作者|Stan Kriventsov
編譯|Flin
來源|medium
在這篇博文中,我想在不作太多技術細節的情況下,解釋其作者提交給2021 ICLR會議的新論文“一張圖等于16x16個字:用于大規模影像識別的變壓器”的意義(目前為止匿名),
另一篇文章中,我提供了一個示例,該示例將這種新模型(稱為Vision Transformer,視覺變壓器)與PyTorch一起用于對標準MNIST資料集進行預測,
自1960年以來深度學習(機器學習利用神經網路有不止一個隱藏層)已經問世,但促使深度學習真正來到了前列的,是2012年的時候AlexNet,一個卷積網路(簡單來說,一個網路,首先查找小的圖案在影像的每個部分,然后嘗試將它們組合成一張整體圖片),由Alex Krizhevsky設計,贏得了年度ImageNet影像分類競賽的冠軍,
-
AlexNet:https://en.wikipedia.org/wiki/AlexNet
-
ImageNet影像分類競賽:https://en.wikipedia.org/wiki/ImageNet
在接下來的幾年里,深度計算機視覺技術經歷了一場真正的革命,每年都會出現新的卷積體系結構(GoogleNet、ResNet、DenseNet、EfficientNet等),以在ImageNet和其他基準資料集(如CIFAR-10、CIFAR-100)上創下新的精度記錄,
下圖顯示了自2011年以來ImageNet資料集上機器學習模型的最高精度(第一次嘗試時正確預測影像所含內容的準確性)的進展情況,
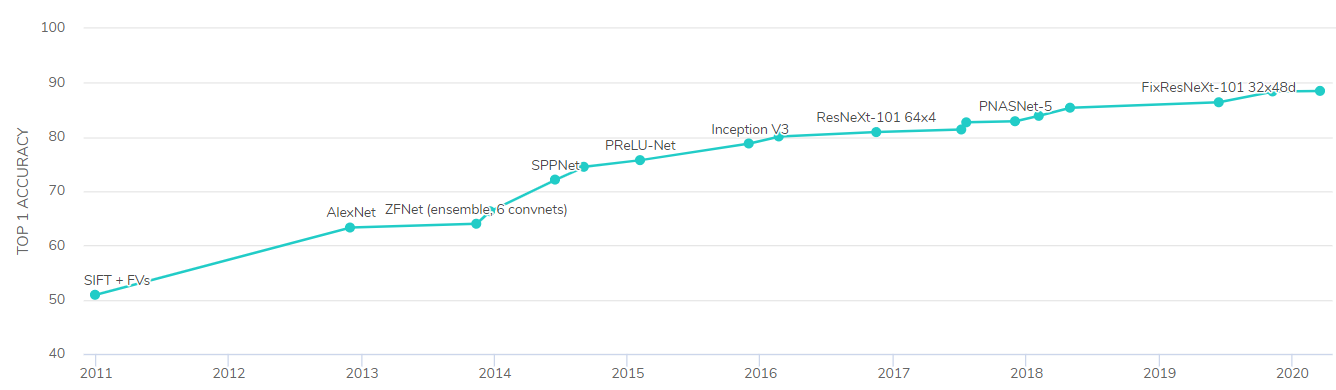
然而,在過去的幾年里,深度學習最有趣的發展不是在影像領域,而是在自然語言處理(NLP)中,這是由Ashish Vaswani等人在2017年的論文“注意力是你需要的一切”中首次提出的,
- 論文地址:https://arxiv.org/abs/1706.03762
注意力的思想,指的是可訓練的權重,模擬輸入句子不同部分之間的每個連接的重要性,對NLP的影響類似于計算機視覺中的卷積網路,極大地提高了機器學習模型對各種語言任務(如自然語言理解)的效果還有機器翻譯的效果,
注意力之所以對語言資料特別有效,是因為理解人類語言通常需要跟蹤長期依賴關系,我們可能會先說“我們到達了紐約”,然后說“城市的天氣很好”,對于任何人類讀者來說,應該很清楚,最后一句話中的“城市”指的是“紐約”,但對于一個只基于在附近資料(如卷積網路)中找到模式的模型,這種聯系可能無法檢測,
長期依賴性的問題可以通過使用遞回網路來解決,例如LSTMs,在變壓器到來之前,LSTMs實際上是NLP中的頂級模型,但即使是那些模型,也很難匹配特定的單詞,
變壓器中的全域注意力模型衡量了文本中任意兩個單詞之間每一個連接的重要性,這解釋了它們性能的優越之處,對于注意力不那么重要的序列資料型別(例如,日銷售額或股票價格等時域資料),遞回網路仍然具有很強的競爭力,可能仍是最佳選擇,
雖然在NLP等序列模型中,遠距離物件之間的依賴關系可能具有特殊的意義,但在影像任務中,它們肯定不能被忽略,要形成一幅完整的圖畫,通常需要了解影像的各個部分,
到目前為止,注意力模型在計算機視覺中一直表現不佳的原因在于縮放它們的難度(它們的縮放比例為N2,因此1000x1000影像的像素之間的全套注意力權重將具有一百萬項),
也許更重要的是,事實上,與文本中的單詞相反,圖片中的各個像素本身并不是很有意義,因此通過注意力將它們連接起來并沒有太大作用,
這篇新論文提出了一種方法,即不關注像素點,而是關注影像的小塊區域(可能是標題中的16x16,盡管最佳塊尺寸實際上取決于模型的影像尺寸和內容),
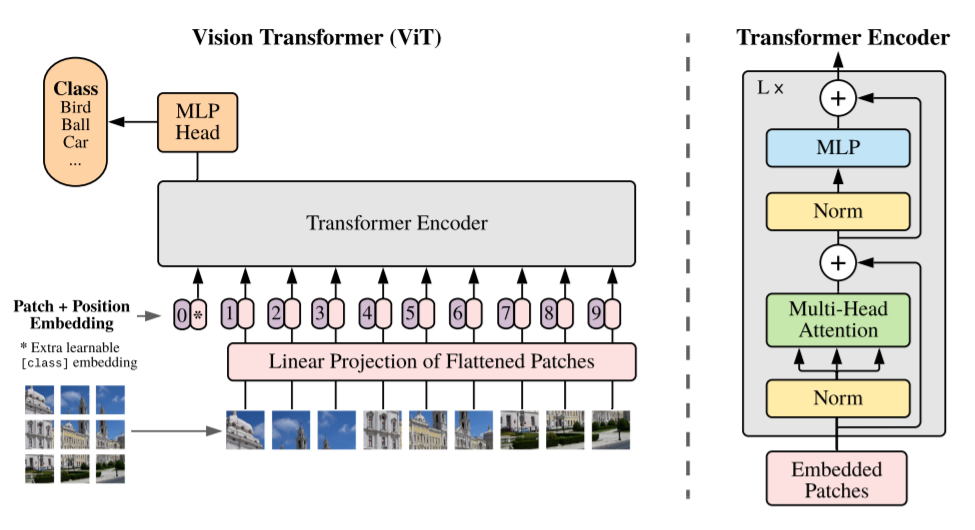
上面的圖片(摘自論文)顯示了視覺變壓器的作業方式,
通過使用線性投影矩陣將輸入影像中的每個色塊展平,并向其添加位置嵌入(學習的數值,其中包含有關該色塊最初在影像中的位置的資訊),這是必需的,因為變壓器會處理所有輸入,而不考慮其順序,因此擁有此位置資訊有助于模型正確評估注意力權重,額外的類標記連接到輸入(影像中的位置0),作為要在分類任務中預測的類的占位符,
類似于2017版,該變壓器編碼器由多個注意力,規范化和完全連接的層組成,這些層具有殘差(跳過)連接,如圖中的右半部分所示,
在每個關注區域中,多個頭部可以捕獲不同的連接模式,如果你有興趣了解有關變壓器的更多資訊,我建議閱讀Jay Alammar撰寫的這篇出色的文章,
- http://jalammar.github.io/illustrated-transformer/
輸出端完全連接的MLP頭可提供所需的類別預測,當然,與當今一樣,主模型可以在大型影像資料集上進行預訓練,然后可以通過標準的遷移學習方法將最終的MLP頭微調為特定任務,
新模型的一個特點是,盡管根據本文的研究,它比卷積方法更有效地以更少的計算量獲得相同的預測精度,但隨著它接受越來越多的資料訓練,其性能似乎在不斷提高,這比其他模型更甚,
這篇文章的作者在一個包含3億的私有googlejft-300M資料集上訓練了視覺變換器影像,從而在許多基準測驗中都獲得了最先進的準確性,人們可以期待這個預先訓練過的模型很快就會發布出來,以便我們都可以試用,
- 資料集:https://arxiv.org/abs/1707.02968
看到神經注意力在計算機視覺領域的新應用,實在太令人興奮了!希望在未來的幾年里,在這種發展的基礎上,能取得更大的進步!
原文鏈接:https://medium.com/swlh/an-image-is-worth-16x16-words-transformers-for-image-recognition-at-scale-brief-review-of-the-8770a636c6a8
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208645.html
標籤:其他