作者|PROCRASTINATOR
編譯|VK
來源|Analytics Vidhya
概述
-
了解類權重優化是如何作業的,以及如何在logistic回歸或任何其他演算法中使用sklearn實作相同的方法
-
了解如何在不使用任何采樣方法的情況下,通過修改類權重可以克服類不平衡資料的問題
介紹
機器學習中的分類問題是我們給出了一些輸入(獨立變數),并且我們必須預測一個離散目標,離散值的分布極有可能是非常不同的,由于每個類的差異,演算法往往偏向于現有的大多數值,而對少數值的處理效果不好,
類頻率的這種差異影響模型的整體可預測性,
在這些問題上獲得良好的準確度并不難,但并不意味著模型是良好的,我們需要檢查這些模型的性能是否具有任何商業意義或有任何價值,這就是為什么理解問題和資料是非常必要的,這樣你就可以使用正確的度量并使用適當的方法優化它,
目錄
-
什么是類別失衡?
-
為什么要處理類別不平衡?
-
什么是類別權重?
-
logistic回歸中的類權重
-
Python實作
- 簡單logistic回歸
- 加權logistic回歸('平衡')
- 加權logistic回歸(手動權重)
-
進一步提高分數的技巧
什么是類別失衡?
類不平衡是機器學習分類問題中出現的一個問題,它只說明目標類的頻率高度不平衡,即其中一個類的頻率與現有的其他類相比非常高,換句話說,對目標中的大多數類存在偏見,
假設我們考慮一個二分類,其中大多數目標類有10000個,而少數目標類只有100個,在這種情況下,比率為100:1,即每100個多數類,就只有一個少數類,這個問題就是我們所說的類別失衡,我們可以找到這些資料的一般領域有欺詐檢測、流失預測、醫療診斷、電子郵件分類等,
我們將在醫學領域中處理一個資料集,以正確理解類不平衡,在這里,我們必須根據給定的屬性(獨立變數)來預測一個人是否會患上心臟病,為了跳過資料的清理和預處理,我們使用的是資料的已清理版本,
在下面的影像中,你可以看到目標變數的分布,
#繪制目標的條形圖
plt.figure(figsize=(10,6))
g = sns.barplot(data['stroke'], data['stroke'], palette='Set1', estimator=lambda x: len(x) / len(data) )
#圖的統計
for p in g.patches:
width, height = p.get_width(), p.get_height()
x, y = p.get_xy()
g.text(x+width/2,
y+height,
'{:.0%}'.format(height),
horizontalalignment='center',fontsize=15)
#設定標簽
plt.xlabel('Heart Stroke', fontsize=14)
plt.ylabel('Precentage', fontsize=14)
plt.title('Percentage of patients will/will not have heart stroke', fontsize=16)
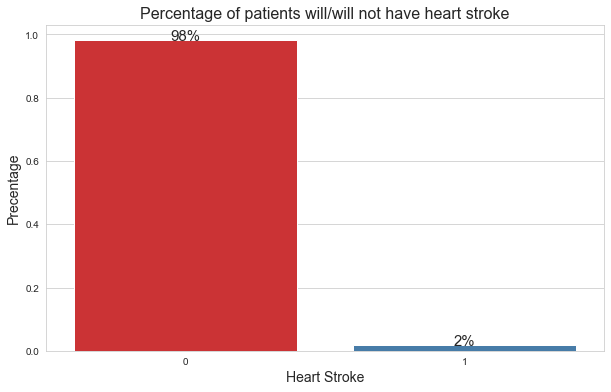
在這里,
0:表示患者沒有心臟病,
1: 表示病人患了心臟病,
從分布上可以看出,只有2%的患者患有心臟病,所以,這是一個經典的類別失衡問題,
為什么要處理類別不平衡?
到目前為止,我們已經對類別失衡有了直覺,但是為什么需要克服這個問題,在使用這些資料建模時會產生什么問題?
大多數機器學習演算法都假定資料在類中分布均勻,在類不平衡問題中,廣泛的問題是演算法將更偏向于預測大多數類別(在我們的情況下沒有心臟病),該演算法沒有足夠的資料來學習少數類(心臟病)中的模式,
讓我們以一個現實生活的例子來更好地理解這一點,
假設你已經從你的家鄉搬到了一個新的城市,你在這里住了一個月,當你來到你的家鄉,你會非常熟悉所有的地方,如你的家,路線,重要的商店,旅游景點等等,因為你在那里度過了你的整個童年,
但是到了新城市,你不會對每個地方的具體位置有太多的想法,走錯路線迷路的幾率會非常高,在這里,你的家鄉是你的多數類,新城是少數類,
同樣,這種情況也會發生在類別不平衡中,少數類關于你類的資訊不充分,這就是為什么少數類會有很高的誤分類錯誤,
注:為了檢查模型的性能,我們將使用f1分數作為衡量標準,而不是準確度,
原因是如果我們建立一個愚蠢的模型,預測每一個新的訓練資料為0(沒有心臟病),即使這樣,我們也會得到非常高的準確率,因為模型偏向大多數類,
在這里,模型非常精確,但對我們的問題陳述沒有任何價值,這就是為什么我們將使用f1分數作為評估指標,F1分數只不過是精確度和召回率的調和平均值,但是,評估指標是根據業務問題和我們希望減少的錯誤型別來選擇的,但是,f1分數是衡量類別不平衡問題的關鍵,
以下是f1分數公式:
f1 score = 2*(precision*recall)/(precision+recall)
讓我們通過訓練一個基于目標變數模式的模型來確認這一點,并檢查我們得到的分數:
#利用目標模式訓練模型
from sklearn.metrics import f1_score, accuracy_score, confusion_matrix
pred_test = []
for i in range (0, 13020):
pred_test.append(y_train.mode()[0])
#列印f1和準確度分數
print('The accuracy for mode model is:', accuracy_score(y_test, pred_test))
print('The f1 score for the model model is:',f1_score(y_test, pred_test))
#繪制混淆矩陣
conf_matrix(y_test, pred_test)
模式模型的準確度為:0.9819508448540707
模式模式的f1分數為:0.0
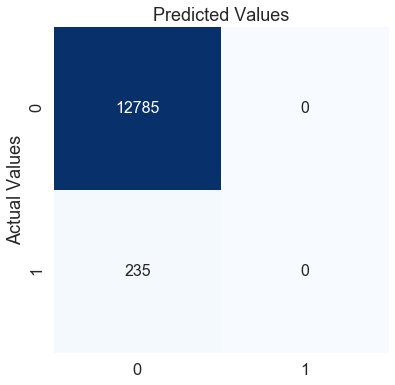
在這里,模型對測驗資料的準確度為0.98,這是一個很好的分數,但另一方面,f1的分數為零,這表明該模型在少數類群體中表現不佳,我們可以通過查看混淆矩陣來確認這一點,
模式模型預測每個病人為0(無心臟病),根據這個模型,無論病人有什么樣的癥狀,他/她永遠不會犯心臟病,使用這個模型有意義嗎?
現在我們已經了解了什么是類不平衡以及它如何影響我們的模型性能,我們將把重點轉移到類權重是什么以及類權重如何幫助改進模型性能,
類別權重是多少?
大多數機器學習演算法對有偏差的類資料不是很有用,但是,我們可以對現有的訓練演算法進行修改,以考慮到類的傾斜分布,這可以通過給予多數類別和少數類別不同的權重來實作,在訓練階段,權重的差異會影響類別的分類,其整體目的是通過設定更高的類權重,同時為多數類降低權重,以懲罰少數類的錯誤分類,
為了更清楚地說明這一點,我們將恢復我們之前考慮過的城市例子,
請這樣想一想,上個月你在這個新城市度過,而不是在需要的時候出去,而是花了整整一個月的時間探索這個城市,整個月你花了更多的時間了解城市的路線和地點,給你更多的時間去研究將有助于你更好地了解這個新城市,并且減少迷路的機會,這正是類權重的作業原理,
在訓練程序中,我們在演算法的代價函式中賦予少數類更大的權重,使其能夠對少數類提供更高的懲罰,使演算法能夠專注于減少少數類的誤差,
注意:有一個閾值,你應該分別增加和減少少數類和多數類的類權重,如果給少數類賦予非常高的類權重,演算法很可能會偏向少數類,并且會增加多數類中的錯誤,
大多數sklearn分類器建模庫,甚至一些基于boosting的庫,如LightGBM和catboost,都有一個內置的引數“class_weight”,這有助于我們優化少數類的得分,就像我們目前所學的那樣,
默認情況下,class_weights 的值為“None”,即兩個類的權重相等,除此之外,我們可以給它“balanced”或者傳遞一個包含兩個類的人工設計權重的字典,
當類權重=‘平衡’時,模型會自動分配與其各自頻率成反比的類權重,
更精確地說,計算公式為:
wj=n_samples / (n_classes * n_samplesj)
在這里,
-
wj是每個類的權重(j表示類)
-
n_samples是資料集中的樣本或行總數
-
n_classes是目標中唯一類的總數
-
n_samplesj是相應類的總行數
對于我們的心臟案例:
n_samples= 43400, n_classes= 2(0&1), n_sample0= 42617, n_samples1= 783
0類的權重:
w0= 43400/(2*42617) = 0.509
1類的權重:
w1= 43400/(2*783) = 27.713
我希望這能讓事情更清楚地表明,類別權重=‘balanced’有助于我們給予少數類別更高的權重,給多數類別較低的權重,
雖然在大多數情況下,將值作為“balanced”傳遞會產生很好的結果,但有時對于極端的類不平衡,我們可以嘗試設計權重,稍后我們將了解如何在Python中找到類權重的最佳值,
Logistic回歸中的類權重
我們可以通過在演算法的代價函式中添加不同的類權重來修改每種機器學習演算法,但這里我們將特別關注logistic回歸,
對于logistic回歸,我們使用對數損失作為成本函式,我們沒有使用均方誤差作為logistic回歸的成本函式,因為我們使用sigmoid曲線作為預測函式,而不是擬合直線,
將sigmoid函式展平會導致一條非凸曲線,這使得代價函式具有大量的區域極小值,而用梯度下降法收斂到全域極小值是非常困難的,但是對數損失是一個凸函式,我們只有一個極小值可以收斂,
log損失公式:
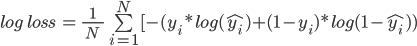
在這里,
-
N是值的數目
-
yi是目標類的實際值
-
yi是目標類的預測概率
讓我們形成一個偽表,其中包含實際預測、預測概率和使用log損失公式計算的成本:
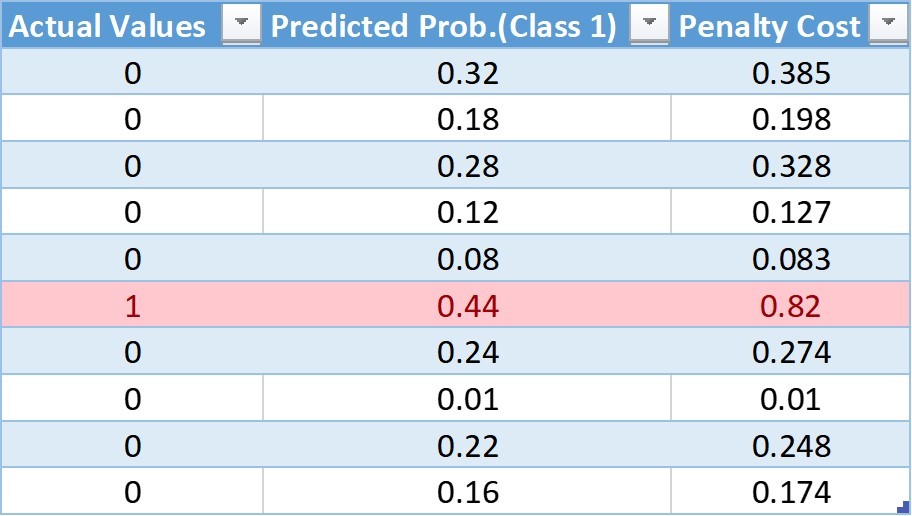
在這個表格中,我們有10個觀察值,其中9個來自0類,9個來自1類,在下一篇專欄文章中,我們將給出每一次觀察的預測概率,最后,利用對數損失公式,我們得到了成本懲罰,
將權重加入成本函式后,修改后的對數損失函式為:
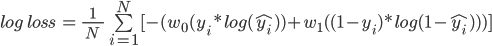
這里
w0是類0的類權重
w1是類1的類權重
現在,我們將添加權重,看看它會對成本懲罰產生什么影響,
對于權重值,我們將使用class_weights='balanced'公式,
w0= 10/(2*1) = 5
w1= 10/(2*9) = 0.55
計算表中第一個值的成本:
Cost = -(5(0*log(0.32) + 0.55(1-0)*log(1-0.32))
= -(0 + 0.55*log(.68))
= -(0.55*(-0.385))
= 0.211
同樣,我們可以計算每個觀測值的加權成本,更新后的表為:
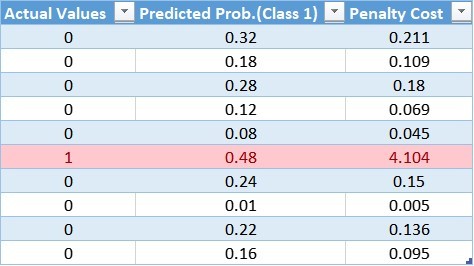
通過該表,我們可以確定對大多數類的成本函式應用了較小的權重,從而導致較小的誤差值,進而減少了對模型系數的更新,一個更大的權重值應用到少數類的成本函式中,這會導致更大的誤差計算,進而對模型系數進行更多的更新,這樣,我們就可以改變模型的偏差,從而減少少數類的誤差,
結論:
較小的權重會導致較小的懲罰和對模型系數的小更新
較大的權重會導致較大的懲罰和對模型系數的大量更新
Python實作
在這里,我們將使用相同的心臟病資料來預測,首先,我們將訓練一個簡單的logistic回歸,然后我們將實作加權logistic回歸,類權重為“平衡”,最后,我們將嘗試使用網格搜索來找到類權重的最佳值,我們試圖優化的指標將是f1分數,
1簡單邏輯回歸:
這里,我們使用sklearn庫來訓練我們的模型,我們使用默認的logistic回歸,默認情況下,演算法將為兩個類賦予相等的權重,
#匯入和訓練模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver='newton-cg')
lr.fit(x_train, y_train)
#測驗資料預測
pred_test = lr.predict(x_test)
#計算并列印f1分數
f1_test = f1_score(y_test, pred_test)
print('The f1 score for the testing data:', f1_test)
# 創建混淆矩陣的函式
def conf_matrix(y_test, pred_test):
# 創建混淆矩陣
con_mat = confusion_matrix(y_test, pred_test)
con_mat = pd.DataFrame(con_mat, range(2), range(2))
plt.figure(figsize=(6,6))
sns.set(font_scale=1.5)
sns.heatmap(con_mat, annot=True, annot_kws={"size": 16}, fmt='g', cmap='Blues', cbar=False)
#呼叫函式
conf_matrix(y_test, pred_test)
測驗資料f1得分:0.0
在簡單的logistic回歸模型中,f1得分為0,通過觀察混淆矩陣,我們可以確認我們的模型預測了每一個觀察結果,因為不會發生心臟病,這個模型并不比我們前面創建的模式模型好,讓我們試著給少數類增加一些權重,看看這是否有幫助,
2邏輯回歸(class_weight='balanced'):
我們在logistic回歸演算法中加入了類權重引數,傳遞的值是“balanced”,
#匯入和訓練模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver='newton-cg', class_weight='balanced')
lr.fit(x_train, y_train)
# 測驗資料預測
pred_test = lr.predict(x_test)
# 計算并列印f1分數
f1_test = f1_score(y_test, pred_test)
print('The f1 score for the testing data:', f1_test)
#繪制混淆矩陣
conf_matrix(y_test, pred_test)
測驗資料f1得分:0.10098851188885921
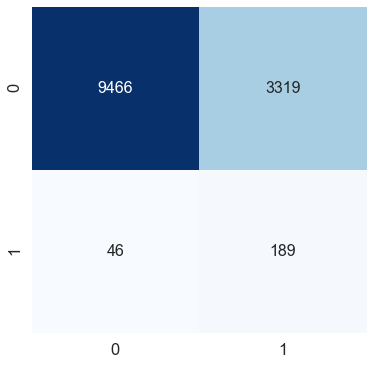
通過在logistic回歸函式中添加一個單類權重引數,我們將f1分數提高了10%,我們可以在混淆矩陣中看到,盡管類0(無心臟病)的錯誤分類增加了,但模型可以很好地捕捉到類1(心臟病),
我們可以通過改變類權重來進一步改進度量嗎?
3邏輯回歸(人工設定類權重):
最后,我們嘗試使用網格搜索來尋找得分最高的最優權重,我們將搜索0到1之間的權重,我們的想法是,如果我們給少數類別n作為權重,多數類別將得到1-n作為權重,
在這里,權重的大小并不是很大,但是多數類別和少數類別之間的權重比例將非常高,
例如:
w1 = 0.95
w0 = 1 – 0.95 = 0.05
w1:w0 = 19:1
因此,少數類別的權重將是多數類別的19倍,
from sklearn.model_selection import GridSearchCV, StratifiedKFold
lr = LogisticRegression(solver='newton-cg')
#設定類權重的范圍
weights = np.linspace(0.0,0.99,200)
#為網格搜索創建字典網格
param_grid = {'class_weight': [{0:x, 1:1.0-x} for x in weights]}
##用5倍網格搜索法擬合訓練資料
gridsearch = GridSearchCV(estimator= lr,
param_grid= param_grid,
cv=StratifiedKFold(),
n_jobs=-1,
scoring='f1',
verbose=2).fit(x_train, y_train)
#繪制不同權重值的分數
sns.set_style('whitegrid')
plt.figure(figsize=(12,8))
weigh_data = https://www.cnblogs.com/panchuangai/archive/2020/11/05/pd.DataFrame({'score': gridsearch.cv_results_['mean_test_score'], 'weight': (1- weights)})
sns.lineplot(weigh_data['weight'], weigh_data['score'])
plt.xlabel('Weight for class 1')
plt.ylabel('F1 score')
plt.xticks([round(i/10,1) for i in range(0,11,1)])
plt.title('Scoring for different class weights', fontsize=24)
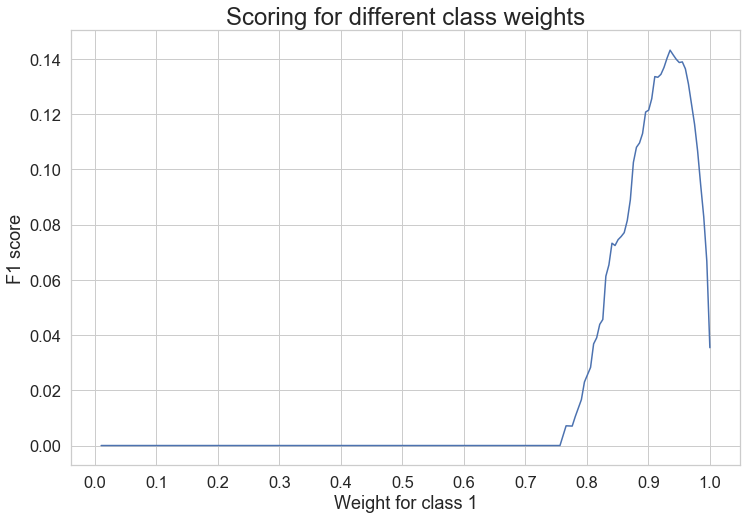
從圖中我們可以看到少數類的最高值在0.93處達到峰值,
通過網格搜索,我們得到了最佳的類權重,0類(多數類)為0.06467,1類(少數類)為1:0.93532,
現在我們已經使用分層交叉驗證和網格搜索獲得了最佳類權重,我們將看到測驗資料的性能,
#匯入和訓練模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver='newton-cg', class_weight={0: 0.06467336683417085, 1: 0.9353266331658292})
lr.fit(x_train, y_train)
# 測驗資料預測
pred_test = lr.predict(x_test)
# 計算并列印f1分數
f1_test = f1_score(y_test, pred_test)
print('The f1 score for the testing data:', f1_test)
# 繪制混淆矩陣
conf_matrix(y_test, pred_test)
f1分數:0.15714644
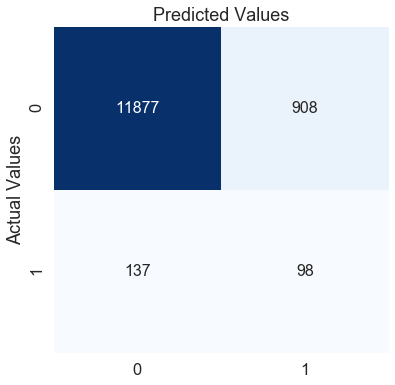
通過手動改變權重值,我們可以進一步提高f1分數約6%,混淆矩陣還表明,從之前的模型來看,我們能夠更好地預測0類,但代價是我們的1類錯誤分類,這完全取決于業務問題或你希望減少的錯誤型別,在這里,我們的重點是提高f1分數,我們可以通過調整類別權重來做到這一點,
進一步提高得分的技巧
特征工程:為了簡單起見,我們只使用了給定的自變數,你可以嘗試創建新的特征
調整閾值:默認情況下,所有演算法的閾值都是0.5,你可以嘗試不同的閾值值,并可以通過使用網格搜索或隨機化搜索來找到最佳值
使用高級演算法:對于這個解釋,我們只使用了logistic回歸,你可以嘗試不同的bagging 和boosting 演算法,最后還可以嘗試混合多種演算法
結尾
我希望這篇文章能讓你了解類權重如何幫助處理類不平衡問題,以及在python中實作它有多容易,
雖然我們已經討論了類權重如何僅適用于logistic回歸,但其他演算法的思想都是相同的;只是每種演算法用于最小化誤差和優化少數類結果的代價函式的變化
原文鏈接:https://www.analyticsvidhya.com/blog/2020/10/improve-class-imbalance-class-weights/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/203945.html
標籤:其他
下一篇:如何選擇分類模型的評價指標