單向鏈表簡介
在底層結構上,單向鏈表通過指標將一組零散的記憶體塊串聯在一起,其中,我們把記憶體塊稱為鏈表的“結點”,為了將所有的結點串起來,每個鏈表的結點除了存盤資料之外,還需要記錄鏈上的下一個結點的地址,如下圖所示,我們把這個記錄下個結點地址的指標叫作后繼指標 next,
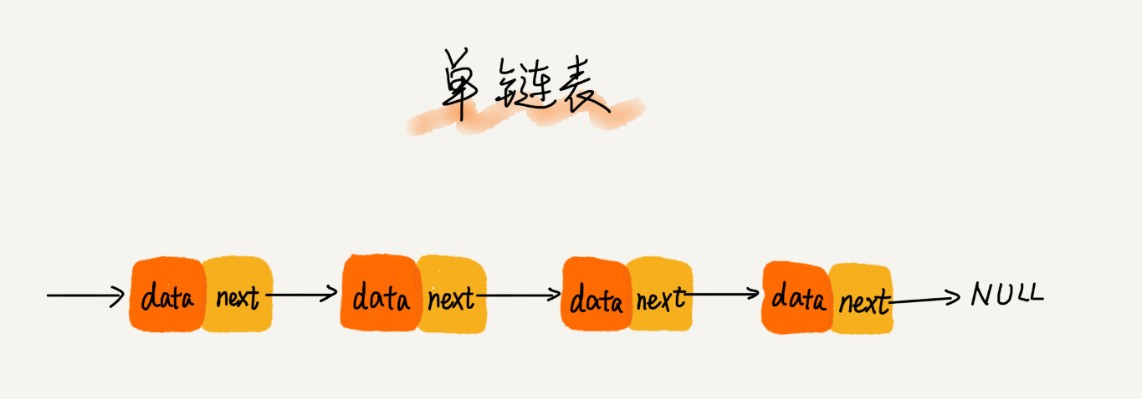
從畫的單鏈表圖中,你應該可以發現,其中有兩個結點是比較特殊的,它們分別是第一個結點和最后一個結點,我們習慣性地把第一個結點叫作頭結點,把最后一個結點叫作尾結點,其中,頭結點用來記錄鏈表的基地址,有了它,我們就可以遍歷得到整條鏈表,而尾結點特殊的地方是:指標不是指向下一個結點,而是指向一個空地址 NULL,表示這是鏈表上最后一個結點,
單向鏈表的增刪改查操作
1. 插入操作
- 頭部插入:時間復雜度O(1)
- 尾部插入:時間復雜度O(1)
- 指定位置后面插入:時間復雜度O(1)
- 指定位置前面插入:時間復雜度O(n)
2. 洗掉操作
洗掉操作的時間復雜度和插入操作的時間復雜度類似,
- 洗掉頭部節點:時間復雜度O(1)
- 洗掉尾部節點:時間復雜度O(n),因為首先需要遍歷鏈表,找到尾部節點的前一個節點(后面分析雙向鏈表時發現就不會有這個問題)
- 洗掉指定節點:時間復雜度O(n)
3. 更新操作
- 更新指定節點:時間復雜度O(1)
- 將鏈表中值等于某個具體值的節點更新:時間復雜度O(n)
4. 查詢操作
- 時間復雜度:O(n)
由于鏈表的底層資料是不連續的,所以不能通過隨機訪問進行資料尋址,只能通過遍歷進行查找資料,
單向鏈表的Java代碼實作
package com.csx.algorithm.link;
public class SinglyLinkedList<E> {
public static void main(String[] args) {
SinglyLinkedList<Integer> list = new SinglyLinkedList<>();
//尾部插入,遍歷鏈表輸出
System.out.println("尾部插入[1-10]");
for (int i = 1; i <= 10; i++) {
list.addLast(Integer.valueOf(i));
}
list.printList();
//頭部插入,遍歷鏈表輸出
System.out.println("頭部插入[1-10]");
for (int i = 1; i <= 10; i++) {
list.addFirst(Integer.valueOf(i));
}
list.printList();
//在指定節點后面插入
System.out.println("在頭節點后面插入[100]");
list.addAfter(100, list.head);
list.printList();
System.out.println("在頭節點前面插入[100]");
list.addBefore(100, list.head);
list.printList();
System.out.println("在尾節點前面插入[100]");
list.addBefore(100, list.tail);
list.printList();
System.out.println("在尾節點后面插入[100]");
list.addAfter(100, list.tail);
list.printList();
System.out.println("------------洗掉方法測驗-----------");
System.out.println("洗掉頭節點");
list.removeFirst();
list.printList();
System.out.println("洗掉尾節點");
list.removeLast();
list.printList();
System.out.println("洗掉指定節點");
list.removeNode(list.head.next);
list.printList();
}
private Node head;
private Node tail;
public SinglyLinkedList() {
}
public SinglyLinkedList(E data) {
Node node = new Node<>(data, null);
head = node;
tail = node;
}
public void printList() {
Node p = head;
while (p != null && p.next != null) {
System.out.print(p.data + "-->");
p = p.next;
}
if (p != null) {
System.out.println(p.data);
}
}
public void addFirst(E data) {
//允許節點值為空
//if(data=https://www.cnblogs.com/54chensongxia/p/=null){
// return;
//}
Node node = new Node(data, head);
head = node;
if (tail == null) {
tail = node;
}
}
public void addLast(E data) {
Node node = new Node(data, null);
if (tail == null) {
head = node;
tail = node;
} else {
tail.next = node;
tail = node;
}
}
/**
* @param data
* @param node node節點必須在鏈表中
*/
public void addAfter(E data, Node node) {
if (node == null) {
return;
}
Node newNode = new Node(data, node.next);
node.next = newNode;
if(tail==node){
tail = newNode;
}
}
/**
* @param data
* @param node node節點必須在鏈表中
*/
public void addBefore(E data, Node node) {
if (node == null) {
return;
}
Node p = head;
if (p == null) {
throw new RuntimeException("node not in LinkedList...");
}
if (p == node) {
Node newNode = new Node(data, node);
head = newNode;
return;
}
while (p.next != null) {
if (p.next == node) {
break;
}
p = p.next;
}
if (p.next == null) {
throw new RuntimeException("node not in LinkedList...");
}
Node newNode = new Node(data, node);
p.next = newNode;
}
public void removeFirst() {
if (head == null) {
return;
}
if (head == tail) {
head = null;
tail = null;
} else {
head = head.next;
}
}
public void removeLast() {
if (tail == null) {
return;
}
if (head == tail) {
head = null;
tail = null;
} else {
Node p = head;
while (p.next != tail) {
p = p.next;
}
p.next = null;
tail = p;
}
}
public void removeNode(Node node) {
if (node == null) {
return;
}
Node p = head;
if (p == null) {
return;
}
while (p.next != null && p.next != node) {
p = p.next;
}
if (p.next != null) {
p.next = node.next;
}
}
private static class Node<E> {
E data;
Node next;
public Node(E data, Node next) {
this.data = https://www.cnblogs.com/54chensongxia/p/data;
this.next = next;
}
}
}
單向鏈表的JDK實作
如果你使用高級編程語言,一般都會有現成的單向鏈表實作,比如你使用的是Java,其中的LinkedList就可以實作單向鏈表功能(雖然LinkedList底層是雙向鏈表,但是雙向鏈表可以實作單向鏈表的所有功能),
有時候你可能只是想實作一個鏈表的結構,并不想暴露太多的操作API給用戶,這時候使用LinkedList可能不太能滿足你的需求,因為LinkedList除了鏈表相關的操作,還暴露了其他的一些介面,這樣可能會給用戶太多的操作權限,
其實這個問題也不是太大,我們是要做下適當的封裝就行了,
package com.csx.algorithm.link;
import java.util.Collection;
import java.util.Collections;
import java.util.LinkedList;
import java.util.Set;
import java.util.function.Predicate;
public class SinglyLinkedList2<E> {
private LinkedList<E> list;
public SinglyLinkedList2() {
this.list = new LinkedList<>();
}
public SinglyLinkedList2(E data){
Set<E> singleton = Collections.singleton(data);
this.list = new LinkedList<>(singleton);
}
public SinglyLinkedList2(Collection<? extends E> c){
this.list = new LinkedList<>(c);
}
// ----------------------------------新增方法---------------------------------------
public void addFirst(E data){
list.addFirst(data);
}
public void addLast(E data){
list.addLast(data);
}
// 在鏈表末尾添加
public boolean add(E date){
return list.add(date);
}
public boolean addAll(Collection<? extends E> collection){
return list.addAll(collection);
}
public boolean addBefore(E data,E succ){
int i = list.indexOf(succ);
if(i<0){
return false;
}
list.add(i,data);
return true;
}
public boolean addAfter(E data,E succ){
int i = list.indexOf(succ);
if(i<0){
return false;
}
if((i+1)==list.size()){
list.addLast(data);
return true;
}else {
list.add(i+1,data);
return true;
}
}
// ---------------------------------- 洗掉方法---------------------------------------
// 洗掉方法,默認洗掉鏈表頭部元素
public E remove(){
return list.remove();
}
// 洗掉方法,洗掉鏈表第一個元素
public E removeFirst(){
return list.removeFirst();
}
// 洗掉方法,洗掉鏈表最后一個元素
public E removeLast(){
return list.removeLast();
}
// 洗掉鏈表中第一次出現的元素,成功洗掉回傳true
// 物件相等的標準是呼叫equals方法相等
public boolean remove(E data){
return list.remove(data);
}
// 邏輯和remove(E data)方法相同
public boolean removeFirstOccur(E data){
return list.removeFirstOccurrence(data);
}
// 因為LinkedList內部是雙向鏈表,所以時間復雜度和removeFirstOccur相同
public boolean removeLastOccur(E data){
return list.removeLastOccurrence(data);
}
// 批量洗掉方法
public boolean removeAll(Collection<?> collection){
return list.removeAll(collection);
}
// 按照條件洗掉
public boolean re(Predicate<? super E> filter){
return list.removeIf(filter);
}
// ----------------------------- 查詢方法----------------------------
// 查詢鏈表頭部元素
public E getFirst(){
return list.getFirst();
}
// 查詢鏈表尾部元素
public E getLast(){
return list.getLast();
}
// 查詢鏈表是否包含某個元素
// 支持null判斷
// 相等的標準是data.equals(item)
public boolean contains(E data){
return list.contains(data);
}
public boolean containsAll(Collection<?> var){
return list.containsAll(var);
}
}
鏈表的使用場景
因為雙向鏈表、回圈鏈表都能實作單鏈表的功能,所以這邊舉例的使用場景不僅僅是針對單鏈表的,使用其他鏈表也可以實作,
鏈表一個經典的鏈表應用場景就是 LRU 快取淘汰演算法,
快取是一種提高資料讀取性能的技術,在硬體設計、軟體開發中都有著非常廣泛的應用,比如常見的 CPU 快取、資料庫快取、瀏覽器快取等等,
快取的大小有限,當快取被用滿時,哪些資料應該被清理出去,哪些資料應該被保留?這就需要快取淘汰策略來決定,常見的策略有三種:先進先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used),
使用單鏈表實作LRU演算法的大致思路是:
維護一個有序單鏈表(鏈表長度有限),越靠近鏈表尾部的結點是越早之前訪問的,當有一個新的資料被訪問時,我們從鏈表頭開始順序遍歷鏈表,
-
如果此資料之前已經被快取在鏈表中了,我們遍歷得到這個資料對應的結點,并將其從原來的位置洗掉,然后再插入到鏈表的頭部,
-
如果此資料沒有在快取鏈表中,又可以分為兩種情況:
- 如果此時快取未滿,則將此結點直接插入到鏈表的頭部;
- 如果此時快取已滿,則鏈表尾結點洗掉,將新的資料結點插入鏈表的頭部,
實作上面演算法的時間復雜度是O(n),
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/228737.html
標籤:其他
上一篇:買賣股票的最佳時機 II
下一篇:資料結構:排序演算法