多目視覺三維重建研究綜述
多目視覺三維重建研究綜述
三維重建經過數十年的發展,已經取得巨大的成功.基于視覺的三維重建在計算機領域是一個重要的研究內容,主要通過使用相關儀器來獲取物體的二維影像資料資訊,然后,再對獲取的資料資訊進行分析處理,最后,利用三維重建的相關理論重建出真實環境中物體表面的輪廓資訊.基于視覺的三維重建具有速度快、實時性好等優點,能夠廣泛應用于人工智能、機器人、無人駕駛、SLAM(Simultaneous localization and mapping)、虛擬現實和3D列印等領域,具有重要的研究價值,也是未來發展的重要研究方向.
1.三維重建方法
從整體上來看,三維重建技術主要通過視覺傳感器來獲取外界的真實資訊,然后,再通過資訊處理 技識訓者投影模型得到物體的三維資訊,也就是說, 三維重建是一種利用二維投影恢復三維資訊的計算機技術,
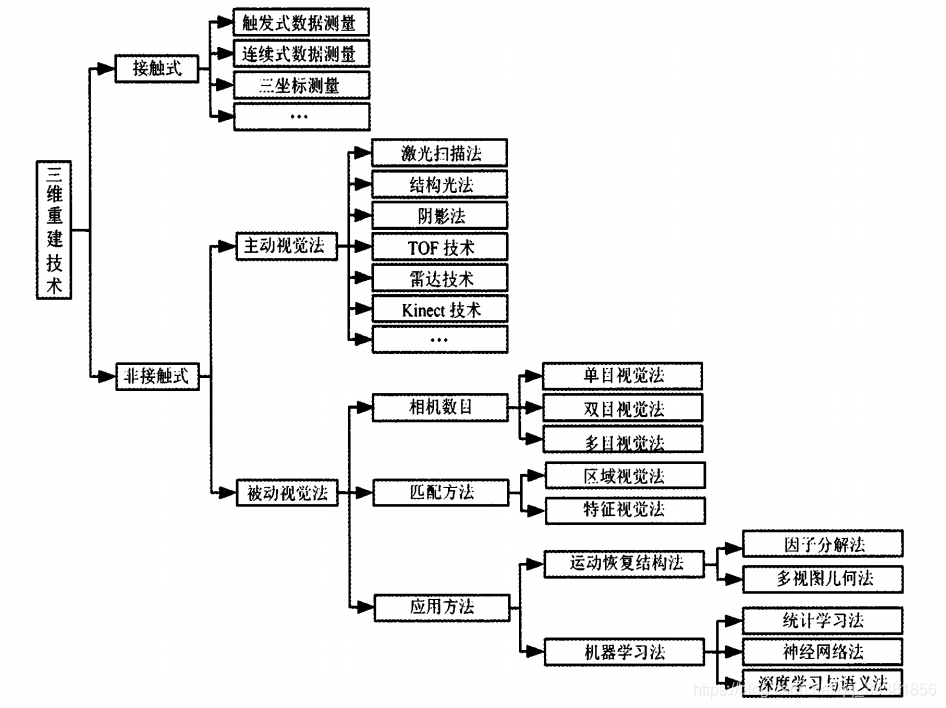
從資料獲取方法上來劃分,可以劃分為接觸式和非接觸式兩種,接觸式方法其實就是利用某些儀器能夠快速直接測量場景的三維資訊,主要包括觸發式測量、 連續式測量、CMMs和RA等.雖然,接觸式方法有其獨特的優點,但是該方法只能應用于儀器能夠接觸到測量場景的場合.非接觸式主要包括主動視覺法和被動視覺法,主動式需要向場景中發射結構光源,然后再通過計算和提取光源在場景中的投影資訊來檢測目標位置 并進行測量.被動式不使用任何其他能量,而是通過獲取外界光源的反射來進行三維測量.
主動視覺又包括激光掃描法、結構光法、陰影法、TOF 技術、雷達技術、Kinect技術等;被動視覺法根據攝像機數目的不同分為單目視覺法、雙目視覺法和多目視覺法;根據原理(匹配方法)不同又可以分為區域視覺法、特征視覺法等;根據應用方法也可以分為運動恢復結構法和機器學習法等,
本文主要對多目視覺方法的三維重建進行綜述,
1.1基于多目視覺的三維重建方法
雙目視覺的作業原理來源于人類的雙目視覺系統,也就是說從不同的視角通過兩個相同的相機捕獲同一個位置下的左右兩側影像,然后再利用三角測量原理獲取物體的深度資訊,通過這些深度資訊重建出物體的三維模型,多目視覺是雙目視覺的一種延伸,它是在雙目視覺的基礎上,增加一臺或者多臺攝像機作為輔助進行測量,從而獲得不同角度下同一物體的多對影像,
多目視覺法不需要人為地對相關輻射源進行設定,能夠在不接觸的情況下進行自動在線檢測.這種方法的優點是可以減少測量中的盲區,獲得更大的視野范圍,更高的識別精度;此外,該方法還能解決雙目視覺中的誤匹配現象,能夠適應各種場景.但由于在雙目的基礎上增加了一臺或多臺相機,在進行三維重建時需要對大量的資料進行處理,導致處理時間的增加,無法滿足實時性的要求;此外,在重建程序中需要進行大量的匹配運算,運算量偏大,而且易受環境光照條件的影響;另外,在基線距離比較大時,重建效果會降低.目前,多目視覺法在車輛自主駕駛、機器人視覺、多自由度機械裝置控制等很多 領域獲得了廣泛的應用,
1.2根據匹配方法分類
影像特征資訊匹配的質量在三維環境重建程序中起著十分關鍵的作用.影像特征資訊的匹配首先提取待重建影像的匹配資訊,并使用相應的演算法在提取出的匹配資訊集中尋找最佳匹配集,根據最佳匹配集求解變換模型.根據匹配的方法不同可以分為區域視覺法和特征視覺法.
1.2.1區域視覺法
區域視覺法就是基于區域立體匹配演算法的三維重建技術.該演算法利用對極幾何約束和連續性,提高了稠密匹配的效率和三維重建的質量.
1986年,Goshtasby等提出了一個由粗到細的分割方法,該方法減小了影像分割的質量對區域檢測的影響,1994年,Flusser等首先對獲取的影像進行分割并提取封閉區域,然后再用質心表示其封閉區域,最后,獲取具有旋轉不變特性的區域.進一步的,2003年,Alhichri等提出一種稱為虛圓的影像特征.為了提取這種特征,需要對影像的邊緣進行檢測,從而獲取其二值化的邊緣影像,然后再使用歐氏距離變換提取影像特征.為了使檢測演算法具有仿射不變性,1997年,Schmid等提出區域灰度值不變數.2004年,Matas等又提出一種仿射不變區域檢測演算法.同年,Tuytelaars等提出了兩種具有仿射變換不變性的特征區域的方法.與此同時,Kadir等也提出了一種顯著區域的方法,遺憾的是,這種方法計算量比較大,并且檢測區域的重復率也不如其他檢測演算法.
1.2.2特征視覺法
基于特征視覺的三維重建技術其實就是通過相機獲取二維影像,然后提取影像中的角點作為特征點,以雙目立體視覺理論為基礎,利用匹配演算法,獲得特征點匹配對,再通過三角測量原理獲取深度值,從而獲得物體表面的三維模型.這種方法的優點是很好地解決了立體匹配的精度和速度,從而能夠較精確地對物體實作三維重建.
1988年,Harris等首先提出具有旋轉不變特性的角點檢測演算法,這種演算法是對Moravec
提出的檢測演算法的改進.由于該演算法在結果檢測中存在許多的誤檢測點,為此Schmid等和Weijer等又在該演算法的基礎上進行了改進,減少了誤檢測點的數量.與此同時,為了適應影像解析度的變化,2004年,Mikolajczyk等又在演算法的基礎上加入了尺度引數,將Harris角點演算法擴展為Harris—Laplace演算法,這種演算法具有尺度不變性.在此基礎上又提出了具有仿射不變的Harris—Affine演算法.這種演算法的優點是在較大的仿射變形情況下仍能保持不變性,
為了使角點的檢測效率更高,速度更快,1997年,Smith等提出SUSAN(SmaUest univalue
segment assimilating nucleus)角點檢測演算法,隨后,Lindeberg等[133_134]提出了一種基于尺度歸一化微分算子的檢測方法,這種方法的優點是對于提取的特征點的尺度和形狀使其能夠滿足仿射不變性.Baumberg提出了一種新的迭代演算法用來調整特征點的形狀,使其能夠滿足影像的區域結構,Lowe最先提出了SIFT算子,該算子具有旋轉不變性、尺度不變性以及光照不變性等優點,是目前最穩定的特征算子,但是,它的缺點也很明顯,運算復雜,處理速度慢.2004年,Ke等在傳統的SIFT特征算子的基礎上,提出了基于主成分分析(Principal component analysis,PCA)的SIFT特征描述算子方法,該方法降低了特征描述子的維度,提高了匹配的精度.2006年,Ba.y等提出了SURF演算法,這個演算法是SIFT算子的一種改進,解決了SIFT算子計算速度慢的缺點.2014年,葛盼盼等在研究Harris演算法和SURF演算法各自的 特點后,提出了Harris-SURF演算法,這種方法結合了Harris演算法定位精度高以及SURF演算法的旋轉不變性、尺度不變性以及光照不變性等兩者的優勢,提高了三維重建的精度,使重建的效果更好.
1.3根據應用方法分類
基于被動視覺的三維重建技術根據所選取方法不同,所重建的效果有明顯差別,但每種方法都有不同的優點和缺點.因此,根據應用方法可以分為運動恢復結構法和機器學習法.
1.3.1運動恢復結構法
如果獲取的影像是從多個視點捕獲的多張影像,可以通過匹配演算法獲得影像中相同像素點的對應關系,再利用匹配約束關系,結合三角測量原理,獲得空間點的三維坐標資訊,進而重建出物體的三維模型.這個程序被稱為運動恢復結構法,即SfM (Structure from motion).
運動恢復結構法是通過三角測量原理來恢復場景的三維結構.這種方法不僅是三維重建的一種重要手段,而且也是一種結構測量的方法,能夠廣泛地應用在測繪、軍事偵查等領域.目前SfM主要分為兩類:增量式SfM(Incremental structure from motion)和全域式SfM(Global structure from motionl).
增量式SfM是最早提出的SfM方法,首先通過相機獲取多幅影像,選取其中一對作為“種子”,其次求解出相機引數并恢復部分三維點,再次加入相關影像進行重加,最后使用BA(Bundle adjustment)進行優化,從而實作對影像重建的程序.
全域式SFM首先使用旋轉一致性求解相機全域旋轉,然后計算相機的位移,最后通過BA(Bundle adjustment)進行優化提升重建質量.全域式是由Sturm在1996 年提出的.隨后,在2011年,Crandall等提出了一種基于馬爾科夫隨機場的全域式方法.同年,Irschara等引入GPS坐標作為相機坐標,并使用全域式SfM進行三維重建.2015年,Cui等在Crandall等人提出的方法基礎上提出了一種全新的全域式SfM理論,主要通過輔助資訊對求解程序進行優化,使其具備處理多種資料的能力.
目前,運動恢復結構法主要有因子分解法和多視圖幾何法兩種.
1)因子分解法
因子分解法是Tomasi等在1992年最早提出的.該方法主要是把攝像機近似為正攝投影模型,再通過奇異值分解SVD(Singular value decomposition)對獲取的觀測矩陣進行處理,從而獲得結構矩陣和運動矩陣.但是,這種方法的不足是忽略了大部分相機的真實投影模型.Poelman等將因子分解法擴展到弱透視投影和平行透視投影模型中,但得到的效果仍不是很好,Triggs又進一步將因子分解法推廣到一般的透視投影模型中,這種模型需要首先恢復射影的深度,然后再通過因子分解法恢復其結構,該模型得到的效果要比以前研究者所使用的方法進步了很多,但其精度仍不是很高.然而,Han等于2001年提出了在透視投影模型下考慮相機投影矩陣約束的因子分解法,該方法取得了不錯的效果,
因子分解法的優點是簡便靈活,對周圍的環境并沒有什么特別的要求,也不依賴于任何一種具體的模型,抗噪能力相對來說也比較強,唯一的缺點就是精度不高,
2)多視圖幾何法
基于多視圖幾何的三維重建在計算機視覺領域中一直都是最熱門的研究問題之一.多視圖幾何法是描述同一場景從不同視角下獲取的多幅影像與物體之間投影關系的幾何模型,該方法主要應用于單相機多視角的三維重建中,
通常多視圖幾何法主要包括以下4個步驟:
1)特征提取與匹配
特征提取與匹配首先利用區域不變性對影像特征資訊進行檢測,然后再用描述算子來提取特征點,最后對同一場景中表示同一空間位置的特征點進行匹配,從而計算出正確的匹配特征點對.特征提取與匹配是計算機視覺的研究基礎,而影像特征資訊匹配的質量在三維環境重建程序中也起著十分重要的作用,被廣泛應用于影像檢索、影像拼接、目標識別與跟蹤及三維重建等領域.
2)多視圖幾何約束關系計算
多視圖幾何約束關系計算就是通過對極幾何將幾何約束關系轉換為基礎矩陣的模型引數估計的程序.1981年,Longuet—HigginsIl55J最早提出多視圖間的幾何約束關系,這種關系在歐氏幾何中可以用本質矩陣表示.1990年,Faugeras等【156】詳細研究了本質矩陣的性質.1993年,Luong等【157】提出了解決兩幅影像之間幾何關系的基礎矩陣,并闡
述了對極幾何在射影空間下的基本性質.1996年,Luong等【15剮將基礎矩陣的概念進行推廣,開啟了多視圖幾何學的新篇章.
3)優化估計結果
當得到初始重建結果后,為了均勻化誤差和獲得更精確的結果,通常需要對初始結果進行非線性優化.在SfM中對誤差應用最精確的非線性優化方法就是捆綁調整法,該方法是大規模三維重建中最為關鍵的一步,也是SfM的核心問題,它主要利用代價函式對多臺相機模型的內外引數以及獲取的三維點云資料同時進行優化調整,
2009年,Lourakis等1160J提出了稀疏捆綁調整法(Sparse bundle adjustment,SBA),它利用增量標準方程的稀疏結構來提高解方程的效率.然而,隨著獲取的三維點云數量的增加,捆綁調整方法需要大量的計算時間,為了解決這種問題,Choudhary等結合CPU和GPU加速運算的方式使用在 BA演算法上,這種方法有利于加速捆綁調整,2012年,Hu等對大規模三維點云的優化進行了捆綁調整改進,可以在SfM中使用高解析度影像,以及進行稠密三維重建,目前,捆綁調整法已經成為基于特征的多視圖三維重建、結構和運動估計演算法最后必須采用的步驟.
4)稠密場景描述
多視圖幾何法經過射影重建和度量重建后會生成一個稀疏的三維結構模型,這種稀疏的三維結構模型已經可以應用于要求精度不高的場景,但其不具有可視化效果.因此,為了獲得應用范圍更廣的三維模型,要進行表面稠密估計,恢復稠密的三維點云結構模型.
1.3.2機器學習法
機器學習其實就是使機器具有學習的能力,從而不斷獲得新知識以及新技能得到有效提升.機器學習在三維環境重建中一直是重點研究物件,因此,根據機器學習可以分為常用的三種方法,分別是統計學習法、神經網路法和深度學習與語意法.
1)統計學習法
統計學習法就是需要通過不斷地學習再學習的程序.該方法是以大型資料庫為基礎,例如,人臉資料庫、場景資料庫等.首先,這種方法需要對資料庫中的每一個目標進行特征統計,這些特征主要包括亮度、紋理、幾何形狀、深度等,然后,再對重建目標的各種特征建立概率函式,最后,計算重建目標與資料庫中相似目標的概率大小,取概率最大的目標深度為重建目標的深度,再使用差值計算和紋理映射進行目標的三維重建.目前,常用的概率
模型有馬爾科夫模型(Markov model,MM)、隱馬爾科夫模型(Hidden Markov model,HMMs)
和PHMMs模型(Pseudo 2D hidden Markov models)等.統計學習法可以對大型場景、人
臉及人體進行重建,并可以應用到視頻檢索和識別系統等其他領域.
2)神經網路法
基于神經網路法的三維重建是利用神經網路具有較好的泛函逼近能力,能夠以任意的精度逼近任何非線性關系的優點來進行三維重建.如,Do 等提出了兩種利用神經網路進行三維重建的方法.第一種方法是首先通過線性關系進行三維重建,然后再使用神經網路的優點來擬合重建的誤差,從而提高三維重建的精度.第二種方法是先利用神經網路擬合影像的像差,從而獲得理想的像點,然后再利用線性關系進行三維重建.不足的是這兩種方法進行三維重建的程序比較復雜,需要進行相機的標定,來獲取相機的引數.為了使三維重建的程序簡
單,而且更能符合人的雙眼認知機理,袁野等提出了一種基于BP網路的三維重建演算法,
3)深度學習與語意法
基于深度學習的三維重建最近幾年取得了非常大進展,是當前計算機視覺領域比較流行的方法之一.學習系統是由多層卷積層和多層全連接層組成的卷積神經網路(CNN)進行學習影像的層次化特征表示,這種方法能夠精確地重建出物體的幾何形狀.與傳統的三維重建相比較,基于深度學習的三維重建技術不需要進行特征提取與匹配以及復雜的幾何運算,使用深度學習的方法更加方便,使得實時性進一步提高,
基于語意的三維重建可以運用在移動的行人或車輛等大的場景,這種方法能夠精確地對環境中的目標物體進行識別,而深度學習技術也是最近幾年剛剛興起的比較有優勢的識別方法,因此,深度學習和語意相結合的三維重建是未來幾年的研究趨勢,也會受到該領域的研究者們廣泛關注,
2015年,Savinov等提出了一個稠密的語意三維重建方法,2016年,Blaha等提出了一個自適應多解析度的語意三維重建方法.該方法的目的是在給定一組場景影像中進行3D場景稠密重建,并分割成語意目標類.隨后,Sunderhauf等提出了面向物件的語意建圖方法,該方法的主要目的是構建環境的3D點云地圖,然后再通過卷積神經網路對關鍵幀影像中的物體進行識別檢測,最后對3D目標物體進行點云分割,從而在地圖中更新或添加目標物體的3D點云等資訊,

2.總結
被動視覺中的雙目視覺方法能夠較好地獲取重建效果,但是,必須要滿足基線的范圍才能重建出更好的效果.被動視覺中的多目視覺方法視野范圍大,識別精度較高,重建效果穩定,適應性較強,能夠應用在各種場景中,不足的是設備復雜,價格昂貴,計算量較大,控制上難以實作.運動恢復結構法對影像的要求較低,通用性非常好,魯棒性較強,一般來說其重建效果依賴于特征點的密集程度,特征點越密集重建效果就越好,但相應的運算量也大大增加.統計學習法重建質量和效率都非常高,但其適用范圍較窄,重建效果取決于資料庫的完備程度,資料庫越完備重建越精確.其他視覺中的區域視覺法計算簡單,匹配精度較高,但是,對影像的要求較高,受光線的干擾較大.其他視覺中的特征視覺法抗干擾能力強,魯棒性較高,應用范圍廣,但是,不能夠對影像資訊進行全面描述.其他視覺中的神經網路法重建效果較好,具有很強的魯棒性,應用范圍較廣,不足的是,在重構之前需要進行訓練,收斂速度較慢,運算量較大.另一方面,三維重建技術方法要求的功能也更加具體化,不僅要能精確地重建出物體的形狀,還要能夠對物體的形狀進行辨識,尤其是能夠對智能車重建出的前方環境中的動態目標進行判別.同時,在人工智能、機器人技術、無人駕駛等領域中,三維重建已成為不可或缺內容,
從目前基于視覺的三維重建關鍵技術的發展狀況來看,以下幾個方面的作業值得關注:
1)目前基于單目視覺的三維重建的應用環境非常廣泛,然而大多數是以靜態室內環境為主.應用于室外單目視覺的三維重建研究相對比較少,因此,對于動態的室外大規模三維場景重建,包括城市建設等是一個重要的研究方向.
2)更高效地將視覺傳感器獲取的三維資訊與其他多傳感器資訊進行融合,可以應用到智能車的環境感知系統,提高智能車周圍環境的識別能力,這也是一個非常有價值的研究方向,
3)基于視覺的三維重建主要是由視覺特征的檢測與匹配完成的,然而,目前的視覺特征匹配還存在著許多缺點,例如匹配精度比較低、速度慢以及無法適應重復的紋理等問題.因此,還需要更深一步的研究來發掘新的視覺特征檢測與匹配方法,從而滿足基于視覺的三維重建在復雜環境中的應用.
4)傳統三維重建方法針對的基本都是剛性物體,對于非剛性物體(如液態物體、火焰)和動態物體等的重建問題一直無法較好的實作,因此這也是未來的一個研究熱點,
5)三維重建在醫學上的應用也具有巨大的研究價值,是未來相關領域的一個研究方向,
6)基于視覺的三維重建技術研究和應用已從傳統的工業領域快速擴展到其他領域,如醫療康復、外星探索等,這些領域也是未來發展的新方向.
由于三維重建中的方法各有缺點,因此在重建方法上需要改進的地方有如下幾點:
1)計算量過大,比較消耗資源;2)抗干擾性不強,易受到各種外在條件的影響;3)對光線的要求比較高,太過于理想化,不符合實際的要求.又由于各種方法離實際應用還有一段距離,各種應用需求亟待被滿足.也正因為如此,越來越多的研究人員進入該領域并積極推動 其發展.總而言之,在未來的作業中,將在現有作業基礎上,重點需要在資訊融合、虛擬現實、多機協作系統、室外動態環境的三維實時重建演算法等方面開展進一步的研究,相信三維重建的發展一定能夠促進其該領域的發展,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/225852.html
標籤:其他