作者|VETRIVEL_PS
編譯|Flin
來源|analyticsvidhya
總覽
-
本文是我的第一篇Analytics Vidhya的博客文章的第二部分,該文章是進入機器學習黑客馬拉松的前10%的終極入門者指南,
-
如果你遵循本文列出的這些簡單步驟,那么贏得黑客馬拉松的分類問題就比較簡單
-
始終保持不斷的學習,以高度的一致性進行實驗,并遵循你的直覺和你隨著時間積累的領域知識
-
從幾個月前在Hackathons作為初學者開始,我最近成為了Kaggle專家,并且是 Vidhya 的JanataHack Hackathon系列分析的前5名貢獻者之一,
-
我在這里分享我的知識,并指導初學者使用Binary分類中的分類用例進行頂級黑客競賽

讓我們深入研究二元分類–來自Analytics Vidhya的JanataHack Hackathon系列的保險交叉銷售用例,并親自進行實驗
鏈接到交叉銷售黑客馬拉松!- https://datahack.analyticsvidhya.com/contest/janatahack-cross-sell-prediction/#ProblemStatement
我們的客戶是一家為客戶提供健康保險的保險公司,現在他們需要我們的幫助來構建模型,以預測過去一年的保單持有人(客戶)是否也會對公司提供的車輛保險感興趣,
保險單是公司承諾為特定的損失,損害,疾病或死亡提供賠償保證,以換取指定的保險費的一種安排,保費是客戶需要定期向保險公司支付此保證金的金額,
例如,我們每年可以為200000盧比的健康保險支付5000盧比的保險費,這樣,如果我們在那一年生病并需要住院治療,保險公司將承擔最高200000盧比的住院費用,現在,如果我們想知道,當公司只收取5000盧比的保險費時,該如何承擔如此高的住院費用,那么,概率的概念就出現了,
例如,像我們一樣,每年可能有100名客戶支付5000盧比的保險費,但只有少數人(比如2-3人)會在當年住院,這樣,每個人都會分擔其他人的風險,
就像醫療保險一樣,有些車輛保險每年需要客戶向保險提供商公司支付一定金額的保險費,這樣,如果車輛不幸發生意外,保險提供商公司將提供賠償(稱為“投保”),
建立模型來預測客戶是否會對車輛保險感興趣對公司非常有幫助,因為它隨后可以相應地計劃其溝通策略,以覆寫這些客戶并優化其業務模型和收入,
分享我的資料科學黑客馬拉松方法——如何在20,000多個資料愛好者中達到前10%
在第1部分中,我們學習可以重復,優化和改進的10個步驟,這是幫助你快速入門的良好基礎,
現在你已經開始練習,讓我們嘗試保險用例來測驗我們的技能,放心,你將在幾個星期的練習中很好地應對任何分類黑客馬拉松(帶有表格資料),希望你熱情,好奇,并通過黑客競賽繼續這一資料科學之旅!
學習,練習和分類黑客馬拉松的10個簡單步驟
1. 理解問題陳述并匯入包和資料集
2. 執行EDA(探索性資料分析)——了解資料集,探索訓練和測驗資料,并了解每個列/特征表示什么,檢查資料集中目標列是否不平衡
3. 從訓練資料檢查重復的行
4. 填充/插補缺失值-連續-平均值/中值/任何特定值|分類-其他/正向填充/回填
5. 特征工程–特征選擇–選擇最重要的現有特征| 特征創建或封裝–從現有特征創建新特征
6. 將訓練資料拆分為特征(獨立變數)| 目標(因變數)
7. 資料編碼–目標編碼,獨熱編碼|資料縮放–MinMaxScaler,StandardScaler,RobustScaler
8. 為二進制分類問題創建基線機器學習模型
9. 結合平均值使用K折交叉驗證改進評估指標“ ROC_AUC”并預測目標“Response”
10. 提交結果,檢查排行榜并改進“ ROC_AUC”
在GitHub鏈接上查看PYTHON中完整的作業代碼以及可用于學習和練習的輸出,只要進行更改,它就會更新!
- https://github.com/Vetrivel-PS/AV-JanataHack-Insurance-Cross-Sell/blob/main/Latest-AV-Cross-Sell-Post-Hackathon-Analysis-3-ML-Models-in-GPU.ipynb
1. 了解問題陳述并匯入包和資料集
資料集說明
| 變數 | 說明 |
| id | 客戶的唯一ID |
| Gender | 客戶性別 |
| Age | 客戶年齡 |
| Driving_License | 0:客戶沒有駕照 1:客戶已經有駕照 |
| Region_Code | 客戶所在地區的唯一代碼 |
| Previously_Insured | 1:客戶已經有車輛保險 0:客戶沒有車輛保險 |
| Vehicle_Age | 車齡 |
| Vehicle_Damage | 1:客戶過去曾損壞車輛 0:客戶過去未曾損壞車輛, |
| Annual_Premium | 客戶需要在當年支付的保費金額 |
| Policy_Sales_Channel | 與客戶聯系的渠道的匿名代碼,即不同的代理,通過郵件,通過電話,見面等 |
| Vintage | 客戶已與公司建立聯系的天數 |
| Response | 1:客戶感興趣 0:客戶不感興趣 |
現在,為了預測客戶是否會對車輛保險感興趣,我們獲得了有關人口統計資訊(性別,年齡,區域代碼型別),車輛(車輛年齡,損壞),保單(保險費,采購渠道)等資訊,
用于檢查所有Hackathon中機器學習模型性能差異的評估指標
在這里,我們將ROC_AUC作為評估指標,
受試者作業特征曲線(ROC)是用于二元分類問題的評價度量,這是一條概率曲線,繪制了各種閾值下的TPR(真陽性率)對FPR(假陽性率),并從本質上將“信號”與“噪聲”分開,所述的曲線下面積(AUC)是一個分類類別之間進行區分的能力的量度,并且被用作ROC曲線的總結,
AUC越高,模型在區分正類和負類方面的性能越好,
-
當AUC=1時,分類器能夠正確區分所有的正類點和負類點,然而,如果AUC為0,那么分類器將預測所有的陰性為陽性,所有的陽性為陰性,
-
當0.5 < AUC < 1時,分類器很有可能將正類別值與負類別值區分開,之所以如此,是因為與假陰性和假陽性相比,分類器能夠檢測更多數量的真陽性和真陰性,
-
當AUC = 0.5時,分類器無法區分正類別點和負類別點,這意味著分類器將為所有資料點預測隨機類別或常量類別,
-
交叉銷售:訓練資料包含3,81,109個示例,測驗資料包含1,27,037個示例,資料再次出現嚴重失衡——根據訓練資料,僅推薦12.2%(總計3,81,109名員工中的46,709名)晉升,
讓我們從匯入所需的Python包開始
# Import Required Python Packages
# Scientific and Data Manipulation Libraries
import numpy as np
import pandas as pd
# Data Viz & Regular Expression Libraries
import matplotlib.pyplot as plt
import seaborn as sns
# Scikit-Learn Pre-Processing Libraries
from sklearn.preprocessing import *
# Garbage Collection Libraries
import gc
# Boosting Algorithm Libraries
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
from lightgbm import LGBMClassifier
# Model Evaluation Metric & Cross Validation Libraries
from sklearn.metrics import roc_auc_score, auc, roc_curve
from sklearn.model_selection import StratifiedKFold, KFold
# Setting SEED to Reproduce Same Results even with "GPU"
seed_value = https://www.cnblogs.com/panchuangai/archive/2020/11/10/1994
import os
os.environ['PYTHONHASHSEED'} = str(seed_value)
import random
random.seed(seed_value)
import numpy as np
np.random.seed(seed_value)
SEED=seed_value
-
科學和資料處理 ——用于使用Numpy處理數字資料,使用Pandas處理表格資料,
-
資料可視化庫——Matplotlib和Seaborn用于可視化單個或多個變數,
-
資料預處理,機器學習和度量標準庫——用于通過使用評估度量標準(例如ROC_AUC分數)通過編碼,縮放和測量日期來預處理資料,
-
提升演算法– XGBoost,CatBoost和LightGBM基于樹的分類器模型用于二進制以及多類分類
-
設定SEED –用于將SEED設定為每次重現相同的結果
2. 執行EDA(探索性資料分析)–了解資料集
# Loading data from train, test and submission csv files
train = pd.read_csv('../input/avcrosssellhackathon/train.csv')
test = pd.read_csv('../input/avcrosssellhackathon/test.csv')
sub = pd.read_csv('../input/avcrosssellhackathon/sample_submission.csv')
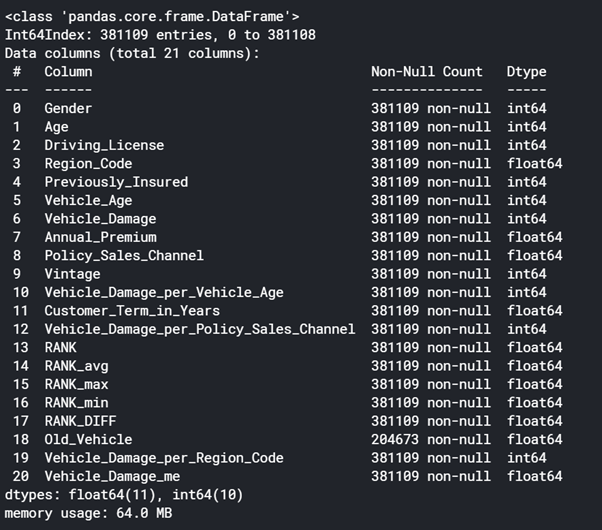
# Python Method 1 : Displays Data Information
def display_data_information(data, data_types, df)
data.info()
print("\n")
for VARIABLE in data_types :
data_type = data.select_dtypes(include=[ VARIABLE }).dtypes
if len(data_type) > 0 :
print(str(len(data_type))+" "+VARIABLE+" Features\n"+str(data_type)+"\n" )
# Display Data Information of "train" :
data_types = ["float32","float64","int32","int64","object","category","datetime64[ns}"}
display_data_information(train, data_types, "train")
# Display Data Information of "test" :
display_data_information(test, data_types, "test")
# Python Method 2 : Displays Data Head (Top Rows) and Tail (Bottom Rows) of the Dataframe (Table) :
def display_head_tail(data, head_rows, tail_rows)
display("Data Head & Tail :")
display(data.head(head_rows).append(data.tail(tail_rows)))
# return True
# Displays Data Head (Top Rows) and Tail (Bottom Rows) of the Dataframe (Table)
# Pass Dataframe as "train", No. of Rows in Head = 3 and No. of Rows in Tail = 2 :
display_head_tail(train, head_rows=3, tail_rows=2)
# Python Method 3 : Displays Data Description using Statistics :
def display_data_description(data, numeric_data_types, categorical_data_types)
print("Data Description :")
display(data.describe( include = numeric_data_types))
print("")
display(data.describe( include = categorical_data_types))
# Display Data Description of "train" :
display_data_description(train, data_types[0:4}, data_types[4:7})
# Display Data Description of "test" :
display_data_description(test, data_types[0:4}, data_types[4:7})
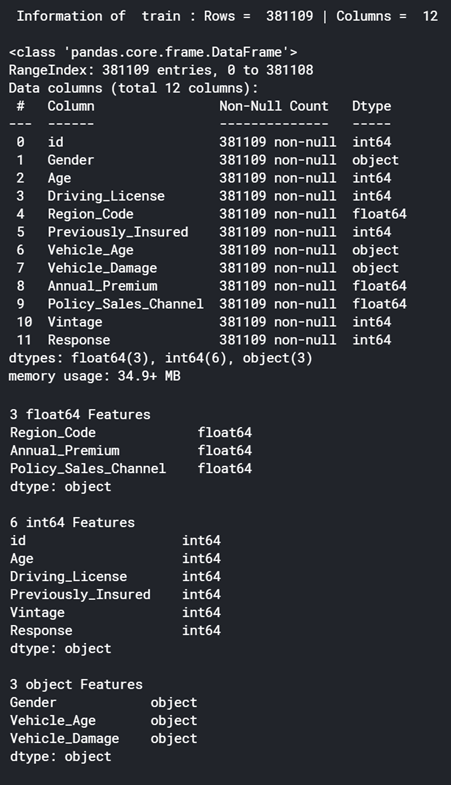
讀取CSV格式的資料檔案——pandas的read_csv方法,用于讀取csv檔案,并轉換成類似Data結構的表,稱為DataFrame,因此,為訓練,測驗和提交創建了3個資料幀,
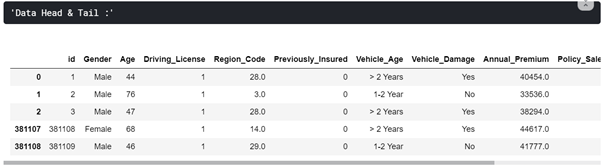
在資料上應用頭尾 –用于查看前3行和后2行以獲取資料概覽,
在資料上應用資訊–用于顯示有關資料幀的列,資料型別和記憶體使用情況的資訊,
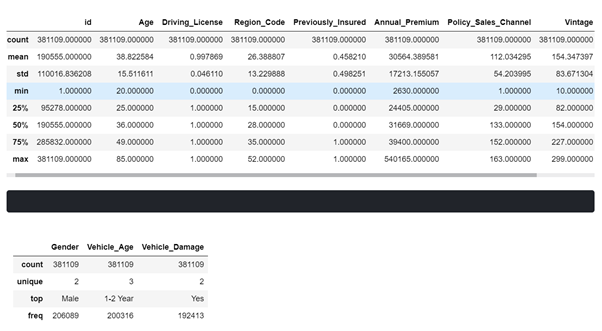
在資料上應用描述–用于在數字列上顯示描述統計資訊,例如計數,唯一性,均值,最小值,最大值等,
3. 從訓練資料檢查重復的行
# Removes Data Duplicates while Retaining the First one
def remove_duplicate(data)
data.drop_duplicates(keep="first", inplace=True)
return "Checked Duplicates
# Removes Duplicates from train data
remove_duplicate(train)
檢查訓練資料是否重復——通過保留第一行來洗掉重復的行,在訓練資料中找不到重復項,
4. 填充/插補缺失值-連續-平均值/中值/任何特定值|分類-其他/正向填充/回填
資料中沒有缺失值,

5. 特征工程
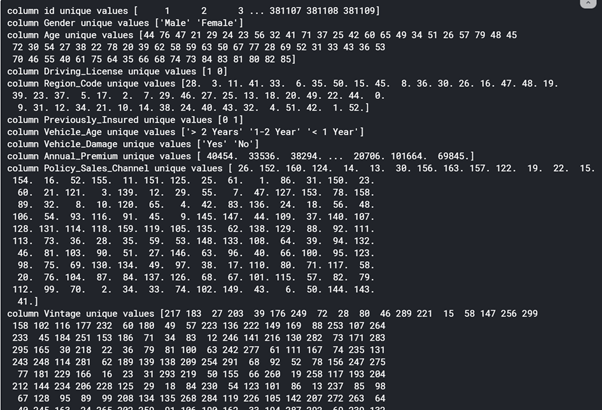
# Check train data for Values of each Column - Short Form
for i in train
print(f'column {i} unique values {train[i}.unique()})

# Binary Classification Problem - Target has ONLY 2 Categories
# Target - Response has 2 Values of Customers 1 & 0
# Combine train and test data into single DataFrame - combine_set
combine_set = pd.concat{[train,test},axis=0}
# converting object to int type :
combine_set['Vehicle_Age'}=combine_set['Vehicle_Age'}.replacee({'< 1 Year':0,'1-2 Year':1,'> 2 Years':2})
combine_set['Gender'}=combine_set['Gender'}.replacee({'Male':1,'Female':0})
combine_set['Vehicle_Damage'}=combine_set['Vehicle_Damage'}.replacee({'Yes':1,'No':0})
sns.heatmap(combine_set.corr())
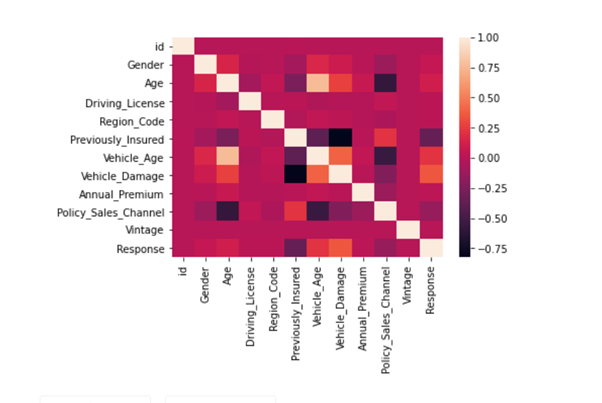
# HOLD - CV - 0.8589 - BEST EVER
combine_set['Vehicle_Damage_per_Vehicle_Age'} = combine_set.groupby(['Region_Code,Age'})['Vehicle_Damage'}.transform('sum'
# Score - 0.858657 (This Feature + Removed Scale_Pos_weight in LGBM) | Rank - 20
combine_set['Customer_Term_in_Years'} = combine_set['Vintage'} / 365
# combine_set['Customer_Term'} = (combine_set['Vintage'} / 365).astype('str')
# Score - 0.85855 | Rank - 20
combine_set['Vehicle_Damage_per_Policy_Sales_Channel'} = combine_set.groupby(['Region_Code,Policy_Sales_Channel'})['Vehicle_Damage'}.transform('sum')
# Score - 0.858527 | Rank - 22
combine_set['Vehicle_Damage_per_Vehicle_Age'} = combine_set.groupby(['Region_Code,Vehicle_Age'})['Vehicle_Damage'}.transform('sum')
# Score - 0.858510 | Rank - 23
combine_set["RANK"} = combine_set.groupby("id")['id'}.rank(method="first", ascending=True)
combine_set["RANK_avg"} = combine_set.groupby("id")['id'}.rank(method="average", ascending=True)
combine_set["RANK_max"} = combine_set.groupby("id")['id'}.rank(method="max", ascending=True)
combine_set["RANK_min"} = combine_set.groupby("id")['id'}.rank(method="min", ascending=True)
combine_set["RANK_DIFF"} = combine_set['RANK_max'} - combine_set['RANK_min'}
# Score - 0.85838 | Rank - 15
combine_set['Vehicle_Damage_per_Vehicle_Age'} = combine_set.groupby([Region_Code})['Vehicle_Damage'}.transform('sum')
# Data is left Skewed as we can see from below distplot
sns.distplot(combine_set['Annual_Premium'})
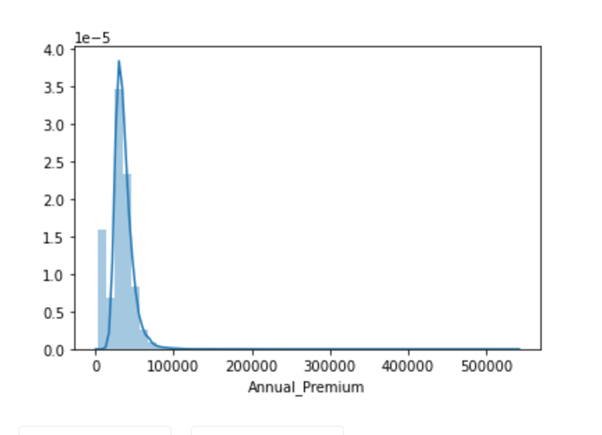
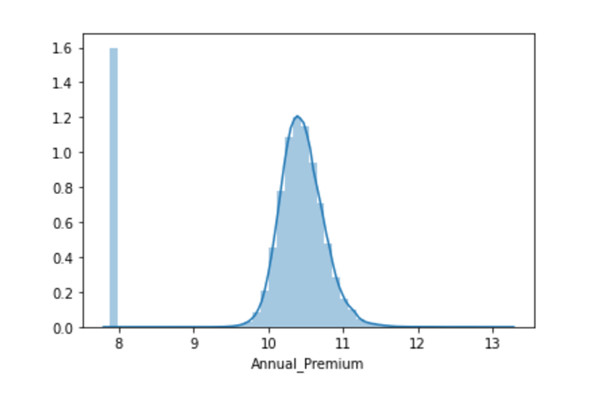
combine_set['Annual_Premium'} = np.log(combine_set['Annual_Premium'})
sns.distplot(combine_set['Annual_Premium'})
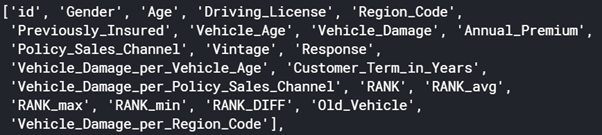
# Getting back Train and Test after Preprocessing :
train=combine_set[combine_set['Response'}.isnull()==False}
test=combine_set[combine_set['Response'}.isnull()==True}.drop(['Response'},axis=1)
train.columns
6. 將訓練資料拆分為特征(獨立變數)| 目標(因變數)
# Split the Train data into predictors and target :
predictor_train = train.drop(['Response','id'],axis=1)
target_train = train['Response']
predictor_train.head()
# Get the Test data by dropping 'id' :
predictor_test = test.drop(['id'],axis=1)
7. 資料編碼–目標編碼
def add_noise(series, noise_level):
return series * (1 + noise_level * np.random.randn(len(series)))
def target_encode(trn_series=None,
tst_series=None,
target=None,
min_samples_leaf=1,
smoothing=1,
noise_level=0):
"""
Smoothing is computed like in the following paper by Daniele Micci-Barreca
https://kaggle2.blob.core.windows.net/forum-message-attachments/225952/7441/high%20cardinality%20categoricals.pdf
trn_series : training categorical feature as a pd.Series
tst_series : test categorical feature as a pd.Series
target : target data as a pd.Series
min_samples_leaf (int) : minimum samples to take category average into account
smoothing (int) : smoothing effect to balance categorical average vs prior
"""
assert len(trn_series) == len(target)
assert trn_series.name == tst_series.name
temp = pd.concat([trn_series, target], axis=1)
# Compute target mean
averages = temp.groupby(by=trn_series.name)[target.name].agg(["mean", "count"])
# Compute smoothing
smoothing = 1 / (1 + np.exp(-(averages["count"] - min_samples_leaf) / smoothing))
# Apply average function to all target data
prior = target.mean()
# The bigger the count the less full_avg is taken into account
averages[target.name] = prior * (1 - smoothing) + averages["mean"] * smoothing
averages.drop(["mean", "count"], axis=1, inplace=True)
# Apply averages to trn and tst series
ft_trn_series = pd.merge(
trn_series.to_frame(trn_series.name),
averages.reset_index().rename(columns={'index': target.name, target.name: 'average'}),
on=trn_series.name,
how='left')['average'].rename(trn_series.name + '_mean').fillna(prior)
# pd.merge does not keep the index so restore it
ft_trn_series.index = trn_series.index
ft_tst_series = pd.merge(
tst_series.to_frame(tst_series.name),
averages.reset_index().rename(columns={'index': target.name, target.name: 'average'}),
on=tst_series.name,
how='left')['average'].rename(trn_series.name + '_mean').fillna(prior)
# pd.merge does not keep the index so restore it
ft_tst_series.index = tst_series.index
return add_noise(ft_trn_series, noise_level), add_noise(ft_tst_series, noise_level)
# Score - 0.85857 | Rank -
tr_g, te_g = target_encode(predictor_train["Vehicle_Damage"],
predictor_test["Vehicle_Damage"],
target= predictor_train["Response"],
min_samples_leaf=200,
smoothing=20,
noise_level=0.02)
predictor_train['Vehicle_Damage_me']=tr_g
predictor_test['Vehicle_Damage_me']=te_g
8. 為二進制分類問題創建基線機器學習模型
# Baseline Model Without Hyperparameters :
Classifiers = {'0.XGBoost' : XGBClassifier(),
'1.CatBoost' : CatBoostClassifier(),
'2.LightGBM' : LGBMClassifier()
}
# Fine Tuned Model With-Hyperparameters :
Classifiers = {'0.XGBoost' : XGBClassifier(eval_metric='auc',
# GPU PARAMETERS #
tree_method='gpu_hist',
gpu_id=0,
# GPU PARAMETERS #
random_state=294,
learning_rate=0.15,
max_depth=4,
n_estimators=494,
objective='binary:logistic'),
'1.CatBoost' : CatBoostClassifier(eval_metric='AUC',
# GPU PARAMETERS #
task_type='GPU',
devices="0",
# GPU PARAMETERS #
learning_rate=0.15,
n_estimators=494,
max_depth=7,
# scale_pos_weight=2),
'2.LightGBM' : LGBMClassifier(metric = 'auc',
# GPU PARAMETERS #
device = "gpu",
gpu_device_id =0,
max_bin = 63,
gpu_platform_id=1,
# GPU PARAMETERS #
n_estimators=50000,
bagging_fraction=0.95,
subsample_freq = 2,
objective ="binary",
min_samples_leaf= 2,
importance_type = "gain",
verbosity = -1,
random_state=294,
num_leaves = 300,
boosting_type = 'gbdt',
learning_rate=0.15,
max_depth=4,
# scale_pos_weight=2, # Score - 0.85865 | Rank - 18
n_jobs=-1)
}
9. 結合平均值使用K折交叉驗證改進評估指標“ ROC_AUC”并預測目標“Response”
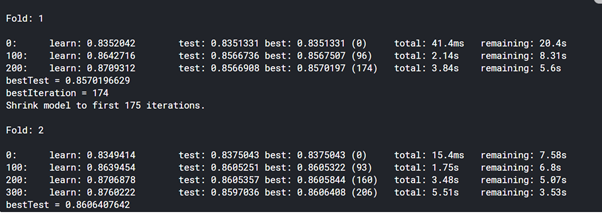
# LightGBM Model
kf=KFold(n_splits=10,shuffle=True)
preds_1 = list()
y_pred_1 = []
rocauc_score = []
for i,(train_idx,val_idx) in enumerate(kf.split(predictor_train)):
X_train, y_train = predictor_train.iloc[train_idx,:], target_train.iloc[train_idx]
X_val, y_val = predictor_train.iloc[val_idx, :], target_train.iloc[val_idx]
print('\nFold: {}\n'.format(i+1))
lg= LGBMClassifier( metric = 'auc',
# GPU PARAMETERS #
device = "gpu",
gpu_device_id =0,
max_bin = 63,
gpu_platform_id=1,
# GPU PARAMETERS #
n_estimators=50000,
bagging_fraction=0.95,
subsample_freq = 2,
objective ="binary",
min_samples_leaf= 2,
importance_type = "gain",
verbosity = -1,
random_state=294,
num_leaves = 300,
boosting_type = 'gbdt',
learning_rate=0.15,
max_depth=4,
# scale_pos_weight=2, # Score - 0.85865 | Rank - 18
n_jobs=-1
)
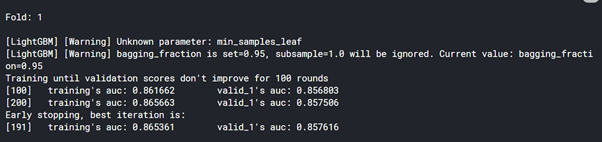
lg.fit(X_train, y_train
,eval_set=[(X_train, y_train),(X_val, y_val)]
,early_stopping_rounds=100
,verbose=100
)
roc_auc = roc_auc_score(y_val,lg.predict_proba(X_val)[:, 1])
rocauc_score.append(roc_auc)
preds_1.append(lg.predict_proba(predictor_test [predictor_test.columns])[:, 1])
y_pred_final_1 = np.mean(preds_1,axis=0)
sub['Response']=y_pred_final_1
Blend_model_1 = sub.copy()
print('ROC_AUC - CV Score: {}'.format((sum(rocauc_score)/10)),'\n')
print("Score : ",rocauc_score)

# Download and Show Submission File :
display("sample_submmission",sub)
sub_file_name_1 = "S1. LGBM_GPU_TargetEnc_Vehicle_Damage_me_1994SEED_NoScaler.csv"
sub.to_csv(sub_file_name_1,index=False)
sub.head(5)
# Catboost Model
kf=KFold(n_splits=10,shuffle=True)
preds_2 = list()
y_pred_2 = []
rocauc_score = []
for i,(train_idx,val_idx) in enumerate(kf.split(predictor_train)):
X_train, y_train = predictor_train.iloc[train_idx,:], target_train.iloc[train_idx]
X_val, y_val = predictor_train.iloc[val_idx, :], target_train.iloc[val_idx]
print('\nFold: {}\n'.format(i+1))
cb = CatBoostClassifier( eval_metric='AUC',
# GPU PARAMETERS #
task_type='GPU',
devices="0",
# GPU PARAMETERS #
learning_rate=0.15,
n_estimators=494,
max_depth=7,
# scale_pos_weight=2
)
cb.fit(X_train, y_train
,eval_set=[(X_val, y_val)]
,early_stopping_rounds=100
,verbose=100
)
roc_auc = roc_auc_score(y_val,cb.predict_proba(X_val)[:, 1])
rocauc_score.append(roc_auc)
preds_2.append(cb.predict_proba(predictor_test [predictor_test.columns])[:, 1])
y_pred_final_2 = np.mean(preds_2,axis=0)
sub['Response']=y_pred_final_2
print('ROC_AUC - CV Score: {}'.format((sum(rocauc_score)/10)),'\n')
print("Score : ",rocauc_score)

# Download and Show Submission File :
display("sample_submmission",sub)
sub_file_name_2 = "S2. CB_GPU_TargetEnc_Vehicle_Damage_me_1994SEED_LGBM_NoScaler_MyStyle.csv"
sub.to_csv(sub_file_name_2,index=False)
Blend_model_2 = sub.copy()
sub.head(5)
# XGBOOST Model
kf=KFold(n_splits=10,shuffle=True)
preds_3 = list()
y_pred_3 = []
rocauc_score = []
for i,(train_idx,val_idx) in enumerate(kf.split(predictor_train)):
X_train, y_train = predictor_train.iloc[train_idx,:], target_train.iloc[train_idx]
X_val, y_val = predictor_train.iloc[val_idx, :], target_train.iloc[val_idx]
print('\nFold: {}\n'.format(i+1))
xg=XGBClassifier( eval_metric='auc',
# GPU PARAMETERS #
tree_method='gpu_hist',
gpu_id=0,
# GPU PARAMETERS #
random_state=294,
learning_rate=0.15,
max_depth=4,
n_estimators=494,
objective='binary:logistic'
)
xg.fit(X_train, y_train
,eval_set=[(X_train, y_train),(X_val, y_val)]
,early_stopping_rounds=100
,verbose=100
)
roc_auc = roc_auc_score(y_val,xg.predict_proba(X_val)[:, 1])
rocauc_score.append(roc_auc)
preds_3.append(xg.predict_proba(predictor_test [predictor_test.columns])[:, 1])
y_pred_final_3 = np.mean(preds_3,axis=0)
sub['Response']=y_pred_final_3
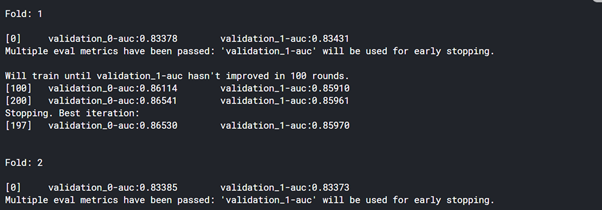
print('ROC_AUC - CV Score: {}'.format((sum(rocauc_score)/10)),'\n')
print("Score : ",rocauc_score)

# Download and Show Submission File :
display("sample_submmission",sub)
sub_file_name_3 = "S3. XGB_GPU_TargetEnc_Vehicle_Damage_me_1994SEED_LGBM_NoScaler.csv"
sub.to_csv(sub_file_name_3,index=False)
Blend_model_3 = sub.copy()
sub.head(5)
10. 提交結果,檢查排行榜并改進“ ROC_AUC”
one = Blend_model_2['id'].copy()
Blend_model_1.drop("id", axis=1, inplace=True)
Blend_model_2.drop("id", axis=1, inplace=True)
Blend_model_3.drop("id", axis=1, inplace=True)
Blend = (Blend_model_1 + Blend_model_2 + Blend_model_3)/3
id_df = pd.DataFrame(one, columns=['id'])
id_df.info()
Blend = pd.concat([ id_df,Blend], axis=1)
Blend.info()
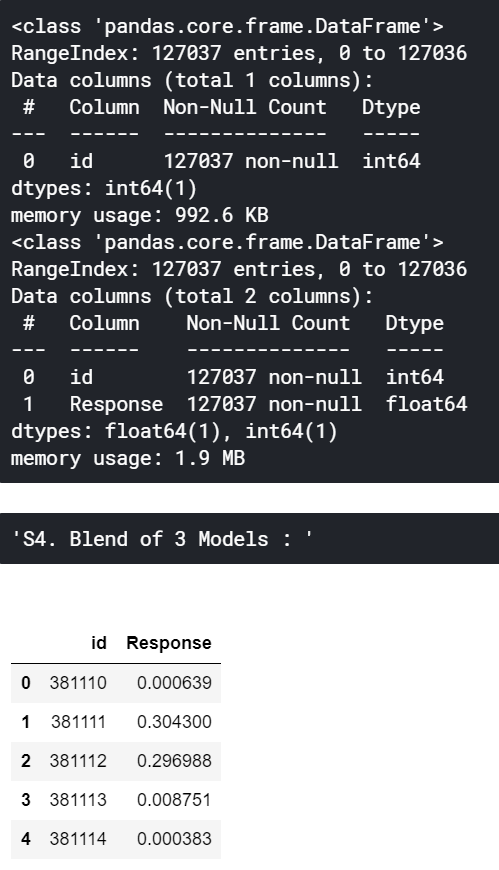
Blend.to_csv('S4. Blend of 3 Models - LGBM_CB_XGB.csv',index=False)
display("S4. Blend of 3 Models : ",Blend.head())
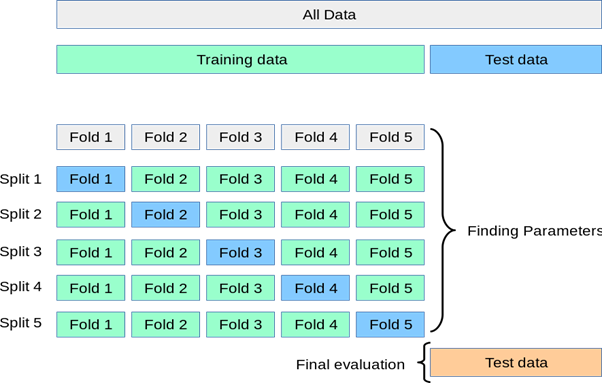
k折交叉驗證
交叉驗證是一種重采樣程序,用于在有限的資料樣本上評估機器學習模型,該程序有一個名為k的引數,它表示給定資料樣本要分成的組數,因此,這個程序通常被稱為k折交叉驗證,
提前停止
-
在機器學習中,提前停止是一種正則化形式,用于在使用迭代方法(例如梯度下降)訓練學習者時避免過擬合,
-
提前停止規則提供了關于學習者開始過擬合之前可以運行多少次迭代的指導,
-
檔案- https://scikit-learn.org/stable/auto_examples/ensemble/plot_gradient_boosting_early_stopping.html
如何使GPU上的3種機器學習模型運行得更快
- LIGHTGBM中的GPU引數
- https://lightgbm.readthedocs.io/en/latest/GPU-Performance.html
要使用LightGBM GPU模型:必須啟用“ Internet” –運行以下所有代碼:
# 保持Internet處于“打開”狀態,該狀態位于Kaggle內核的右側->“設定”面板中
# Cell 1:
!rm -r /opt/conda/lib/python3.6/site-packages/lightgbm
!git clone –recursive https://github.com/Microsoft/LightGBM
# Cell 2:
!apt-get install -y -qq libboost-all-dev
# Cell 3:
%% bash
cd LightGBM
rm -r build
mkdir build
cd build
cmake -DUSE_GPU=1 -DOpenCL_LIBRARY=/usr/local/cuda/lib64/libOpenCL.so -DOpenCL_INCLUDE_DIR=/usr/local/cuda/include/ ..
make -j$(nproc)
# Cell 4:
!cd LightGBM/python-package/;python3 setup.py install –precompile
# Cell 5:
!mkdir -p /etc/OpenCL/vendors && echo “libnvidia-opencl.so.1” > /etc/OpenCL/vendors/nvidia.icd
!rm -r LightGBM
-
device = “gpu”
-
gpu_device_id =0
-
max_bin = 63
-
gpu_platform_id=1
如何在GPU上實作良好的速度
-
你想運行一些經過我們驗證且具有良好加速性能的資料集(包括Higgs, epsilon, Bosch等),以確保設定正確,如果你有多個GPU,請確保將gpu_platform_id和gpu_device_id設定為使用所需的GPU,還要確保你的系統處于空閑狀態(尤其是在使用共享計算機時),以進行準確性性能測量,
-
GPU在大規模和密集資料集上表現最佳,如果資料集太小,則在GPU上進行計算效率不高,因為資料傳輸開銷可能很大,如果你具有分類功能,請使用categorical_column選項并將其直接輸入到LightGBM中,不要將它們轉換為獨熱變數,
-
為了更好地利用GPU,建議使用較少數量的bin,建議設定max_bin = 63,因為它通常不會明顯影響大型資料集上的訓練精度,但是GPU訓練比使用默認bin大小255明顯快得多,對于某些資料集,即使使用15個bin也就足夠了(max_bin = 15 ); 使用15個bin將最大化GPU性能,確保檢查運行日志并驗證是否使用了所需數量的bin,
-
盡可能嘗試使用單精度訓練(gpu_use_dp = false),因為大多數GPU(尤其是NVIDIA消費類GPU)的雙精度性能都很差,
2. CATBOOST中的GPU引數
-
task_type=’GPU’
-
devices=”0″
| 引數 | 描述 |
| CatBoost (fit) | task_type:用于訓練的處理單元型別,可能的值:(1)中央處理器(2)GPU |
| CatBoostClassifier(fit)
CatBoostRegressor(fit) | 設備:用于訓練的GPU設備的ID(索引從零開始), 格式: (1)一臺設備的 (2)<多個設備的 (3)<設備ID1>-<設備IDN>用于一系列設備(例如,devices ='0-3') |
3. XGBOOST中的GPU引數
-
tree_method ='gpu_hist'
-
gpu_id = 0
用法
將tree_method引數指定為以下演算法之一,
演演算法
| tree_method | 描述 |
| gpu_hist | 等效于XGBoost快速直方圖演算法,它快得多,并使用更少的記憶體,注意:在比Pascal架構更早的GPU上運行可能會非常緩慢, |
支持的引數
| 引數 | gpu_hist |
| subsample | ? |
| sampling_method | ? |
| colsample_bytree | ? |
| colsample_bylevel | ? |
| max_bin | ? |
| gamma | ? |
| gpu_id | ? |
| predictor | ? |
| grow_policy | ? |
| monotone_constraints | ? |
| interaction_constraints | ? |
| single_precision_histogram | ? |
黑客馬拉松交叉銷售總結
在這個AV交叉銷售黑客競賽中起作用的“10件事”:
-
2個最佳功能:Vehicle_Damage的目標編碼和按Region_Code分組的Vehicle_Damage總和——基于特征重要性-在CV(10折交叉驗證)和LB(公共排行榜)方面有了很大提升,
-
基于域的特征:舊車輛的頻率編碼——有所提高,LB得分:0.85838 |LB排名:15
-
Hackathon Solutions的排名功能:帶來了巨大的推動力,LB得分:0.858510 |LB排名:23
-
洗掉“id”欄:帶來了巨大的推動力,
-
基于域的特性:每輛車輛的車輛損壞、年齡和地區代碼——有一點提升,LB得分:0.858527 |LB排名:22
-
消除年度保險費的偏離值:帶來了巨大的推動力, LB得分: 0.85855 |LB排名: 20
-
基于領域的特征:每個地區的車輛損壞,代碼和政策,銷售渠道,基于特征重要性,有一點提升,LB得分:0.85856 |LB排名:20
-
用超引數和10-Fold CV對所有3個模型進行了調整,得出了一個穩健的策略和最好的結果,早期停止的輪數=50或100,Scale_pos_weight在這里沒有太大作用,
-
基于域的特性:客戶期限以年為單位,因為其他特性也以年為單位,保險回應將基于年數,LB得分:0.858657 |LB排名:18
-
綜合/混合所有3個最好的單獨模型:LightGBM、CatBoost和XGBoost,得到了最好的分數,
5件“不管用”的事
-
未處理的特征:[ 按年齡分組的車輛損壞總和,按以前投保的車輛損壞總和,按地區代碼分組的車輛損壞計數,按地區代碼分組的車輛最大損壞,按地區代碼分組的最小車輛損壞,按老舊車輛的頻率編碼,車輛年齡的頻率編碼,每月EMI=年度保險費/12,按保險單分組的車輛損壞總額,按車輛年齡分組的車輛損壞總額,按駕駛執照分組的車輛損壞總額 ]
-
洗掉與回應不相關的駕駛執照列
-
所有特征的獨熱編碼/虛擬編碼
-
與未標度資料相比,所有3種標度方法都不起作用——StandardScaler給出了其中最好的LB評分,StandardScaler –0.8581 | MinMaxScaler–0.8580 | RobustScaler–0.8444
-
洗掉基于訓練和測驗的Region_Code上的重復代碼根本不起作用
第2部分結束!(系列待續)
如果你覺得這篇文章有幫助,請與資料科學初學者分享,幫助他們開始黑客競賽,因為它解釋了許多步驟,如基于領域知識的特征工程、交叉驗證、提前停止、在GPU中運行3個機器學習模型,對多個模型進行平均組合,最后總結出“哪些技術有效,哪些無效–最后一步將幫助我們節省大量時間和精力,這將提高未來我們對黑客競賽的關注度,
非常感謝你的閱讀!
原文鏈接:https://www.analyticsvidhya.com/blog/2020/10/ultimate-beginners-guide-to-win-classification-hackathons-with-a-data-science-use-case/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/209907.html
標籤:其他