本文轉載自:資料結構和演算法之美
當我們設計了一個演算法以后,往往會從時間和空間這兩個維度來評判這個演算法的優劣,執行時間越短,占用記憶體空間越小的演算法,我們認為是更優的演算法,
這篇文章的主題:復雜度分析就是用來分析演算法時間和空間復雜度的,
為什么需要復雜度分析
你可能會有些疑惑,我把代碼跑一遍,通過統計、監控,就能得到演算法執行的時間和占用的記憶體大小,為什么還要做時間、空間復雜度分析呢?這種分析方法能比我實實在在跑一遍得到的資料更準確嗎?
首先,我可以肯定地說,你這種評估演算法執行效率的方法是正確的,很多資料結構和演算法書籍還給這種方法起了一個名字,叫事后統計法,但是,這種統計方法有非常大的局限性,
1. 測驗的結果依賴測驗的環境
測驗環境中硬體的不同會對測驗結果有很大的影響,比如,我們拿同樣一段代碼,分別用 Intel Core i9 處理器和 Intel Core i3 處理器來運行,不用說,i9 處理器要比 i3 處理器執行的速度快很多,還有,比如原本在這臺機器上 a 代碼執行的速度比 b 代碼要快,等我們換到另一臺機器上時,可能會有截然相反的結果,
2. 測驗結果受資料規模的影響很大
如果測驗資料規模太小,測驗結果可能無法真實地反映演算法的性能,比如,對于小規模的資料排序,插入排序可能反倒會比快速排序要快!
所以,我們需要一個不用具體的測驗資料來測驗,就可以粗略地估計演算法的執行效率的方法,這就是我們今天要講的時間、空間復雜度分析方法,
大 O 復雜度表示法
演算法的執行效率,粗略地講,就是演算法代碼執行的時間,但是,如何在不運行代碼的情況下,用“肉眼”得到一段代碼的執行時間呢?
這里有段非常簡單的代碼,求 1,2,3…n 的累加和,現在,我就帶你一塊來估算一下這段代碼的執行時間,
int cal(int n)
{
int sum = 0;
int i = 1;
for (; i <= n; ++i)
{
sum = sum + i;
}
return sum;
}
從 CPU 的角度來看,這段代碼的每一行都執行著類似的操作:讀資料-運算-寫資料,盡管每行代碼對應的 CPU 執行的個數、執行的時間都不一樣,但是,我們這里只是粗略估計,所以可以假設每行代碼執行的時間都一樣,為 unit_time,在這個假設的基礎之上,這段代碼的總執行時間是多少呢?
第 2、3 行代碼分別需要 1 個 unit_time 的執行時間,第 4、5 行都運行了 n 遍,所以需要 2nunit_time 的執行時間,所以這段代碼總的執行時間就是 (2n+2)unit_time,可以看出來,所有代碼的執行時間 T(n) 與每行代碼的執行次數成正比,
按照這個分析思路,我們再來看這段代碼,
int cal(int n) {
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
}
我們依舊假設每個陳述句的執行時間是 unit_time,那這段代碼的總執行時間 T(n) 是多少呢?
第 2、3、4 行代碼,每行都需要 1 個 unit_time 的執行時間,第 5、6 行代碼回圈執行了 n 遍,需要 2n * unit_time 的執行時間,第 7、8 行代碼回圈執行了 n2遍,所以需要 2n2 * unit_time 的執行時間,所以,整段代碼總的執行時間 T(n) = (2n2+2n+3)*unit_time,
盡管我們不知道 unit_time 的具體值,但是通過這兩段代碼執行時間的推導程序,我們可以得到一個非常重要的規律,那就是,所有代碼的執行時間 T(n) 與每行代碼的執行次數 n 成比例,
我們可以把這個規律總結成一個公式,注意,大 O 就要登場了!
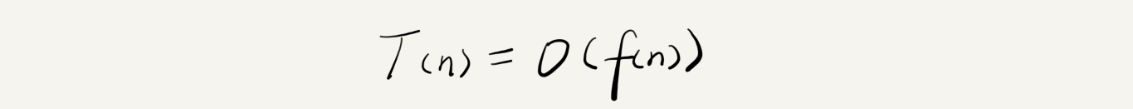
我來具體解釋一下這個公式,其中,T(n) 我們已經講過了,它表示代碼執行的時間;n 表示資料規模的大小;f(n) 表示每行代碼執行的次數總和,因為這是一個公式,所以用 f(n) 來表示,公式中的 O,表示代碼的執行時間 T(n) 與 f(n) 運算式成正比,
所以,第一個例子中的 T(n) = O(2n+2),第二個例子中的 T(n) = O(2n2+2n+3),這就是大 O 時間復雜度表示法,大 O 時間復雜度實際上并不具體表示代碼真正的執行時間,而是表示代碼執行時間隨資料規模增長的變化趨勢,所以,也叫作漸進時間復雜度(asymptotic time complexity),簡稱時間復雜度,
當 n 很大時,你可以把它想象成 10000、100000,而公式中的低階、常量、系數三部分并不左右增長趨勢,所以都可以忽略,我們只需要記錄一個最大量級就可以了,如果用大 O 表示法表示剛講的那兩段代碼的時間復雜度,就可以記為:T(n) = O(n); T(n) = O(n2),
時間復雜度分析方法
1. 只關注回圈執行次數最多的一段代碼
我剛才說了,大 O 這種復雜度表示方法只是表示一種變化趨勢,我們通常會忽略掉公式中的常量、低階、系數,只需要記錄一個最大階的量級就可以了,所以,我們在分析一個演算法、一段代碼的時間復雜度的時候,也只關注回圈執行次數最多的那一段代碼就可以了,這段核心代碼執行次數的 n 的量級,就是整段要分析代碼的時間復雜度,
為了便于你理解,我還是拿前面的例子來說明,
int cal(int n) {
int sum = 0; //2
int i = 1; //3
for (; i <= n; ++i) { //4
sum = sum + i; //5
}
return sum;
}
其中第 2、3 行代碼都是常量級的執行時間,與 n 的大小無關,所以對于復雜度并沒有影響,回圈執行次數最多的是第 4、5 行代碼,所以這塊代碼要重點分析,前面我們也講過,這兩行代碼被執行了 n 次,所以總的時間復雜度就是 O(n),
2. 加法法則:總復雜度等于量級最大的那段代碼的復雜度
我這里還有一段代碼,你可以先試著分析一下,然后再往下看跟我的分析思路是否一樣,
int cal(int n) {
int sum_1 = 0; //2
int p = 1; //3
for (; p < 100; ++p) {
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
for (; q < n; ++q) {
sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}
這個代碼分為三部分,分別是求 sum_1、sum_2、sum_3,我們可以分別分析每一部分的時間復雜度,然后把它們放到一塊兒,再取一個量級最大的作為整段代碼的復雜度,
第一段的時間復雜度是多少呢?這段代碼回圈執行了 100 次,所以是一個常量的執行時間,跟 n 的規模無關,
這里我要再強調一下,即便這段代碼回圈 10000 次、100000 次,只要是一個已知的數,跟 n 無關,照樣也是常量級的執行時間,當 n 無限大的時候,就可以忽略,盡管對代碼的執行時間會有很大影響,但是回到時間復雜度的概念來說,它表示的是一個演算法執行效率與資料規模增長的變化趨勢,所以不管常量的執行時間多大,我們都可以忽略掉,因為它本身對增長趨勢并沒有影響,
那第二段代碼和第三段代碼的時間復雜度是多少呢?答案是 O(n) 和 O(n2),你應該能容易就分析出來,我就不啰嗦了,
綜合這三段代碼的時間復雜度,我們取其中最大的量級,所以,整段代碼的時間復雜度就為 O(n2),也就是說:總的時間復雜度就等于量級最大的那段代碼的時間復雜度,那我們將這個規律抽象成公式就是:
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n))).
3. 乘法法則:嵌套代碼的復雜度等于嵌套內外代碼復雜度的乘積
我剛講了一個復雜度分析中的加法法則,這兒還有一個乘法法則,類比一下,你應該能“猜到”公式是什么樣子的吧?
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)T2(n)=O(f(n))O(g(n))=O(f(n)*g(n)).
也就是說,假設 T1(n) = O(n),T2(n) = O(n2),則 T1(n) * T2(n) = O(n3),落實到具體的代碼上,我們可以把乘法法則看成是嵌套回圈,我舉個例子給你解釋一下,
int cal(int n) {
int ret = 0;
int i = 1;
for (; i < n; ++i) {
ret = ret + f(i);
}
}
int f(int n) {
int sum = 0;
int i = 1;
for (; i < n; ++i) {
sum = sum + i;
}
return sum;
}
我們單獨看 cal() 函式,假設 f() 只是一個普通的操作,那第 4~6 行的時間復雜度就是,T1(n) = O(n),但 f() 函式本身不是一個簡單的操作,它的時間復雜度是 T2(n) = O(n),所以,整個 cal() 函式的時間復雜度就是,T(n) = T1(n) * T2(n) = O(n*n) = O(n2),
我剛剛講了三種復雜度的分析技巧,不過,你并不用刻意去記憶,實際上,復雜度分析這個東西關鍵在于“熟練”,你只要多看案例,多分析,就能做到“無招勝有招”,
幾種常見時間復雜度實體分析
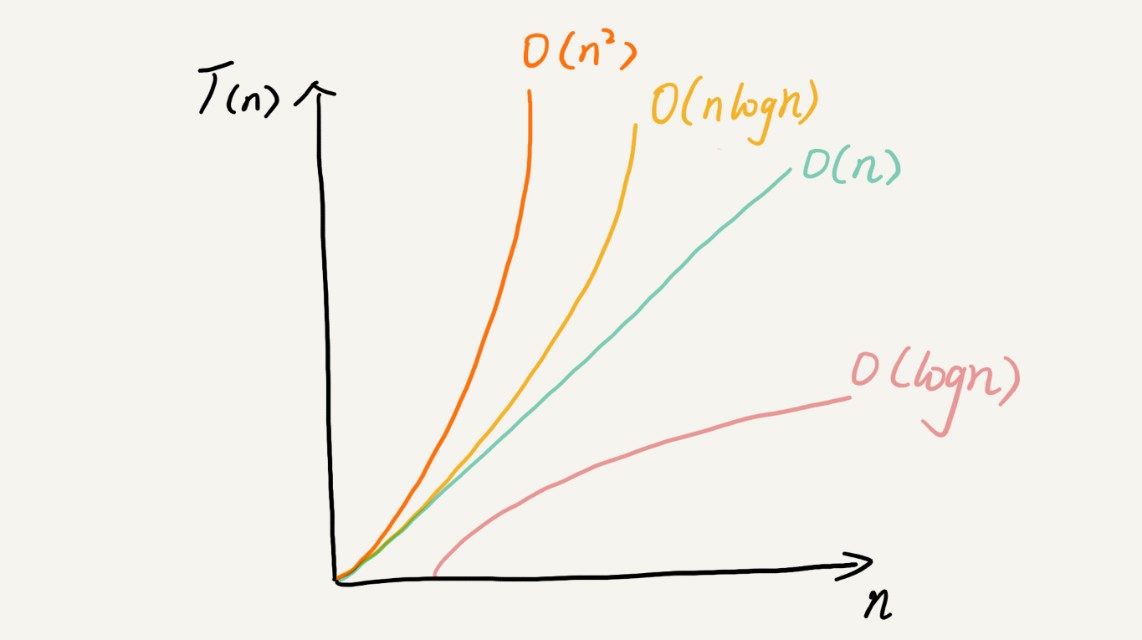
雖然代碼千差萬別,但是常見的復雜度量級并不多,我稍微總結了一下,這些復雜度量級幾乎涵蓋了你今后可以接觸的所有代碼的復雜度量級,

對于剛羅列的復雜度量級,我們可以粗略地分為兩類,多項式量級和非多項式量級,其中,非多項式量級只有兩個:O(2n) 和 O(n!),
我們把時間復雜度為非多項式量級的演算法問題叫作 NP(Non-Deterministic Polynomial,非確定多項式)問題,
當資料規模 n 越來越大時,非多項式量級演算法的執行時間會急劇增加,求解問題的執行時間會無限增長,所以,非多項式時間復雜度的演算法其實是非常低效的演算法,因此,關于 NP 時間復雜度我就不展開講了,我們主要來看幾種常見的多項式時間復雜度,
在計算機領域,一般可以將問題分為可解問題和不可解問題,不可解問題也可以分為兩類:一類如停機問題,的確無解;另一類雖然有解,但時間復雜度很高,可解問題也分為多項式問題(Polynomial Problem,P問題)和非確定性多項式問題(NondeterministicPolynomial Problem,NP問題),更詳細的內容可參照百科
下面是多項式量級復雜度的對比:
1. O(1)
首先你必須明確一個概念,O(1) 只是常量級時間復雜度的一種表示方法,并不是指只執行了一行代碼,比如這段代碼,即便有 3 行,它的時間復雜度也是 O(1),而不是 O(3),
int i = 8;
int j = 6;
int sum = i + j;
我稍微總結一下,只要代碼的執行時間不隨 n 的增大而增長,這樣代碼的時間復雜度我們都記作 O(1),或者說,一般情況下,只要演算法中不存在回圈陳述句、遞回陳述句,即使有成千上萬行的代碼,其時間復雜度也是Ο(1),
2. O(n)**
這種時間復雜度的演算法很常見,
int f(int n) {
int sum = 0;
int i = 1;
for (; i < n; ++i) {
sum = sum + i;
}
return sum;
}
3. O(logn)、O(nlogn)
對數階時間復雜度非常常見,同時也是最難分析的一種時間復雜度,我通過一個例子來說明一下,
i=1;
while (i <= n) {
i = i * 2;
}
根據我們前面講的復雜度分析方法,第三行代碼是回圈執行次數最多的,所以,我們只要能計算出這行代碼被執行了多少次,就能知道整段代碼的時間復雜度,
從代碼中可以看出,變數 i 的值從 1 開始取,每回圈一次就乘以 2,當大于 n 時,回圈結束,還記得我們高中學過的等比數列嗎?實際上,變數 i 的取值就是一個等比數列,如果我把它一個一個列出來,就應該是這個樣子的:

所以,我們只要知道 x 值是多少,就知道這行代碼執行的次數了,通過 2x=n 求解 x 這個問題我們想高中應該就學過了,我就不多說了,x=log2n,所以,這段代碼的時間復雜度就是 O(log2n),
現在,我把代碼稍微改下,你再看看,這段代碼的時間復雜度是多少?
i=1;
while (i <= n) {
i = i * 3;
}
根據我剛剛講的思路,很簡單就能看出來,這段代碼的時間復雜度為 O(log3n),
實際上,不管是以 2 為底、以 3 為底,還是以 10 為底,我們可以把所有對數階的時間復雜度都記為 O(logn),為什么呢?
我們知道,對數之間是可以互相轉換的,log3n 就等于 log32 * log2n,所以 O(log3n) = O(C * log2n),其中 C=log32 是一個常量,基于我們前面的一個理論:在采用大 O 標記復雜度的時候,可以忽略系數,即 O(Cf(n)) = O(f(n)),所以,O(log2n) 就等于 O(log3n),因此,在對數階時間復雜度的表示方法里,我們忽略對數的“底”,統一表示為 O(logn),
對數的換底公式:https://www.cnblogs.com/ransn/p/5138643.html
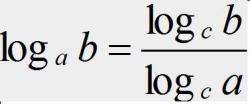
如果你理解了我前面講的 O(logn),那 O(nlogn) 就很容易理解了,還記得我們剛講的乘法法則嗎?如果一段代碼的時間復雜度是 O(logn),我們回圈執行 n 遍,時間復雜度就是 O(nlogn) 了,而且,O(nlogn) 也是一種非常常見的演算法時間復雜度,比如,歸并排序、快速排序的時間復雜度都是 O(nlogn),
4. O(m+n)、O(m*n)
我們再來講一種跟前面都不一樣的時間復雜度,代碼的復雜度由兩個資料的規模來決定,老規矩,先看代碼!
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}
從代碼中可以看出,m 和 n 是表示兩個資料規模,我們無法事先評估 m 和 n 誰的量級大,所以我們在表示復雜度的時候,就不能簡單地利用加法法則,省略掉其中一個,所以,上面代碼的時間復雜度就是 O(m+n),
針對這種情況,原來的加法法則就不正確了,我們需要將加法規則改為:T1(m) + T2(n) = O(f(m) + g(n)),但是乘法法則繼續有效:T1(m)*T2(n) = O(f(m) * f(n)),
空間復雜度分析
前面,咱們花了很長時間講大 O 表示法和時間復雜度分析,理解了前面講的內容,空間復雜度分析方法學起來就非常簡單了,
前面我講過,時間復雜度的全稱是漸進時間復雜度,表示演算法的執行時間與資料規模之間的增長關系,類比一下,空間復雜度全稱就是漸進空間復雜度(asymptotic space complexity),表示演算法的存盤空間與資料規模之間的增長關系,
我還是拿具體的例子來給你說明,(這段代碼有點“傻”,一般沒人會這么寫,我這么寫只是為了方便給你解釋,)
void print(int n) {
int i = 0; //2
int[] a = new int[n]; //3
for (i; i <n; ++i) {
a[i] = i * i;
}
for (i = n-1; i >= 0; --i) {
print out a[i]
}
}
跟時間復雜度分析一樣,我們可以看到,第 2 行代碼中,我們申請了一個空間存盤變數 i,但是它是常量階的,跟資料規模 n 沒有關系,所以我們可以忽略,第 3 行申請了一個大小為 n 的 int 型別陣列,除此之外,剩下的代碼都沒有占用更多的空間,所以整段代碼的空間復雜度就是 O(n),
我們常見的空間復雜度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 這樣的對數階復雜度平時都用不到,而且,空間復雜度分析比時間復雜度分析要簡單很多,所以,對于空間復雜度,掌握剛我說的這些內容已經足夠了,
最好、最壞、平均、均攤時間復雜度
本節重點:
- 最好情況時間復雜度(best case time complexity);
- 最壞情況時間復雜度(worst case time complexity);
- 平均情況時間復雜度(average case time complexity);
- 均攤時間復雜度(amortized time complexity)
先來看一段代碼:
// n表示陣列array的長度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
這段代碼的功能非常簡單,就是查找整數x在陣列中的位置,找到就直接回傳,因為,要查找的變數 x 可能出現在陣列的任意位置,如果陣列中第一個元素正好是要查找的變數 x,那就不需要繼續遍歷剩下的 n-1 個資料了,那時間復雜度就是 O(1),但如果陣列中不存在變數 x,那我們就需要把整個陣列都遍歷一遍,時間復雜度就成了 O(n),所以,不同的情況下,這段代碼的時間復雜度是不一樣的,
為了表示代碼在不同情況下的不同時間復雜度,我們需要引入三個概念:最好情況時間復雜度、最壞情況時間復雜度和平均情況時間復雜度,
1.最好情況時間復雜度
最好情況時間復雜度就是,在最理想的情況下,執行這段代碼的時間復雜度,在最理想的情況下,要查找的變數 x 正好是陣列的第一個元素,這個時候對應的時間復雜度就是最好情況時間復雜度,
2.最壞情況時間復雜度
最壞情況時間復雜度就是,在最糟糕的情況下,執行這段代碼的時間復雜度,如果陣列中沒有要查找的變數 x,我們需要把整個陣列都遍歷一遍才行,所以這種最糟糕情況下對應的時間復雜度就是最壞情況時間復雜度,
3. 平均情況時間復雜度
我們都知道,最好情況時間復雜度和最壞情況時間復雜度對應的都是極端情況下的代碼復雜度,發生的概率其實并不大,為了更好地表示平均情況下的復雜度,我們需要引入另一個概念:平均情況時間復雜度,后面我簡稱為平均時間復雜度,
要查找的變數 x 在陣列中的位置,有 n+1 種情況:在陣列的 0~n-1 位置中和不在陣列中,我們把每種情況下,查找需要遍歷的元素個數累加起來,然后再除以 n+1,就可以得到需要遍歷的元素個數的平均值,即:
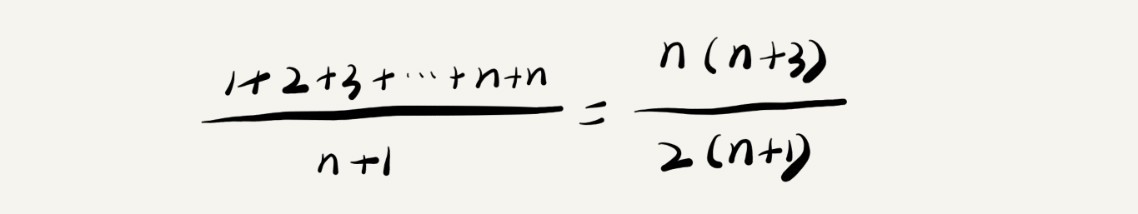
我們知道,時間復雜度的大 O 標記法中,可以省略掉系數、低階、常量,所以,咱們把剛剛這個公式簡化之后,得到的平均時間復雜度就是 O(n),
這個結論雖然是正確的,但是計算程序稍微有點兒問題,究竟是什么問題呢?我們剛講的這 n+1 種情況,出現的概率并不是一樣的,
我們知道,要查找的變數 x,要么在陣列里,要么就不在陣列里,這兩種情況對應的概率統計起來很麻煩,為了方便你理解,我們假設在陣列中與不在陣列中的概率都為 1/2,另外,要查找的資料出現在 0~n-1 這 n 個位置的概率也是一樣的,為 1/n,所以,根據概率乘法法則,要查找的資料出現在 0~n-1 中任意位置的概率就是 1/(2n),
因此,前面的推導程序中存在的最大問題就是,沒有將各種情況發生的概率考慮進去,如果我們把每種情況發生的概率也考慮進去,那平均時間復雜度的計算程序就變成了這樣:
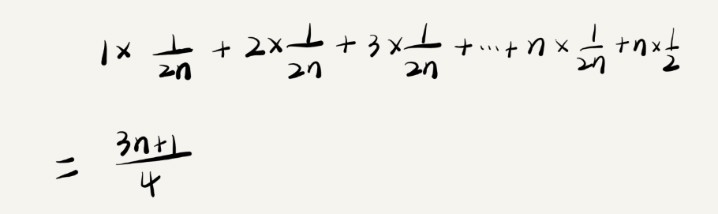
這個值就是概率論中的加權平均值,也叫作期望值,所以平均時間復雜度的全稱應該叫加權平均時間復雜度或者期望時間復雜度,
引入概率之后,前面那段代碼的加權平均值為 (3n+1)/4,用大 O 表示法來表示,去掉系數和常量,這段代碼的加權平均時間復雜度仍然是 O(n),
實際上,在大多數情況下,我們并不需要區分最好、最壞、平均情況時間復雜度三種情況,像我們上一節課舉的那些例子那樣,很多時候,我們使用一個復雜度就可以滿足需求了,只有同一塊代碼在不同的情況下,時間復雜度有量級的差距,我們才會使用這三種復雜度表示法來區分,
4. 均攤時間復雜度
均攤時間復雜度,聽起來跟平均時間復雜度有點兒像,對于初學者來說,這兩個概念確實非常容易弄混,我前面說了,大部分情況下,我們并不需要區分最好、最壞、平均三種復雜度,平均復雜度只在某些特殊情況下才會用到,而均攤時間復雜度應用的場景比它更加特殊、更加有限,
// array表示一個長度為n的陣列
// 代碼中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
我先來解釋一下這段代碼,這段代碼實作了一個往陣列中插入資料的功能,當陣列滿了之后,也就是代碼中的 count == array.length 時,我們用 for 回圈遍歷陣列求和,并清空陣列,將求和之后的 sum 值放到陣列的第一個位置,然后再將新的資料插入,但如果陣列一開始就有空閑空間,則直接將資料插入陣列,
那這段代碼的時間復雜度是多少呢?你可以先用我們剛講到的三種時間復雜度的分析方法來分析一下,
最理想的情況下,陣列中有空閑空間,我們只需要將資料插入到陣列下標為 count 的位置就可以了,所以最好情況時間復雜度為 O(1),最壞的情況下,陣列中沒有空閑空間了,我們需要先做一次陣列的遍歷求和,然后再將資料插入,所以最壞情況時間復雜度為 O(n),
那平均時間復雜度是多少呢?答案是 O(1),我們還是可以通過前面講的概率論的方法來分析,
假設陣列的長度是 n,根據資料插入的位置的不同,我們可以分為 n 種情況,每種情況的時間復雜度是 O(1),除此之外,還有一種“額外”的情況,就是在陣列沒有空閑空間時插入一個資料,這個時候的時間復雜度是 O(n),而且,這 n+1 種情況發生的概率一樣,都是 1/(n+1),所以,根據加權平均的計算方法,我們求得的平均時間復雜度就是:
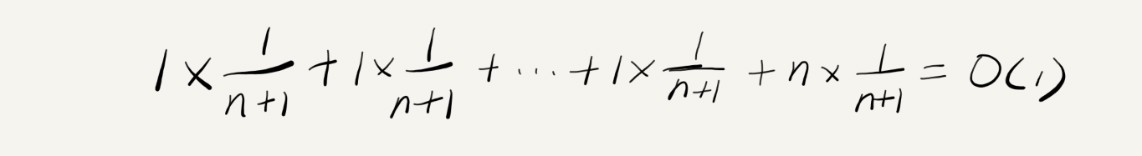
至此為止,前面的最好、最壞、平均時間復雜度的計算,理解起來應該都沒有問題,但是這個例子里的平均復雜度分析其實并不需要這么復雜,不需要引入概率論的知識,這是為什么呢?我們先來對比一下這個 insert() 的例子和前面那個 find() 的例子,你就會發現這兩者有很大差別,
首先,find() 函式在極端情況下,復雜度才為 O(1),但 insert() 在大部分情況下,時間復雜度都為 O(1),只有個別情況下,復雜度才比較高,為 O(n),這是 insert()第一個區別于 find() 的地方,
我們再來看第二個不同的地方,對于 insert() 函式來說,O(1) 時間復雜度的插入和 O(n) 時間復雜度的插入,出現的頻率是非常有規律的,而且有一定的前后時序關系,一般都是一個 O(n) 插入之后,緊跟著 n-1 個 O(1) 的插入操作,回圈往復,
所以,針對這樣一種特殊場景的復雜度分析,我們并不需要像之前講平均復雜度分析方法那樣,找出所有的輸入情況及相應的發生概率,然后再計算加權平均值,
針對這種特殊的場景,我們引入了一種更加簡單的分析方法:攤還分析法,通過攤還分析得到的時間復雜度我們起了一個名字,叫均攤時間復雜度,
那究竟如何使用攤還分析法來分析演算法的均攤時間復雜度呢?
我們還是繼續看在陣列中插入資料的這個例子,每一次 O(n) 的插入操作,都會跟著 n-1 次 O(1) 的插入操作,所以把耗時多的那次操作均攤到接下來的 n-1 次耗時少的操作上,均攤下來,這一組連續的操作的均攤時間復雜度就是 O(1),這就是均攤分析的大致思路,你都理解了嗎?
均攤時間復雜度和攤還分析應用場景比較特殊,所以我們并不會經常用到,為了方便你理解、記憶,我這里簡單總結一下它們的應用場景,如果你遇到了,知道是怎么回事兒就行了,
對一個資料結構進行一組連續操作中,大部分情況下時間復雜度都很低,只有個別情況下時間復雜度比較高,而且這些操作之間存在前后連貫的時序關系,這個時候,我們就可以將這一組操作放在一塊兒分析,看是否能將較高時間復雜度那次操作的耗時,平攤到其他那些時間復雜度比較低的操作上,而且,在能夠應用均攤時間復雜度分析的場合,一般均攤時間復雜度就等于最好情況時間復雜度,
盡管很多資料結構和演算法書籍都花了很大力氣來區分平均時間復雜度和均攤時間復雜度,但其實我個人認為,均攤時間復雜度就是一種特殊的平均時間復雜度,我們沒必要花太多精力去區分它們,你最應該掌握的是它的分析方法,攤還分析,至于分析出來的結果是叫平均還是叫均攤,這只是個說法,并不重要,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/227304.html
標籤:其他
上一篇:0337. House Robber III (M)
下一篇:完全二叉樹的節點個數