
同學們好,我是來自 《技術銀河》的 💎 三鉆 ,
大家可能覺得 KMP 這個演算法的名字很特別、很怪,因為 KMP 它并不是三個英文單詞的開頭,而是三個計算機科學家的名字,發明這個演算法的三位計算機科學家分別為:Knuth、Morris、Pratt,第一個是大家都非常熟悉的 Donald Ervin Knuth (高德納),他是《計算機設計藝術》的作者,也是編程界非常有名的一位老專家,然后 M 和 P 也都是當時比較著名的計算機專家,而 KMP 匹配演算法就是他們三個一起研究出來的 ,
什么是 KMP 演算法?
快速的從一個主串中找出一個你想要的子串—— 這里面的主串就是source 串,而要尋找的子串就是pattern 串也叫模式串,
如果我們先不考慮 KMP 演算法,我們用一個最樸素的演算法,在演算法里面經常用到的 Brute-Force(BF) ,這個在歷史上也是有一個演算法的名稱的,就是我們的 “暴力解”,
那么我們怎么使用暴力破解來匹配我們的字串呢?這里我們需要在一串字符的開始,逐個去與我們的模式串中的字符比對,如果我們能找到一段連續的字符與我們整個模式串中的字符完全匹配的,那么我們可以認為,這串字符中存在與我們模式串的字符一致的字符,這種演算法的時間復雜度就是 m 乘以 n的,m 的長度就是原串的長度,而 n 就是模式串的長度,
這種非常高時間復雜度的演算法,對我們程式的性能肯定是有嚴重影響的,所以我們的計算機科學家經過一定的研究發現,通過一些演算法的技巧,我們是可以把時間復雜度降到 O(m + n) ,這個就是三個科學家發明的 KMP 的演算法,
接下來我們一起來看一下,KMP 匹配演算法到底是怎么做的,
KMP 演算法匹配程序
我們先來一個簡單的例子,假設現在我們有兩串字符:
- 主串 (source):ABABABABABAAABABAA
- 模式串 (pattern):AAAB
KMP 演算法最終的目的就是在我們主串中,找到與我們模式串匹配的子串,看看以下動態效果:

里面紅色部分的就是我們的 主串,而我們的藍色部分就是我們的 模式串,我們快速的在主串中找到了 AAAB 這個子串,而它是與我們的模式串完全匹配的,這里最重要的點就是 “快速”,KMP 演算法就是為了可以快速找到我們在主串中的子串,
我們先來了解一下 “不快” 的方式是怎么做的,其實暴力破解法,一般都是比較直觀的,也是比較容易可以想到的,
確實不是很難想到,我們暴力破解無非就是讓主串和模式串中的所有字母逐個對比和匹配,如果遇到不匹配的,就讓模式串順延整體回到開頭字母的下一個的位置,重新開始逐個匹配,以此類推,最后要不我們找到了能匹配上的子串,要不就走到了盡頭代表主串中沒有可以匹配上模式串的字串,
好,我們來看看效果圖:

這種演算法確實很直觀對吧?這里我們要注意一個點,就是在第一輪匹配的程序中,當我們遇到不匹配的字符的時候,我們的指標
i和j都會挪動到主串的第二個位置,這個動作我們就叫做比較指標回溯,那么"回溯" 就是導致這個簡單的演算法效率比較低的主要原因,
那么我們應該怎么做才能達到我們所說的 “快” 速查找呢?

毋庸置疑,肯定是使用我們的 KMP 演算法,KMP 演算法可以做到僅僅后移模式串,比較指標不回溯!聽起來是不是很牛?那么我們來看看是怎么做到的,
我們回到剛剛發現某一個字符不匹配的狀態:

這里我們模式串是在 A 的位置,而我們的主串是在 B 的位置,很明顯這里是不匹配的,如果我們細心觀察一下前面的 5 個字母中,我們會發現兩個重要的現象:
- 主串和模式串的這一段字符是匹配的,兩個都是
ABBAB - 模式串左右兩端有兩個子串
AB是完全一致的,這兩個字串我們稱之為模式串的公共前后綴
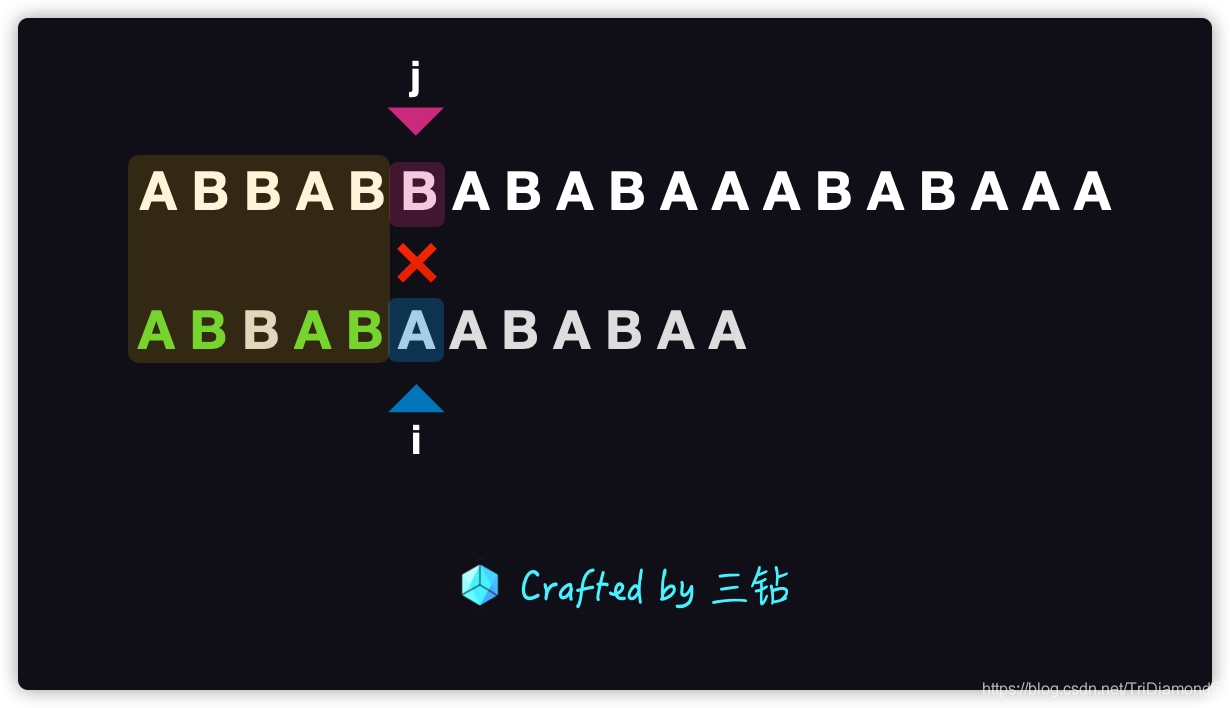
根據這兩點,我們就可以使用 KMP 演算法中的技巧了,這個也是 KMP 演算法的核心,只要理解了它整個演算法我們就理解了,我們直接把模式串前綴 AB 的位置直接移動到,模式串后綴所在的位置,

這樣一移動我們就可以保證我們當前指標匹配的字符前面的字串是上下匹配的,也就是說,我們這種移動的方式,可以確保我們 復用 部分的字符是匹配的,在我們例子里面,移動后我們前面的 AB 在主串和模式串中是匹配的,那么為什么會有這樣的現象呢?其實就是因為我們的公共前后綴是匹配的,移動后還是可以匹配的,
那么嚴謹的同學就會有疑問了,我們這么一下子把模式串移到這個位置,那么我們會不會錯過了一些其他匹配的情況呢?我可以很負責任的說,移動前和移動后之間的兩個位置中,是沒有任何可匹配成功的情況,

保持質疑的態度,是一個程式員的基本素養,那么我們來逐個走一篇看看吧,

通過上面的效果圖,我們可以看到,從一開始一直移動過來,在到達我們模式串公共后綴的位置之前都是沒有能匹配上的,這樣也證明了我們上面所說的結果,
上面講的是一種特殊的情況,那么我們來看看一般情況下是怎么樣的,在我們特殊例子中發現了一個特點,在匹配的程序中當我們到達了匹配失敗的字符的位置時,模式串的這個位置之前的所有字符都是與主串能匹配的,然后我們是在這段能匹配的字串里面找 公共前后綴的,也就說我們其實只需要分析 模式串就可以了,因為我們分析的這段字串是完全與主串一致的,
我們來舉一個更通用的例子,比如我們現在有一串字符AB ... ... ABX ... ..., 這里面 ... 代表著多個任意字符,而 X 代表的就是跟隨在 AB 這個公共后綴的字符,X 也能理解為模式串和主串第一個匹配失敗的位置,
這個時候我們只需要把 公共前綴 移到 公共后綴所在的位置,就可以繼續往后匹配了,這個就是我們剛剛例子里面所講到的,那么我們也證明了前綴和后綴之間是不會有可以匹配上的情況的,那么如果有,證明我們選擇的 公共前后綴 不是最長的公共前后綴,
什么意思呢?就是在匹配失敗的位置前面的字符當中,還有更長的前后綴,這里我們就引出了一個 最長公共前后綴 的概念了,
最長公共前后綴就是 —— 當我們分析的字串中有多個公共前后綴時,我們要取最長的公共前后綴,
到這里 KMP 演算法的概念我們就講完了,接下來我們一起把上面的例子的匹配程序走完,我們就來看一段影片了解一下剩余的匹配程序吧 ~

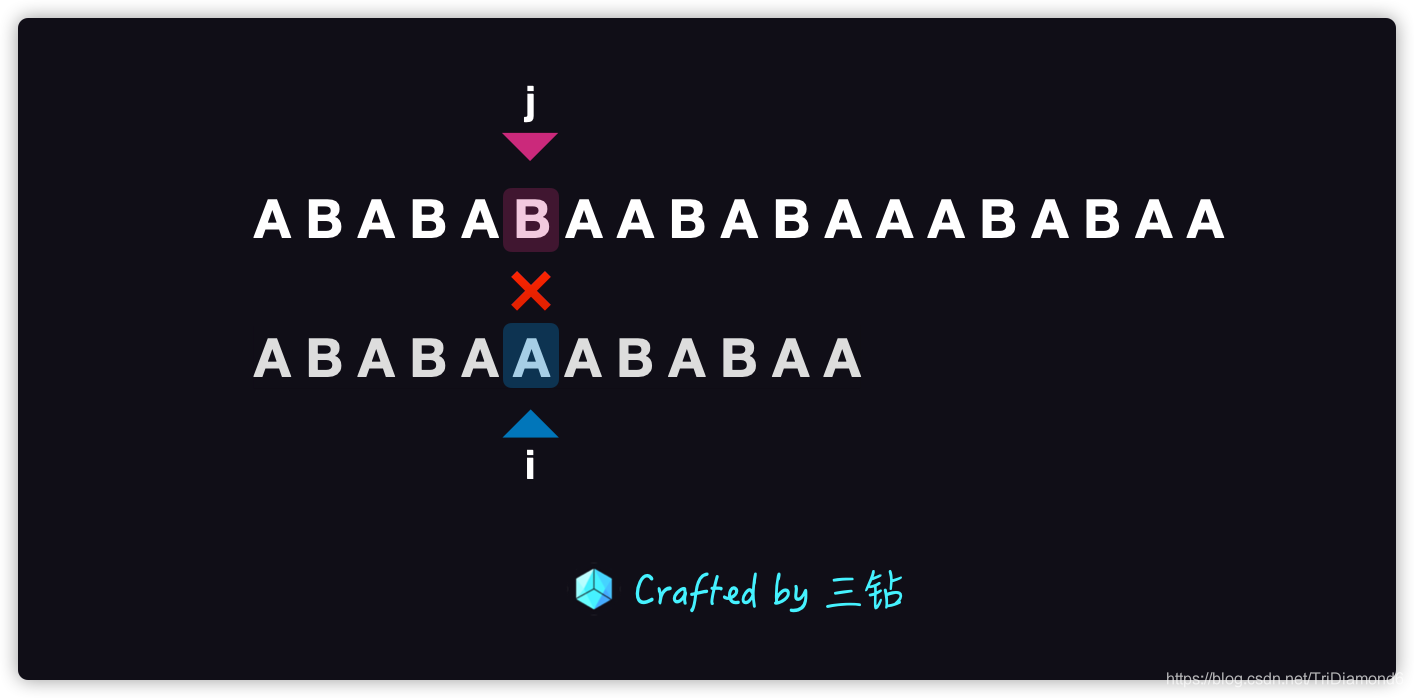
上面的影片中,我們從第二次匹配的位置開始:
- 因為根據上面的邏輯我們已經把公共前綴
AB移動到了后綴的位置,所以我們就可以繼續逐個字符繼續匹配 - 匹配到主串的
B和模式串的A的時候,就發現匹配又失敗了 - 這個時候我們去看這個模式串
A前面已經匹配過的字符ABBABA,這串字符中只有前后綴A - 所以最后我們讓模式串從前綴
A移動到后綴A的位置 - 這個時候我們發現我們的模式串長度已經超出了主串的長度,所以這里就說明主串中沒有可以匹配這個模式串的子串,
顯然這種匹配方法,要比我們的 “暴力解” 的方法的比較次數要少的多,自然我們的演算法的效率就會高的多,
接下來我們再看一個例子:
- 主串:
ABABABAABABAAABABAA - 模式串:
ABABAAABABAA
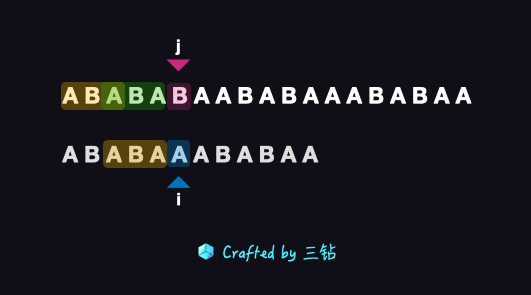
首先我們把兩個字串在左邊頭部對齊,然后我們開始逐個比較主串和模式串中的字母,
到了第六個字母的時候,我們發現不匹配的情況,這個時候我們就開始分析前面匹配過的字串 ABABA,這里我們需要找到最長的 公共前后綴,找最長前后綴的最佳方法就是從兩個末端往內延伸,

在我們上面的這個影片中,我們可以看到我們是怎么尋找最長前后綴的,在這個程序中我們找到了 3 對前后綴:
- A 和 A
- ABA 和 ABA
- ABABA 和 ABABA
這三對前后綴都是完全匹配的,但是第三對是一個無效的前后綴,因為它的長度與我們這串字符的長度是一樣的,那么就意味著我們完全不需要移動,就可以從前綴挪動到后綴的位置,這樣的話對我們進入下一個匹配沒有任何意義,所以只有第一和第二對前后綴是有效的,
通過上面的例子中,我們就可以給尋找公共前后綴加上一個約束條件:
我們需要找最長的,并且長度要小于錯誤位置左端子串長度的公共前后綴,
因為我們需要的是 最長公共前后綴,所以第二組的 ABA 是最適合的,
找到了最長公共前后綴之后,我們就可以把模式串的位置從前綴的位置挪動到后綴所在的位置,然后繼續往后匹配字符,
逐個掃描后我們在模式串第 7 個字母又發現了不匹配,這個位置的右邊的字串就是 ABABAA,通過 “上帝視角”,我們一看就能看到這個子串里面只有一對公共前后綴,那就是 A 和 A,
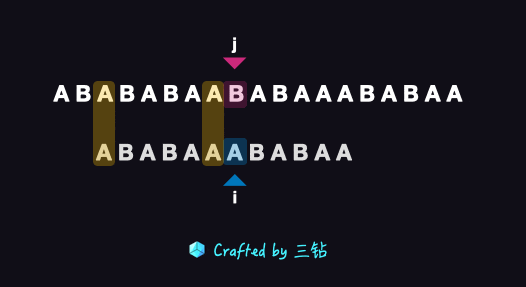
與之前的做法一樣,首先把公共前綴的位置挪動到公共后綴的位置,然后繼續往后匹配,匹配到最后我們會發現我們在主串中找到一個子串是與模式串完全一致的,這個就得出一個結果,我們的主串中是有我們需要的字串的(也就是含有我們的模式串的),
一般我們的字串都是存在一個字符陣列中,而陣列在記憶體中是不可能移動的,所以剛才我們演示的例子都是形象化的程序,我們還需要轉化為計算機方便處理的方式,
KMP next 陣列
既然我們知道在實際代碼中,我們是無法移動陣列位置的,那么我們就需要把這個概念轉化成代碼可以執行的邏輯,
首先我們要理解一個概念,在我們上邊的演算法匹配程序中,我們知道一直在移動的都是我們的 模式串而我們的主串都是沒有任何變動的,所以在 KMP 演算法的匹配中,最關鍵的運算和變化都是在我們的 模式串 之中,
換句話說我們只需要研究模式串,并且把它的相關資訊挖掘出來,然后用它就可以跟任何字串做匹配了,
我們先用一個例子來了解一下我們需要怎么研究一個模式串,并且把它的資訊挖掘出來的,
這里我們就用我們之前例子中的 ABABAAABABAA,
首先我們給這個字串加上下標,方便我們分析:

注意: 這里我們是從下標 0 開始儲存的,而很多學校教 KMP 演算法的時候,習慣從下標 1 開始儲存,但是在代碼中,大多資料結構都是從下標 0 開始的,如果我們用了從 1 開始,在寫代碼的時候就會容易混亂,(個人覺得這也是讓本來比較簡單的 KMP 演算法,變得很難理解的一個原因,有一些教程是從 0,有一些教程是從 1,然后在寫代碼的時候陣列又是從下標 0 開始的,最后搞得我們腦殼疼,掉頭發,)
不過就算我們要從下標
1開始,那我們的匹配串和模式串都要從下標 1 開始,要不我們的 next 陣列就是錯亂的,**這里為了大家更好理解,而且更接近代碼中的原本的資料結構,我們就統一都從下標0開始, **
好,那么我們開始分析這個模式串吧,
首先我們假設這個模式串是可以與任何一個主串用 KMP 演算法匹配的,那么這個模式串中的每一個字符的位置都有可能發生不匹配的,
但是我們重點要看的是,任何一個位置發生不匹配時,前面那一串字符的公共前后綴長度,從而我們可以獲得我們需要回移動模式串的位置,
下標 0 位置
首先模式串的下標 0 的位置,我們是不需要去計算 next 數值的,因為這個位置的字符長度為 1,是無法獲得一個最長公共前后綴的,因為 最長公共前后綴的長度必須小于子串自身的長度
所以第一位字符的 next 數值必定是
0,
下標 1 位置
接下來我們往后看,如果是模式串下標 1 這個位置后面的字符發生匹配失敗,

- 下標 0 到當前下標的字符是
ab - 很明顯這里是沒有公共前后綴的
- 也就是說最長公共前后綴是
0
所以下標
1的 Next 數值就是0,
下標 2 位置
接下來我們看看下標 2 位置后面發生匹配失敗時的情況,

- 下標 0 到當前下標的字符是
aba - 這里我們就發現
a是這個段字符的公共前后綴 - 而這個前后綴的長度是
1
所以下標
2的 Next 數值就是1,
下標 3 位置

- 下標 0 到當前下標的字符是
abab - 這里的公共前后綴就是
ab - 它的長度就是
2
所以下標
3的 Next 數值就是2,
下標 4 位置

- 下標 0 到當前下標的字符是
ababa - 公共前后綴是
aba - 它的長度是
3
所以下標
4的 Next 數值就是3,
下標 5 位置

- 下標 0 到當前下標的字符是
ababaa - 公共前后綴是
a - 它的長度是
1
所以下標
5的 Next 數值就是1,
N 位匹配規則
這里我們分析了 5 個下標的 Next 數值,我們顯然可以發現一個規律,每一個位置的 Next 數值其實就是,字串開頭到當前位置的字符中的公共前后綴長度,
所以我們把剩余的 Next 數值都寫下來看看,
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| String | a | b | a | b | a | a | a | b | a | b | a | a |
| Next | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 4 | 5 | 6 |
這個就是我們經常在 KMP 演算法中聽到的
Next 陣列了,
其實很多地方又稱這個為 prefix 前綴陣列或者 PMT 陣列,因為它對應的值,代表的是前字串中的公共前后綴長度,但是 Next 陣列在代碼中需要起到的作用就是 “挪動前綴到后綴所在的位置”,
要做到這個,我們就需要知道在每一個位置,我們前綴最后一個字符的下標位置,很奇妙的是,當前我們的 Next 陣列中的每一個陣列的前面一個就是我們前綴最后一個字符的位置的下標值,
所以我們只需要把現在的 Next 陣列的所有數值整體往右挪動一位即可獲得我們真正想要的 Next 陣列,
有了這個 Next 陣列 我們就可以根據這個陣列所提供的資訊,在我們模式串任意一個位置發生不匹配時就能找到下一個匹配的位置,
然后我們發現下標 0 的位置就空了,沒有數值了,所以我們一般都會給下標 0 位置賦予 -1,
最后我們就會得到這樣的資料:
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| String | a | b | a | b | a | a | a | b | a | b | a | a |
| Prefix/PMT | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 4 | 5 | 6 |
| Next | -1 | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 4 | 5 |
代碼實體
接下來我們一起來看看 KMP 的代碼應該怎么寫,首先 KMP 它肯定是一個 function 并且會接收兩個引數,一個是 source 一個是 pattern,分別代表的是 主串 和 模式串,
然后我們的處理會分成兩個部分,第一部分我們就是計算 Next 陣列,而第二部分才是匹配,
計算 Next 陣列
根據我們上面的 KMP 演算法的推理邏輯,要算出 Next 陣列來做匹配,我們首先就要找到每一個位置的前面字符的最長公共前后綴,而這個資料就是 prefix 前綴陣列,
在尋找前后綴的時候,如果我們用 “上帝視角:我們聰明的大腦” 去分析的話,我們是比較容易可以看出一段字符中最長的公共前后綴的,但是對計算機來說,就需要笨拙一點的方法,挨個去比對,而且要寫成代碼,真的不是那么容易,那怎么辦呢?
就像我們解答演算法題一樣,遇到一個復雜的問題的時候,就試著在復雜的問題里面找簡單的規律,從而就能讓我們對這個題目做到降緯打擊的效果,也就是 “復雜的問題簡單化” 的效果,
我們就用上面理論里面講到的例子 ababaaababaa,首先我們把它每一個匹配字符前面的那一段字符拆出來,并且列出它的公共前后綴,然后找找這里面有沒有什么規律:
- ab :0
aba:1abab:2ababa:3 (aba, aba)ababaa:1ababaaa:1ababaaab:2ababaaaba:3ababaaabab:4ababaaababa:5
在這里,我們可以找到什么規律呢?其實有的,我們拿 aba 和 abab 這兩段字串來看看,首先我們知道 aba 的公共前后綴是 a,公共前后綴長度是 1,假設我們想讓它的最長公共前后綴長度變成 2 的話,我們只要在 aba 的后面加一個 b 就可以了,
所以換一種思維方式,是不是在 aba 的基礎上,我們只需要判斷它接下來的字符是不是 b 就知道下一段的字符最長公共前后綴的長度呢?
如果 aba 接下來的字符是 b ,下一段字符的公共前后綴必然就是當前最長公共前后綴 + 1,也就是 1+1=2,好,我們來確認這個規則是不是對的!
我們拿 ababaaa 這一段來測驗一下,ababaaa 它的最長公共前后綴就是 a, 長度為 1,它前綴最后一個字符的后面,是一個 b,根據我們剛剛的邏輯,如果 ababaaa 的下一個字符是 b 的話,那么最長公共前后綴就可以變成 ab,長度為 2,
果不其然,下一個字符就是 b,而且真的是長度為 2,所以現在的字符是 ababaaab,公共前后綴是 ab,長度為 2,完美,我們找到第一個規律了!
我們來把這個規律總結一下,我們要用公共“前綴”的下一個字符,與我們公共“后綴”的下一個字符做比對,如果它們是一樣的,那么我們下一段字符的最長公共前后綴就是
當前最長公共前后綴 + 1,
整個邏輯就如下面的影片一樣:

這個影片里面的 j 指向的就是我們公共前綴的末尾字符,而 i 指向的就是我們公共后綴的末尾字符,
細心的同學應該會注意到,其實剛剛說的
當前最長公共前后綴長度 + 1,如果換成是與j所在位置的話,也可以理解為j 所在下標 + 1,我們會發現這個規則也是相同的,(為什么這里又提到這一點呢?因為這個規則更利于我們寫成代碼,)
那么如果下一個字符是不匹配的呢?好家伙,這個是一個好問題!沒關系,我們的例子中也有這樣的情況,我們把它們拿出來分析一下,相信我們強大的大腦總能看出一些蛛絲馬跡!
那么我們就把 ababa 和 ababaa 單獨拿出來看一下,首先 ababa 有一個公共前后綴為 aba,長度為 3,那么如果 ababa 下一個字符出現的是 b,我們就能有一個長度為 4 的公共前后綴了,可惜事實并不會那么容易放過我們,下一個字符是 a,所以這里就出現與我們剛剛講的場景恰好相反的情況,
“------------ ~ 2 個小時之后 ~ -------------”
怎么辦呢?找不到規律呀!!

大家不要誤會,我不是很苦惱,只是頭皮發麻,所以需要整理一下頭發,這也不是程式員經常掉頭發的原因,請不要多想哦~
嗯哼~ 回歸正題,既然想不到辦法了,那么我們就把整個模式串每一個位置對應的最長公共前后綴列成表格,說不定我們就能看破天機了!
| 下標 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符 | a | b | a | b | a | a | a | b | a | b | a | a |
| prefix | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 4 | 5 | 1 |
| pos | - | - | - | j | - | i | - | - | - | - | - | - |
上面的表格中,我們標記了兩段字串中的最后一個字母的位置,同時我們也標記了當前 j 和 i 的位置,這里我們可以看到:
- ab
aba 的公共前后綴是 aba,那么前綴最后一個字符在下標 2 的位置 ababaa 的公共前后綴是 a, 那么前綴最后一個字符是在下標 0 的位置
同學們,有沒有發現什么?其實我們 ababaa 與 ababa 的區別就是這個下標,也就是說如果我們的 j 回溯到下標 0 的位置,我們 j 和 i 指向的字符就是一致了,然后如果 j 回溯到了 0,那么我們又可以使用剛剛分析出來的規則,j 的下標 + 1 = 下一串字符的公共前后綴的長度,
所以這里我們 j 指標回溯(回退)后就是在 0 下標的位置,而下一段字串的最長公共前后綴就是 0 + 1 = 1,哇~出來啦!這就對了!
這里我們只知道我們 j 是需要回溯(回退)到更前面的下標,但是畢竟我們要把這個邏輯寫成代碼,那么必須就要有 “規律可尋” 才行,我們再回去看看上面的表格,我們發現 j 指向我們 prefix(前后綴) 的值是 2,那么我們是不是可以用當前 j 下標的 prefix 值替換當前 j 的位置呢?這樣我們就可以讓 j 回溯到更前面的位置了,
首先我們要知道,我們的 prefix 表中的值,代表的是從頭到當前位置的字串中,所擁有的最長公共前后綴的長度,當前我們 j 所在位置指向的 prefix 值是 2,對應的公共前后綴是 ab,如果我們用這個值去挪動 j 的位置,那么 j 就會指向第三位字符 a,也就是 aba 中的第二個 a 這個位置,
根據我們剛剛整理出來的第一個規則,我們用當前 “公共前后綴” 后面的一個字符與 i 指向的值做匹配,那么現在如果 j 挪動到下標 2 的位置的話,我們來看看它前面的字符是什么?
| 下標 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符 | a | b | a | b | a | a | a | b | a | b | a | a |
| prefix | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 4 | 5 | 1 |
| pos | - | - | j | - | - | i | - | - | - | - | - | - |
我們可以看到,j 前面的字串是 ab,很顯然 ab 并不是我們現在 ababaa 這段字符中的公共前后綴,所以這樣挪動 j 的位置是不妥的,所以我們還需要換一種策略,
我們目標很簡單,就是讓 j 回溯到正確的位置,如果當前對應的 prefix 值不行,那么我們拿 j-1 的 prefix 值呢?
j-1 的值,其實就是上面表格中 j 現在對應的 prefix 的值,也就是 1,
| 下標 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符 | a | b | a | b | a | a | a | b | a | b | a | a |
| prefix | 0 | 0 | 1 | 2 | 3 | 1 | 1 | 2 | 3 | 4 | 5 | 1 |
| pos | - | j | - | - | - | i | - | - | - | - | - | - |
這時候我們發現這個 j 的位置對應的字串公共前綴是對的了,說明我們這種 j 的回溯方法是對的,但是我們又發現 j 位置對應的字符與 i 現在對應的字符不對等,
既然 j 回溯的策略是對的,我們這個時候我們用同樣的方式再次讓 j 回溯,往前挪動它的位置,這個時候 j-1 的位置就是下標為 0 的位置了,
這個時候,j 指向的字符與 i 指向的字符就一致了,用我們之前的規則,這個時候 i 所在位置前面的字串的最長公共前后綴就是 0 + 1 = 1,
我們發現我們獲得的值就對了,所以有了這規律,我們就可以算出 prefix 表的資料,也就是每一個位置前面的字符擁有的公共前后綴長度,然后我們就可以通過這個 prefix 表獲得我們的 next 陣列,
我們來總結以下這兩條規則:
i從 1 下標開始,j從 0 下標開始,依次匹配彼此位置對應的字符,如果相同,證明 i 當前位置前面的字符擁有一個公共前后綴長度為j 下標值 + 1- 如果
i和j對應的字符不匹配,那么 j 就會回溯到更前面的位置找尋一個匹配的字符,回溯的規則為prefix[j-1],
這里需要特別注意的是,如果我們的
j已經回溯到下標為 0 的時候,還是沒有找到公共前后綴,那我們就要停止j繼續回溯了,并且也證明這段字串沒有公共前后綴,
講了那么多,理論是整理清楚了,接下來看看代碼我們應該怎么去實作,
根據上面的理論分析,我們首先需要計算出 prefix 前綴陣列,然后在 prefix 陣列的所有值往右挪動一位即可獲得我們的 Next 陣列,
在生成 Next 陣列這里我們會用一個 next 變數來儲存資料,根據我們上面分析出來的 Next 陣列,它的長度肯定是和我們模式串的長度一致的,所以我們創建 Array 的時候就直接給 table 填好資料,這里我們都填入 0 即可,
function kmp (source, pattern) {
// 計算 Next 陣列
let next = new Array(pattern.length).fill(0);
// 尋找模式串中的公共前后綴
let i = 1,
j = 0;
}
按照我們之前講的,下標 0 號位,我們是不需要分析它的 next 值的,所以我們的 i 可以直接從 1 下標開始,這里 i 默認值是 1, j 默認值是 0,
接下來我們就可以開始回圈我們的模式串,這里我們使用一個小技巧,在上面講理論的時候,我們是先計算出 prefix 前綴資料,然后通過把所有的值整體往右挪動一位,獲得我們的 next 陣列,
但是其實在我們回圈的程序中,就可以做到這一點,每次我們比對 i 和 j 對應的值的時候,如果我們發現匹配成功,我們就把 對應的 prefix 值,放到當前下標下一個位的位置,也就是 next[j+1],這樣我們就一定把所有 prefix 值往右挪動了一位,也就不需要在后面再統一挪動一次了,
好,有了這個技巧,我們就可以快樂去撰寫 Next 陣列的生成代碼啦~
這里我們就運用剛剛分析出來的兩條規則來處理兩種情況,第一種就是 i 對應的字符與 j 對應的字符相同,這個時候我們就知道 prefix 值就是 j + 1,
我們知道了 prefix 值,根據上面所說的技巧,我們需要把這個值放入 next[j+1] 的位置,
不過,因為我們 i 和 j 是匹配的,所以我們同時是需要把 j 和 i 挪動到下一個下標的位置,因為 j 挪動了一位,其實就等于 j 自身已經 +1 了,那么我們賦值給 next 的時候就可以直接用 next[i] = j,這里 i 也一樣不需要再 +1 了,因為 i 挪動到下一個下標的時候已經自身也 +1 了,
然后就是第二種情況,當 i 和 j 對應的字符不匹配的時候,我們就要讓 j 進行回溯,因為我們已經把 prefix 陣列的值往右挪動了一位,所以我們直接用 j = next[j] 即可,就不要獲取 next[j-1] 的值了,
最后,我們前面講過,如果 j 已經回溯到下標 0 還是沒有發現有公共前后綴的情況,這個時候我們就不能讓 j 繼續回溯了,所以我們需要控制這種邊界的情況,只有 j > 0 的時候才會繼續回溯,如果到達了下標 0 還是沒有發現公共前后綴, 那就可以讓 i 往前挪動一位了,
注意:我們一開始就給 next 陣列里面所有的值都賦予
0,所以遇到i和j不匹配的時并且j已經在下標 0了,這個時候我們不需要給 next 數值賦值0了,因為它本來就已經是0了,
在理論部分我們講到,Next 陣列的下標 0 在挪動后是空值,所以需要補一個 -1,為了保持一直,最后我們加上這個邏輯 next[0] = -1,
這里還有一個點需要我們注意的,就是我們的回圈截止的條件是
pattern.length - 1,而不是pattern.length,這是因為我們已經把 prefix 陣列的值都往后挪動了一位,所在如果我們使用 pattern.length 條件的話,如果我們一共有 11 個字母,在回圈到 i = 11 的時候,我們一樣呼叫了next[11 + 1] = j,自然這里就多出了一個數值,而這個我們是需要的,所以這里我們截止條件改為pattern.length - 1即可,
這個邏輯的動態效果如下:

function kmp(source, pattern) {
// 計算 Next 陣列
let next = new Array(pattern.length).fill(0);
// 尋找模式竄中的公共前后綴
let i = 1,
j = 0;
while (i < pattern.length - 1) {
if (pattern[i] === pattern[j]) {
++j, ++i;
next[i] = j;
} else {
if (j > 0) {
j = next[j];
} else {
++i;
}
}
}
next[0] = -1;
console.log(next);
}
kmp('', 'ababaaababaa');
這里我們呼叫一下 kmp 函式來試試,最終的 next 陣列是不是對的,
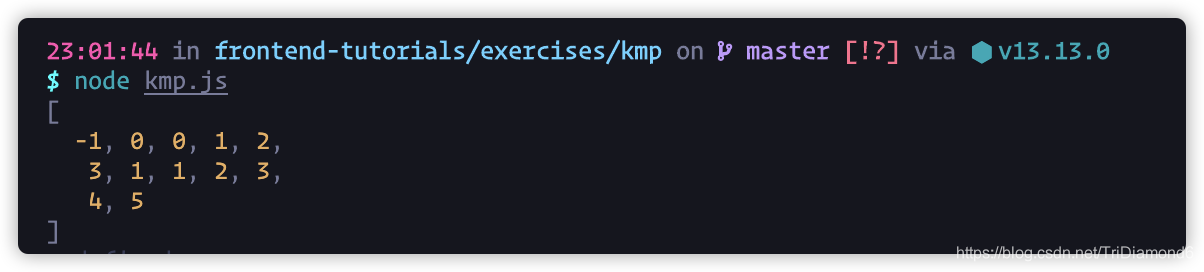
完美,這樣我們就達到我們預期的 next 陣列了,接下來就是去實作我們的匹配邏輯了,
匹配
其實匹配的邏輯是和我們計算 Next 陣列的邏輯是基本相似的,最大的區別就是現在不是模式串于自己的字符對比,而是于原串的字符做對比,
在這個匹配的回圈里面,我們又需要用到
i和j,這樣其實我們作用域就沖突了,所以這里我們用到一個小技巧,在我們用{}包著我們計算 Next 陣列代碼,這樣它里面的i和j就只限于這部分的代碼,然后我們匹配的代碼也是一樣,用{}包著即可,
這個匹配邏輯我們 i 和 j 就都是需要從下標 0 開始了,
然后我們的回圈會一直回圈直到 i 到達我們原串的長度,
回圈中的邏輯如下:
- 首先我們判斷匹配成功的情況,
模式串中的j指向的字符與原串中i指向的字符相同時,i和j就都可以往右挪動一位,往后繼續匹配了, - 根據我們分析 KMP 的回溯方式,我們就需要把前面一段字符的公共前綴挪動到公共后綴的位置,所以我們就可以使用計算好的
next陣列的值:j = next[j]進行移動, - 但是還有一種情況,就是當前的 j 是在下標 0 的位置,這樣的話,其實根本就不可能有公共前后綴的,這種情況我們就可以直接找原串中的下一個字符與我們模式串的下標 0 的字符進行匹配了,所以這里就是
++i即可, - 所有我們判斷一下,當前 j 的位置是否一定到達模式串的最后一位了,如果是,證明我們已經匹配成功,
- 如果走完整個原串的所有字符,我們模式串還沒有全部被匹配到,這就證明我們原串中沒有一個子串與我們模式串相同,即時匹配失敗,
按照上面的邏輯,我們的代碼就是這樣的:
function kmp(source, pattern) {
// 計算 Next 陣列
let next = new Array(pattern.length).fill(0);
{
// 尋找模式竄中的公共前后綴
let i = 1,
j = 0;
while (i < pattern.length - 1) {
if (pattern[i] === pattern[j]) {
++j, ++i;
next[i] = j;
} else {
if (j > 0) {
j = next[j];
} else {
++i;
}
}
}
next[0] = -1;
}
// 匹配
{
let i = 0,
j = 0;
while (i < source.length) {
if (pattern[j] === source[i]) {
++j, ++i;
} else {
if (j > 0) {
j = next[j];
} else {
++i;
}
}
if (j === pattern.length) return true;
}
return false;
}
}
console.log(kmp('ABABABAABABAAABABAA', 'ABABAAABABAA'));
console.log(kmp('helbbblo', 'll'));
最后我們執行了這個不同的字符匹配例子,如果我們的 KMP 演算法的代碼是正確的,第一個字符匹配應該是成功的,而第二個應該會失敗,我們來執行一下看看,是否正確,

顯然這里是正確的,這樣我們就完成了 KMP 演算法的代碼實作了,
希望這篇文章可以讓大家更好的理解 KMP 演算法,說實話,因為市面上有很多教程,很多文章講解這個演算法的,但是我看了很多,基本講法都各有不同,prefix,PMT,next 這些概念也是各有各的說法,經過我一番研究,其實實際上最后的實作都是一樣的,其實就是按個更好理解而已,對我而言,使用 prefix 和 next 這兩種概念是最好理解的,
這篇文章是我所有文章中花時間最長的一篇,總共重寫了 3 遍,因為 KMP 不同的文章的差異,讓我剛開始整理的時候走入了很多誤區,導致對 KMP 的知識越看就越混亂,最后看了很多視屏和文章,然后一一研究后才真的弄懂了它們,如果這篇文章讓你們對 KMP 有了更清晰的認知,那就給我點贊三連吧~ 謝謝~

博主開始在B站直播學習,歡迎過來《直播間》一起學習,
我們在這里互相監督,互相鼓勵,互相努力走上人生學習之路,讓學習改變我們生活!
學習的路上,很枯燥,很寂寞,但是希望這樣可以給我們彼此帶來多一點陪伴,多一點鼓勵,我們一起加油吧! (? ?????)?
我是來自《技術銀河》的三鉆,一位正在重塑知識的技術人,下期再見,
推薦專欄
小伙伴們可以查看或者訂閱相關的專欄,從而集中閱讀相關知識的文章哦,
-
📖 《前端進階》 — 這里包含的文章學習內容需要我們擁有 1-2 年前端開發經驗后,選擇讓自己升級到高級前端工程師的學習內容(這里學習的內容是對應阿里 P6 級別的內容),
-
📖 《資料結構與演算法》 — 到了如今,如果想成為一個高級開發工程師或者進入大廠,不論崗位是前端、后端還是AI,演算法都是重中之重,也無論我們需要進入的公司的崗位是否最后是做演算法工程師,前提面試就需要考演算法,
-
📖 《FCC前端集訓營》 — 根據FreeCodeCamp的學習課程,一起深入淺出學習前端,穩固前端知識,一起在FreeCodeCamp獲得證書
-
📖 《前端星球》 — 以實戰為線索,深入淺出前端多維度的知識點,內含有多方面的前端知識文章,帶領不懂前端的童鞋一起學習前端,在前端開發路上童鞋一起燃起心中那團火🔥



 CSDN認證博客專家
前端
Vue
React
CSDN認證博客專家
前端
Vue
React
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229113.html
標籤:其他