田海立@CSDN 2020-11-07
PyTorch 1.3中發布Pytorch Mobile,其支持情況如何,能否與TensorFlow Lite一較高下呢?本文試分析之,PyTorch Mobile的宣傳顯得要么誠意不足要么對行業領悟不夠,目前只能說是有Mobile這個路在而已,與TFLite比不可同日而語,至少目前的實作是,相對于Google移動端的即有Android生態布局,Facebook有其苦衷,要堅守其生態底線又要放棄次要考量去適配NNAPI才是其捷徑,
一、歷史
Facebook歷史上,在Caffe2中號稱設計之初就為移動部署考慮的,筆者也跟蹤了幾年,發現Caffe2對NNAPI的支持就是3年前提交過代碼,也只是對幾個最常用算子做了適配,幾乎是無所作為,當然顯然Caffe2目前也基本是被廢棄的狀態,現在PyTorch實作Mobile支持,特別是PyTorch作為訓練(模型)框架,已占主導地位,當然也應關注其在移動領域的表現,
關注AI移動領域的讀者應該有所了解,其實TensorFlow最初對移動的支持是通過TensotFlow Mobile,之后才是重新實作了TensorFlow Lite,而TensorFlow Mobile也終究是被放棄的,
二、PyTorch Mobile
據PyTorch Mobile網站介紹,處在Beta階段,待API穩定之后,很快會推出穩定版,Feature包括:
- 為ios,Android,Linux提供支持;
- 提供API,涵蓋將 ML 集成到移動應用中所需的常見預處理和集成任務;
- 通過TorchScript IR支持tracing與scripting;
- 支持 XNNPACK為ARM CPU上執行浮點運算;
- 集成QNNPACK 支持INT8量化內核庫,可支持per-channel量化、動態量化以及其他方式;
- 根據用戶的應用需求進行構建級別的優化和選擇性編譯,也就是根據應用如用的模型里的算子可定制選擇算子從而改變最終編譯出目標程式的尺寸;
- GPU/DSP/NPU等backends會在后續支持,
典型作業流程:
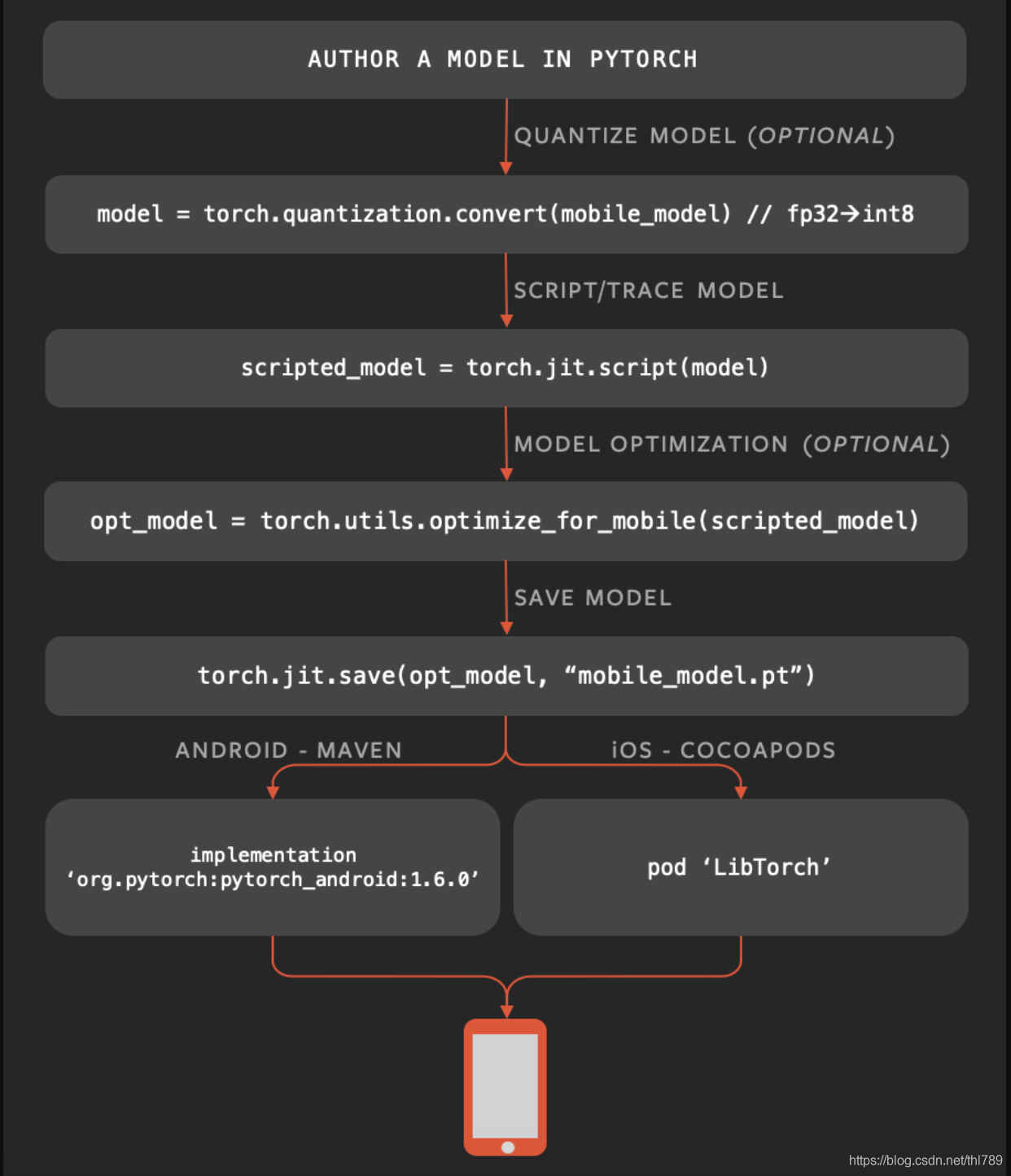
與別的推理框架其實并沒大的差別:
- 把訓練出的模型進行量化(可選)
- 模型轉換:pt(TorchScript)
- 優化(可選)
- 保存
- 部署到終端上執行
只是,上述1~4步驟中在Host上完成;步驟5在手機或別的端側設備上部署,別的方案把這些都明白的交代清楚了而已,
三、PyTorch Mobile前景分析
PyTorch Mobile目前發布的資訊可以說是沒什么特別的新意,本來就在移動端落后了TensorFlow Lite很多,第一次發布這種情況也可以理解,
不過,有些說法就讓人覺得要么真的跟產業離的太遠,不知道端側設備的痛點在哪,要么誠意不足!
看Facebook所宣傳的PyTorch Mobile的“賣點”:
- No new framework
- No model conversion
- No operator porting
No new framework:都已經轉換了模型了,在端側設備上執行pt模型了還說是沒有新的Framework,應該是有一個端側Runtime的東西在運行,什么量級的才叫Framework呢?刻意隱藏不告訴普通開發者而已,
No model conversion:變成pt TorchScript模型了不是模型轉換嗎?而且將來有NPU/GPU/DSP支持沒有模型轉換或編譯的存在才怪,也還是偷換概念,
No operator porting:這點還沒有深入看實作,不好說做沒做,不過知道TensorFlow Mobile到TensorFlow Lite發展變化歷程的讀者應該都知道,這可能不是賣點,而是還沒get到痛點,之前TensorFlow Mobile是挑選了一些TF的算子做了個c++的推理,但是尺寸和運行速度都是端上設備最關注的,所以后來才全部重寫算子,重新實作而成的TFLite,TensorFlow Mobile也被放棄了,后來者可能連TF Mobile的名字都沒聽說過,當然,可能PyTorch Mobile也是重寫了的,只是不宣傳,隱藏起來而號稱的算子一樣而已,
目前PyTorch Mobile只能說是有Mobile這個路在而已,與TFLite的現狀不可同日而語,至少目前的現狀是,
端側設備更關注的是Latency、功耗、隱私等,所以對加速器的支持更重要:
- TFLite里對GPU通過Delegate機制(OpenCL/OpenGL ES)支持;
- TFLite對Qualcomm Hexagon提供Delegate機制支持;
- TFLite對通過NNAPI Delegate對所有NN Device(GPU/DSP/NPU)提供支持
當然對Arm CPU浮點計算今年7月也提供了XNNPACK delegate方式,加上之前Neon/dotproduct的INT計算支持等,基本上對CPU和加速器(NPU/GPU/DSP)的支持是完備的,
PyTorch Mobile到目前還沒看到這部分的實作,公開場合也沒看到具體計劃,
四、總結
顯然與Google不會加入ONNX一樣,Facebook的PyTorch也不會提供模型轉換或適配的方式轉換到Google的TensorFlow生態,而是守住自己生態內的這條底線的情況下,盡量支持端側設備,
Google手里有Android,并耕耘了這么多年,對移動設備的理解和生態布局不是Facebook所能比擬的,PyTorch Mobile如果把競爭對手瞄準TensorFlow Lite,不要針對AndroidNN(NNAPI),積極擁抱去適配NNAPI,倒是推動AI設備支持的捷徑,AndroidNN誕生之初的定位本就是與上層ML Framework配合,不假定上層ML Framework一定是TFLite,這也剛好契合,
 CSDN認證博客專家
系統分析師
Android
人工智能
CSDN認證博客專家
系統分析師
Android
人工智能
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208959.html
標籤:其他
上一篇:2020CCFBDCI訓練賽之室內用戶時序資料分類baseline
下一篇:讀書筆記-增量學習-iCaRL: Incremental Classifier and Representation Learning