論文地址: FGAGT: Flow-Guided Adaptive Graph Tracking
FGAGT閱讀心得
- 一、 摘要
- 二、 簡要介紹
- 2.1 光流
- 2.1 圖神經網路(GNN)
- 三、 FGAGT網路結構
- 3.1 自適應圖神經網路模型
- 3.2 平衡MSE Loss
- 3.3 推理
- 3.3.1. 匹配關聯和新目標的出現
- 3.3.2. 目標消失
- 四、 總結
一、 摘要
本文提出的FGAGT追蹤器,不同于FairMoT,使用Lucas金字塔光流方法預測當前幀中的歷史目標位置資訊,同時利用ROI Pooling和全連通層提取歷史物件在當前幀特征圖上的外觀特征向量,然后將他們和新目標的特征向量輸入進自適應圖神經網路來更新特征向量,自適應圖神經網路可以通過組合全域歷史位置和外貌資訊來更新目標的特征向量,因為歷史資訊的保留,他可以重新識別被遮擋的目標,訓練階段,提出了平衡MSE損失來平衡采樣分布,推理階段,使用匈牙利演算法進行資料關聯,FGAGT堅信匹配目標的時候,位置資訊和外貌特征必須全部使用才能獲得一個好的追蹤結果,這也是這演算法的核心,
創新點:
- 使用光流預測歷史目標的在當前幀的位置,并且提取特征,相較于其他的利用過去幀的特征圖來提取特征向量,我們的方法避免了從不同特征圖上提取特征,這樣新檢測的目標特征和提取的目標歷史特征會保持一致,
- 使用自適應的圖網路來整合時空外貌位置資訊,并且來更新特征和識別遮擋目標(加權學習特征),
- 提出了平衡MSE損失來平衡不同的采樣分布,
二、 簡要介紹
多目標追蹤需要根據目標的歷史軌跡匹配當前幀中檢測到的多個目標,同樣的目標需要分配同樣的id,并且形成新的軌跡,新出現的目標需要分配一個新的id而消失的目標需要洗掉軌跡,且無法被匹配,
問題:盡管很多方法使用了光流方法預測位置資訊,但是在特征匹配程序中,歷史目標和新檢測的目標的特征是從不同的特征圖上獲得的,這會導致同樣的目標特征向量總會不同,甚至相差很遠,這樣一個目標因為遮擋而消失,當再次出現在視野時,如何匹配上歷史軌跡成為一個問題,并且過去的目標能夠唯一匹配當前幀的一個目標,長時間歷史目標一多,歷史目標很有可能會匹配上新出現目標(錯誤匹配),從而導致會出現很少的新目標,
解決:提出了FGAGT追蹤器,使用Lucas金字塔演算法計算當前幀歷史目標的中心位置,

然后當前幀通過卷積神經網路進行下采樣獲得特征圖,使用ROI Pooling和全連接層提取歷史目標和新檢測到的目標(當前幀中的目標)的初始外貌特征向量,將他們輸入自適應圖網路,歷史目標和新檢測目標被視為二分圖,初始外貌特征的距離和IOU被認為是邊的權重,組合全域時空位置和外貌資訊,輸入進圖網路,來更新特征向量,
圖網路中,每個維度的整合特征會被乘上一個自適應的權重,用以強化學習目標中最能解決遮擋和重識別問題的特征,圖網路最終輸出是一個相似性矩陣,訓練階段,提出了一個MSE Loss,具體來說就是分別在連續正,連續負,新和消失目標的損失函式前乘以一個和樣本數負相關的一個系數,有利于解決不平衡樣本數量分布的問題,從而讓圖網路學到我們想要的特征向量,
2.1 光流
光流:它指的是視頻中一幀中表示同一物件到下一幀的像素移動量,由一個二維向量表示,根據是否選擇影像像素稀疏的點用于光流評估,可以將光流評估分為稀疏光流評估和密集光流評估,稀疏光流選擇明顯的特征(梯度大的)用于光流評估和追蹤,密集光流描述的是影像中的所有像素點到下一幀的運動,使用顏色作為光流的方向,亮度表示光流大小,
LK (Lucas-Kanade)演算法有三個假設:1.亮度恒定,2.目標運動小,3.鄰域光流一致,
所有假設成立都滿足的條件下,可以構造所選像素從當前幀到下一幀的光流微分方程:
考慮第一幀的像素亮度強度
I
(
x
,
y
,
t
)
I\left(x,\ y,\ t\right)
I(x, y, t)(t代表時間維度,(x,y)代表位置),到下一幀,這個像素運動了
(
d
x
,
d
y
)
\left(dx,\ dy\right)
(dx, dy)的距離,花費了
d
t
dt
dt的時間,因為是同樣的像素,且根據第一個假設像素運動前后亮度恒定,即:
I
(
x
,
y
,
t
)
=
I
(
x
+
d
x
,
y
+
d
y
,
t
+
d
t
)
(1)
I(x, y, t)=\mathrm{I}(\mathrm{x}+\mathrm{d} \mathrm{x}, \mathrm{y}+\mathrm{d} \mathrm{y}, \mathrm{t}+\mathrm{dt}) \tag1
I(x,y,t)=I(x+dx,y+dy,t+dt)(1)
右邊泰勒展開得:
I
(
x
,
y
,
t
)
=
I
(
x
,
y
,
t
)
+
?
I
?
x
d
x
+
?
I
?
y
d
y
+
?
I
?
t
d
t
+
ε
(2)
I(x, y, t)=\mathrm{I}(\mathrm{x}, \mathrm{y}, \mathrm{t})+\frac{\partial I}{\partial x} d x+\frac{\partial I}{\partial y} d y+\frac{\partial I}{\partial t} d t+\varepsilon \tag2
I(x,y,t)=I(x,y,t)+?x?I?dx+?y?I?dy+?t?I?dt+ε(2)
ε
\varepsilon
ε是二階無窮小,可以忽略,然后將公式(2)帶入公式(1),同時除以
d
t
dt
dt獲得:
?
I
?
x
d
x
d
t
+
?
I
?
y
d
y
d
t
+
?
I
?
t
d
t
d
t
≈
0
(3)
\frac{\partial I}{\partial x} \frac{d x}{d t}+\frac{\partial I}{\partial y} \frac{d y}{d t}+\frac{\partial I}{\partial t} \frac{d t}{d t} \approx 0 \tag3
?x?I?dtdx?+?y?I?dtdy?+?t?I?dtdt?≈0(3)
假設u,v分別為x軸和y軸的速度矢量:
u
=
d
x
d
t
,
v
=
d
y
d
t
(4)
\mathrm{u}=\frac{d x}{d t}, v=\frac{d y}{d t}\tag4
u=dtdx?,v=dtdy?(4)
I
x
=
?
I
?
x
I_x=\frac{\partial I}{\partial x}
Ix?=?x?I?,
I
y
=
?
I
?
y
I_y=\frac{\partial I}{\partial y}
Iy?=?y?I?,
I
t
=
?
I
?
t
I_t=\frac{\partial I}{\partial t}
It?=?t?I?代表圖片沿著X軸,Y軸,t軸方向的像素灰度值的偏導數,則(3)可以描述為:
I
x
u
+
I
y
v
+
I
t
≈
0
(5)
I_{x} u+I_{y} v+I_{t} \approx 0\tag5
Ix?u+Iy?v+It?≈0(5)
其中
I
x
,
I
y
,
I
t
I_x,\ I_y,I_t
Ix?, Iy?,It?都可以通過有限差分(一種求偏微分(或常微分)方程和方程組定解問題的數值解的方法)得到,
(
u
,
v
)
\left(u,\ v\right)
(u, v)是所需的光流向量,由(5)估計一個目標函式:
min
?
∑
(
x
,
y
∈
Ω
)
W
2
(
X
)
(
I
x
u
+
I
y
v
+
I
t
)
2
(6)
\min \sum_{(x, y \in \Omega)} W^{2}(X)\left(I_{x} u+I_{y} v+I_{t}\right)^{2}\tag6
min(x,y∈Ω)∑?W2(X)(Ix?u+Iy?v+It?)2(6)
上式中
W
2
(
X
)
W^2\left(X\right)
W2(X)是一個權重函式,離鄰域中心越遠,權重越小,讓
V
=
(
d
x
d
t
,
d
y
d
t
)
=
(
u
,
v
)
T
,
?
I
(
X
)
=
(
?
I
?
x
,
?
I
?
y
)
=
(
I
x
,
I
y
)
T
V=\left(\frac{dx}{dt},\frac{dy}{dt}\right)=(u,v)^T,\nabla I(X)=(\frac{\partial I}{\partial x},\frac{\partial I}{\partial y}){=\left(I_x,I_y\right)}^T
V=(dtdx?,dtdy?)=(u,v)T,?I(X)=(?x?I?,?y?I?)=(Ix?,Iy?)T
A
=
(
?
I
(
X
1
)
,
…
,
?
I
(
X
n
)
)
T
A=\left(\nabla I\left(X_1\right),\ldots,\nabla I\left(X_n\right)\right)^T
A=(?I(X1?),…,?I(Xn?))T
W
=
d
i
a
g
(
W
(
X
1
)
,
…
W
(
X
n
)
)
W=diag{\left(W\left(X_1\right),\ldots W\left(X_n\right)\right)}
W=diag(W(X1?),…W(Xn?))
b
=
?
(
?
I
(
X
1
)
?
t
,
…
,
?
I
(
X
n
)
?
t
)
T
b=-\left(\frac{\partial I\left(X_1\right)}{\partial t},\ldots,\frac{\partial I\left(X_n\right)}{\partial t}\right)^T
b=?(?t?I(X1?)?,…,?t?I(Xn?)?)T
n表示鄰域像素的個數,然后用最小二乘法求出式(6)的解:
V
=
(
A
T
W
2
A
)
?
1
A
T
W
2
b
(7)
\mathrm{V}=\left(A^{T} W^{2} A\right)^{-1} A^{T} W^{2} b\tag7
V=(ATW2A)?1ATW2b(7)
最后可以使用Newton-Raphson方法獲得更加精確的值,
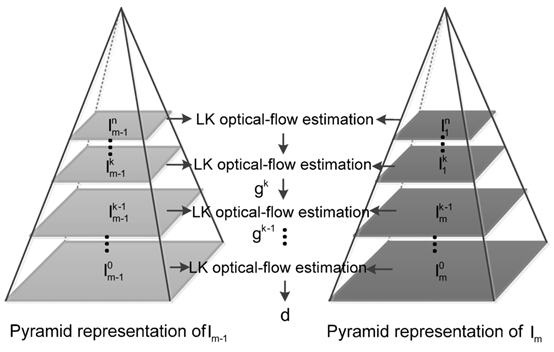
金字塔LK演算法
由于LK演算法要求位移必須足夠的小,所以Pyramid-LK演算法解決了這個缺點:
逐層向上減少圖片大小,形成一個圖片金字塔,其中圖片的縮放大小為底層的寬高的一半,這會將大的位移轉換為小的位移,然后使用LK演算法從頂層開始計算光流,在每一層進行光流的矯正,知道最底層獲得最終的光流,
金
字
塔
L
K
算
法
示
意
圖
金字塔LK演算法示意圖
金字塔LK算法示意圖
2.1 圖神經網路(GNN)
早期的圖網路多用于分子結構分類問題,事實上,歐式空間(例如圖片)或者序列(例如text文本)等常見的場景也可以轉變為圖,然后利用圖神經網路技術進行處理,
直到2013年,Bruna基于圖信號處理提出了基于譜域和空域的圖卷積神經網路,自此GNN開始不斷展示其強大的能力,
對于一張圖
G
G
G,每個節點v有自己的特征向量
X
v
X_v
Xv?,每條邊連接兩個節點,并且對于連接的結點
v
,
u
v,u
v,u,這條邊也有自己的特征向量
X
(
v
,
u
)
X_{\left(v,u\right)}
X(v,u)?,GNN的目標是獲得每個節點的圖形感知
h
v
h_v
hv?的隱藏狀態,對于每個節點,他的隱藏狀態包含從鄰節點獲得的資訊,圖上通過迭代更新所有節點的隱藏狀態來實作GNN,在
c
+
1
c\ +\ 1
c + 1層,節點
v
v
v的更新狀態為:
h
v
c
+
1
=
f
(
x
v
,
x
c
o
[
v
]
,
h
n
e
c
[
v
]
,
x
n
e
[
v
]
)
(8)
\mathbf{h}_{v}^{c+1}=f\left(\mathbf{x}_{v}, \mathbf{x}_{c o}[v], \mathbf{h}_{n e}^{c}[v], \mathbf{x}_{n e}[v]\right)\tag8
hvc+1?=f(xv?,xco?[v],hnec?[v],xne?[v])(8)
上式中的
f
f
f是隱藏狀態的狀態更新函式,我們使用神經網路代替,
x
c
o
[
v
]
\mathbf{x}_{co}\left[v\right]
xco?[v]代表為節點
v
v
v的相鄰邊對應的特征向量,
x
n
e
[
v
]
\mathbf{x}_{ne}\left[v\right]
xne?[v]代表節點
v
v
v的相鄰節點的特征向量,
h
n
e
c
[
v
]
\mathbf{h}_{ne}^c\left[v\right]
hnec?[v]代表在𝑐層的時候,節點
v
v
v的鄰節點的隱藏狀態,
f
f
f是所有節點共享的全域函式,
三、 FGAGT網路結構
結構圖如下:
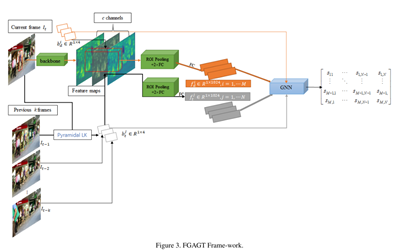
如圖,當前幀
I
t
I_t
It?通過backbone變為了特征圖,用當前幀檢測后的獲得的M個bbox提取區域特征,然后通過ROI Pooling和全連接層全變為特征向量,同時
I
t
?
1
I_{t-1}
It?1?幀的歷史目標的在當前幀中的bbox通過LK金字塔演算法進行預測出來,然后加上過去
T
T
T(除去
I
t
?
1
I_{t-1}
It?1?幀) 幀中的bbox,一共N個歷史bbox通過ROI Pooling和全連接層轉化為特征向量,
輸入圖神經網路主要有兩部分:當前幀的M個目標的外貌特征向量和bbox和過去T幀的歷史目標的外貌特征向量和bbox,
需要注意的是,外貌特征向量是從當前幀的特征圖中提取,而不是從歷史幀的特征圖中提取的歷史目標,最終輸出相似矩陣
S
∈
R
M
×
N
S\ \in\ R^{M\times N}
S ∈ RM×N,
3.1 自適應圖神經網路模型
如下,將新檢測的目標和歷史目標作為一個二分圖,如下圖(和上面介紹的意義通過迭代的思想不斷優化歷史和當前檢測的資訊相同):
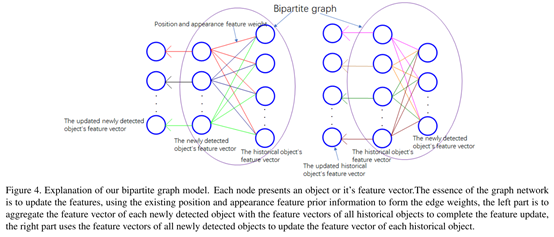
如上圖中左邊,任意一個新檢測的目標會和所有的歷史目標進行關聯,但是任意兩個新檢測目標或者兩個歷史目標之間不會有關聯,為了獲取點之間的隱藏狀態
h
v
h_v
hv?,根據公式(8),我們來進行迭代更新:
(
c
+
1
)
h
d
i
=
f
(
(
c
)
h
d
i
,
{
(
c
)
h
t
j
,
(
c
)
e
d
i
,
j
}
j
=
1
N
)
,
i
=
1
,
2
,
?
?
,
M
(
c
+
1
)
h
t
j
=
f
(
(
c
)
h
t
j
,
{
(
c
)
h
d
i
,
(
c
)
e
t
j
,
i
}
i
=
1
M
)
j
=
1
,
2
,
?
?
,
N
\begin{aligned} {}^{(c+1) }& h_{d}^{i}=f\left({ }^{(c)} h_{d}^{i},\left\{{ }^{(c)} h_{t}^{j},{ }^{(c)} e_{d}^{i, j}\right\}_{j=1}^{N}\right), i=1,2, \cdots, M \\ { }^{(c+1)} h_{t}^{j} &=f\left({ }^{(c)} h_{t}^{j},\left\{{ }^{(c)} h_{d}^{i},{ }^{(c)} e_{t}^{j, i}\right\}_{i=1}^{M}\right) j=1,2, \cdots, N \end{aligned}
(c+1)(c+1)htj??hdi?=f((c)hdi?,{(c)htj?,(c)edi,j?}j=1N?),i=1,2,?,M=f((c)htj?,{(c)hdi?,(c)etj,i?}i=1M?)j=1,2,?,N?
f
f
f是隱藏狀態的更新函式,使用神經網路代替,在本文中,我們使用一個單層GNN,并添加了一個自適應部分,
AGNN(自適應圖神經網路)利用已存在的位置和特征先驗資訊作為邊
e
i
,
j
e_{i,j}
ei,j?的權重來整合目標特征向量并更新所有目標特征,
整合步驟如下:
- 首先計算初始特征相似性:
s i , j = 1 ∥ f d i ? f t j ∥ 2 2 + 1 × 1 0 ? 16 s i , j = s i , j s i , 1 2 + s i , 2 2 + ? s i , j 2 + ? + s i , N 2 S f t = [ s i , j ] M × N , i = 1 , 2 , ? M , j = 1 , 2 , ? N \begin{aligned} s_{i, j}=& \frac{1}{\left\|f_{d}^{i}-f_{t}^{j}\right\|_{2}^{2}+1 \times 10^{-16}} \\ s_{i, j}=& \frac{s_{i, j}}{\sqrt{s_{i, 1}^{2}+s_{i, 2}^{2}+\cdots s_{i, j}^{2}+\cdots+s_{i, N}^{2}}} \\ \mathbf{S}_{\mathrm{ft}}=&\left[s_{i, j}\right]_{M \times N}, \quad i=1,2, \cdots M, j=1,2, \cdots N \end{aligned} si,j?=si,j?=Sft?=?∥∥∥?fdi??ftj?∥∥∥?22?+1×10?161?si,12?+si,22?+?si,j2?+?+si,N2? ?si,j??[si,j?]M×N?,i=1,2,?M,j=1,2,?N? - 計算交并比,和1的結果形成一個先驗相似性矩陣:
E = w × I O U + ( 1 ? w ) × S f t \mathrm{E}=w \times \mathrm{IOU}+(1-w) \times \mathbf{S}_{\mathrm{ft}} E=w×IOU+(1?w)×Sft?引數w測量的是位置資訊和外貌特征資訊之間的關聯度,初始為0.5, - 整合資訊:
F
t
a
g
=
E
F
t
=
E
[
f
t
1
f
t
2
?
f
t
N
]
\mathbf{F}_{\mathrm{t}}^{\mathrm{ag}}=\mathrm{EF}_{t}=\mathrm{E}\left[\begin{array}{c} f_{t}^{1} \\ f_{t}^{2} \\ \vdots \\ f_{t}^{N} \end{array}\right]
Ftag?=EFt?=E??????ft1?ft2??ftN????????
然后更新特征: H d = σ ( F d W 1 + Sigmoid ? ( F d W a ) ⊙ F t a g W 2 ) (9) \mathbf{H}_{\mathrm{d}}=\sigma\left(\mathbf{F}_{d} W_{1}+\operatorname{Sigmoid}\left(\mathbf{F}_{d} W_{a}\right) \odot \mathbf{F}_{\mathrm{t}}^{\mathrm{ag}} W_{2}\right)\tag9 Hd?=σ(Fd?W1?+Sigmoid(Fd?Wa?)⊙Ftag?W2?)(9)同時更新: H t = σ ( F t W 1 + Sigmoid ? ( F t W a ) ⊙ F d a g W 2 ) (10) \mathbf{H}_{\mathrm{t}}=\sigma\left(\mathbf{F}_{t} W_{1}+\operatorname{Sigmoid}\left(\mathbf{F}_{t} W_{a}\right) \odot \mathbf{F}_{\mathrm{d}}^{\mathrm{ag}} W_{2}\right)\tag{10} Ht?=σ(Ft?W1?+Sigmoid(Ft?Wa?)⊙Fdag?W2?)(10)
⊙ \odot ⊙是點積,物件特征向量在不同維度上的值代表了被捕獲物件不同部位的特征,不同部位可能是區分物件的關鍵,因此聚合資訊是需要給不同維度特征加權,設定一個自適應引數 W a W_a Wa?, S i g m o i d ( F d W a ) Sigmoid{\left(\mathbf{F}_dW_a\right)} Sigmoid(Fd?Wa?)作為自適應權重,
更新完特征后,通過全連接層,來減少圖網路更新后的特征的維度,并計算歐式距離來測量特征之間的相似性,我們只需要一個簡單的單層圖網路將輸出的特征向量進行歸一化,然后通過矩陣乘法即可得到相似度矩陣: h d i = h d i ∥ h d i ∥ 2 h t j = h t j ∥ h t j ∥ 2 S out = H d H t T (11) \begin{aligned} h_{d}^{i} &=\frac{h_{d}^{i}}{\left\|h_{d}^{i}\right\|_{2}} \\ h_{t}^{j} &=\frac{h_{t}^{j}}{\left\|h_{t}^{j}\right\|_{2}} \\ \mathbf{S}_{\text {out }} &=\mathbf{H}_{\mathrm{d}} \mathbf{H}_{\mathrm{t}}^{\mathrm{T}} \end{aligned}\tag{11} hdi?htj?Sout ??=∥∥?hdi?∥∥?2?hdi??=∥∥∥?htj?∥∥∥?2?htj??=Hd?HtT??(11)
相同目標輸出1,不同目標輸出0,其目的是使同一目標的特征向量近似重合,不同目標的特征向量近似垂直,當特征向量未歸一化且元素均大于0時,相當于同一目標之間特征的歐幾里得距離越近,不同目標之間的歐幾里得距離越長越好,
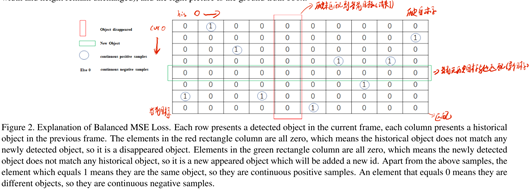
3.2 平衡MSE Loss
在所有的目標中,新出現的目標和消失的目標占少數,所以他們在損失中的比重也相應的小,對于每個目標,至多存在一個正樣本(label=1),相應的其余都是負樣本(label=0),采樣極度不平衡,因此想到了在每種損失前面乘以一個系數,來達到平衡的作用,
L
=
α
E
c
0
+
β
E
c
1
+
γ
E
n
e
+
δ
E
d
+
ε
E
w
=
∑
i
=
1
M
∑
j
=
1
N
[
α
(
S
^
i
,
j
?
S
i
,
j
)
2
?
I
continue
?
I
S
i
,
j
=
0
+
β
(
S
^
i
,
j
?
S
i
,
j
)
2
?
I
continue
?
I
S
i
,
j
=
1
+
γ
(
S
^
i
,
j
?
S
i
,
j
)
2
?
I
n
e
w
+
δ
(
S
^
i
,
j
?
S
i
,
j
)
2
?
I
disap
+
ε
∥
W
∥
2
2
]
(12)
\begin{aligned} \mathcal{L} &=\alpha E_{c 0}+\beta E_{c 1}+\gamma E_{n e}+\delta E_{d}+\varepsilon E_{w} \\ &=\sum_{i=1}^{M} \sum_{j=1}^{N}\left[\begin{array}{c} \alpha\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {continue }} \cdot \mathbb{I}_{S_{i, j}=0}+\beta\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {continue }} \cdot \mathbb{I}_{S_{i, j}=1} \\ +\gamma\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{n e w}+\delta\left(\hat{S}_{i, j}-S_{i, j}\right)^{2} \cdot \mathbb{I}_{\text {disap }}+\varepsilon\|W\|_{2}^{2} \end{array}\right] \end{aligned}\tag{12}
L?=αEc0?+βEc1?+γEne?+δEd?+εEw?=i=1∑M?j=1∑N?????α(S^i,j??Si,j?)2?Icontinue ??ISi,j?=0?+β(S^i,j??Si,j?)2?Icontinue ??ISi,j?=1?+γ(S^i,j??Si,j?)2?Inew?+δ(S^i,j??Si,j?)2?Idisap ?+ε∥W∥22???????(12)
I
c
(
S
i
,
j
)
=
{
1
,
if
S
i
,
j
is the c target
0
,
if
S
i
,
j
isn’t the c target
\mathbb{I}_{c}\left(S_{i, j}\right)=\left\{\begin{array}{c} 1, \text { if } S_{i, j} \text { is the c target } \\ 0, \text { if } S_{i, j} \text { isn't the c target } \end{array}\right.
Ic?(Si,j?)={1, if Si,j? is the c target 0, if Si,j? isn’t the c target ?其中𝛼,𝛽,𝛾,𝛿,𝜀是超參,
3.3 推理
通過自適應矩陣獲得的相似度矩陣S_{out},然后在其右邊增加一個 M × M M\times M M×M的矩陣,其所有元素為 m a r g i n = π margin = π margin=π,形成一個增廣矩陣 S o u t = [ S o u t , π × 1 M × M ] S_{out}=\ [S_{out},\ \pi\ \times\ 1_{M\times M}] Sout?= [Sout?, π × 1M×M?],然后使用匈牙利演算法匹配,
3.3.1. 匹配關聯和新目標的出現
假設匈牙利輸出為
(
i
,
j
)
(i,j)
(i,j),
i
i
i代表行,
j
j
j代表列,如果
j
<
N
j<N
j<N,則
i
i
i和
j
j
j的軌跡匹配,
j
j
j的
i
d
id
id就分配給
i
i
i;否則i就是個新目標,然后
i
i
i的
i
d
id
id就為
m
a
x
{
i
d
}
+
1
max\{id\}\ +\ 1
max{id} + 1,

3.3.2. 目標消失
假設選取的過去幀數為10,如果一個目標在接下來的10幀中都沒有匹配成功,則目標會被認為是消失,
四、 總結
MOTChalleng上達到了SOTA,提高很大,這項作業進一步研究了如何提取更好的物件特征,以獲得更好的資料關聯,第一次使用再當前幀中預測過去幀的位置資訊,并且提取特征,將他們和當前幀檢測到的特征共同輸入到自適應圖網路,通過整合時空全域位置和外貌資訊來更新特征,同時提出了一個平衡MSE損失用于訓練,能夠更加平衡不同型別目標之間的損失的權重,以便讓神經網路更好的資料關聯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/205430.html
標籤:其他
上一篇:A Knee_Guided Evolutionary Algorithm for Compressing Deep Neural Network (KGEA)解讀