SQL的特點:是一個綜合的、功能極強并且簡潔容易學的語言,
SQL的功能:資料查詢、資料操縱、資料定義、資料控制,
資料庫系統的主要功能是通過資料庫支持的資料語言來實作,
菲關系模型(層次模型、網狀模型)的資料語言分為:
- DDL:資料定義語言(用來維護存盤資料的結構,例如:資料庫、表等),
- DML:資料操縱語言(對資料進行操作,也就是對資料表的內容進行操作),
- DSDL:資料存盤有關的描述語言,
SQL的特點:
- 綜合統一:集資料定義語言、資料操縱語言、資料控制語言的功能與一體,語言風格統一,可以獨立完成資料庫生命周期中的全部活動;在關系模型中物體與物體之間的聯系均用關系表示,這種資料結構的單一性帶來了資料運算子的統一性,
- 高度非程序化:只要提出“做什么”,不用指明“怎么做”,因此無須了解存取路徑,存取路徑的選擇以及SQL的操作程序由系統自動完成,
- 面向集合的操作方式:非關系資料模型采用的是面向記錄的操作方式,操作物件是一條記錄,但SQL采用集合操作方式,不僅操作物件、查找結果可以使元組的集合,而且一次插入、洗掉、更新操作的物件也可以是元組的集合,
- 以同一種語法結構提供多種使用方式:SQL既是獨立的語言,又是嵌入式語言,作為獨立語言,它能夠獨立的用于聯機互動的使用方式,用戶可以在終端鍵盤上直接敲入SQL命令對資料庫進行操作;作為嵌入式語言,SQL陳述句可以嵌入到高級語言(C,C++,Java)程式中,供程式員設計程式時使用,
- 語言簡潔、易學易用:SQL功能極強,語言十分簡潔,核心功能只用了9個動詞(資料查詢:SELECT;資料定義:CREATE、DROP、ALTER;資料操縱:INSERT、UPDATE、DELETE;資料控制:GRANT、REVOKE)
補充:
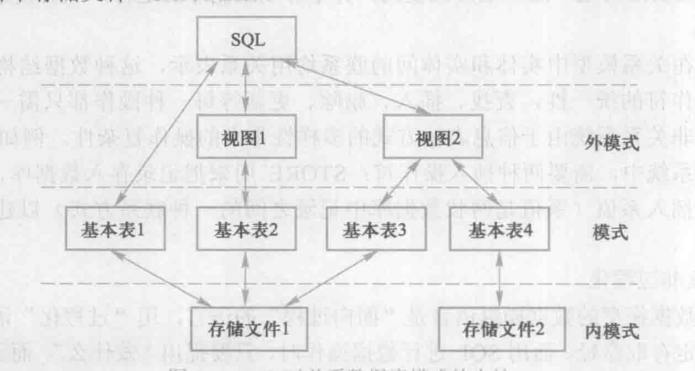
- 基本表和視圖一樣,都是關系,
- 基本表是本身獨立存在的表,在關系資料庫管理系統中一個關系對應一個基本表,
- 一個或多個基本表對應一個存盤檔案,一個表可以帶若干索引,這些索引存放在存盤檔案中
- 存盤檔案的邏輯結構組成了關系資料庫的內模式,存盤檔案的物理結構對最終用戶是隱蔽的,
- 視圖是從一個或多個基本表匯出來的,它本身不獨立存盤的資料庫中,所以視圖是一個虛表,
資料定義:
關系資料庫系統支持三級模式結構,其模式、外模式、內模式中的基本物件是模式、表、索引,因此SQL的資料定義包括模式定義、表定義、視圖和索引的定義,
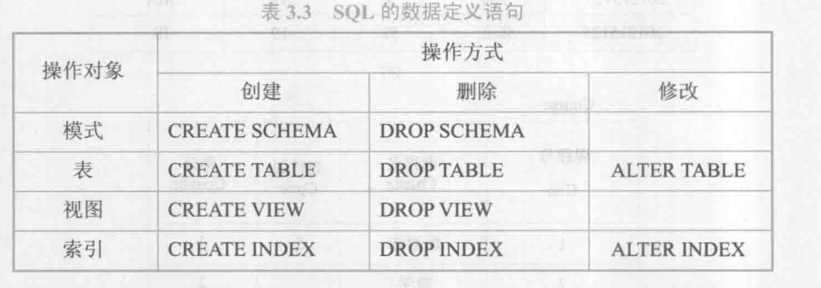
SQL標準不提供修改模式定義和修改視圖定義的操作,如果想修改這些物件,只能先將它們洗掉然年再重建,SQL標準也沒用提供索引相關的陳述句,
一個資料庫管理系統的實體中可以建多個資料庫,一個資料庫中可以建立多個模式,一個模式下通常包括多個表、視圖和索引等資料,
- 定義模式:
CREATE SCHEMA <模式名> AUTHORIZATION <用戶名>;
如果沒有指定<模式名>,那么<模式名>隱含為<用戶名>,要創建模式,呼叫該命令的用戶必須擁有資料庫管理員權限,或者獲得了資料庫管理員授予的CREATE SCHEMA的權限,
定義模式實際上定義了一個命名空間,在這個空間中可以進一步定義該模式包含的資料庫物件,例如基本表、視圖、索引等,
- 洗掉模式:
DROP SCHEMA <模式名> <CASCADE|RESTRICT>;
其中CASCADE和RESTRICT必須二選一,選擇了CASCADE(級聯),表示在洗掉模式的同時把該模式中所有的資料庫物件全部洗掉;選擇了RESTRICT(限制),表示如果該模式中已經定義了下屬的資料庫物件,則拒絕洗掉陳述句的執行,只有當該模式中沒有任何下屬的物件時才能執行,
- 定義基本表
創建了一個模式就建立了一個資料庫的命名空間,一個框架,
CREATE TABLE <表名> (<列名> <資料型別> [列級完整性約束條件]
,<列名> <資料型別> [列級完整性約束條件]
……
,[<表級完整性約束條件>]);
建表的同時可以定義與該表有關的完整性約束條件,這些完整性約束條件被存入系統的資料字典中,如果完整性約束條件涉及表中的多個屬性列,則必須定義在表級上,否則可以定義在列級也可以定義在表級,有主碼時要在主碼那一列定義完后面加上“PRIMARY KEY”,標識為主碼,如果有外碼和被參照表以及被參照列,在完整性約束條件定義完后加上相應標識,外碼“FOREIGN KEY”,被參照表“REFERENCES”,被參照列加上“()”就行,參照表和被參照表可以是同一個表,
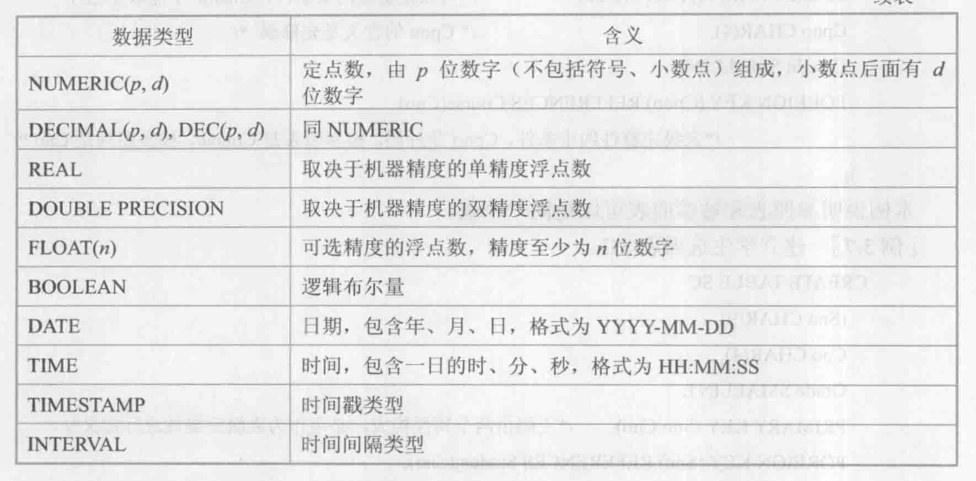
資料型別:

- 修改基本表
ALTER TABLE<表名>
[ADD [COLUMN] <新列名> <資料型別> [完整性約束]]
[ADD <表級完整性約束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT]]
[DROP CONSTRAINT<完整性約束> [CASCADE|RESTRICT]]
[ALTRE COLUMN <列名> <資料型別>];
其中<表名>是要修改的基本表,ADD字句用于增加新的列、新的列級完整性約束條件和新的表級完整性約束條件,DROP COLUMN字句用于洗掉表中的列,DROP CONSTRAINT字句用于洗掉指定的完整性約束條件,ALTER COLUMN 字句用于修改原有的列定義,包括修改列名和資料型別,
- 洗掉基本表
DROP TABLE <表名> [CASCADE|RESTRICT];
索引:
建立索引是加快查詢素的有效手段,
資料庫索引有多種型別,常見索引包括順序檔案上的索引、B+樹索引、散列索引、位圖索引等,索引雖然能加快資料庫查詢速度,但需要占用一定的存盤空間,當基本表跟新時,索引要進行相應的維護,這些都會增加資料庫的負擔,
一般來說,建立與洗掉索引由資料庫管理員或表的屬主,即建立表的人,負責完成,關系資料庫管理系統在執行查詢時會自動選擇合適的索引作為存取路徑,用戶不必也不能顯示地選擇索引,索引是關系資料庫管理系統的內部實作技術,屬于內模式的范疇,
- 建立索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>;
ON <表名>(<列名> [<次序>][,<列名>[<次序>]]……);
其中,<表名>是要建立索引的基本表的名字,索引可以建立在該表的一列或多列上,各列名之間用逗號隔開,每個<列名>后面還可以用<次序>指定索引值的排列次序,可選ASC(升序)或DESC(降序),默認值為ASC,
UNIQUE表明此索引的每一個索引值只對應唯一的資料記錄,CLUSTER表示要建立的索引是聚簇索引,
- 修改索引
ALTER INDEX <舊索引名> RENAME TO <新索引名>;
- 洗掉索引
索引一經建立就由系統使用和維護,不需用戶干預,建立索引是為了減少查詢操作的時間,但如果資料增、刪、改頻繁,系統會花費許多時間來維護,從而降低了查詢效率,這時可以洗掉一些不必要的索引,
DROP INDEX <索引名>;
洗掉索引時,系統會同時從資料字典中刪去有關該索引的描述,
資料字典
資料字典是關系資料庫管理系統內部的一組系統表,它記錄了資料庫中所有的定義資訊,包括關系模式定義、視圖定義、索引定義、完整性約束定義、各類用戶對資料庫的操作權限、統計資訊等,關系資料庫管理系統在執行SQL的資料定義陳述句時,實際上就是在更新資料字典表中的回應資訊,在進行查詢優化和查詢處理時,資料字典中的纖細是其重要依據,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/21180.html
標籤:其他
上一篇:初體驗小書匠
下一篇:糟糕的中文版龍書