,
c
t
?
1
x_t, h_{t-1}, c_{t-1}
xt?,ht?1?,ct?1?:
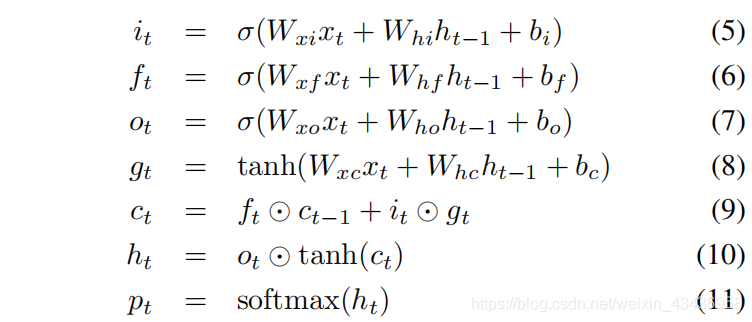
??其中
i
t
,
f
t
,
c
t
,
o
t
i_t, f_t, c_t, o_t
it?,ft?,ct?,ot?是LSTM的輸入,忘記,記憶,輸出狀態,各種
W
W
W矩陣都是訓練過的引數 ,
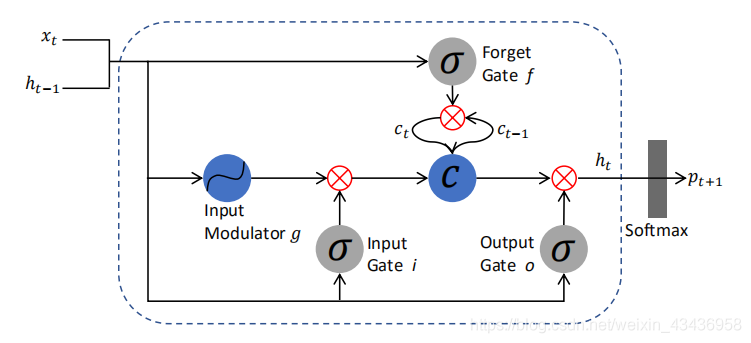
h
t
h_t
ht?是時間步長t的隱藏狀態,并被輸入到Softmax中,它將在所有標簽上產生一個概率分布
p
t
p_t
pt?:
??圖5表示LSTM的結構
??給定一個區域特征向量
v
v
v,設
x
0
=
W
e
v
v
x_0 = W_{ev}v
x0?=Wev?v,其中
W
e
v
W_{ev}
Wev?為可學習的區域特征嵌入權值,由式(5)到式(11),得到一個初始隱藏狀態
h
0
h_0
h0?,可用于下一個時間步.從
t
=
1
t = 1
t=1到
t
=
T
t = T
t=T,設
x
t
=
W
e
s
S
t
x_t = W_{es}S_t
xt?=Wes?St?,隱藏狀態
h
t
?
1
h_{t-1}
ht?1?由上一步給出,其中
W
e
s
W_{es}
Wes?為可學習標簽嵌入權值,T是區域內的標簽數,
S
t
S_t
St?是時間步長
t
t
t處的輸入標簽.實際上,在我們的RLSD模型中,由于在訓練階段(和測驗階段)只提供了全域多標簽的地面真值,不能使用區域的地面真值,我們將
S
t
S_t
St?稱為潛在標簽,可由下式得到:
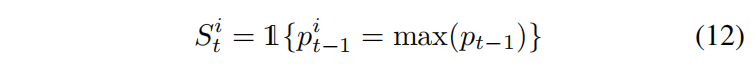
??其中1是一個指標函式,
S
t
S_t
St?是索引
i
=
1
i = 1
i=1的獨熱向量,其他情況則為0.
i
i
i是所有標簽上的概率分布
p
t
?
1
p_{t-1}
pt?1?的最大值的索引,它是通過LSTM前饋程序在前
t
?
1
t-1
t?1時間步計算得到的,在預測一個區域的所有標簽之后,添加一個“END”標簽來完成預測
??將一個小批量中的所有M區域特征(一個小批量中的所有區域都來自同一幅影像)放入到LSTM模型中,我們在每個時間步長t上收集每個區域
m
m
m上的預測
p
t
m
p_{tm}
ptm?,形成一個形狀為
M
×
T
×
L
M×T×L
M×T×L的矩陣,其中
L
L
L為資料集的標簽大小,如果一個區域標簽的長度小于T,我們將填充0.
C.最大池化和損失函式
??為了抑制某些候選區域或某些時間步長的噪聲預測,采用跨區域和時間最大池化的方法將輸出融合為一個綜合預測,設
p
t
m
p_{tm}
ptm?為區域
m
m
m在時間步長
t
t
t的輸出預測,
p
t
m
(
j
)
(
(
j
=
1
,
…
,
L
)
p^{(j)} _{tm}((j = 1,…, L)
ptm(j)?((j=1,…,L)為
p
t
m
p_{tm}
ptm?的第
j
j
j個分量,融合層的最大池可以表示為:
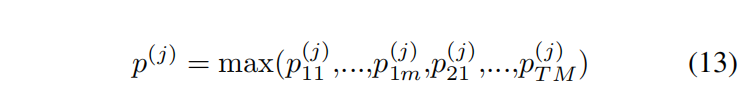
??其中
p
(
j
)
p^{(j)}
p(j)可以認為是給定影像第
j
j
j類的預測值
??最大池融合是RLSD模型對噪聲魯棒性的關鍵步驟.以平方損失為代價函式,將融合層的輸出輸入多路softmax層,定義為:
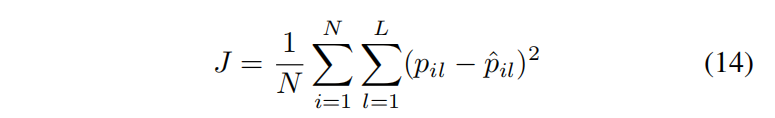
?? 其 中 p i ^ = y i / ∣ ∣ y i ∣ ∣ 1 其中\hat{p_i} = y_i/||y_i||_1 其中pi?^?=yi?/∣∣yi?∣∣1?是第 i i i幅影像的ground-truth概率向量, p i p_i pi?是第 i i i幅影像的預測概率向量.N是影像的數量
??圖6顯示了所提出的測驗影像RLSD模型的示意圖,定位層生成測驗影像的潛在多標簽區域,進一步提取特征并輸入到共享LSTM中,我們可以看到,像“酒杯”、“瓶子”、“花瓶”等小尺寸的物體,由于我們的多標簽定位網路,可以包含在區域內,測驗也以端到端方式執行.
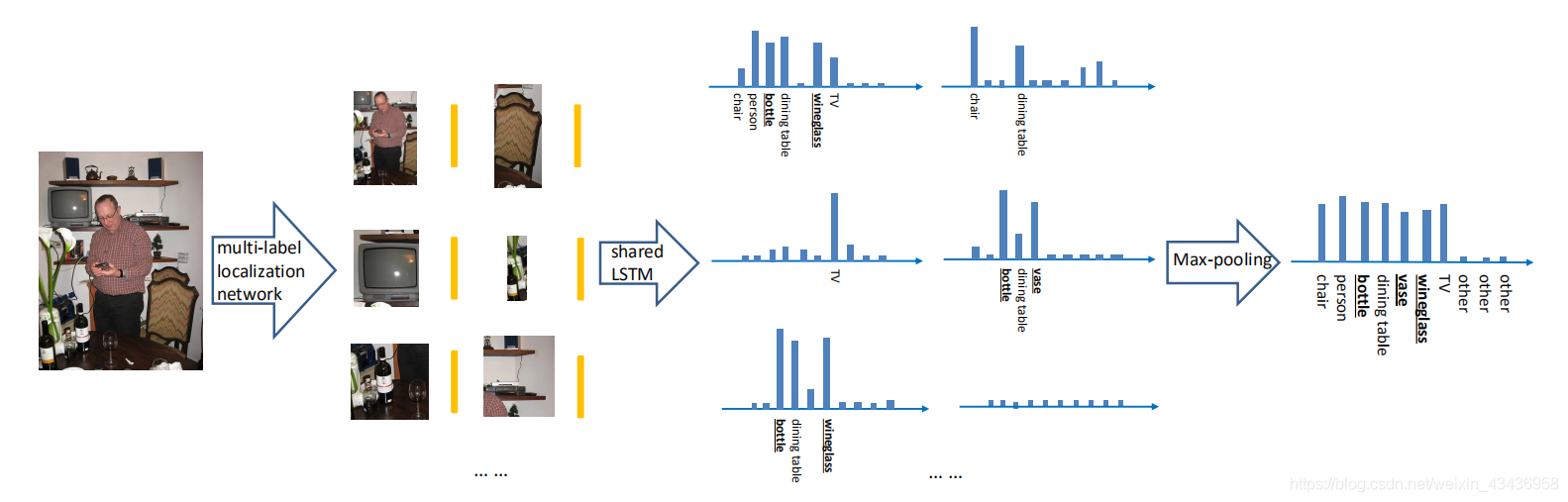
??圖6:測驗影像的RLSD模型示意圖,定位層生成測驗影像的潛在多標簽區域,進一步提取特征并輸入到共享LSTM中,我們可以看到,像“酒杯”、“瓶子”、“花瓶”等小尺寸的物體,由于我們的多標簽定位網路,可以包含在區域內,測驗也以端到端方式執行
D.初始化和預培訓
??我們的模型能夠從頭到尾進行訓練,但是正確的初始化和預訓練機制對于實作良好的性能非常重要,
??a)定位層預訓練:定位層在視徑訓因組區域標題資料集上預先訓練,與其他目標檢測資料集不同的是,該資料集影像中的每個區域通常包含多個目標和視覺概念,非常適合我們的多標簽區域定位任務,
??b) LSTM預訓練:在訓練階段,LSTM首先對全域影像進行預訓練,沒有候選區域,其中每個時間步長都以全域影像標簽作為真實標簽,計算損失,然后使用預先訓練好的LSTM作為我們提出的RLSD模式下區域LSTM的初始化,我們發現初始化程序對模型快速收斂非常重要
4.實驗
??在這一節中,我們給出了我們的實驗結果和分析來證明我們提出的RLSD模型在多標簽影像分類問題上的有效性.我們在三個基準資料集上評估了提出的模型:VOC PASCAL 2007 [48], Microsoft COCO[49]和NUS-WIDE[50],通過與幾種最先進的模型和基線模型的比較,我們表明我們提出的RLSD模型取得了最好的性能,我們進一步分析了精確度-召回率和邊界盒的大小,表明我們的模型特別擅長預測小的物件,
4.1 評價指標
??我們使用的評價指標:計算預測標簽的精度和召回率,對于每個測驗影像,我們預測k個排名最高的標簽,并與影像的ground-truth進行比較,精確度是正確標注標簽的數量除以預測標簽的數量;召回率是正確標注標簽的數量除以地面真實值標簽的數量,我們根據下述的公式計算總體精度和召回率(op & or)和每級精度和召回率(cp & cr),我們還計算了用于比較的平均平均精度(mAP):
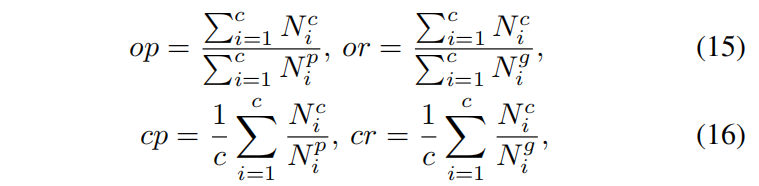
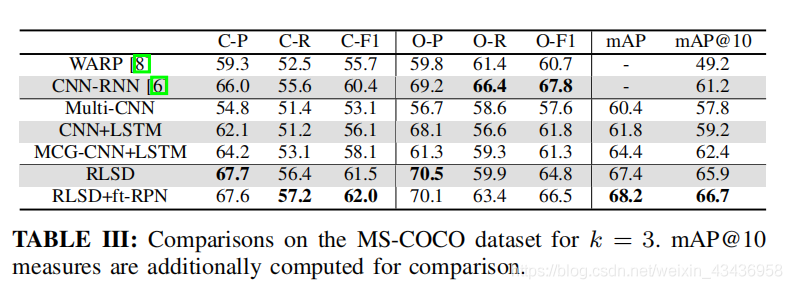
4.2 在Microsoft COCO的實驗結果
??Microsoft COCO dataset[49]是一個大規模的基準資料集,用于幾個視覺任務,總共有123,287張影像用于訓練和驗證,其中注釋了80個物件概念.我們使用一幅影像中所有標注的物件標簽作為多標簽的地真,以其訓練集作為訓練資料,以驗證集作為測驗資料.去除沒有標注的影像后,我們有82081張訓練影像和40137張測驗影像,我們通過計算這些標簽的共現率來獲得這些標簽的語意依賴性,并將其形成一個矩陣.我們發現它的標簽集有很強的依賴性,例如鍵盤和計算機總是同時出現:
5.結論
??多標簽影像分類是多媒體領域的一個重要問題,因為它不僅比單標簽影像分類更具挑戰性,而且更接近于現實應用,在本文中,我們提出了一個區域潛在語意依賴(RLSD)模型來解決這個問題,顧名思義,該模型可以捕獲區域級別上的標簽依賴關系,在幾個基準資料集上的實驗結果表明,提出的RLSD模型始終能夠取得優于現有方法的整體性能,特別是在預測影像中的小目標和視覺概念方面
??在未來,我們將研究以無監督的方式定位多標簽區域,注意機制在這種情況下可以被重視,因為它可以用來建模標簽之間的空間關系,我們將在未來的作業中將注意力機制與我們提出的區域潛在語意依賴模型結合起來,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/202227.html
標籤:其他
下一篇:軟考