一篇2017年的經典文章,iCaRL: Incremental Classifier and Representaion Learning,作者提出了一種增量學習實作方法簡稱iCaRL,這是一種增加識別種類的學習演算法,想法是構建并管理一個exemplar set(舊資料的代表性樣本集合),在增量學習階段,把新資料和該exemplar set混合作為輸入資料,模型訓練結束后,再把部分新資料添加到exemplar set,并剔除部分舊資料(因為記憶體有限),
在未增量的模型中,執行以下演算法:
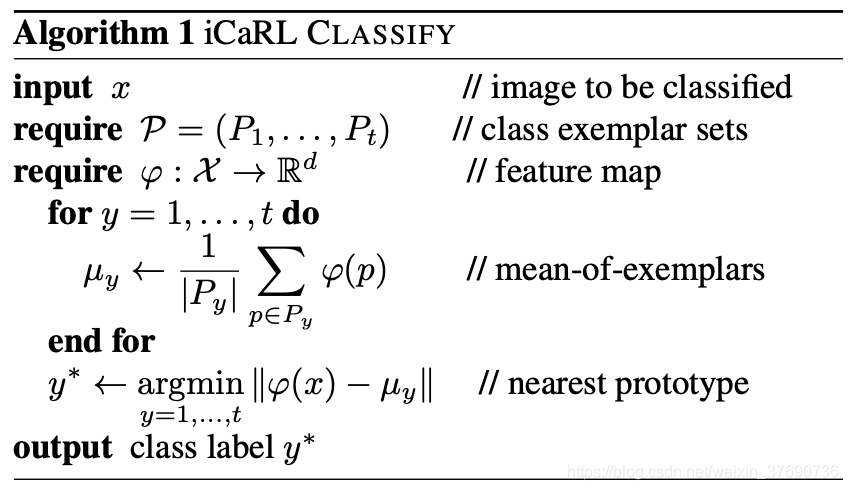
x是輸入資料,P是代表性樣本集合,t是樣本種類的總數,求解當前exemplar中,每個樣本種類的均值Uy,比較輸入資料與哪個樣本種類的均值Uy差值最小(最接近),即把輸入資料分為該樣本型別,
在增量程序中,執行以下演算法:

增量的訓練程序中使用舊知識的代表性樣本集合P,輸入資料Xs...Xt及當前模型的引數,三者共同更新當前模型的引數,
接下來,對exemplar set進行更新,因記憶體有效,該集合需要洗掉部分舊知識,以添加新知識進入集合,
對于更新操作,分為Reduce和Construct兩個操作,偽代碼分別如下:


其中,進出集合的規則是按每個樣本離該樣本種類均值的遠近,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/208960.html
標籤:其他
上一篇:PyTorch Mobile在端側可堪大用?能否與TensorFlow Lite一較高下
下一篇:python3.9下錯誤,pip安裝matplotlib卡在Building wheel for matplotlib (setup.py)..不動的原因與解決