作者|David Woroniuk
編譯|VK
來源|Towards Data Science
什么是例外
例外,通常稱為例外值,是指資料中不符合資料系列總體行為的資料點、資料序列或模式,因此,例外檢測就是檢測不符合更廣泛資料中的模式的資料點或序列的任務,
對例外資料的有效檢測和洗掉對于許多業務功能非常有用,如檢測嵌入在網站中的破損鏈接、互聯網流量峰值或股價的劇烈變化,將這些現象標記為例外值,或制定預先計劃的應對措施,可以節省企業的時間和資金,
例外型別
通常情況下,例外資料可以分為三類:加性例外值、時間變化例外值或水平變化例外值,
加性例外值的特點是價值突然大幅增加或減少,這可能是由外生或內生因素驅動的,加性例外值的例子可能是由于電視節目的出現而導致網站流量的大幅增長(外因),或者由于強勁的季度業績而導致股票交易量的短期增長(內因),
時間變化例外值的特點是一個短序列,它不符合資料中更廣泛的趨勢,例如,如果一個網站服務器崩潰,在一系列資料點上,網站流量將降為零,直到服務器重新啟動,此時流量將恢復正常,
水平變化例外值是商品市場的常見現象,因為商品市場對電力的高需求與惡劣的天氣條件有著內在的聯系,因此我們可以觀察到夏季和冬季電價之間的“水平變化”,這是由天氣驅動的需求變化和可再生能源發電變化造成的,
什么是自編碼器
自動編碼器是設計用來學習給定輸入的低維表示的神經網路,自動編碼器通常由兩個部分組成:一個編碼器學習將輸入資料映射到低維表示,另一個解碼器學習將表示映射回輸入資料,
由于這種結構,編碼器網路迭代學習一個有效的資料壓縮函式,該函式將資料映射到低維表示,經過訓練,譯碼器能夠成功地重建原始輸入資料,重建誤差(譯碼器產生的輸入和重構輸出之間的差異)是整個訓練程序的目標函式,
實作
既然我們了解了自動編碼器模型的底層架構,我們就可以開始實作該模型了,
第一步是安裝我們將使用的庫、包和模塊:
# 資料處理:
import numpy as np
import pandas as pd
from datetime import date, datetime
# RNN自編碼器:
from tensorflow import keras
from tensorflow.keras import layers
# 繪圖:
!pip install chart-studio
import plotly.graph_objects as go
其次,我們需要獲得一些資料進行分析,本文使用歷史加密軟體包獲取2013年6月6日至今的位元幣歷史資料,下面的代碼還生成每日位元幣回報率和日內價格波動率,然后洗掉任何丟失的資料行并回傳資料幀的前5行,
# 匯入 Historic Crypto 包:
!pip install Historic-Crypto
from Historic_Crypto import HistoricalData
# 獲取位元幣資料,計算收益和日內波動:
dataset = HistoricalData(start_date = '2013-06-06',ticker = 'BTC').retrieve_data()
dataset['Returns'] = dataset['Close'].pct_change()
dataset['Volatility'] = np.abs(dataset['Close']- dataset['Open'])
dataset.dropna(axis = 0, how = 'any', inplace = True)
dataset.head()
既然我們已經獲得了一些資料,我們應該直觀地掃描每個序列中潛在的例外值,下面的plot_dates_values函式可以迭代繪制資料幀中包含的每個序列,
def plot_dates_values(data_timestamps, data_plot):
'''
這個函式提供輸入序列的平面圖
Arguments:
data_timestamps: 與每個資料實體關聯的時間戳,
data_plot: 要繪制的資料序列,
Returns:
fig: 用滑塊和按鈕顯示序列的圖形,
'''
fig = go.Figure()
fig.add_trace(go.Scatter(x = data_timestamps, y = data_plot,
mode = 'lines',
name = data_plot.name,
connectgaps=True))
fig.update_xaxes(
rangeslider_visible=True,
rangeselector=dict(
buttons=list([
dict(count=1, label="YTD", step="year", stepmode="todate"),
dict(count=1, label="1 Years", step="year", stepmode="backward"),
dict(count=2, label="2 Years", step="year", stepmode="backward"),
dict(count=3, label="3 Years", step="year", stepmode="backward"),
dict(label="All", step="all")
])))
fig.update_layout(
title=data_plot.name,
xaxis_title="Date",
yaxis_title="",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
我們現在可以反復呼叫上述函式,生成位元幣的成交量、收盤價、開盤價、波動率和收益率曲線圖,
plot_dates_values(dataset.index, dataset['Volume'])
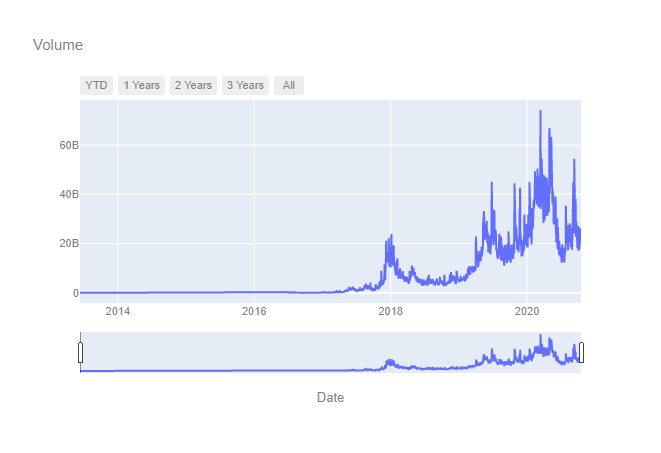
值得注意的是,2020年出現了一些交易量的峰值,調查這些峰值是否例外或預示著更廣泛的序列可能是有用的,
plot_dates_values(dataset.index, dataset['Close'])
.png)
2018年收盤價出現了一個明顯的上漲,隨后下跌至技術支撐水平,然而,一個向上的趨勢在整個資料中普遍存在,
plot_dates_values(dataset.index, dataset['Open'])
.png)
每日開盤價與上述收盤價走勢相似,
plot_dates_values(dataset.index, dataset['Volatility'])
.png)
2018年的價格和波動性都很明顯,因此,我們可以研究這些波動率峰值是否被自編碼器模型視為例外,
plot_dates_values(dataset.index, dataset['Returns'])
.png)
由于收益序列的隨機性,我們選擇測驗位元幣日交易量中的例外值,以交易量為特征,
因此,我們可以開始自動編碼器模型的資料預處理,資料預處理的第一步是確定訓練資料和測驗資料之間的適當分割,下面概述的generate_train_test_split功能可以按日期分割訓練和測驗資料,在呼叫下面的函式時,將生成兩個資料幀,即訓練資料和測驗資料作為全域變數,
def generate_train_test_split(data, train_end, test_start):
'''
此函式通過使用字串將資料集分解為訓練資料和測驗資料,作為'train_end'和'test_start'引數提供的字串必須是連續的天,
Arguments:
data: 資料分割為訓練資料和測驗資料,
train_end: 訓練資料結束的日期(str),
test_start: 測驗資料開始的日期(str),
Returns:
training_data: 模型訓練中使用的資料(Pandas DataFrame),
testing_data: 模型測驗中使用的資料(panda DataFrame),
'''
if isinstance(train_end, str) is False:
raise TypeError("train_end argument should be a string.")
if isinstance(test_start, str) is False:
raise TypeError("test_start argument should be a string.")
train_end_datetime = datetime.strptime(train_end, '%Y-%m-%d')
test_start_datetime = datetime.strptime(test_start, '%Y-%m-%d')
while train_end_datetime >= test_start_datetime:
raise ValueError("train_end argument cannot occur prior to the test_start argument.")
while abs((train_end_datetime - test_start_datetime).days) > 1:
raise ValueError("the train_end argument and test_start argument should be seperated by 1 day.")
training_data = https://www.cnblogs.com/panchuangai/archive/2020/11/04/data[:train_end]
testing_data = data[test_start:]
print('Train Dataset Shape:',training_data.shape)
print('Test Dataset Shape:',testing_data.shape)
return training_data, testing_data
# 我們現在呼叫上面的函式,生成訓練和測驗資料
training_data, testing_data = https://www.cnblogs.com/panchuangai/archive/2020/11/04/generate_train_test_split(dataset,'2018-12-31','2019-01-01')
為了提高模型的準確性,我們可以對資料進行“標準化”或縮放,此函式可縮放上面生成的訓練資料幀,保存訓練平均值和訓練標準,以便以后對測驗資料進行標準化,
注:對訓練和測驗資料進行同等級別的縮放是很重要的,否則規模的差異將產生可解釋性問題和模型不一致,
def normalise_training_values(data):
'''
這個函式用平均值和標準差對輸入值進行規格化,
Arguments:
data: 要標準化的DataFrame列,
Returns:
values: 用于模型訓練的歸一化資料(numpy陣列),
mean: 訓練集mean,用于標準化測驗集(float),
std: 訓練集的標準差,用于標準化測驗集(float),
'''
if isinstance(data, pd.Series) is False:
raise TypeError("data argument should be a Pandas Series.")
values = data.to_list()
mean = np.mean(values)
values -= mean
std = np.std(values)
values /= std
print("*"*80)
print("The length of the training data is: {}".format(len(values)))
print("The mean of the training data is: {}".format(mean.round(2)))
print("The standard deviation of the training data is {}".format(std.round(2)))
print("*"*80)
return values, mean, std
# 現在呼叫上面的函式:
training_values, training_mean, training_std = normalise_training_values(training_data['Volume'])
正如我們在上面所說的normalise_training_values函式,我們現在有一個numpy陣列,其中包含稱為training_values的標準化訓練資料,我們已經將training_mean和training_std存盤為全域變數,用于標準化測驗集,
我們現在可以開始生成一系列序列,這些序列可以用來訓練自動編碼器模型,我們定義視窗大小30,提供一個形狀的3D訓練資料(2004,30,1):
# 定義每個序列的時間步數:
TIME_STEPS = 30
def generate_sequences(values, time_steps = TIME_STEPS):
'''
這個函式生成要傳遞給模型的長度序列'TIME_STEPS',
Arguments:
values: 生成序列(numpy陣列)的標準化值,
time_steps: 序列的長度(int),
Returns:
train_data: 用于模型訓練的3D資料(numpy array),
'''
if isinstance(values, np.ndarray) is False:
raise TypeError("values argument must be a numpy array.")
if isinstance(time_steps, int) is False:
raise TypeError("time_steps must be an integer object.")
output = []
for i in range(len(values) - time_steps):
output.append(values[i : (i + time_steps)])
train_data = https://www.cnblogs.com/panchuangai/archive/2020/11/04/np.expand_dims(output, axis =2)
print("Training input data shape: {}".format(train_data.shape))
return train_data
# 現在呼叫上面的函式生成x_train:
x_train = generate_sequences(training_values)
現在我們已經完成了訓練資料的處理,我們可以定義自動編碼器模型,然后將模型擬合到訓練資料上,define_model函式使用訓練資料形狀定義適當的模型,回傳自編碼器模型和自編碼器模型的摘要,
def define_model(x_train):
'''
這個函式使用x_train的維度來生成RNN模型,
Arguments:
x_train: 用于模型訓練的3D資料(numpy array),
Returns:
model: 模型架構(Tensorflow物件),
model_summary: 模型架構的摘要,
'''
if isinstance(x_train, np.ndarray) is False:
raise TypeError("The x_train argument should be a 3 dimensional numpy array.")
num_steps = x_train.shape[1]
num_features = x_train.shape[2]
keras.backend.clear_session()
model = keras.Sequential(
[
layers.Input(shape=(num_steps, num_features)),
layers.Conv1D(filters=32, kernel_size = 15, padding = 'same', data_format= 'channels_last',
dilation_rate = 1, activation = 'linear'),
layers.LSTM(units = 25, activation = 'tanh', name = 'LSTM_layer_1',return_sequences= False),
layers.RepeatVector(num_steps),
layers.LSTM(units = 25, activation = 'tanh', name = 'LSTM_layer_2', return_sequences= True),
layers.Conv1D(filters = 32, kernel_size = 15, padding = 'same', data_format = 'channels_last',
dilation_rate = 1, activation = 'linear'),
layers.TimeDistributed(layers.Dense(1, activation = 'linear'))
]
)
model.compile(optimizer=keras.optimizers.Adam(learning_rate = 0.001), loss = "mse")
return model, model.summary()
隨后,model_fit函式在內部呼叫define_model函式,然后向模型提供epochs、batch_size和validation_loss引數,然后呼叫此函式,開始模型訓練程序,
def model_fit():
'''
這個函式呼叫上面的'define_model()'函式,然后根據x_train資料對模型進行訓練,
Arguments:
N/A.
Returns:
model: 訓練好的模型,
history: 模型如何訓練的摘要(訓練錯誤,驗證錯誤),
'''
# 在x_train上呼叫上面的define_model函式:
model, summary = define_model(x_train)
history = model.fit(
x_train,
x_train,
epochs=400,
batch_size=128,
validation_split=0.1,
callbacks=[keras.callbacks.EarlyStopping(monitor="val_loss",
patience=25,
mode="min",
restore_best_weights=True)])
return model, history
# 呼叫上面的函式,生成模型和模型的歷史:
model, history = model_fit()
一旦對模型進行了訓練,就必須繪制訓練和驗證損失曲線,以了解模型是否存在偏差(欠擬合)或方差(過擬合),這可以通過呼叫下面的plot_training_validation_loss函式來觀察,
def plot_training_validation_loss():
'''
這個函式繪制了訓練模型的訓練和驗證損失曲線,可以對欠擬合或過擬合進行可視化診斷,
Arguments:
N/A.
Returns:
fig:模型的訓練損失和驗證的可視化表示
'''
training_validation_loss = pd.DataFrame.from_dict(history.history, orient='columns')
fig = go.Figure()
fig.add_trace(go.Scatter(x = training_validation_loss.index, y = training_validation_loss["loss"].round(6),
mode = 'lines',
name = 'Training Loss',
connectgaps=True))
fig.add_trace(go.Scatter(x = training_validation_loss.index, y = training_validation_loss["val_loss"].round(6),
mode = 'lines',
name = 'Validation Loss',
connectgaps=True))
fig.update_layout(
title='Training and Validation Loss',
xaxis_title="Epoch",
yaxis_title="Loss",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
# 呼叫上面的函式:
plot_training_validation_loss()
.png)
值得注意的是,訓練和驗證損失曲線在整個圖表中都在收斂,驗證損失仍然略大于訓練損失,在給定形狀誤差和相對誤差的情況下,我們可以確定自動編碼器模型不存在欠擬合或過擬合,
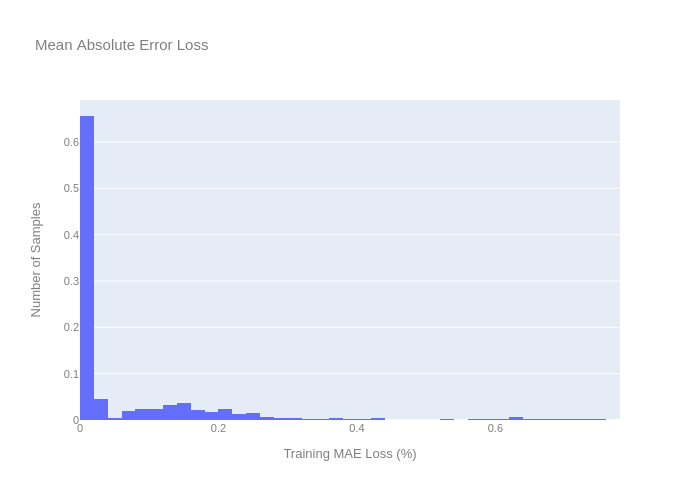
現在,我們可以定義重建誤差,這是自動編碼器模型的核心原理之一,重建誤差表示為訓練損失,重建誤差閾值為訓練損失的最大值,因此,在計算試驗誤差時,任何大于訓練損失最大值的值都可以視為例外值,
def reconstruction_error(x_train):
'''
這個函式計算重建誤差,并顯示訓練平均絕對誤差的直方圖
Arguments:
x_train: 用于模型訓練的3D資料(numpy array),
Returns:
fig: 訓練MAE分布的可視化圖,
'''
if isinstance(x_train, np.ndarray) is False:
raise TypeError("x_train argument should be a numpy array.")
x_train_pred = model.predict(x_train)
global train_mae_loss
train_mae_loss = np.mean(np.abs(x_train_pred - x_train), axis = 1)
histogram = train_mae_loss.flatten()
fig =go.Figure(data = https://www.cnblogs.com/panchuangai/archive/2020/11/04/[go.Histogram(x = histogram,
histnorm ='probability',
name = 'MAE Loss')])
fig.update_layout(
title='Mean Absolute Error Loss',
xaxis_title="Training MAE Loss (%)",
yaxis_title="Number of Samples",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
print("*"*80)
print("Reconstruction error threshold: {} ".format(np.max(train_mae_loss).round(4)))
print("*"*80)
return fig.show()
# 呼叫上面的函式:
reconstruction_error(x_train)
在上面,我們將training_mean和training_std保存為全域變數,以便將它們用于縮放測驗資料,我們現在定義normalise_testing_values函式來縮放測驗資料,
def normalise_testing_values(data, training_mean, training_std):
'''
該函式使用訓練平均值和標準差對測驗資料進行歸一化,生成一個測驗值的numpy陣列,
Arguments:
data: 使用的資料(panda DataFrame列)
mean: 訓練集平均值(浮點數),
std: 訓練集標準差(float),
Returns:
values: 陣列 (numpy array).
'''
if isinstance(data, pd.Series) is False:
raise TypeError("data argument should be a Pandas Series.")
values = data.to_list()
values -= training_mean
values /= training_std
print("*"*80)
print("The length of the testing data is: {}".format(data.shape[0]))
print("The mean of the testing data is: {}".format(data.mean()))
print("The standard deviation of the testing data is {}".format(data.std()))
print("*"*80)
return values
隨后,在testing_data的Volume列上呼叫此函式,因此,test_value被具體化為numpy陣列,
# 呼叫上面的函式:
test_value = https://www.cnblogs.com/panchuangai/archive/2020/11/04/normalise_testing_values(testing_data['Volume'], training_mean, training_std)
在此基礎上,定義了生成測驗損失函式,計算了重構資料與測驗資料之間的差異,如果任何值大于訓練最大損失值,則將其存盤在全域例外串列中,
def generate_testing_loss(test_value):
'''
這個函式使用模型來預測測驗集中的例外情況,此外,該函式生成“例外”全域變數,包含由RNN識別的例外值,
Arguments:
test_value: 測驗的陣列(numpy陣列),
Returns:
fig: 訓練MAE分布的可視化圖,
'''
x_test = generate_sequences(test_value)
print("*"*80)
print("Test input shape: {}".format(x_test.shape))
x_test_pred = model.predict(x_test)
test_mae_loss = np.mean(np.abs(x_test_pred - x_test), axis = 1)
test_mae_loss = test_mae_loss.reshape((-1))
global anomalies
anomalies = (test_mae_loss >= np.max(train_mae_loss)).tolist()
print("Number of anomaly samples: ", np.sum(anomalies))
print("Indices of anomaly samples: ", np.where(anomalies))
print("*"*80)
histogram = test_mae_loss.flatten()
fig =go.Figure(data = https://www.cnblogs.com/panchuangai/archive/2020/11/04/[go.Histogram(x = histogram,
histnorm ='probability',
name = 'MAE Loss')])
fig.update_layout(
title='Mean Absolute Error Loss',
xaxis_title="Testing MAE Loss (%)",
yaxis_title="Number of Samples",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
# 呼叫上面的函式:
generate_testing_loss(test_value)
此外,還介紹了MAE的分布,并與MAE的直接損失進行了比較,
.png)
最后,例外值在下面直觀地表示出來,
def plot_outliers(data):
'''
這個函式決定了時間序列中離群點的位置,這些離群點被依次繪制出來,
Arguments:
data: 初始資料集(Pandas DataFrame),
Returns:
fig: 由RNN確定的序列中出現的例外值的可視化表示,
'''
outliers = []
for data_idx in range(TIME_STEPS -1, len(test_value) - TIME_STEPS + 1):
time_series = range(data_idx - TIME_STEPS + 1, data_idx)
if all([anomalies[j] for j in time_series]):
outliers.append(data_idx + len(training_data))
outlying_data = https://www.cnblogs.com/panchuangai/archive/2020/11/04/data.iloc[outliers, :]
cond = data.index.isin(outlying_data.index)
no_outliers = data.drop(data[cond].index)
fig = go.Figure()
fig.add_trace(go.Scatter(x = no_outliers.index, y = no_outliers["Volume"],
mode = 'markers',
name = no_outliers["Volume"].name,
connectgaps=False))
fig.add_trace(go.Scatter(x = outlying_data.index, y = outlying_data["Volume"],
mode = 'markers',
name = outlying_data["Volume"].name + ' Outliers',
connectgaps=False))
fig.update_xaxes(rangeslider_visible=True)
fig.update_layout(
title='Detected Outliers',
xaxis_title=data.index.name,
yaxis_title=no_outliers["Volume"].name,
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
# 呼叫上面的函式:
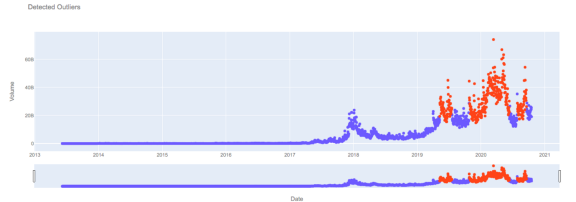
plot_outliers(dataset)
以自動編碼器模型為特征的邊遠資料用橙色表示,而一致性資料用藍色表示,
.png)
我們可以看到,2020年位元幣交易量資料的很大一部分被認為是例外的——可能是由于Covid-19推動的零售交易活動增加?
嘗試自動編碼器引數和新的資料集,看看你是否能在位元幣收盤價中發現任何例外,或者使用歷史加密庫下載不同的加密貨幣!
原文鏈接:https://towardsdatascience.com/outlier-detection-with-rnn-autoencoders-b82e2c230ed9
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/202805.html
標籤:其他