
作者|Lamothe Thibaud
編譯|Flin
來源|towardsdatascience
使用曲率積分和動態時間規整,讓我們深入研究抹香鯨識別!
前言
最近,我們嘗試了Capgemini的全球資料科學挑戰賽,我與Acores鯨魚研究中心合作,挑戰的目的是確定抹香鯨,用人工智能幫助拯救抹香鯨的生命,
為了完成這項任務,我們收集了幾千張過去幾年的鯨魚照片,在訓練資料集中,平均每頭鯨魚有1.77張照片,很多動物只出現過一次,因此,主要思想是,給定一個新的圖片,在已有資料中找出最接近它的,
因此,如果鯨魚已經被拍下來,研究人員就可以知道是何時何地拍的了,
我很自豪地宣布,我們以第三名的成績結束了比賽,我們使用暹羅網路取得了勝利,但是,由于已經有很多關于這個奇妙架構的文章,今天我將介紹一個更有趣、更新穎的方法來解決這個問題,
方法
由Weideman等人設計,在他們的論文“用于識別海豚和鯨魚的曲率積分表示和匹配演算法”中,這是我今天要介紹的方法的關鍵步驟如下:
-
基于顏色分析和輪廓檢測的尾部提取
-
曲率積分尾部處理(IC)
-
與動態時間規整(DTW)的尾部比較
免責宣告N°1:預測率不如暹羅網路好,我們不得不探索其他解決方案,但是這個想法非常有趣,值得分享和了解,
免責宣告N°2:在許多資料科學專案中,資料準備是最困難的部分,實際上,要將尾部處理為信號,信號的質量必須非常好,在本文中,我們將花一些時間來理解信號處理之前的所有必要步驟,
探索我們的資料集,分析圖片
如引言中所述,我們得到了數千張圖片,乍一看,鯨魚就是鯨魚,所有這些圖片看上去都像是一個藍色背景(天空和大海),中間有一個灰色斑點(尾巴),
經過初步探索之后,我們開始在兩條不同的抹香鯨之間進行區別,這主要歸功于尾巴的形狀,我們確信這對我們的演算法至關重要,那顏色呢?像素分布中是否有什么有趣的資訊?

每個圖片中顏色數量之間的相關性(綠色與紅色–藍色與紅色–綠色與藍色)
使用Bokeh可視化庫(https://bokeh.org/) ,我們很快發現影像中的顏色高度相關,因此,我們專注于輪廓,嘗試通過顏色變化來檢測它們,
基于彩色濾波器的尾部提取
檢測尾巴輪廓的第一步是從天空和水中提取尾巴,實際上,這是該程序中最困難的部分,
首先,我們使用輪廓檢測??演算法,但是由于從一個鏡頭到另一個鏡頭的陽光不斷變化,因此對比度發生了很大變化,結果總不能令人滿意,
順便說一句,看到圖片演算法失敗最多的地方還是很有趣的,因為在大多數情況下,尾巴和大海之間的區別對于人類來說是顯而易見的,
話雖如此,讓我們深入研究顏色分析和輪廓提取自動化,
使用顏色提取尾巴
讓我們為每個通道強度(紅色,綠色,藍色)繪制灰度圖片

觀察單個圖片的三個通道
正如你在上面看到的,對于大多數圖片來說都是這樣,圖片中間的顏色較少,可以按像素強度進行過濾,由于尾巴通常是灰色的,因此它們的每種顏色的數量幾乎相同(R = G = B),但是,海和天空往往是藍色的,這使該顏色成為過濾的理想選擇,
讓我們看看當只保留藍色值,并且只保留藍色值<選定的閾值(blue_value < SELECTED_THRESHOLD)的像素時會發生什么,
選定的閾值SELECTED_THRESHOLD的最大值為255,因為它是像素強度的最大值,

通過這一系列圖片,我們可以相信,提取尾巴很容易,但是我該如何選擇過濾閾值?
以下是使用10到170(十乘十)的所有值作為單個圖片的閾值的結果示例,
根據藍色像素的強度,在一張圖片上應用17種不同的濾波器:

以下是一些有趣的內容:
-
閾值很小(大約10),大海消失了,但尾巴也消失了
-
閾值很小(大約20),尾巴的一部分消失了
-
閾值不太高(大約40),提取的挺好,所有的尾巴都沒有閾值那么藍,但是所有的大海都比閾值藍,
-
在中間閾值(大約80)的情況下,尾巴保持完整,但我們開始只能保留部分海洋
-
在接近中間值的閾值(約110)的情況下,很難區分海和尾巴
-
在較高的閾值(>=140)下,尾巴完全消失,這意味著即使大海也不夠藍,無法通過過濾器選擇,
這樣就到了,而且似乎很明顯應該采用SELECTED_THRESHOLD = 40并應用filter blue_value < 40,
可以猜到,這并不容易,給定該圖片的光強度,該圖片的正確值為40,但是這也是陳詞濫調了,通過將所有這些閾值繪制在隨機圖片上的結果,該閾值發生在10到130之間變化,那么如何選擇合適的值呢?
使用邊界框選擇閾值
通過查看前面的圖片,我們想到了一些東西:正確閾值的正確圖片是外部具有最大空白區域而內部具有最大區域的影像,并希望一些在ImageNet上訓練的神經網路可以將鯨魚定位在圖片中,我們決定使用基于ImageNet類的MobileNet,
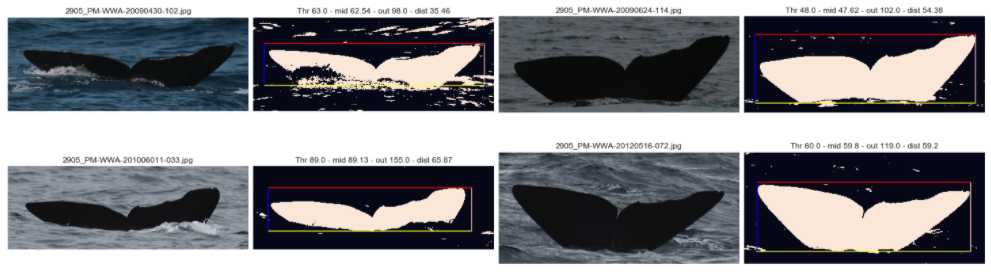
與原始圖片相比,一批提取的尾巴帶有邊框
這真是個好主意,如下所示,我們可以非常準確地確定圖片中尾巴的位置,然后,我們幾乎可以在所有圖片中將“尾部-內部”與“海部-外部”分開,
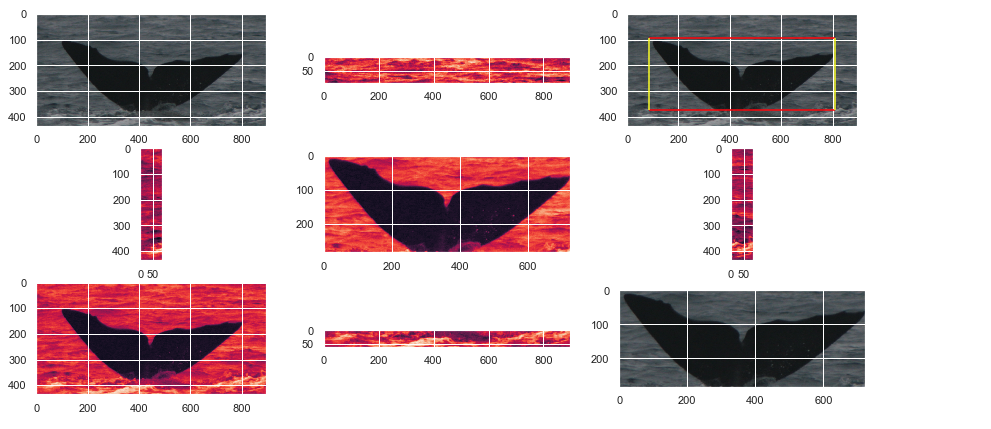
為了更好地了解這種分離,對于訓練集的每張圖片,我們將邊界框內每個像素的藍色值相加,并對框外的像素進行相同的處理,
然后,我們在下圖上繪制每個圖片,內部結果體現在X軸上,外部結果體現在Y軸上,藍線代表X = Y,我們可以從此圖形中獲得的含義如下:你離線條越遠,尾巴和海洋之間的分隔就越容易,
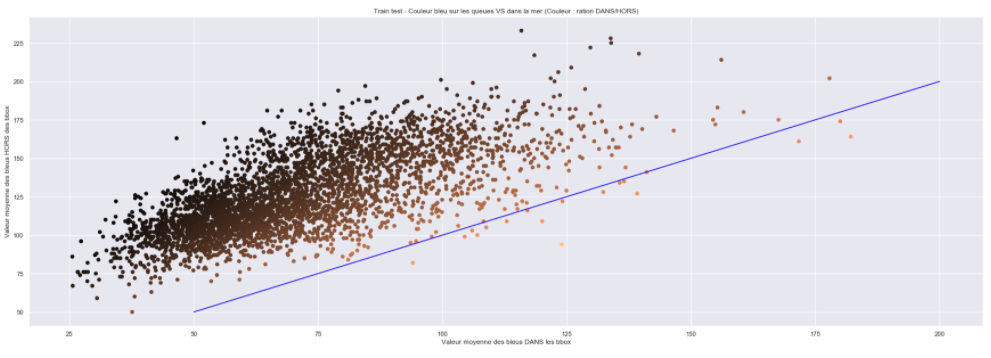
在邊界框內外的藍色像素強度下比較抹香鯨圖片
我們嘗試根據與線的距離應用過濾器閾值,但這沒有產生任何結果,經過幾次嘗試,我們僅根據圖片的顏色分布做不出什么,因此決定采用強硬的方法,除了查看圖片并確定閾值外,我們還為每張圖片應用15個濾波器,對其進行分析,然后自動選擇最佳濾波器以進行進一步處理,
然后對于給定的圖片,我們將15個濾波器應用了15個不同的值作為閾值,對于每個濾波器,我們計算邊界框內的像素和外面的像素的數量(過濾后,像素值為0或1,無需再對強度求和),然后,我們對結果進行歸一化,使數字獨立于影像的大小,并將結果繪制在一個圖形上,
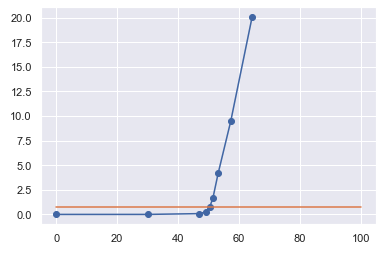
單個圖片和不同過濾閾值的邊界框內(X軸)和外框(Y軸)的像素數量,
對于每張圖片,我們得到的曲線都類似于上面的曲線,這是我們隨著閾值的演變而對前面的陳述進行的數學轉換,
-
當閾值很小時,尾巴和大海消失了,尾部內部或外部均無像素
-
當閾值增加時,出現尾巴,并且X軸的值升高,
-
直到閾值開始出現在海洋的某些部分,并且外部價值開始增長,
使用線性回歸或導數,現在很容易檢測到正確的閾值:它是圖的兩條線的交點處的閾值,
注意:橙色線是 y = y_of_the_selected_threshold
尾巴提取的最后提示
最后,為了在提取時得到最好的圖片,當我們計算出最佳閾值(10,20,30,40,…,120,130,140,150)時,假設是80,我們對-5/+5值應用了過濾器,所以我們有三張照片:藍色< 75,藍色< 80,藍色< 85,然后我們將這些網格圖片中的三個(0和1)求和,并且只保留結果像素的值等于2,這將作為最后的過濾器,去除尾部的噪音,這樣的提取效果很好,我們決定適用于所有的圖片,
結果
作為總結,以下是我們到目前為止所做的假設:
-
我們可以使用濾波器對藍色像素的強度把尾巴和海洋區分開
-
在過濾之前,需要為每個圖片找到一個閾值
-
使用邊界框是找到此閾值的有效的方法
經過幾個小時的作業,我們最終得到了一個非常好的尾巴提取器,可以很好地處理具有不同亮度,天氣,海洋顏色,尾巴顏色的尾巴,并且能夠瀏覽最難的圖片,

一批提取出來的尾巴與原始圖片進行比較
輪廓檢測
現在尾部位于圖片中,我們進行輪廓檢測,確實,要處理時間序列中的尾巴,我們需要發出信號,
在這一步,我們可以使用OpenCV的輪廓檢測演算法,但是通過以下兩個步驟,看起來會更快一些:
步驟1:使用熵去除尾巴周圍的噪聲
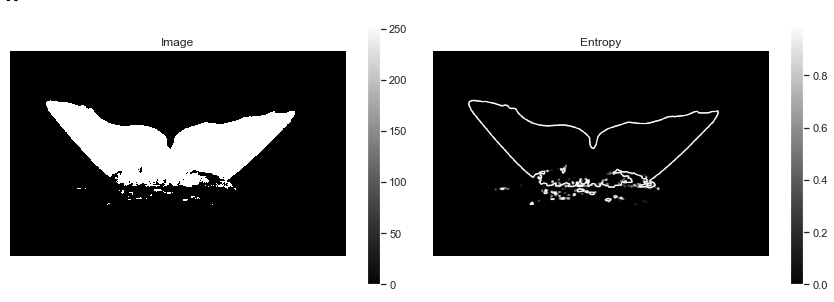
使用熵變僅保留提取的尾巴的輪廓
步驟2:保持每列圖片的高光像素
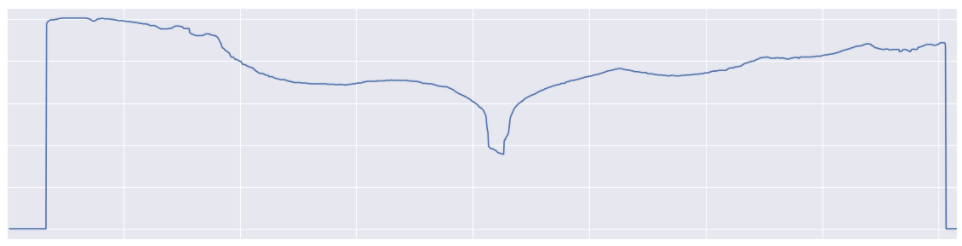
應用熵濾波器后檢測到的提取的尾巴輪廓
此步驟非常簡單,沒有什么復雜性,
曲率積分
通過從海中提取尾巴并獲取圖片的上部像素,我們得到了尾巴的后沿作為信號,現在我們有了這個,我們就要處理規范化問題,實際上,所有圖片的大小或像素數量都不相同,此外,到抹香鯨的距離并不總是相同的,拍攝時的方位可能會發生變化,
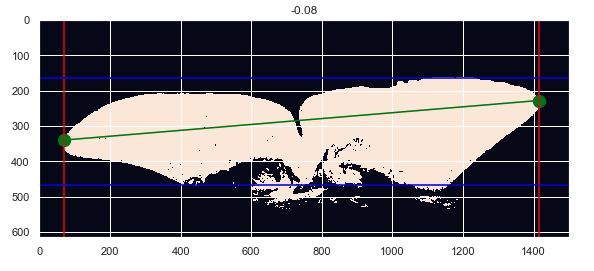
尾巴方向的示例,同一條鯨的兩張照片之間可能會有所不同
為了進行標準化,我們必須沿著兩個軸進行,首先,我們決定使用每條尾巴300個點進行信號比較,然后我們對最短的插值進行插值,并對最長的進行采樣,其次,我們將0到1之間的所有值歸一化,這導致信號疊加,如下圖所示,
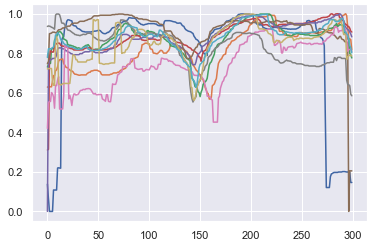
標度信號疊加
為了解決定向問題,我們使用了曲率積分度量,該度量通過區域評估將信號轉換為另一個信號,
如原始論文中所述:“它捕獲沿后緣的每個點的區域形狀資訊,對于位于后緣上的給定點,我們在該點處放置一個半徑為r的圓,然后找到后緣上位于該圓內的所有點,”
然后,在每一步中,我們將信號的邊緣沿圓形拉直,以使其內接為正方形,
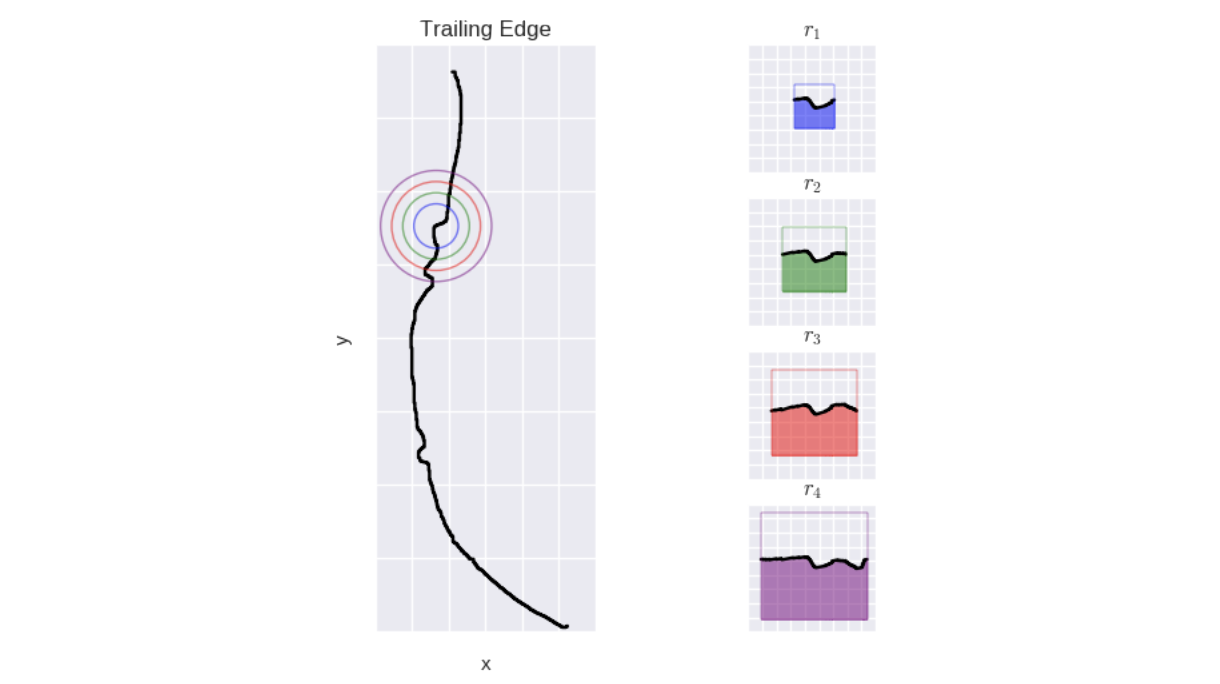
曲率積分原理
最后,我們定義曲率如下:
曲率是曲線下到正方形總面積的面積,這意味著直線的曲率值為c = 0.5
因此,我們獲得了標準化信號,與鯨魚和攝影者之間的距離無關,與鯨魚和攝影者之間的角度無關,并且與鯨魚和海洋之間的傾角無關,
然后,對于每張訓練測驗圖片,我們在IC相移期間創建了半徑分別為5、10和15像素的那些信號,我們將它們存盤起來,并用于最后一步:時間序列之間的比較,
在本文中,我將介紹這種演算法的實作,一旦作業,我們就可以將其應用到尾緣,并從環境細節中提取信號,對于一條尾巴,信號看起來像這樣:
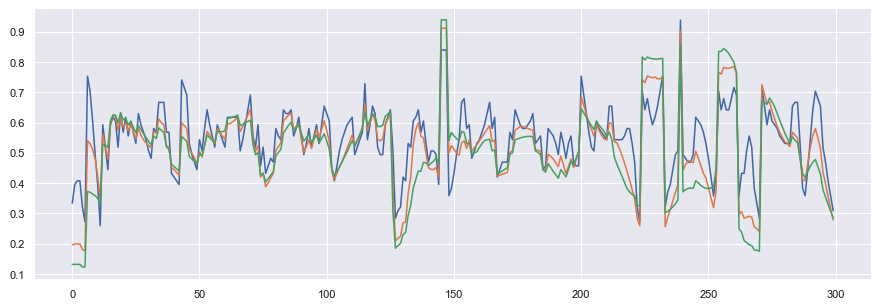
曲率積分應用于帶有3個不同半徑值的抹香鯨尾緣
現在,讓我們進行信號比較!
動態時間規整
動態時間規整(DTW,https://en.wikipedia.org/wiki/Dynamic_time_warping) 是一種能夠在兩個時間序列之間找到最佳對齊方式的演算法,它通常用于確定時間序列的相似性,分類以及查找兩個時間序列之間的對應區域,
與歐幾里得距離(指??的是兩條曲線之間的距離,逐點)相反,DTW距離允許鏈接曲線的不同部分,該演算法的作業原理如下:
使用2條曲線,我們創建了兩個系列之間的距離矩陣,從左下角到右上角,計算兩點之間的距離Ai和Bi,如下計算兩個點之間的距離:D(Ai, Bi) = |Ai — Bi] + min(D[i-1, j-1], D[i-1, j], D[i, j-1]),
當距離矩陣滿足時,我們計算從右上角到左下角的權重較小的路徑,為此,我們在每一步中選擇具有最小值的平方,
最后,所選的路徑(下圖中的綠色)指示來自序列A的哪個資料點對應于序列B中的資料點,
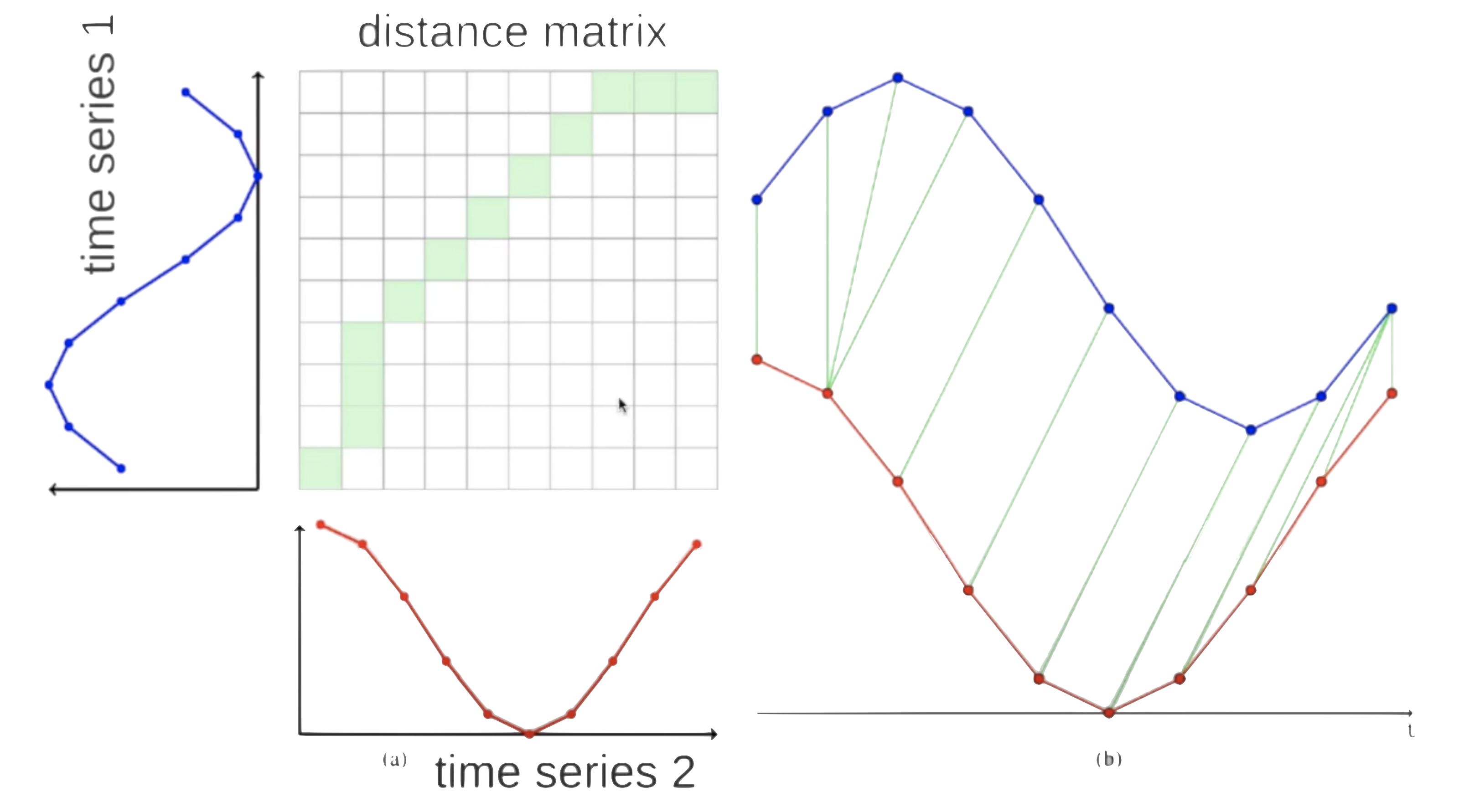
這樣的基本計算的實作非常容易,例如,這是一個根據兩個序列s和創建距離矩陣的函式t,
def dtw(s, t):
""" Computes the distance matrix between two time series
args: s and t are two numpy arrays of size (n, 1) and (m, 1)
"""
# Instanciate distance matrix
n, m = len(s), len(t)
dtw_matrix = np.zeros((n+1, m+1))
for i in range(n+1):
for j in range(m+1):
dtw_matrix[i, j] = np.inf
dtw_matrix[0, 0] = 0
# Compute distance matrix
for i in range(1, n+1):
for j in range(1, m+1):
cost = abs(s[i-1] - t[j-1])
last_min = np.min([
dtw_matrix[i-1, j],
dtw_matrix[i, j-1],
dtw_matrix[i-1, j-1]
])
dtw_matrix[i, j] = cost + last_min
return dtw_matrix
話雖如此,讓我們回到我們的抹香鯨!資料集的每個尾巴都轉換為“積分曲線信號”,我們計算了所有尾巴之間的距離,以發現最接近的那些,
之后,當接收到一張新圖片時,我們必須使其通過整個準備流程:使用藍色濾波器的尾部提取,使用熵方法進行輪廓檢測以及使用IC進行輪廓轉換,它給了我們一個300x1形狀的張量,最后我們要計算整個資料集的距離,順便說一句,這很費時,
判決:結果可觀!當我們有兩張相同的鯨魚照片時,在大多數情況下,兩張照片是最接近的40張,這在2000年中是最好的,但是,如引言中所述,使用暹羅網路的結果要好于這張照片(圖片通常在最近的5張中) ),鑒于比賽的時間,我們不得不在調查中選擇其他的方法,
獎勵:處理一半的尾巴和一半的信號
我們嘗試使用半尾巴,假設以下任一情況:
-
尾巴是對稱的,這將簡化計算,
-
尾巴是不對稱的,因此可以通過半尾巴進行比較,
盡管進行了大量測驗,但這并沒有給我們非常確定的結果,我們認為我們的分離不夠可靠:我們將需要更多時間來研究信號處理帶來的更好分離,
最后的想法
在發送了一些比我們想象的要難的時間的尾部提取后,由于圖片的顏色(基本上是藍色——海洋和天空)以及資料集中圖片的各種亮度,我們對尾巴識別應用了兩種連續的處理方法,
首先,曲率積分是一種通過查看曲線的區域變化對信號進行歸一化的方法,然后,我們使用了動態時間規整,這是兩條曲線之間的距離計算,即使移動了兩條曲線也可能會發現兩條曲線之間的相似性,
不幸的是,結果并不如我所愿,我們無法繼續使用該解決方案,通過更多的時間和更多的努力,我深信我們可以改進管道的每個步驟,從而獲得更好的模型,我也非常喜歡和本文提到的這些概念一起作業,
通過所有步驟,實作它們的不同方法以及引數,監視所有轉換非常具有挑戰性,正如我們有路線圖一樣,每一步都有其自身的困難,每一次小小的成功都是勝利,它開啟了下一步,非常可喜,
我發現這種方法非常有趣,并且與通常的預訓練的CNN完全不同,希望你也喜歡本文主題的這種方法的優點,如有任何疑問,請隨時與我聯系??
參考文獻
-
我們從這篇論文中得到了IC + DTW的想法:
- https://arxiv.org/abs/1708.07785
-
動態時間規整1–0–1(中等)
- https://towardsdatascience.com/dynamic-time-warping-3933f25fcdd
-
DTW python實作
- https://pypi.org/project/dtw-python/
-
Kaggle座頭鯨鑒定比賽
- https://www.kaggle.com/c/humpback-whale-identification
-
關于此次活動的Capgemini 網頁(面向公司外人員)
- https://www.yammer.com/capgemini.com/#/threads/inGroup?type=in_group&feedId=13438430&view=all
原文鏈接:https://towardsdatascience.com/whale-identification-by-processing-tails-as-time-series-6d8c928d4343
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208643.html
標籤:其他