作者|Behic Guven
編譯|VK
來源|Towards Data Science

在這篇文章中,我將向你介紹一種稱為監督學習的機器學習方法,我將向你展示如何使用Scikit-learn構建kNN分類器模型,
這將是一個實踐演練,我們將能夠在實踐知識的同時學習,作為我們的分類器模型,我們將使用k-NN演算法模型,這將在引言部分進行更多介紹,作為編程語言,我們將使用Python,
閱讀本教程后,你將更好地了解深度學習和監督學習模型的作業原理,
目錄
-
監督學習
-
庫
-
了解資料
-
kNN分類器模型
-
過擬合與欠擬合
-
結論
監督學習
深度學習是一門科學,它使計算機能夠在沒有明確編程的情況下從資料中得出結論,比如學會預測電子郵件是否是垃圾郵件,另一個很好的例子是通過觀察花的圖片將它們分為不同的類別,
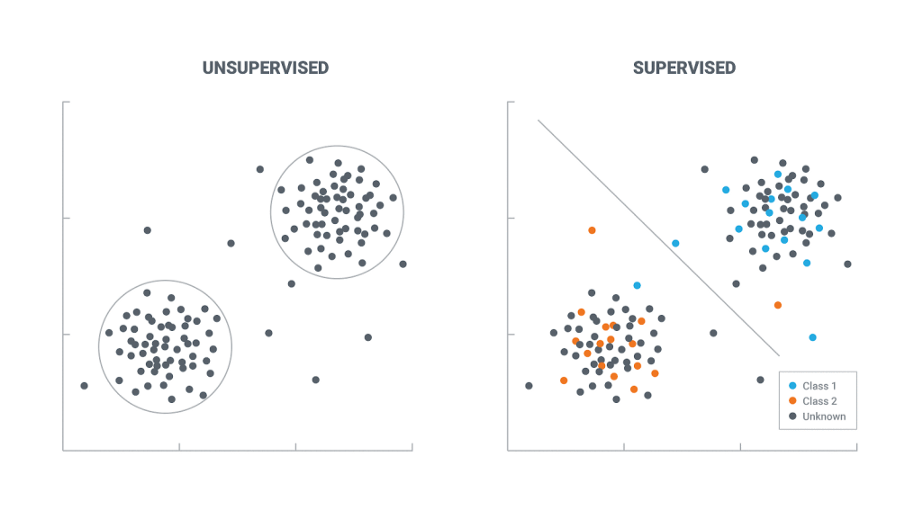
在監督學習中,資料分為兩部分:特征和目標變數,任務是通過觀察特征變數來預測目標變數,監督學習可用于兩種不同的模型:分類和回歸
當目標變數是分類資料集時,可以使用分類模型,
當目標變數是連續值時,使用回歸模型,
庫
在這一步中,我們將安裝本教程所需的庫,正如引言中提到深度學習lib庫的主要知識庫,除此之外,我們將安裝兩個簡單的庫,它們是NumPy和Matplotlib,使用PIP(python包管理器)可以很容易地安裝庫,
安裝庫
進入終端視窗,開始安裝程序:
pip install scikit-learn
現在讓我們安裝其他兩個庫:
pip install numpy matplotlib
匯入庫
很完美!現在讓我們將它們匯入到我們的程式中,以便使用它們,我將在本教程中使用Jupyter Notebook,因此,我創建了一個新的Notebook并匯入了以下庫模塊,
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
了解資料
在本練習中,我們將使用數字資料,它也被稱為MNIST,這是一個著名的資料開始建立一個監督學習模型,這個資料的好處是我們不必下載任何東西;它是隨我們先前安裝的sklearn模塊一起提供的,下面是如何加載資料集:
digits = datasets.load_digits()
現在,讓我們試著對運行幾行的資料集有一些了解,
print(digits.keys)

Bunch是一個提供屬性樣式訪問的Python字典,Bunch就像字典,
print(digits.DESCR)
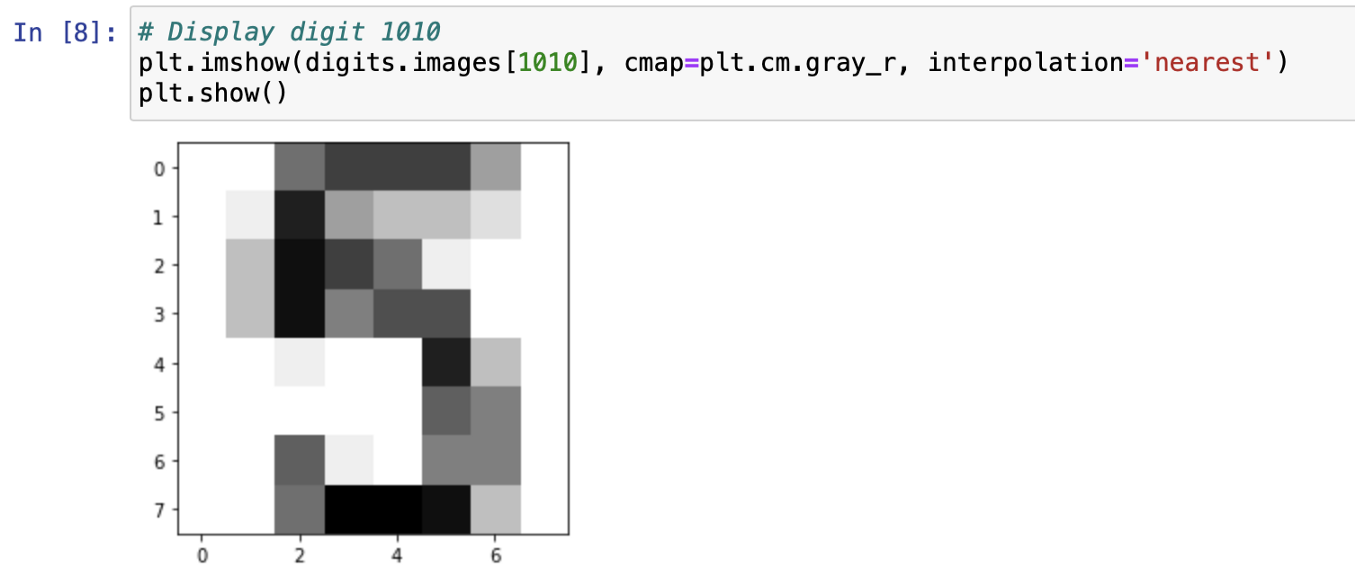
plt.imshow(digits.images[1010], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
K近鄰分類器
在庫步驟中,我們已經在庫步驟中匯入了k-NN分類器模塊,所以,我們要做的就是在我們的資料集中使用它,這一步是在專案中使用sklearn模塊的一個很好的練習,因為我們正在進行監督學習,所以資料集必須被標記,這意味著在訓練資料時,我們也傳遞結果,
k-最近鄰演算法(k-NN)是一種用于分類和回歸的非引數方法,在這兩種情況下,輸入由特征空間中k個最近的訓練樣本組成,輸出取決于k-NN是用于分類還是回歸,”(參考:https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm)
特征和目標變數
我們從sklearn資料集匯入的數字資料有兩個屬性,即data和target,我們首先將這些部分分配給我們的新變數,我們把特征(資料)稱為X和標簽(目標)稱為y:
X = digits.data
y = digits.target
拆分資料
接下來,我們將使用train_test_split方法來分割資料部分,與其對整個資料進行訓練,不如將其拆分為訓練和測驗資料,以審查模型的準確性,這將在下一步更有意義,我們將看到如何使用一些方法改進預測,
#test size 是指將資料集中作為測驗資料的比率,其余將是訓練資料
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=42, stratify=y)
定義分類器
knn = KNeighborsClassifier(n_neighbors = 7)
擬合模型
knn.fit(X_train, y_train)
準確度得分
print(knn.score(X_test, y_test))

我來給你看看這個分數是怎么計算的,首先,我們使用knn模型對X_test特征進行預測,然后與實際標簽進行比較,以下是在后臺實際計算準確度的方法:
y_pred = knn.predict(X_test)
number_of_equal_elements = np.sum(y_pred==y_test)
number_of_equal_elements/y_pred.shape[0]

過擬合與欠擬合
以下是我在Amazon機器學習課程檔案中發現的模型過擬合和欠擬合的一個很好的解釋:
“當模型在訓練資料上表現不佳時,模型對訓練資料的擬合不足,這是因為模型無法捕獲輸入示例(特性)和目標值(標簽)之間的關系,當你看到模型在訓練資料上表現良好,但在評估資料上表現不佳時,該模型會過擬合你的訓練資料,這是因為模型正在記憶它所看到的資料,并且無法將其推廣到未看到的示例中,”(參考:https://docs.aws.amazon.com/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting.html)
現在,讓我們撰寫一個for回圈,它將幫助我們了解資料在不同的鄰居值中的表現,此函式還將幫助我們分析模型的最佳性能,這意味著更準確的預測,
neighbors = np.arange(1, 9)
train_accuracy = np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
for i, k in enumerate(neighbors):
# 定義knn分類器
knn = KNeighborsClassifier(n_neighbors = k)
# 將分類器與訓練資料相匹配
knn.fit(X_train, y_train)
# 在訓練集上計算準確度
train_accuracy[i] = knn.score(X_train, y_train)
# 在測驗集上計算準確度
test_accuracy[i] = knn.score(X_test, y_test)
現在,讓我們用圖形表示結果:
plt.title('k-NN: Performance by Number of Neighbors')
plt.plot(neighbors, test_accuracy, label = 'Testing Accuracy')
plt.plot(neighbors, train_accuracy, label = 'Training Accuracy')
plt.legend()
plt.xlabel('# of Neighbors')
plt.ylabel('Accuracy')
plt.show()
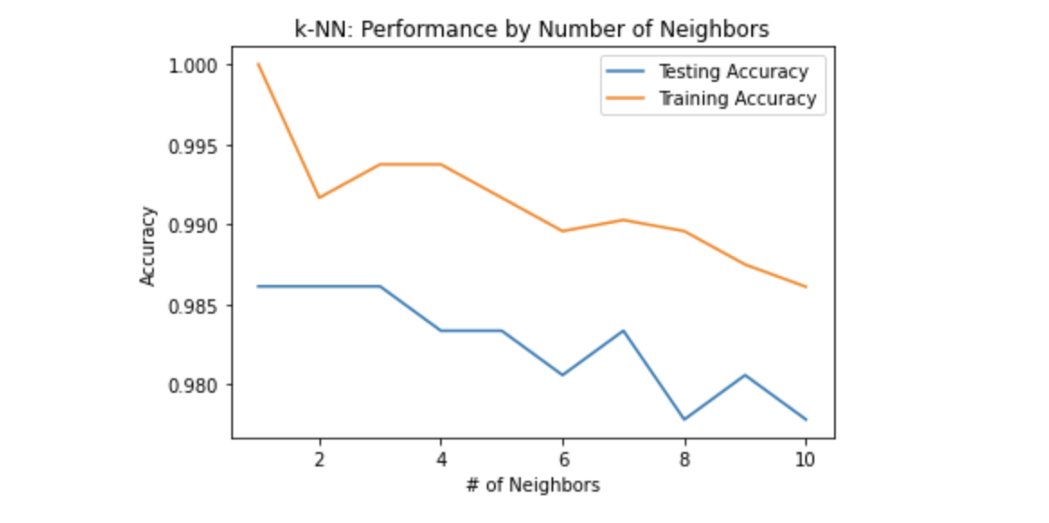
這個圖證明了更多的鄰居并不總是意味著更好的性能,當然,這主要取決于模型和資料,在我們的例子中,正如我們所看到的,1-3個鄰居準確度是最高的,之前,我們用7個鄰居訓練了knn模型,得到了0.983的準確度,所以,現在我們知道我們的模型在兩個鄰居的情況下表現更好,讓我們重新訓練我們的模型,看看我們的預測將如何改變,
knn = KNeighborsClassifier(n_neighbors = 2)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))

結論
很完美!你已經使用scikit learn模塊創建了一個監督學習分類器,我們還學習了如何檢查分類器模型的性能,我們還學習了過擬合和欠擬合,這使我們能夠改進預測,深度學習是如此有趣和神奇,我將分享更多深入學習的文章,敬請期待!
原文鏈接:https://towardsdatascience.com/the-beginners-guide-to-supervised-learning-and-knn-classification-87061b044904
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/228771.html
標籤:其他