作者|MUSKAN097
編譯|VK
來源|Analytics Vidhya
簡介

你已經成功地構建了分類模型,你現在該怎么辦?你如何評估模型的性能,也就是模型在預測結果方面的表現,為了回答這些問題,讓我們通過一個簡單的案例研究了解在評估分類模型時使用的度量,
讓我們通過案例研究深入了解概念
在這個全球化的時代,人們經常從一個地方旅行到另一個地方,由于乘客排隊等候、辦理登機手續、拜訪食品供應商以及使用衛生間等設施,機場可能會帶來風險,在機場追蹤攜帶病毒的乘客有助于防止病毒的傳播,

考慮一下,我們有一個機器學習模型,將乘客分為COVID陽性和陰性,在進行分類預測時,可能會出現四種型別的結果:
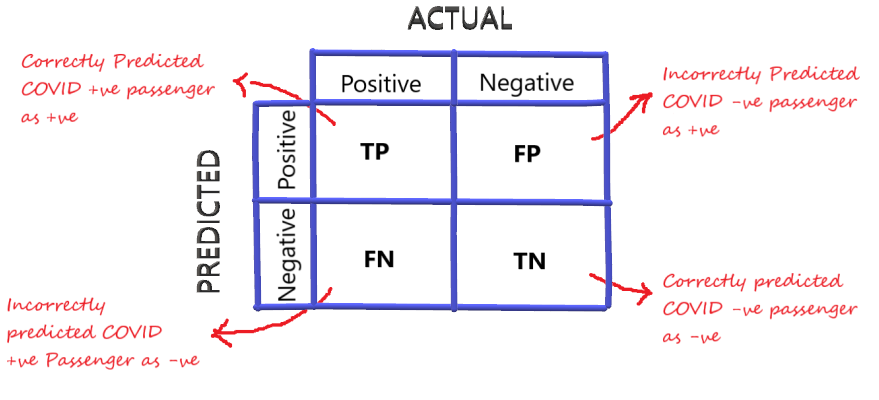
真正例(TP):當你預測一個觀察值屬于一個類,而它實際上屬于那個類,在這種情況下,也就是預測為COVID陽性并且實際上也是陽性的乘客,

真反例(TN):當你預測一個觀察不屬于一個類,它實際上也不屬于那個類,在這種情況下,也就是預測為非COVID陽性(陰性)并且實際上不是COVID陽性(陰性)的乘客,

假正例(FalsePositive,FP):當你預測一個觀察值屬于某個類,而實際上它并不屬于該類時,在這種情況下,也就是預測為COVID陽性但實際上不是COVID陽性(陰性)的乘客,

假反例(FN):當你預測一個觀察不屬于一個類,而它實際上屬于那個類,在這種情況下,也就是預測為非COVID陽性(陰性)并且實際上是COVID陽性的乘客,

混淆矩陣
為了更好地可視化模型的性能,這四個結果被繪制在混淆矩陣上,
準確度
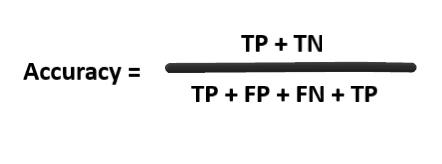
對!你說得對,我們希望我們的模型能集中在真正的正例和反例,準確度是一個指標,它給出了我們的模型正確預測的分數,形式上,準確度有以下定義:
準確度=正確預測數/預測總數,
現在,讓我們考慮平均每天有50000名乘客出行,其中有10個是COVID陽性,
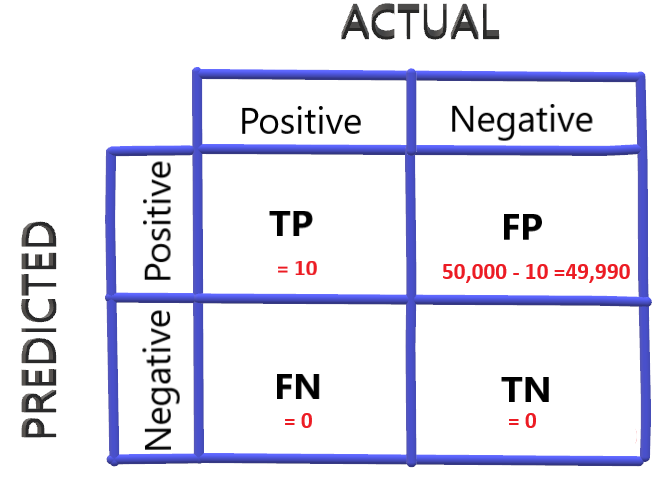
提高準確率的一個簡單方法是將每個乘客都歸為COVID陰性,所以我們的混淆矩陣如下:
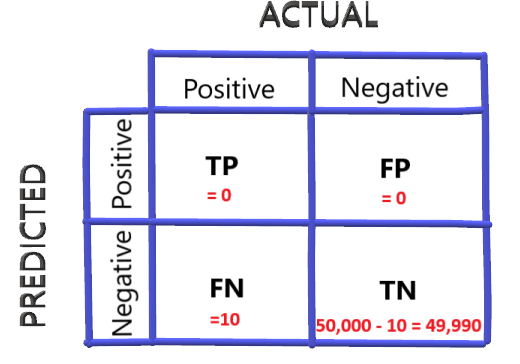
本案例的準確度為:
準確度=49990/50000=0.9998或99.98%

神奇!!這是正確的?那么,這真的解決了我們正確分類COVID陽性乘客的目的嗎?
對于這個特殊的例子,我們試圖將乘客標記為COVID陽性和陰性,希望能夠識別出正確的乘客,我可以通過簡單地將每個人標記為COVID陰性來獲得99.98%的準確率,
顯然,這是一種比我們在任何模型中見過的更精確的方法,但這并不能解決目的,這里的目的是識別COVID陽性的乘客,在這種情況下,準確度是一個可怕的衡量標準,因為它很容易獲得非常好的準確度,但這不是我們感興趣的,
所以在這種情況下,準確度并不是評估模型的好方法,讓我們來看看一個非常流行的措施,叫做召回率,
召回率(敏感度或真正例率)
召回率給出你正確識別為陽性的分數,
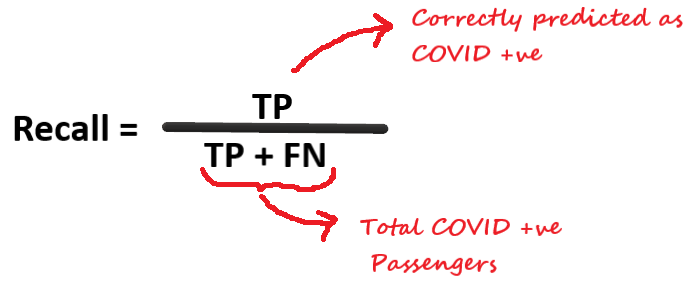
現在,這是一項重要措施,在所有陽性的乘客中,你正確識別的分數是多少,回到我們以前的策略,把每個乘客都標為陰性,這樣召回率為零,
Recall = 0/10 = 0
因此,在這種情況下,召回率是一個很好的衡量標準,它說,把每個乘客都認定為COVID陰性的可怕策略導致了零召回率,我們想最大限度地提高召回率,


作為對上述每個問題的另一個正面回答,請考慮COVID的每一個問題,每個人走進機場,模型都會給他們貼上陽性標簽,給每位乘客貼上陽性標簽是不好的,因為在他們登機前,實際調查每一位乘客所需的費用是巨大的,
混淆矩陣如下:
召回率將是:
Recall = 10/(10+0) = 1
這是個大問題,因此,結論是,準確度是個壞主意,因為給每個人貼上負面標簽可以提高準確度,但希望召回率在這種情況下是一個很好的衡量標準,但后來意識到,給每個人貼上正面標簽也會增加召回率,
所以獨立的召回率并不是一個好的衡量標準,
還有一種測量方法叫做精確度
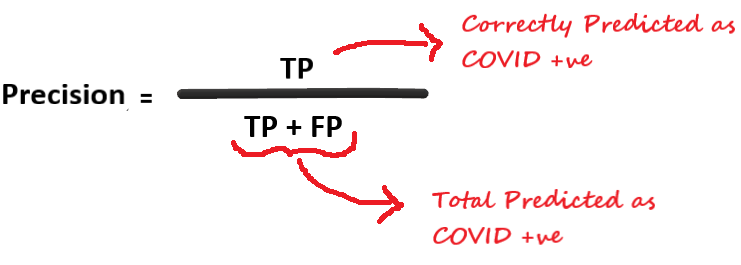
精確度
精確度給出了所有預測為陽性結果中正確識別為陽性的分數,
考慮到我們的第二個錯誤策略,即將每位乘客標記為陽性,其精確度將為:
Precision = 10 / (10 + 49990) = 0.0002
雖然這個錯誤的策略有一個好的召回值1,但它有一個可怕的精確度值0.0002,
這說明單純的召回并不是一個好的衡量標準,我們需要考慮精確度,
考慮到另一種情況(這將是最后一種情況,我保證:P)將排名靠前的乘客標記為COVID陽性,即標記出患COVID的可能性最高的乘客,假設我們只有一個這樣的乘客,這種情況下的混淆矩陣為:
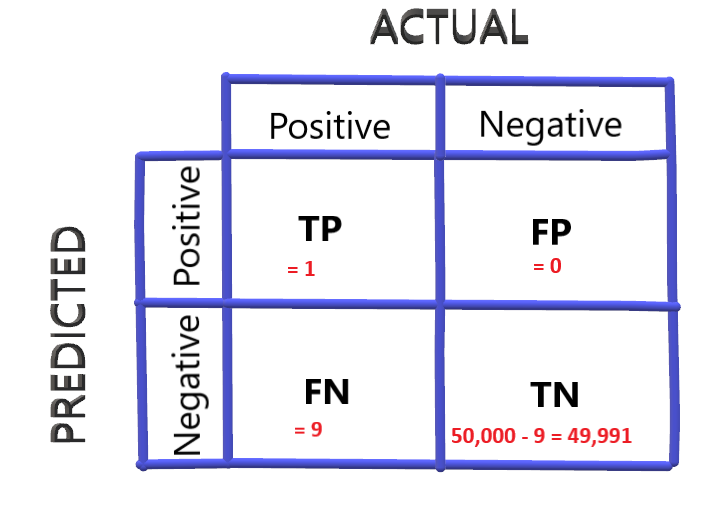
精確度為:1/(1+0)=1
在這種情況下,精度值很好,但是讓我們檢查一下召回率:
Recall = 1 / (1 + 9) = 0.1
在這種情況下,精度值很好,但召回值較低,
| 場景 | 準確度 | 召回率 | 精確度 |
|---|---|---|---|
| 將所有乘客分類為陰性 | 高 | 低 | 低 |
| 將所有乘客分類為陽性 | 低 | 高 | 低 |
| 排名靠前的乘客標記為COVID陽性 | 高 | 低 | 低 |
在某些情況下,我們非常確定我們想要最大限度地提高召回率或精確性,而代價是其他人,在這個標記乘客的案例中,我們真的希望能正確地預測COVID陽性的乘客,因為不預測乘客的正確性是非常昂貴的,因為允許COVID陽性的人通過會導致傳播的增加,所以我們更感興趣的是召回率,
不幸的是,你不能兩者兼得:提高精確度會降低召回率,反之亦然,這稱為準確度/召回率權衡,
準確度/召回率權衡
一些分類模型輸出的概率介于0和1之間,在我們將乘客分為COVID陽性和陰性的案例中,我們希望避免遺漏陽性的實際案例,特別是,如果一個乘客確實是陽性的,但我們的模型無法識別它,這將是非常糟糕的,因為病毒很有可能通過允許這些乘客登機而傳播,所以,即使有一點懷疑有COVID,我們也要貼上陽性的標簽,
所以我們的策略是,如果輸出概率大于0.3,我們將它們標記為COVID陽性,

這會導致較高的召回率和較低的精確度,
考慮與此相反的情況,當我們確定乘客為陽性時,我們希望將乘客分類為陽性,我們將概率閾值設定為0.9,即當概率大于或等于0.9時,將乘客分類為正,否則為負,
所以一般來說,對于大多數分類器來說,當你改變概率閾值時,會在召回率和精確度之間進行權衡,

如果需要比較具有不同精確召回值的不同型號,通常可以方便地將精度和召回合并為一個度量,對的!!我們需要一個同時考慮召回率和精確度的指標來計算性能,
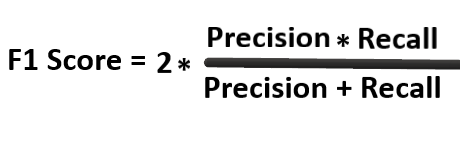
F1分數
它被定義為模型精度和召回率的調和平均值,
你一定想知道為什么調和平均而不是簡單平均?我們使用調和平均值是因為它對非常大的值不敏感,不像簡單的平均值,
比方說,我們有一個精度為1的模型,召回率為0給出了一個簡單的平均值為0.5,F1分數為0,如果其中一個引數很低,第二個引數在F1分數中就不再重要了,F1分數傾向于具有相似精確度和召回率的分類器,
因此,如果你想在精確度和召回率之間尋求平衡,F1分數是一個更好的衡量標準,
ROC/AUC曲線
ROC是另一種常用的評估工具,它給出了模型在0到1之間每一個可能的決策點的敏感性和特異性,對于具有概率輸出的分類問題,閾值可以將概率輸出轉換為分類,所以通過改變閾值,可以改變混淆矩陣中的一些數字,但這里最重要的問題是,如何找到合適的閾值?
對于每個可能的閾值,ROC曲線繪制假正例率與真正例率,
假正例率:被錯誤分類為正例的反例實體的比例,
真正例率:正確預測為正例的正例實體的比例,
現在,考慮一個低閾值,因此,在所有按升序排列的概率中,低于0.1的被認為是負的,高于0.1的都被認為是正的,選擇閾值是自由的

但是如果你把你的門檻設得很高,比如0.9,

以下是同一模型在不同閾值下的ROC曲線,
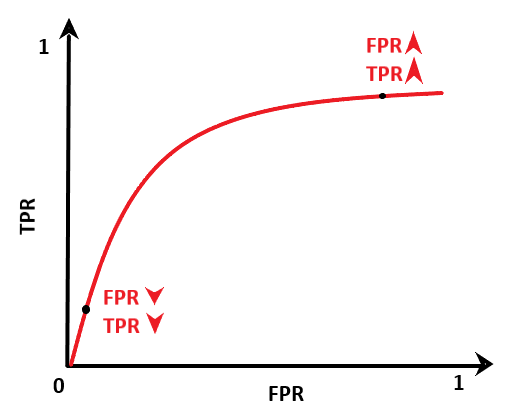
從上圖可以看出,真正例率以更高的速率增加,但在某個閾值處,TPR開始逐漸減小,每增加一次TPR,我們就要付出代價—FPR的增加,在初始階段,TPR的增加高于FPR
因此,我們可以選擇TPR高而FPR低的閾值,
現在,讓我們看看TPR和FPR的不同值告訴了我們關于這個模型的什么,
對于不同的模型,我們會有不同的ROC曲線,現在,如何比較不同的模型?從上面的曲線圖可以看出,曲線在上面代表模型是好的,比較分類器的一種方法是測量ROC曲線下的面積,
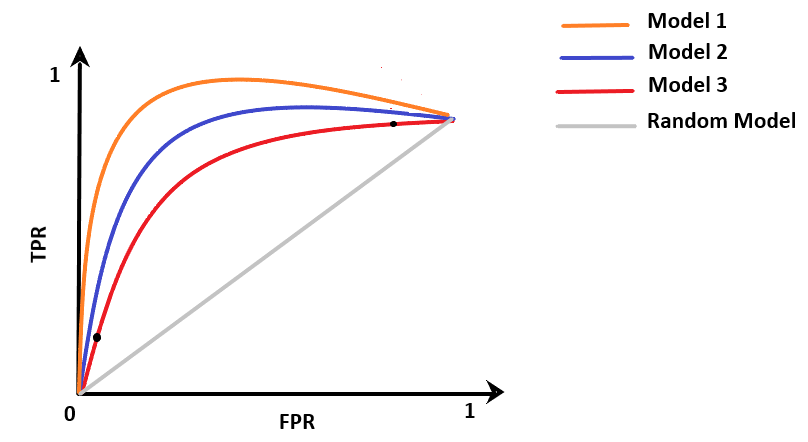
AUC(模型1)>AUC(模型2)>AUC(模型2)
因此模型1是最好的,
總結
我們了解了用于評估分類模型的不同度量,何時使用哪些指標主要取決于問題的性質,所以現在回到你的模型,問問自己你想要解決的主要目的是什么,選擇正確的指標,并評估你的模型,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/10/how-to-choose-evaluation-metrics-for-classification-model/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/203946.html
標籤:其他
上一篇:利用類權重來改善類別不平衡