A Knee_Guided Evolutionary Algorithm for Compressing Deep Neural Networks (KGEA)解讀
- 1、主要思想
- 2、模型壓縮
- 2.1 濾波器剪枝
- 2.2 衡量濾波器重要性
- 3、KGEA
- 3.1 NSGA-II
- 3.2 KGEA
- 3.3 KGEA演算法
- 4、實驗
- 5、總結
- 6、參考文獻
原論文:A Knee-Guided Evolutionary Algorithm for Compression Deep Neural Networks
1、主要思想
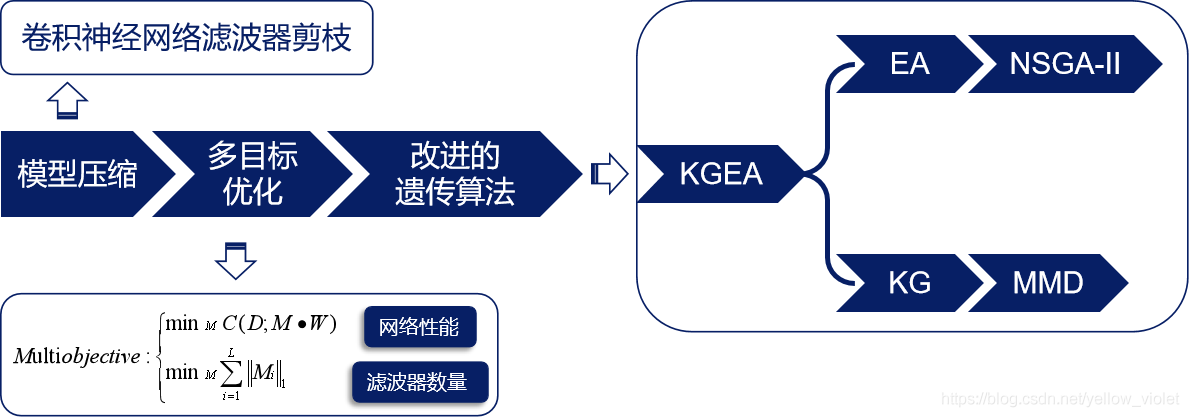
這篇文章的最主要的思想就是將模型壓縮的問題轉化為了多目標優化的問題,然后用改進的遺傳演算法來求解這個問題,
主要涉及三方面的知識:模型壓縮、多目標優化、遺傳演算法,以下分別講解,
2、模型壓縮
2.1 濾波器剪枝
這篇文章使用的模型壓縮方法是濾波器剪枝方法 [2] ,其程序如下:
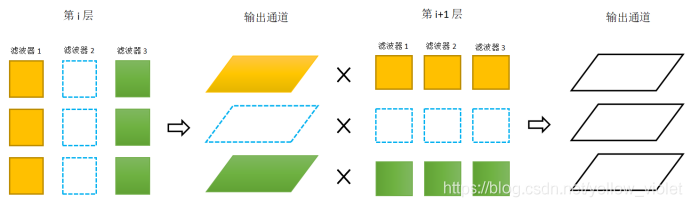
我們知道,在卷積神經網路中,卷積層是由多個濾波器組成的,而每個濾波器也是由多個卷積核組成的,而且,每一層的濾波器數量是等于該層的輸出特征圖數量的,也就是等于輸出通道;而每個濾波器的卷積核數量則等于輸入特征圖的數量,即等于輸入通道,
所以,為了保持這種結構上的對應關系,在對濾波器剪枝時,在該層剪掉一個濾波器,就應相應的把該層的輸出通道給剪掉,且下一層對應的每個濾波器的卷積核也應該被剪掉,像上圖那樣,就像這張圖中的虛框一樣,經過這樣的剪枝后,網路的引數大大減小了,這就是濾波器剪枝的程序,
在濾波器剪枝研究中,最重要的問題就是如何去選擇那些被剪的濾波器,或說,如何衡量濾波器的重要性,
2.2 衡量濾波器重要性
一般的做法:
- 基于濾波器的權重值: 如求權重和(Weight Sum, WS)[2],和越大,則越重要;
- 基于激活函式: 基于激活函式:如計算激活函式輸出中0占的比例(Average Percentage of Zeros,APoZ) [3] ;
- 基于重建誤差: 如通過最小化特征重建誤差來確定哪些濾波器需要裁剪(ThiNet)[4] ,
本文沒有使用以上的方法,而是根據一個最直接的指標——神經網路的性能來衡量濾波器的重要性,同時考慮網路性能和濾波器數量,以找到平衡兩者的最優結構,
濾波器重不重要,網路性能最能說明問題,剪掉一個濾波器,如果性能變得很差,那說明這個濾波器很重要,但是如果性能幾乎不變,,那就說明這個濾波器不重要,可以剪掉,所以用網路性能來衡量濾波器重要性是非常直接且有效的,
既然是模型壓縮問題,濾波器數量當然是要考慮的,我們希望得到一個引數量更小的網路,所以,要同時優化網路性能和濾波器數量這兩個目標,這就成為了一個多目標優化的問題了,
這就是文章給出的這個問題的數學表達,
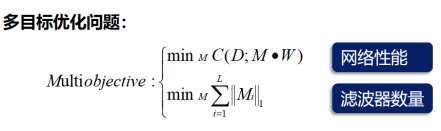
其中,C是cost,也就是網路的損失函式,D是資料集,W是濾波器權重,M是掩膜,其元素全為0或1,M乘W的意思就是:若M全為0則,則乘上W后W就變為0,就相當于把這個濾波器剪掉了,若全為1,則W不變,也就是保留這個濾波器,這樣就能達到剪枝和保留的作用了,
第二個式子用1-范數來計算濾波器數量,即計算有多少元素全為1的M的個數,有多少個元素全為1的M,那就有多少個濾波器保留下來,
就這樣,通過這個式子,濾波器剪枝問題就變成了一個多目標優化的問題,接下來,就是如何去求解這個問題了,
3、KGEA
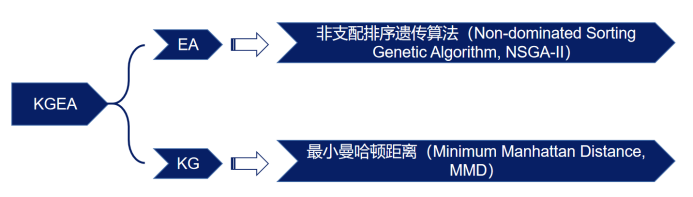
本文使用的求解辦法是膝蓋導向進化演算法( Knee_guided Evolutionary Algorithm, KGEA),它是進化演算法的一種,是對非支配排序遺傳演算法(Non-dominated Sorting Genetic Algorithm, NSGA-II) [5] 的改進,主要就是提出使用最小曼哈頓距離(Minimum Manhattan Distance, MMD) [6] 來計算種群中的一個最優解,即膝蓋knee,然后以Knee為進化方向,選擇優秀的個體保留到下一代種群中,這就是KGEA的主要思想,
3.1 NSGA-II
在講解NSGA-II前,有些概念需要被知道,
- 支配與非支配: 如果任何兩個解S1和S2對所有目標而言,S1均優于S2,則稱S1支配S2;若S1不被其他解支配,則S1即為非支配解,即不被支配的解,
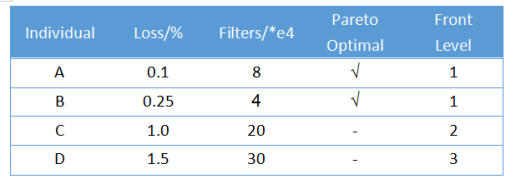
如這里有4個個體ABCD,A和B相對于C和D來說,在網路損失和濾波器數量上都要好,且A和B之間沒有說哪一個非常好的,所以A和B就是非支配解,同樣的,C相對于D來說也是非支配解,
- 帕雷托前沿面: 就是在找到非支配解后,這些解所形成的曲面就是帕雷托前沿面(Pareto Front,PF) ,
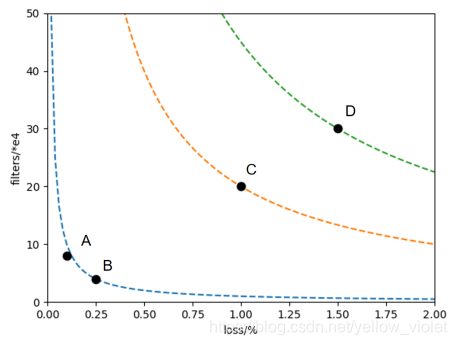
如這里,AB 就構成一個PF,C構成一個PF,D一個PF,因為這里只有兩個目標,所以PF是曲線,當目標數較多時,PF就是曲面,
- 非支配排序: 對帕雷托前沿面從非支配到被支配進行排序,非支配解排在前面,
這里,AB構成的PF排第一,接著是C,到D,
可以看到,PF排名靠前的個體在各方面都比排名靠后的個體要優秀的,
所以,NSGA-II的思想就是將這些PF排名靠前的個體作為精英保留到下一代,使種群往更優的方向發展,加快搜索到最優解的速度,
- 演算法
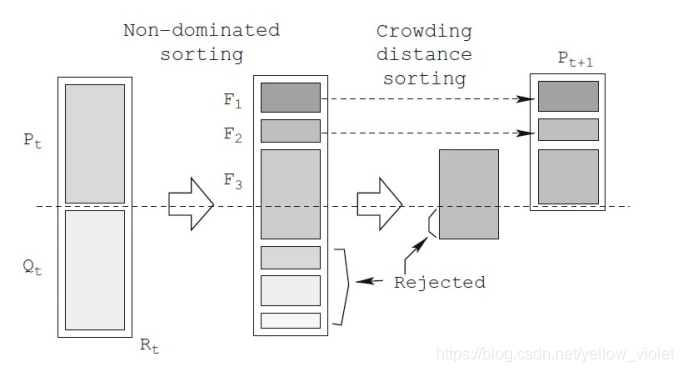
演算法: NSGA-II
- 由遺傳演算法產生種群Pt;
- 種群個體變異,產生的子代Qt和父代Pt一起構成新的種群Rt;
- 對種群進行非支配排序,保留**帕雷托前沿面(PF)**排名靠前的個體;
- 若保留的個體超出種群個數,則對PF最后的個體進行擁擠距離計算,保留擁擠距離較大的個體;
- 保留下來的個體構成新種群Pt+1,繼續遺傳進化;
這就是NSGA-II的程序,首先遺傳演算法,產生種群,然后變異產生子代,子代和父代合并為新的種群,對種群進行非支配排序,保留PF靠前的個體,
但這里有個問題就是,要保留的個體可能超出種群的數量,所以這里,NSGA提出對要保留的最后一個PF里的個體再進行一次擁擠距離排序,
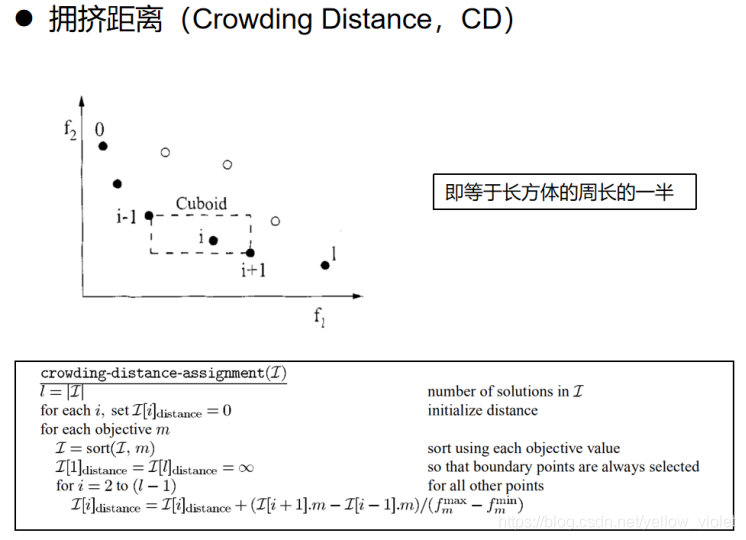
所謂擁擠距離,就是計算一個解與最近兩個解的在各個目標上的距離,如圖中的i ,計算公式如上,簡單理解就是計算這個長方形的周長的一半,從上圖可以看出,i與i-1、i+1在f1上的距離就是長方形的長,f2上就是寬,所以就是長方形周長的一半,
擁擠距離表示的是解的相似度,如果保留的解都是相似度高的,則容易陷入區域最優中,所以,為了保持種群的多樣性,增加探索,所以要保留那些擁擠距離大的個體,
這就是整個NSGA-II的一個程序了,
3.2 KGEA
- 思想
膝蓋進化演算法在NSGA-II的基礎上,提出擁擠距離排序階段,使用膝蓋導向作為主要的個體選擇方法,而擁擠距離則作為輔助方法,然后綜合這兩種方法來選擇要保留的個體,
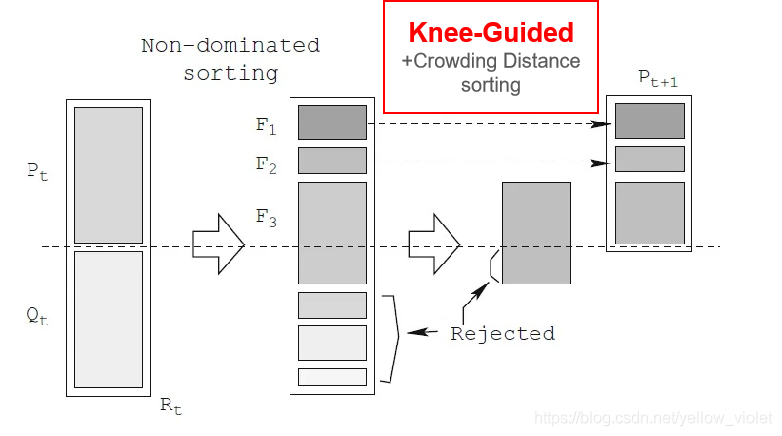
所謂的膝蓋是指種群中在各個目標上都比較平衡且優秀的個體,一般就是那個拐點,像人的膝蓋一樣,所以叫做膝蓋,如下圖,因為膝蓋是平衡了各個目標的最優解,所以將其作為一個進化方向,保留其附近的個體,能讓種群發展更好,更快收斂,
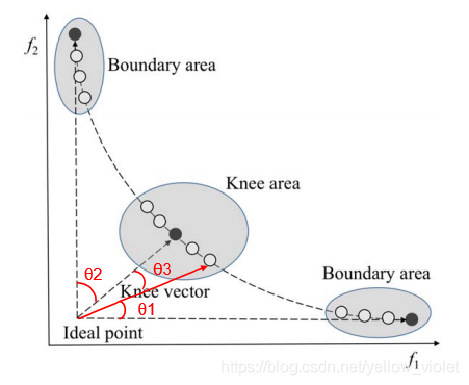
怎么找到這個膝蓋呢?文章提出使用最小化曼哈頓距離(Minimum Manhattan Distance, MMD) 來求這個膝蓋,其公式如下,其實曼哈頓距離就是1-范數,這個公式的意思就是求每個點與理想點組成的向量的模,就是距離,距離最小的點就是膝蓋點,這個向量就是膝蓋向量knee vector,
x ? = arg?min ? x ∣ ∣ f ( x ) L ? Z min ? L ∣ ∣ 1 w h e r e L = max ? f ( x ) ? min ? f ( x ) , Z min ? = min ? f ( x ) , ∣ ∣ ? ∣ ∣ 1 r e p r e s e n t s t h e M a n h a t t a n n o r m . \small x^* = \argmin_x ||{f(x)\above{1pt} L} -{Z^{\min} \above{1pt} L}||_1 \\ \small where \space L=\max f(x)-\min f(x),\\ \small Z^{\min }=\min f(x), \space ||\cdotp||_1 \space represents \space the \space Manhattan \space norm. x?=xargmin?∣∣Lf(x)??LZmin?∣∣1?where L=maxf(x)?minf(x),Zmin=minf(x), ∣∣?∣∣1? represents the Manhattan norm.
又因為用MMD來求膝蓋向量的時候需要邊界資訊,即公式里的L和Zmin ,所以邊界周圍的點也被認為是重要的,
因此,這個膝蓋導向就變成了,以兩個邊界和一個膝蓋向量為參考向量,綜合選擇與他們相近的個體保留到下一代,
如何衡量這個近,本文使用的就是計算和這三個參考向量的夾角,并分別排序,保留那些排名靠前的個體,
這就是這篇膝蓋導向演算法的改程序序,
3.3 KGEA演算法



這就是整個KGEA的演算法,
KGEA和NSGA-II的不同就是這些紅框標出來的地方,首先利用MMD求膝蓋向量,然后和兩個邊界一起作為參考向量,然后在要保留的PF超過群體數量后,對最后一個PF的個體再進行一次排序,就是計算每個個體和那三個參考向量的角度,然后進行排序,作為主要的選擇依據,同時,這里也還是使用了NSGA-II里面的擁擠度排序,作為一個輔助選擇依據,最后綜合考慮這兩個排序,保留那些排序靠前的個體到下一代,
4、實驗
為驗證KGEA的效果,文章做了實驗,
使用KGEA對一個訓練好的全卷積LeNet進行剪枝,并在MNIST資料集上進行驗證,
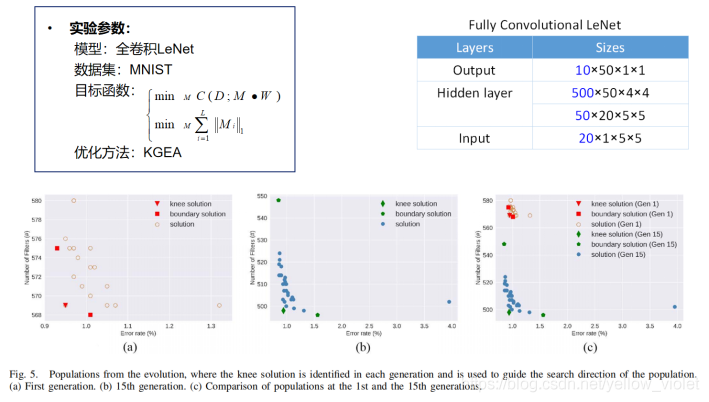
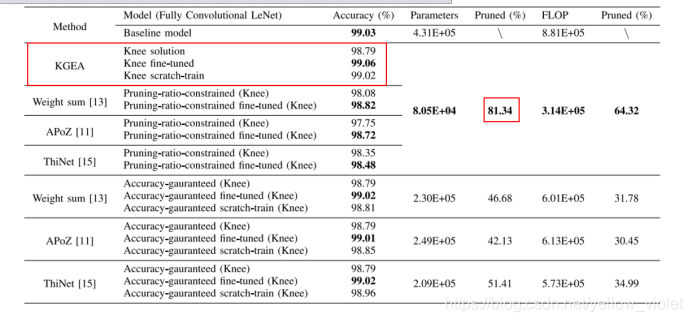
這就是實驗完后的結果,在剪枝后,還對剪枝后的網路進行了微調,也就是再訓練了幾個回合,
可以看到,剪枝后,引數的數量已經減少了81.34%,而且,經過微調后的網路的精度反而還提高了,
這足以說明這篇文章提出的方法的有效性,這也能夠說明,神經網路確實有很多引數是冗余的,所以研究神經網路的壓縮是有必要的,對神經網路自組織原理的研究也是很有必要的,
5、總結
好了,這就是這篇文章的所有內容了,
總的來說,就是將卷積神經網路濾波器剪枝這樣一個模型壓縮的問題,轉化為了一個多目標優化的問題,也就是同時考慮了網路的性能和濾波器的數量這兩個目標,然后用改進的遺傳演算法即KGEA來求解這個問題,
6、參考文獻
[1] A Knee-Guided Evolutionary Algorithm for Compression Deep Neural Networks
[2] Pruning Filters for Efficient Convnets
[3] Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures
[4] ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression
[5] A Fast and Elitist Multiobjective Genetic Algorithm:NSGA-II
[6] Minimum Manhattan Distance Approach to Multiple Criteria Decision Making in Multiobjective Optimization Problems
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/205429.html
標籤:其他