論文題目:《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》
論文鏈接:https://arxiv.org/pdf/1708.05234.pdf
年份:2017
論文作者:Shifeng Zhang等人
作者單位:中國科學院自動化研究所等
公眾號CVpython同步發布
1. 論文要解決什么問題?
要保持高精度,還要在CPU上達到實時?還真有點難,但是Shifeng Zhang等人針對這個問題,提出了人臉檢測模型FaceBoxes,表現SOTA,
2. FaceBoxes如何解決問題?
FaceBoxes框架如圖1所示,主要包括Rapidly Digested Convolutional Layers (RDCL)和Multiple Scale Convolutional Layers (MSCL)模塊,還有anchor密集策略,
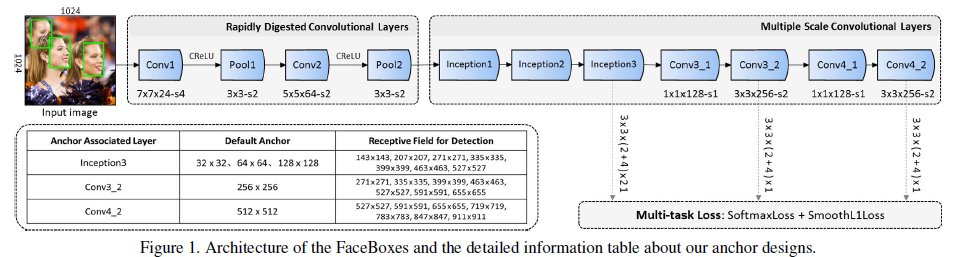
2.1 RDCL
RDCL的目的是為了快速下采樣,讓模型能夠在CPU上面能達到實時,RDCL采用的方法是縮小空間大小,選擇合適的卷積核大小和減少輸出通道,
- 縮小空間大小:Conv1, Pool1, Conv2 and Pool2 的步長分別是4, 2, 2和 2, 空間大小快速降低了32倍,
- 合適的卷積核大小:前幾層的一些核應該是比較小,以便加速,但是也應該足夠大,以減輕空間大小減小而帶有的資訊丟失(為什么可以減少資訊丟失s),Conv1, Conv2的核大小為7x7, 5x5,所有池化層的核大小為3x3,
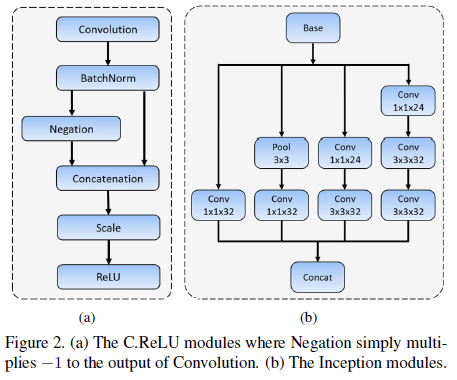
- 減少輸出通道:使用C.ReLU減少輸出通道,操作如圖2(a)所示,因為C.ReLU作者統計發現底層卷積時卷積核存在負相關,也就是說假設我們本來使用10個卷積核,但是現在只需要用5個卷積核,另外5個卷積核的結果可以通過負相關得到,結果表明使用C.ReLU加速的同時也沒損失精度,
2.2 MSCL
MSCL是為了得到更好地檢測不同尺度的人臉,
- 深度:在MSCL模塊中,隨著網路的加深,便得到不同大小的特征映射(多尺度特征),在不同大小特征映射中設定不同大小的anchor,有利于檢測不同大小的人臉,
- 寬度:Inception由多個不同核大小的卷積分支組成,在這些分支中,不同的網路寬度,也有不同大小的特征映射,通過Inception,感受野也豐富了一波,有利用檢測不同大小的人臉,
MSCL在多個上尺度進行回歸和分類,在不同尺度下檢測不同大小的人臉,能夠大大提高檢測的召回率,
2.3 Anchor密度策略
Inception3的anchor大小為32,64和128,而Conv3_2和Con4_2的anchor大小分別為256,512,anchor的平鋪間隔等于anchor對應層的步長大小,例如,Con3_2的步長是64個像素點,anchor大小為256x256,這表明在輸入圖片上,每隔64個像素就會有一個256x256的anchor,關于anchor的平鋪密度文中是這樣定義的:
$$
A_{density}=A_{scale}/A_{interval}
$$
其中$A_{density}$和$A_{interval}$分別為anchor的尺度和平鋪間隔,默認的平鋪間隔(等于步長)默分別認為32,32,32,64和128,所以Inception的平鋪密度分別為1,2,4,而Con3_2和Con4_2的平鋪密度分別為4,4,
可以看出來,不同尺度的anchor之間存在平鋪密度不平衡的問題,導致小尺度的人臉召回率比較低,因此,為了改善小anchor的平鋪密度,作者提出了anchor密度策略,為了使anchor密集n倍,作者均勻地將$A_{number}=n^2$個anchor鋪在感受野的中心附近,而不是鋪在中心,如圖3所示,將32x32的anchor密集4倍,64x64的anchor密集兩倍,以保證不同尺度的anchor有相同的密度,
2.4 訓練
資料擴增:
- 顏色扭曲
- 隨機采樣
- 尺度變換
- 水平翻轉
- Face Boxes過濾:經過資料擴增的圖片中,如果face boxes的中心還在圖片上,則保留重疊部分,然后把高或者寬<20的過濾掉(這個操作不是很懂了,為什么把小目標過濾掉?)
匹配策略:訓練期間,需要確定哪些anchor對應臉部的bounding box,我們首先用最佳jaccard重疊將每一張臉匹配到anchor,然后將anchor匹配到jaccard重疊大于閾值的任何一張臉,
Loss function: 對于分類,采用softmax loss,而回歸則采用smooth L1 損失,
Hard negative mining:anchor 匹配后,發現很多anchor是負的,這會引入嚴重的正負樣本不平衡,為了快速優化和穩定訓練,作者對loss進行排序然后選擇最小的,這樣子使得負樣本和正樣本的比例最大3:1,
3 實驗結果如何?
Runtime
Evaluation on benchmark
在FDDB上SOTA,
4.對我們有什么指導意義?
- 要在CPU上達到實時,考慮一開始就對特征進行快速下采樣,
- 在淺的卷積層考慮使用CReLU,可以減少計算量,
- MSCL告訴我們,檢測各種不同大小的物體,考慮從深度和寬度上豐富感受野,
- anchor密度策略告訴我們考慮anchor密度以提高召回率,
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/228772.html
標籤:其他
上一篇:監督學習和kNN分類初學者教程