作者|Vagif Aliyev
編譯|VK
來源|Towards Data Science

線性回歸可能是最常見的演算法之一,線性回歸是機器學習實踐者必須知道的,這通常是初學者第一次接觸的機器學習演算法,了解它的操作方式對于更好地理解它至關重要,
所以,簡單地說,讓我們來分解一下真正的問題:什么是線性回歸?
線性回歸定義
線性回歸是一種有監督的學習演算法,旨在采用線性方法來建模因變數和自變數之間的關系,換句話說,它的目標是擬合一條最好地捕捉資料關系的線性趨勢線,并且,從這條線,它可以預測目標值可能是什么,
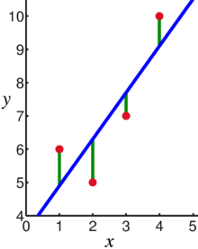
太好了,我知道它的定義,但它是如何作業的呢?好問題!為了回答這個問題,讓我們逐步了解一下線性回歸是如何運作的:
-
擬合資料(如上圖所示),
-
計算點之間的距離(圖上的紅點是點,綠線是距離),然后求平方,然后求和(這些值是平方的,以確保負值不會產生錯誤的值并阻礙計算),這是演算法的誤差,或者更好地稱為殘差
-
存盤迭代的殘差
-
基于一個優化演算法,使得該線稍微“移動”,以便該線可以更好地擬合資料,
-
重復步驟2-5,直到達到理想的結果,或者剩余誤差減小到零,
這種擬合直線的方法稱為最小二乘法,
線性回歸背后的數學
如果已經理解的請隨意跳過這一部分
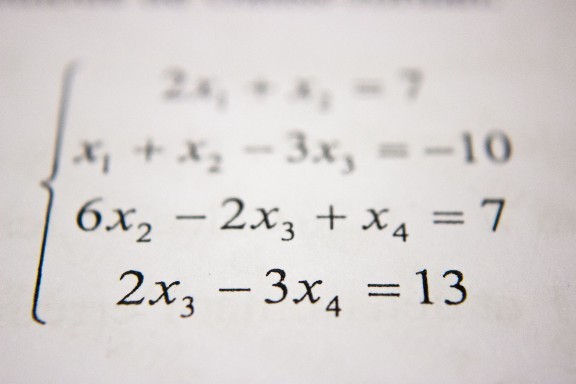
線性回歸演算法如下:
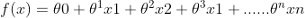
可以簡化為:
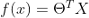
以下演算法將基本完成以下操作:
- 接受一個Y向量(你的資料標簽,(房價,股票價格,等等…)
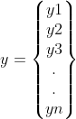
這是你的目標向量,稍后將用于評估你的資料(稍后將詳細介紹),
- 矩陣X(資料的特征):
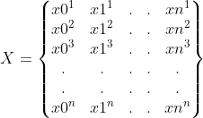
這是資料的特征,即年齡、性別、性別、身高等,這是演算法將實際用于預測的資料,注意如何有一個特征0,這稱為截距項,且始終等于1,
- 取一個權重向量,并將其轉置:
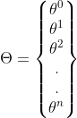
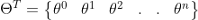
這是演算法的神奇之處,所有的特征向量都會乘以這些權重,這就是所謂的點積,實際上,你將嘗試為給定的資料集找到這些值的最佳組合,這就是所謂的優化,
- 得到輸出向量:
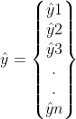
這是從資料中輸出的預測向量,然后,你可以使用成本函式來評估模型的性能,
這基本上就是用數學表示的整個演算法,現在你應該對線性回歸的功能有一個堅實的理解,但問題是,什么是優化演算法?我們如何選擇最佳權重?我們如何評估績效?
成本函式
成本函式本質上是一個公式,用來衡量模型的損失或“成本”,如果你曾經參加過任何Kaggle比賽,你可能會遇到過一些,一些常見的方法包括:
-
均方誤差
-
均方根誤差
-
平均絕對誤差
這些函式對于模型訓練和開發是必不可少的,因為它們回答了“我的模型預測新實體的能力如何”這一基本問題?”. 請記住這一點,因為這與我們的下一個主題有關,
優化演算法
優化通常被定義為改進某事物,使其發揮其全部潛力的程序,這也適用于機器學習,在ML的世界里,優化本質上是試圖為某個資料集找到最佳的引陣列合,這基本上是機器學習的“學習”部分,
我將討論兩種最常見的演算法:梯度下降法和標準方程,
梯度下降
梯度下降是一種優化演算法,旨在尋找函式的最小值,它通過在梯度的負方向上迭代地采取步驟來實作這個目標,在我們的例子中,梯度下降將通過移動函式切線的斜率來不斷更新權重,
梯度下降的一個具體例子

為了更好地說明梯度下降,讓我們看一個簡單的例子,想象一個人在山頂上,他/她想爬到山底,他們可能會做的是環顧四周,看看應該朝哪個方向邁出一步,以便更快地下來,然后,他們可能會朝這個方向邁出一步,現在他們離目標更近了,然而,它們在下降時必須小心,因為它們可能會在某一點卡住,所以我們必須確保相應地選擇我們的步長,
同樣,梯度下降的目標是最小化函式,在我們的例子中,這是為了使我們的模型的成本最小化,它通過找到函式的切線并朝那個方向移動來實作這一點,演算法“步長”的大小是由已知的學習速率來定義的,這基本上控制著我們向下移動的距離,使用此引數,我們必須注意兩種情況:
-
學習速率太大,演算法可能無法收斂(達到最小值)并在最小值附近反彈,但永遠不會達到該值
-
學習率太小,演算法將花費太長時間才能達到最小值,也可能會“卡”在一個次優點上,
我們還有一個引數,它控制演算法迭代資料集的次數,
從視覺上看,該演算法將執行以下操作:
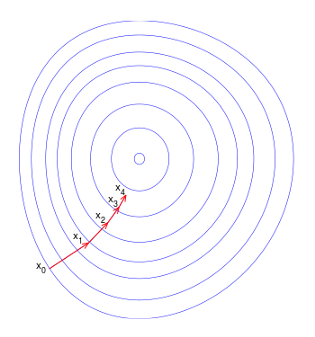
由于此演算法對機器學習非常重要,讓我們回顧一下它的作用:
-
隨機初始化權重,這叫做隨機初始化
-
然后,模型使用這些隨機權重進行預測
-
模型的預測是通過成本函式來評估的
-
然后模型運行梯度下降,找到函式的切線,然后在切線的斜率上邁出一步
-
該程序將重復N次迭代,或者如果滿足某個條件,
梯度下降法的優缺點
優點:
-
很可能將成本函式降低到全域最小值(非常接近或=0)
-
最有效的優化演算法之一
缺點:
-
在大型資料集上可能比較慢,因為它使用整個資料集來計算函式切線的梯度
-
容易陷入次優點(或區域極小值)
-
用戶必須手動選擇學習速率和迭代次數,這可能很耗時
既然已經介紹了梯度下降,現在我們來介紹標準方程,
標準方程(Normal Equation)
如果我們回到我們的例子中,而不是一步一步地往下走,我們將能夠立即到達底部,標準方程就是這樣,它利用線性代數來生成權重,可以在很短的時間內產生和梯度下降一樣好的結果,
標準方程的優缺點
優點
-
無需選擇學習速率或迭代次數
-
非常快
缺點
-
不能很好地擴展到大型資料集
-
傾向于產生好的權重,但不是最佳權重

特征縮放
這是許多機器學習演算法的重要預處理步驟,尤其是那些使用距離度量和計算(如線性回歸和梯度下降)的演算法,它本質上是縮放我們的特征,使它們在相似的范圍內,把它想象成一座房子,一座房子的比例模型,兩者的形狀是一樣的(他們都是房子),但大小不同(5米!=500米),我們這樣做的原因如下:
-
它加快了演算法的速度
-
有些演算法對尺度敏感,換言之,如果特征具有不同的尺度,則有可能將更高的權重賦予具有更高量級的特征,這將影響機器學習演算法的性能,顯然,我們不希望我們的演算法偏向于一個特征,
為了演示這一點,假設我們有三個特征,分別命名為A、B和C:
- 縮放前AB距離=>
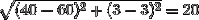
- 縮放前BC距離=>
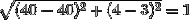
- 縮放后AB距離=>
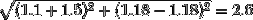
- 縮放后BC的距離=>
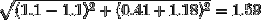
我們可以清楚地看到,這些特征比縮放之前更具可比性和無偏性,
從頭開始撰寫線性回歸

好吧,現在你一直在等待的時刻;實作!
注意:所有代碼都可以從這個Github repo下載,但是,我建議你在執行此操作之前先遵循教程,因為這樣你將更好地理解你實際在撰寫什么代碼:
https://github.com/Vagif12/ML-Algorithms-From-Scratch/blob/main/Linear Regression from Scratch.ipynb
首先,讓我們做一些基本的匯入:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
是的,這就是所有需要匯入的了!我們使用的是numpy作為數學實作,matplotlib用于繪制圖形,以及scikitlearn的boston資料集,
# 加載和拆分資料
data = https://www.cnblogs.com/panchuangai/archive/2020/11/04/load_boston()
X,y = data['data'],data['target']
接下來,讓我們創建一個定制的train_test_split函式,將我們的資料拆分為一個訓練和測驗集:
# 拆分訓練和測驗集
def train_test_divide(X,y,test_size=0.3,random_state=42):
np.random.seed(random_state)
train_size = 1 - test_size
arr_rand = np.random.rand(X.shape[0])
split = arr_rand < np.percentile(arr_rand,(100*train_size))
X_train = X[split]
y_train = y[split]
X_test = X[~split]
y_test = y[~split]
return X_train, X_test, y_train, y_test
X_train,X_test,y_train,y_test = train_test_divide(X,y,test_size=0.3,random_state=42)
基本上,我們在進行
-
得到測驗集大小,
-
設定一個隨機種子,以確保我們的結果和可重復性,
-
根據測驗集大小得到訓練集大小
-
從我們的特征中隨機抽取樣本
-
將隨機選擇的實體拆分為訓練集和測驗集
我們的成本函式
我們將實作MSE或均方誤差,一個用于回歸任務的常見成本函式:
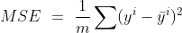
def mse(preds,y):
m = len(y)
return 1/(m) * np.sum(np.square((y - preds)))
-
M指的是訓練實體的數量
-
yi指的是我們標簽向量中的一個實體
-
preds指的是我們的預測
為了撰寫干凈、可重復和高效的代碼,并遵守軟體開發實踐,我們將創建一個線性回歸類:
class LinReg:
def __init__(self,X,y):
self.X = X
self.y = y
self.m = len(y)
self.bgd = False
- bgd是一個引數,它定義我們是否應該使用批量梯度下降,
現在我們將創建一個方法來添加截距項:
def add_intercept_term(self,X):
X = np.insert(X,1,np.ones(X.shape[0:1]),axis=1).copy()
return X
這基本上是在我們的特征開始處插入一個列,它只是為了矩陣乘法,
如果我們不加上這一點,那么我們將迫使超平面通過原點,導致它大幅度傾斜,從而無法正確擬合資料
縮放我們的特征:
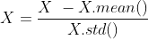
def feature_scale(self,X):
X = (X - X.mean()) / (X.std())
return X
接下來,我們將隨機初始化權重:
def initialise_thetas(self):
np.random.seed(42)
self.thetas = np.random.rand(self.X.shape[1])
現在,我們將使用以下公式從頭開始撰寫標準方程:
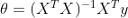
def normal_equation(self):
A = np.linalg.inv(np.dot(self.X.T,self.X))
B = np.dot(self.X.T,self.y)
thetas = np.dot(A,B)
return thetas
基本上,我們將演算法分為三個部分:
-
我們得到了X轉置后與X的點積的逆
-
我們得到重量和標簽的點積
-
我們得到兩個計算值的點積
這就是標準方程!還不錯!現在,我們將使用以下公式實作批量梯度下降:
def batch_gradient_descent(self,alpha,n_iterations):
self.cost_history = [0] * (n_iterations)
self.n_iterations = n_iterations
for i in range(n_iterations):
h = np.dot(self.X,self.thetas.T)
gradient = alpha * (1/self.m) * ((h - self.y)).dot(self.X)
self.thetas = self.thetas - gradient
self.cost_history[i] = mse(np.dot(self.X,self.thetas.T),self.y)
return self.thetas
在這里,我們執行以下操作:
-
我們設定alpha,或者學習率,和迭代次數
-
我們創建一個串列來存盤我們的成本函式歷史記錄,以便以后在折線圖中繪制
-
回圈n_iterations 次,
-
我們得到預測,并計算梯度(函式切線的斜率),
-
我們更新權重以沿梯度負方向移動
-
我們使用我們的自定義MSE函式記錄值
-
重復,完成后,回傳結果
讓我們定義一個擬合函式來擬合我們的資料:
def fit(self,bgd=False,alpha=0.158,n_iterations=4000):
self.X = self.add_intercept_term(self.X)
self.X = self.feature_scale(self.X)
if bgd == False:
self.thetas = self.normal_equation()
else:
self.bgd = True
self.initialise_thetas()
self.thetas = self.batch_gradient_descent(alpha,n_iterations)
在這里,我們只需要檢查用戶是否需要梯度下降,并相應地執行我們的步驟,
讓我們構建一個函式來繪制成本函式:
def plot_cost_function(self):
if self.bgd == True:
plt.plot(range((self.n_iterations)),self.cost_history)
plt.xlabel('No. of iterations')
plt.ylabel('Cost Function')
plt.title('Gradient Descent Cost Function Line Plot')
plt.show()
else:
print('Batch Gradient Descent was not used!')
最后一種預測未標記實體的方法:
def predict(self,X_test):
self.X_test = X_test.copy()
self.X_test = self.add_intercept_term(self.X_test)
self.X_test = self.feature_scale(self.X_test)
predictions = np.dot(self.X_test,self.thetas.T)
return predictions
現在,讓我們看看哪個優化產生了更好的結果,首先,讓我們試試梯度下降:
lin_reg_bgd = LinReg(X_train,y_train)
lin_reg_bgd.fit(bgd=True)
mse(y_test,lin_reg_bgd.predict(X_test))
OUT:
28.824024414708344
讓我們畫出我們的函式,看看成本函式是如何減少的:
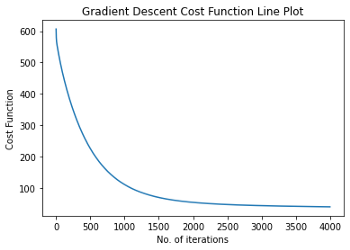
所以我們可以看到,在大約1000次迭代時,它開始收斂,
現在的標準方程是:
lin_reg_normal = LinReg(X_train,y_train)
lin_reg_normal.fit()
mse(y_test,lin_reg_normal.predict(X_test))
OUT:
22.151417764247284
所以我們可以看到,標準方程的性能略優于梯度下降法,這可能是因為資料集很小,而且我們沒有為學習率選擇最佳引數,
未來
-
大幅度提高學習率,會發生什么?
-
不應用特征縮放,有區別嗎?
-
嘗試研究一下,看看你能不能實作一個更好的優化演算法,在測驗集中評估你的模型
寫這篇文章真的很有趣,雖然有點長,但我希望你今天學到了一些東西,
原文鏈接:https://towardsdatascience.com/machine-learning-algorithms-from-start-to-finish-in-python-linear-regression-aa8c1d6b1169
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/202806.html
標籤:其他
上一篇:基于RNN自編碼器的離群點檢測
下一篇:matlab求助 讀取資料