文章目錄
- 一、正規文法和正規式
- 1、文法與自動機的關系
- 2、正規文法與正規式
- 3、正規式等價
- 4、正規式到正規文法
- 5、正規文法到正規式
- 二、自動機
- 1、DFA : 確定的有窮自動機
- 2、NFA : 不確定的有窮自動機
- 3、NFA確定化演算法
- 4、構造NFA N狀態K的子集的演算法
- 5、確定有窮自動機(DFA)化簡
- 6、DFA的最小化演算法
- 三、詞法分析
- 1、正規運算式與有限自動機的等價性
- 2、正規文法與有限自動機的等價性
- 3、詞法分析
一、正規文法和正規式
1、文法與自動機的關系

-
0型文法(短語結構文法):其能力相當于圖靈機,可以表征任何遞回可列舉集,而且任何0型語言都是遞回可列舉的,
-
1型文法(背景關系有關文法CSG):產生式的形式為 α 1 A α 2 → α 1 β α 2 α_1Aα_2→α_1βα_2 α1?Aα2?→α1?βα2?,即只有 A A A 出現在 α 1 α_1 α1? 和 α 2 α_2 α2? 的背景關系中時,才允許 β β β 取代 A A A ,其識別系統是線性有界自動機,
-
2型文法(背景關系無關文法CFG):產生式的形式為 A → β A→β A→β, β β β取代 A A A時與 A A A的背景關系無關,其識別系統是不確定的下推自動機,
-
3型文法(正規文法RG):產生的語言是有窮自動機(FA)所接受的集合,
2、正規文法與正規式
單詞符號結構的描述方法:
- 正規文法(3型文法)
- 正規式(正則運算式)
正規運算式(正則運算式)(regular expression)
是說明單詞模式(pattern)的一種重要的表示法(記號), 是定義正規集的數學工具,
在編譯中,用以描述單詞符號,
定義(正規式和它所表示的正規集):
設字母表為
∑
∑
∑,輔助字母表
∑
′
=
{
Φ
,
ε
,
∣
,
?
,
?
,
(
,
)
}
∑'=\{ Φ,ε,|,?,*,(,)\}
∑′={Φ,ε,∣,?,?,(,)}
- Φ Φ Φ 和 ε ε ε 都是 ∑ ∑ ∑ 上的正規式,它們所表示的正規集分別為 ε {ε} ε 和 { } \{\} {} ;
- 任何 a ∈ ∑ a∈∑ a∈∑, a a a 是 ∑ ∑ ∑ 上的一個正規式,它所表示的正規集為 a {a} a ;
- 假定 e 1 e_1 e1? 和 e 2 e_2 e2? 都是 ∑ ∑ ∑ 上的正規式,它們所表示的正規集分別為 L ( e 1 ) L(e_1) L(e1?) 和 L ( e 2 ) L(e_2) L(e2?) ,那么, ( e 1 ) (e_1) (e1?) , e 1 ∣ e 2 e_1| e_2 e1?∣e2?, e 1 ? e 2 e_1?e_2 e1??e2?, e ? e^* e? 也都是正規式,它們所表示的正規集分別為 L ( e 1 ) L(e_1) L(e1?), L ( e 1 ) ∪ L ( e 2 ) L(e_1)∪L(e_2) L(e1?)∪L(e2?), L ( e 1 ) L ( e 2 ) L(e_1)L(e_2) L(e1?)L(e2?) 和 ( L ( e 1 ) ) ? (L(e_1))^* (L(e1?))?,
- 僅由有限次使用上述三步驟而定義的運算式才是 ∑ ∑ ∑ 上的正規式,僅由這些正規式所表示的集合才是 ∑ ∑ ∑ 上的正規集,
正規式中的符號
- “ ∣ | ∣ ” 讀為“或”(也有使用“ + + + ”代替“ ∣ | ∣ ” 的);
- “ ? ? ? ” 讀為 “連接 ”;
- “ ? * ? ”讀為“閉包”(即任意有限次的自重復連接,
在不致混淆時,括號可省去,但規定算符的優先順序為“ ? * ? ”、“ ? ? ? ”、“ ∣ | ∣ ” ,連接符“ ? ? ? ”一般可省略不寫,“ ? * ? ”、“ ? ? ? ”和“ ∣ | ∣ ”都是左結合的,
 |  |
3、正規式等價
若兩個正規式 e 1 e_1 e1? 和 e 2 e_2 e2? 所表示的正規集相同,則說 e 1 e_1 e1? 和 e 2 e_2 e2? 等價,寫作 e 1 = e 2 e_1 = e_2 e1?=e2?
例如: e 1 = ( a ∣ b ) , e 2 = b ∣ a e_1= (a|b), e_2 = b|a e1?=(a∣b),e2?=b∣a
又如:
e
1
=
b
(
a
b
)
?
,
e
2
=
(
b
a
)
?
b
e_1= b(ab)^* , e_2 = (ba)^*b
e1?=b(ab)?,e2?=(ba)?b
e
1
=
(
a
∣
b
)
?
,
e
2
=
(
a
?
∣
b
?
)
?
e_1= (a|b)^* , e2 = (a^*|b^*)^*
e1?=(a∣b)?,e2=(a?∣b?)?
正規式等價變換規則:
設r,s,t為正規式,正規式服從的代數規律有:
- “或”服從交換律: r ∣ s = s ∣ r r|s=s|r r∣s=s∣r
- “或”的可結合律: r ∣ ( s ∣ t ) = ( r ∣ s ) ∣ t r|(s|t)=(r|s)|t r∣(s∣t)=(r∣s)∣t
- “連接”的可結合律: ( r s ) t = r ( s t ) (rs)t=r(st) (rs)t=r(st)
- 分配律: r ( s ∣ t ) = r s ∣ r t r(s|t)=rs|rt r(s∣t)=rs∣rt , ( s ∣ t ) r = s r ∣ t r (s|t)r=sr|tr (s∣t)r=sr∣tr
- 零一律(ε是“連接”的恒等元素): ε r = r εr=r εr=r , r ε = r rε=r rε=r
- “或”的抽取律: r ∣ r = r r|r=r r∣r=r , r ? = ε ∣ r ∣ r r ∣ … r^*=ε|r|rr|… r?=ε∣r∣rr∣…
4、正規式到正規文法

 |  |
5、正規文法到正規式
對 G = ( V N , V T , P , S ) G=(V_N,V_T,P,S) G=(VN?,VT?,P,S) ,存在一個 ∑ = V T ∑ =V_T ∑=VT? 上的正規式 r : L ( r ) = L ( G ) r : L(r)=L(G) r:L(r)=L(G)
- A → x B , B → y ≈ A = x y A→xB, B→y ≈ A=xy A→xB,B→y≈A=xy
- A → x A ∣ y ≈ A = x ? y A→xA|y ≈ A=x^*y A→xA∣y≈A=x?y
- A → x ∣ y ≈ A = x ∣ y A→x|y ≈ A=x|y A→x∣y≈A=x∣y

二、自動機
有窮自動機:
有窮自動機(有限自動機)作為一種識別裝置,它能準確地識別正規集,即識別正規文法所定義的語言和正規式所表示的集合,引入有窮自動機這個理論,正是為詞法分析程式的自動構造尋找特殊的方法和工具
有窮自動機分為兩類:
-
確定的有窮自動機(Deterministic Finite Automata) :DFA
-
不確定的有窮自動機(Nondeterministic Finite Automata) :NFA
1、DFA : 確定的有窮自動機
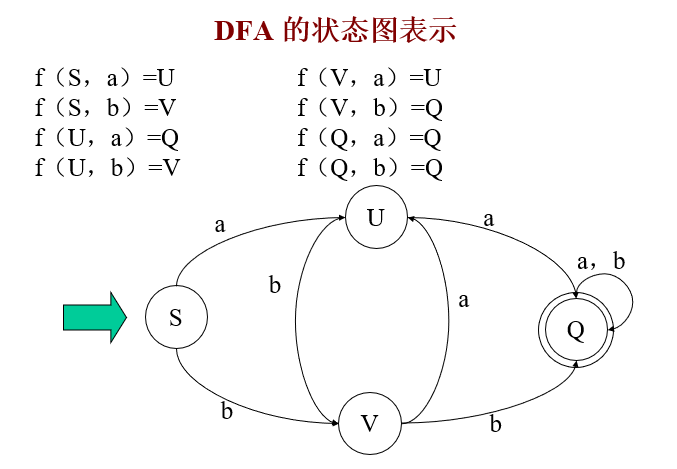
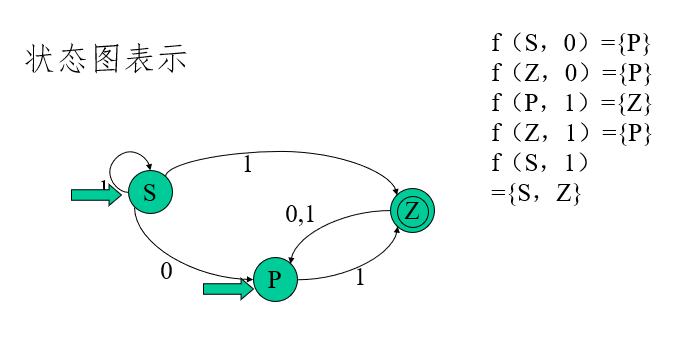
DFA定義:
一個確定的有窮自動機(DFA)M是一個五元組:M=(K,Σ,f,S,Z),其中:
-
K 是一個有窮集,它的每個元素稱為一個狀態;
-
Σ 是一個有窮字母表,它的每個元素稱為一個輸入符號,所以也稱Σ為輸入符號表;
-
f 是轉換函式,是在 K×Σ→K 上的映射,即,如 f(ki,a)=kj ,(ki∈K,kj∈K)就意味著,當前狀態為ki,輸入符為a時,將轉換為下一個狀態 kj ,我們把 kj 稱作 ki 的一個后繼狀態;
-
S∈K是唯一的一個初態;
-
Z?K是一個終態集,終態也稱可接受狀態或結束狀態,


|
|

|
|
∑*上的符號串 t 在DFA M上運行:
-
一個輸入符號串t,(將它表示成 Tt1 的形式,其中T∈∑,t1∈ ∑ * )在DFA M=(K,Σ,f,S,Z)上運行的定義為:
f(Q, Tt1)=f(f(Q,T),t1),其中Q∈K 擴充轉換函式 f 為 K×Σ * → K上的映射,且: f(ki,ε)= ki
∑ * 上的符號串 t 被 DFA M接受:
-
M=(K,Σ,f,S,Z)
若t∈ ∑ * ,f(S,t)=P,其中S為M的開始狀態,P ∈ Z,Z為終態集,則稱t為DFA M所接受(識別),
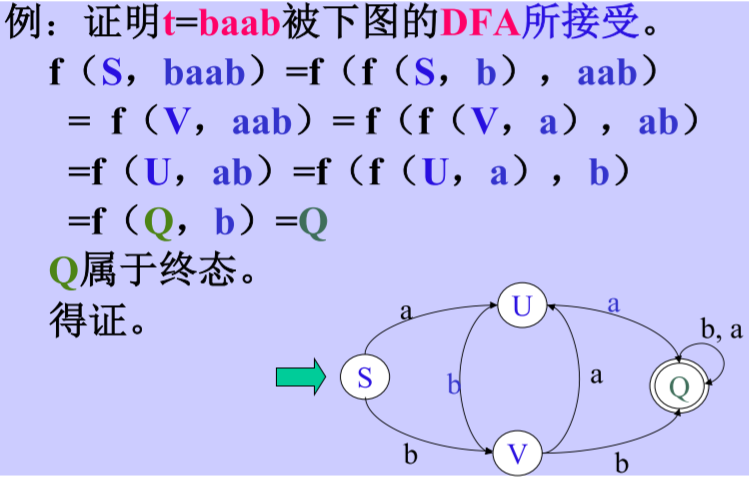
DFA M所能接受的符號串的全體記為L(M)
對于任何兩個有窮自動機M和M′,如果L(M)=L(M′),則稱M與M′是等價的
結論:
∑ 上一個符號串集 V?∑ * 是正規的,當且僅當存在一個 ∑ 上的確定有窮自動機M,使得 V=L(M)
DFA的確定性表現在轉換函式f:K×Σ→K是一個單值函式,也就是說,對任何狀態k∈K,和輸入符號a∈Σ,f(k,a)唯一地確定了下一個狀態
從狀態轉換圖來看,若字母表Σ含有n個輸入字符,那么任何一個狀態結點最多有n潭訓射出,而且每潭訓以一個不同的輸入字符標記
2、NFA : 不確定的有窮自動機
定義:
NFA M=(K,∑,f,S,Z),其中:
-
K為狀態的有窮非空集
-
∑為有窮輸入字母表
-
f為 K×∑* 到 K 的子集(2K)的一種映射
-
S?K 是初始狀態集
-
Z?K 為終止狀態集
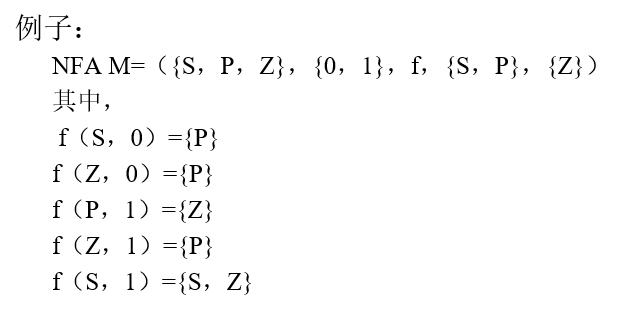
|
|
f為 K×∑* 到 K 的子集(2K)的一種映射
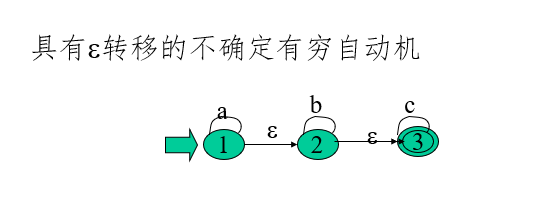
對任何一個具有 ε 轉移的不確定的有窮自動機NFA N,一定存在一個不具有 ε轉移的不確定的有窮自動機NFA M,使得L(M)=L(N)
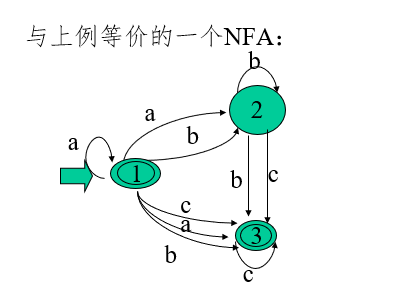
∑*上的符號串 t 在NFA M上運行:
- 一個輸入符號串t,(我們將它表示成Tt1的形式,其中T∈∑,t1∈ ∑*)在NFA M上運行的定義為:
f(Q,Tt1)=f(f(Q,T),t1) 其中Q∈K
∑*上的符號串t被NFA M接受:
-
若t ∈ ∑*,f(S0,t)=P,其中S0 ∈S,P ∈ Z,則稱
t為NFA M所接受(識別)
-
也可以這樣理解:
對于 Σ * 中的任何一個串 t,若存在一條從某一初態結到某一終態結的道路,且這條道路上所有弧的標記字依序連接成的串(不理采那些標記為 ε的弧)等于 t ,則稱 t 可為NFA M所識別(讀出或接受),
若M的某些結既是初態結又是終態結,或者存在一條從某個初態結到某個終態結的道路,其上所有弧的標記均為 ε,那么空字可為 M 所接受,
NFA M所能接受的符號串的全體記為L(M)
結論:
∑ 上一個符號串集V ? ∑ * 是正規的,當且僅當存在一個 ∑ 上的不確定的有窮自動機M,使得 V=L(M)
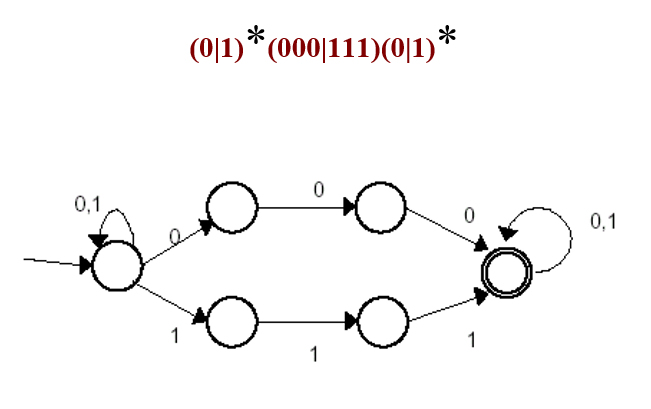
-
DFA是NFA的特例,對每個NFA N一定
存在一個DFA M, 使得 L(M)=L(N);
-
對每個NFA N存在著與之等價的DFA M
-
有一種演算法,可以將NFA轉換成接受同樣語言的DFA.這種演算法稱為子集法
-
與某一NFA等價的DFA不唯一
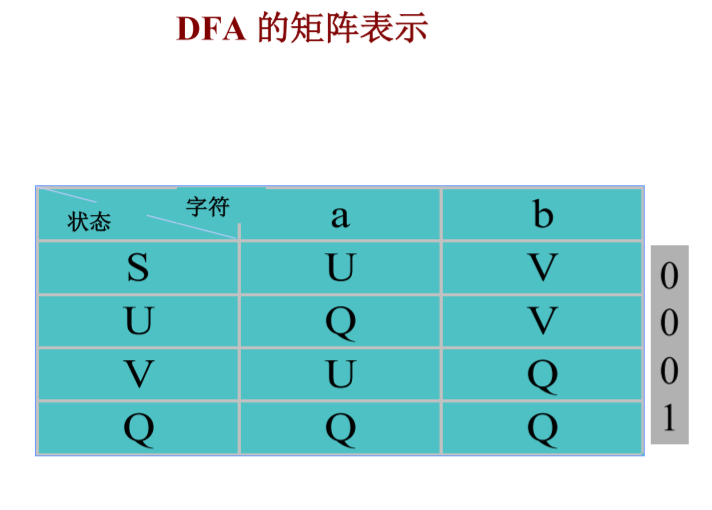
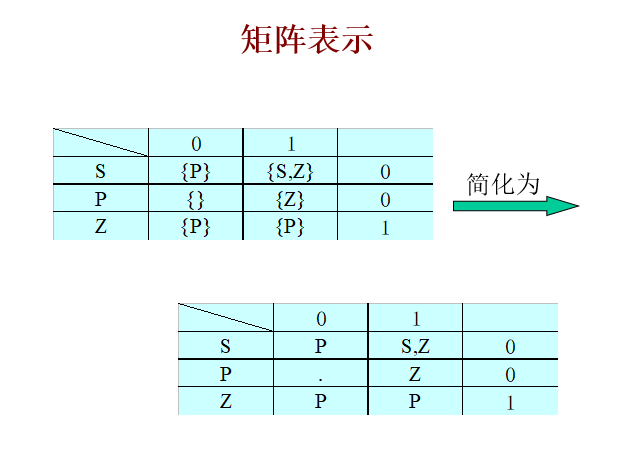
從NFA的矩陣表示中可以看出,表項通常是一狀態的集合,
而在DFA的矩陣表示中,表項是一個狀態,
NFA到相應的DFA的構造的基本思路是:
- DFA的每一個狀態對應NFA的一組狀態
DFA使用它的狀態去記錄在NFA讀入一個輸入符號后可能達到的所有狀態
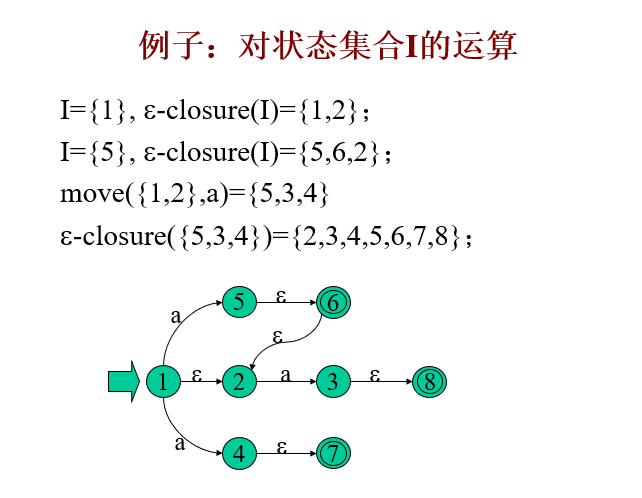
3、NFA確定化演算法
NFA N = (K, ∑, f, K0, Kt) , 按如下方法構造一個DFA M=(S, ∑, d, S0, St), 使得L(M)=L(N):
-
M 的狀態集 S 由K的一些子集組成,用 [S1 S2… Sj] 表示 S 的元素,其中S1 ,S2… Sj 是K的狀態,并且約定,狀態S1 ,S2… Sj 是按某種規則排列的,即對于子集 {S1, S2}={ S2, S1} 來說,S的狀態就是[S1S2]
-
M和N的輸入字母表是相同的,即為 ∑
-
轉換函式是這樣定義的:
d ( [ S 1 S 2 . . . S j ] , a ) = [ R 1 R 2 . . . R t ] d([S_1S_2...S_j], a) = [R_1R_2...R_t] d([S1?S2?...Sj?],a)=[R1?R2?...Rt?],其中
R 1 , R 2 , . . . , R t = ε ? c l o s u r e ( m o v e ( { S 1 , S 2 , … , S j } , a ) ) {R_1, R_2, ... , R_t}= ε-closure(move(\{S_1,S_2,…,S_j\},a)) R1?,R2?,...,Rt?=ε?closure(move({S1?,S2?,…,Sj?},a)) -
S 0 = ε ? c l o s u r e ( K 0 ) S_0=ε-closure(K_0) S0?=ε?closure(K0?)為 M 的開始狀態;
-
St={[Si Sk … Se] ,其中[Si Sk … Se]∈S 且 {Si, Sk, … , Se}∩ Kt ≠ Φ}

|
|
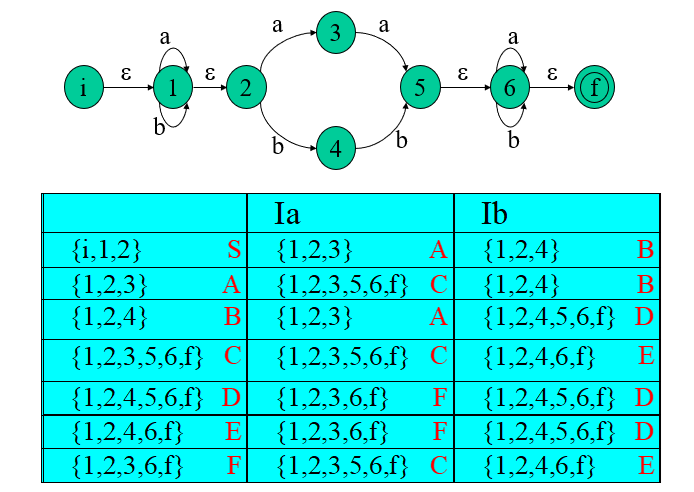
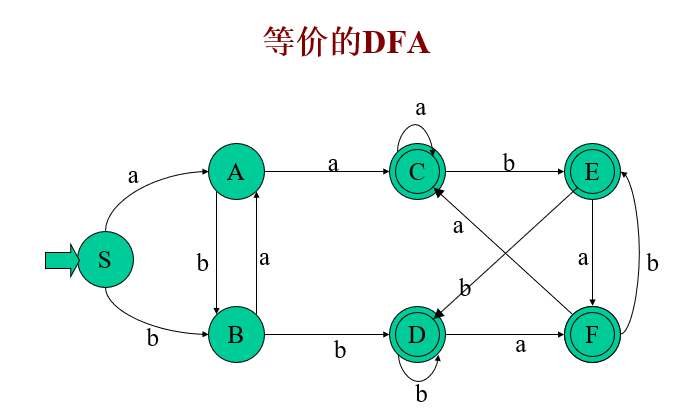
4、構造NFA N狀態K的子集的演算法
假定所構造的子集族為C,即C= (T1, T2,… TI),其中T1, T2,… TI為狀態K的子集,
- 開始,令e-closure(K0)為C中唯一成員,并且它是未被標記的,
while (C中存在尚未被標記的子集T)do {
標記T;
for 每個輸入字母a do {
U:= ε-closure(move(T,a));
if U不在C中 then
將U作為未標記的子集加在C中
}
}
5、確定有窮自動機(DFA)化簡
- 一個有窮自動機是化簡了的
<
=
>
<=>
<=>
它沒有多余狀態并且它的狀態中沒有兩個是互相等價的 - 一個有窮自動機可以通過消除多余狀態和合并等價狀態而轉換成一個最小的與之等價的有窮自動機
- 有窮自動機的多余狀態:
- 從自動機的開始狀態出發,任何輸入串也不能到達的那個狀態(S2)
- 從這個狀態沒有通路到達終態(S1)
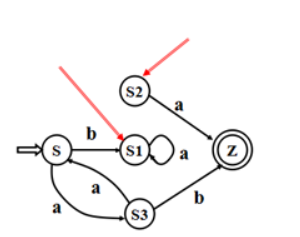
DFA最小化就是尋求最小狀態DFA
最小狀態DFA的含義:
- 沒有多余狀態(死狀態)
- 沒有兩個狀態是互相等價(不可區別)
兩個狀態s和t可區別:不滿足
- 兼容性——同是終態或同是非終態
- 傳播性——從s出發讀入某個 a(a∈∑) 和從 t 出發讀入某個 a 到達的狀態等價
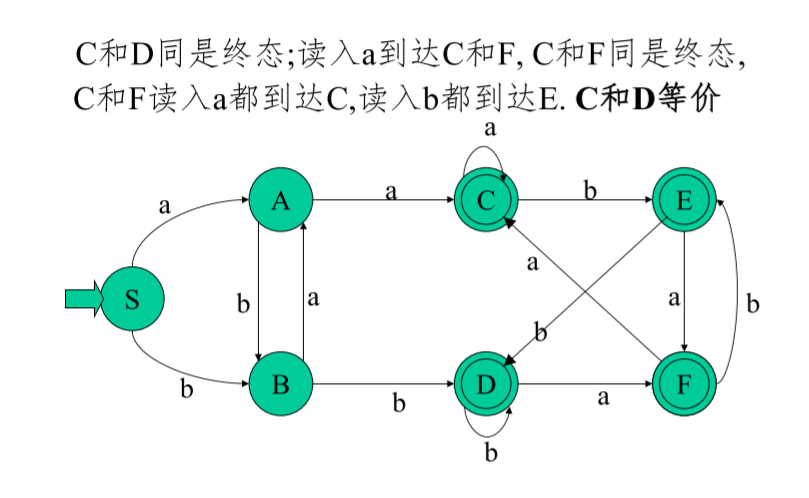
最小狀態DFA
對于一個DFA M =(K,∑, f, k0, kt),存在一個最小狀態DFA M’ =(K’,∑, f’, k0’, kt’),使L(M’)=L(M)
結論: 接受L的最小狀態有窮自動機(不計同構)是唯一的
6、DFA的最小化演算法
DFA最小化演算法的核心思想(分割法):
- 把一個DFA的狀態分成一些不相交的子集,使得任何不同的兩子集的狀態都是可區別的,而同一子集中的任何兩個狀態都是等價的
- 演算法假定每個狀態射出的弧都是完全的,否則,引入一個新狀態,叫死狀態,該狀態是非終止狀態, 將不完全的輸入弧都射向該狀態,對所有輸入,該狀態射出的弧還回到自己
DFA M =(K,∑,f,k0,kt),最小狀態DFA M’:
- 構造狀態的一初始劃分∏:
終態 kt 和非終態 K- kt 兩組(group) - 對 ∏ 施用程序PP構造新劃分 ∏new
- 如 ∏new = ∏ , 則令 ∏final = ∏ 并繼續步驟4
否則 ∏:=∏new,重復2 - 為 ∏final 中的每一組選一代表,這些代表構成 M’ 的狀態
若 k 是一代表且 f(k,a)=t ,令 r 是 t 組的代表, 則 M’ 中有一轉換 f’(k,a)=r
M’ 的開始狀態是含有S0那組的代表;
M’ 的終態是含有F那組的代表 - 去掉M’中的死狀態
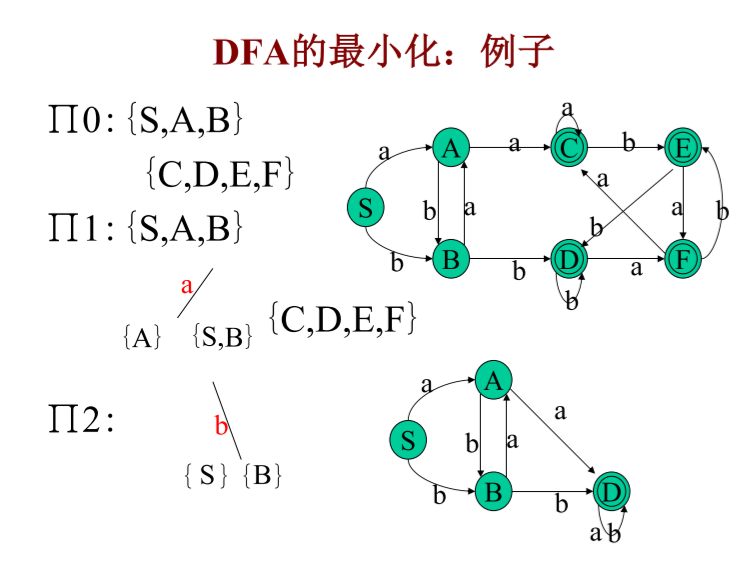
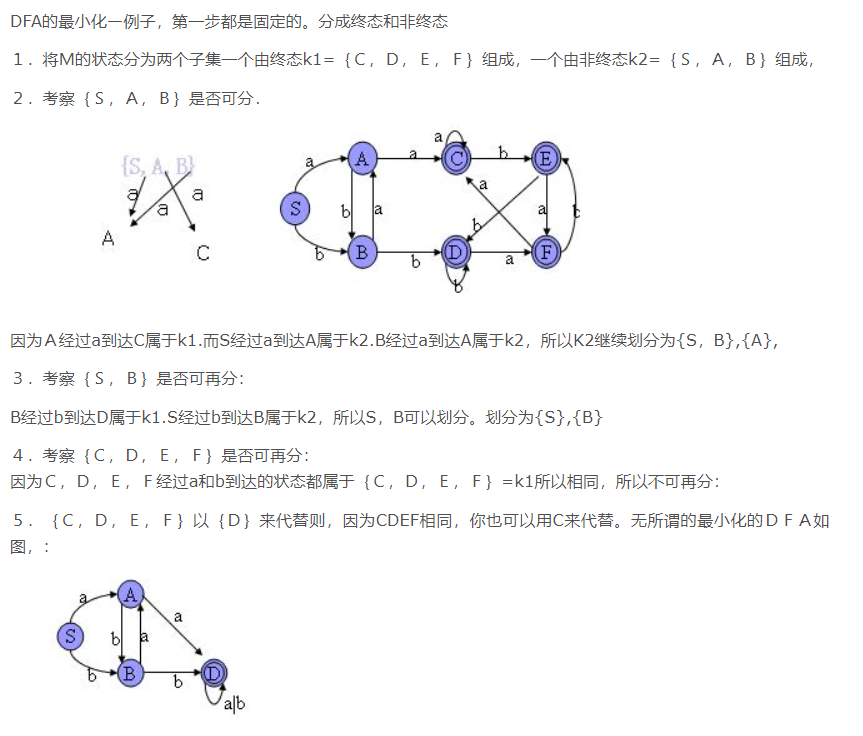
三、詞法分析
1、正規運算式與有限自動機的等價性
定理 :設 r 是 ∑ 上一個正規運算式,則存在一個 FA M 接受 L(r),反之亦然
(1)有限自動機=>正規運算式
- 將轉換圖的概念拓廣,每潭訓上可以用一個正規式標記,
- 首先,在 m 的轉換圖上加進 x, y 兩個結點,
從 x 用 ε 弧連接到 m 的所有初態結點,
從m的所有接受態結點用 ε 弧連接到y,
從而構成一個新的NFA m’,L(m)=L(m’) - 然后,逐步消去NFA m’中的狀態結點,直至剩下x,y為止,
在消結的程序中,逐步用正規式標記弧,
消結的程序是直觀的,只需反復使用下面的替換規則:
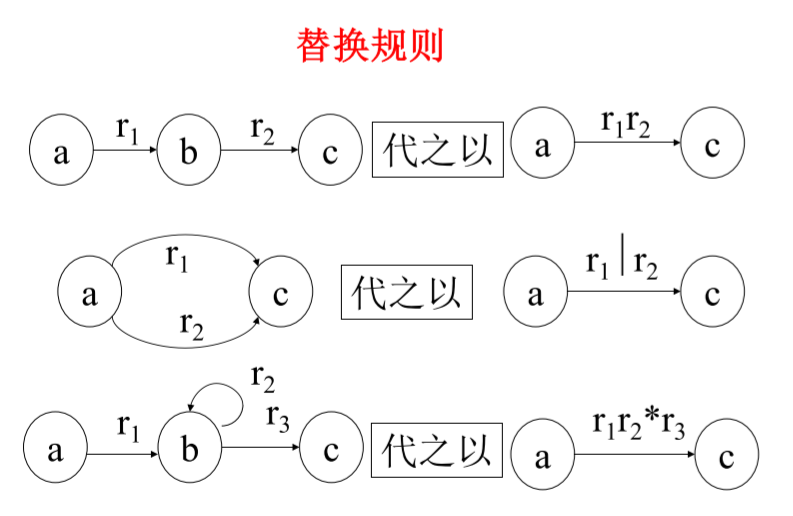
- 首先,在 m 的轉換圖上加進 x, y 兩個結點,
(2)正規運算式=>有限自動機
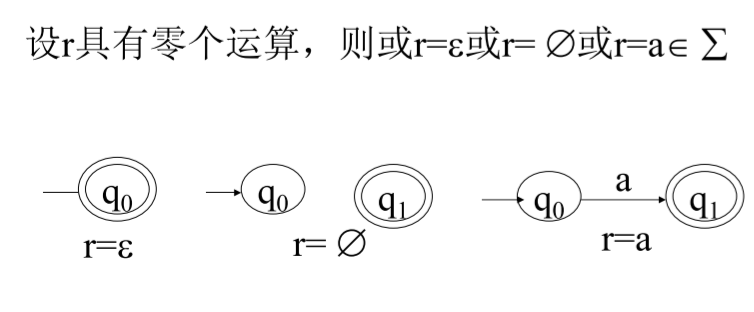

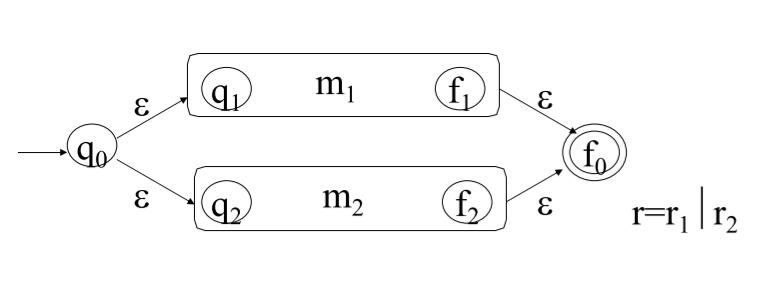 | 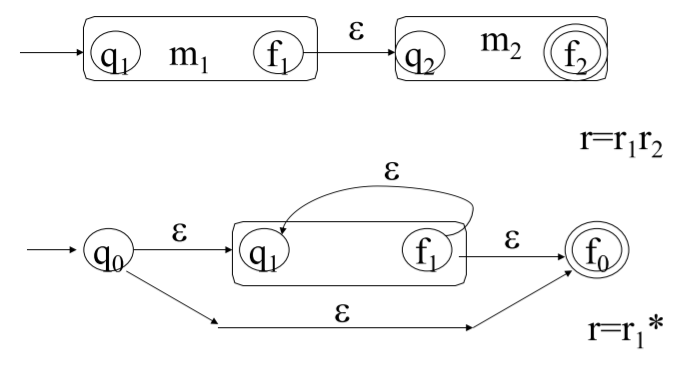 |
2、正規文法與有限自動機的等價性
定理: 對于每一個右線性正規文法或左線性正規文法G,都存在一個FA m,使L(m)=L(G)
 |  |
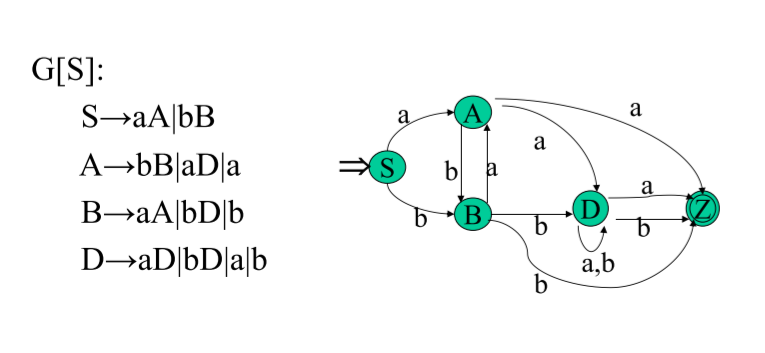
定理 對于每一個FA m, 都存在一個右線性正規文法G和一個左線性正規文法G’, 使L(G)=L(G’)=L(m)
3、詞法分析
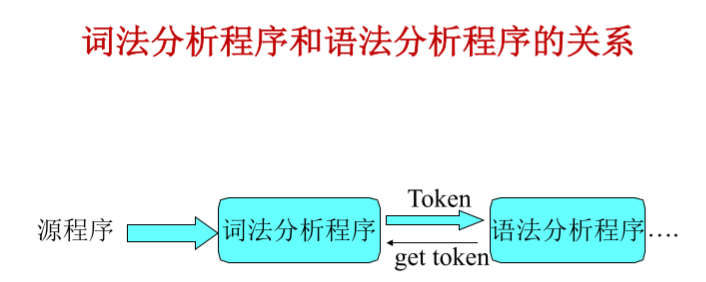
詞法分析是編譯程序中的一個階段,在語法分析前進行,
也可以和語法分析結合在一起作為一遍,由語法分析程式呼叫詞法分析程式來獲得當前單詞供語法分析使用,
 |  |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/221279.html
標籤:其他