文章目錄
- 驗證碼
- 字符驗證碼
- OCR識別
- 灰度處理
- 二值化處理
- OCR識別
- 打碼平臺
- 小結
驗證碼
全自動區分計算機和人類的公開圖靈測驗 (Completely Automated Public Turing test to tell Computers and Humans Apart),簡稱 CAPTCHA,俗稱 驗證碼,
由于這個測驗是由計算機來考人類,而不是標準圖靈測驗中那樣由人類來考計算機,所以也被稱為反向圖靈測驗,
驗證碼可以有效防止惡意注冊,刷票,論壇“灌水” 等有損網站利益的行為,驗證碼的原理很簡單:人類有主觀意識,能夠根據要求執行操作,而計算機卻不能,
最初,驗證碼是一張帶有字符的圖片,用戶只需要將圖片中的字符輸入到文本框中即可,但這種簡單的驗證碼很快就被繞過了,于是人們向圖片中加入了一些混淆的元素,如斜線,彩色斑點等,接著出現了一些基于用戶操作的驗證碼,也就是行為驗證碼,常見的有滑動驗證碼,拼圖驗證碼和文字點選驗證碼等,
字符驗證碼
字符驗證碼是指用數字,字母,漢字和標點符號等字符作為元素的圖片驗證碼,字符驗證碼是常見的驗證碼型別,它將人類視覺和計算機視覺的差異作為區分用戶身份的依據,
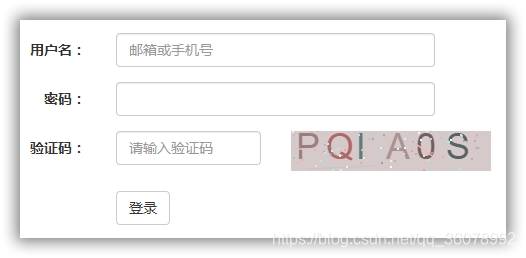
OCR識別
我們曾在前邊的文章中使用 百度AI開放平臺文字識別 成功地從圖片中識別電話號碼,那么是否可以用來識別驗證碼圖片中的文字呢? 將網站中的驗證碼保存到本地,然后呼叫 百度OCR 進行識別:
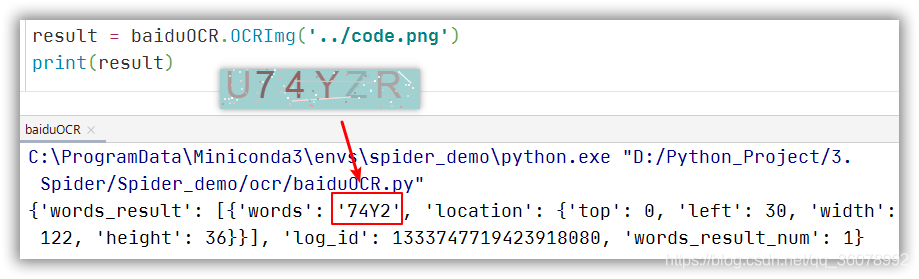
相較于之前的電話號碼來說,本次所面對的驗證碼是帶有彩色背景斜線和噪點,而且圖片中字符顏色和背景色并沒有強烈反差,這些因素都會影響識別效果,
要想提高識別的成功率,我們必須對圖片進行處理,例如降低斜線和噪點對文字的干擾,增強背景色與字符顏色的反差,
也就是說,我們需要對圖片進行灰度處理(去掉彩色)和二值化處理(降低干擾,增強顏色反差),
灰度處理
from PIL import Image
im = Image.open(r"C:\Users\Administrator\Desktop\code.png")
im = im.convert('L')
im.show()

這時候整張圖片變成了灰色,但字符顏色與背景顏色并不明顯,對識別沒有明顯幫助,接下來,我們對圖片進行二值化處理,并嘗試識別處理后的圖片,
二值化處理
二值化處理其實就是根據 閾值 調整原圖的像素值,將大于閾值的像素點顏色改為白色,小于閾值的像素點顏色改為黑色,這樣就能夠達到增強顏色反差的目的,
def handler(grays, threshold=170):
"""
二值化處理
:param grays: 待處理的圖片
:param threshold: 默認閾值為 160, 可根據實際情況調整
:return:
"""
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
anti = grays.point(table, '1')
return anti
彩色的驗證碼圖片在經過灰度和二值化處理后變成了如下的樣子
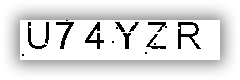
OCR識別
處理后的圖片輪廓清晰,字符與背景顏色反差大,此時我們再次呼叫 百度OCR 對圖片進行識別
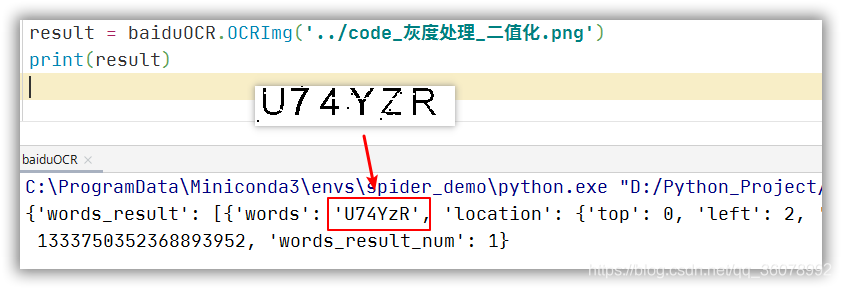
本次識別的效果還是不錯的,那么我們多獲取一些驗證碼圖片嘗試一下

對于隨機的 8張略微復雜的驗證碼,OCR 的效果就不忍直視了,在實際應用中,圖片驗證碼的識別成功率達到 75% 才能夠滿足爬蟲工程師的需求,面對這樣的問題,我們是否還有其他的解決方法呢?
打碼平臺
打碼平臺的主要功能就是提供驗證碼識別,目前主流的打碼平臺都支持數字、漢字、英文字母、圖片、座標、答題等各種形式的驗證碼的智能識別,機器與人工相配合,平均識別時間 1~3秒,有著非常高的識別率
本次我們以 超級鷹 打碼平臺為例,展示打碼平臺的使用!
-
注冊賬號登錄網站
-
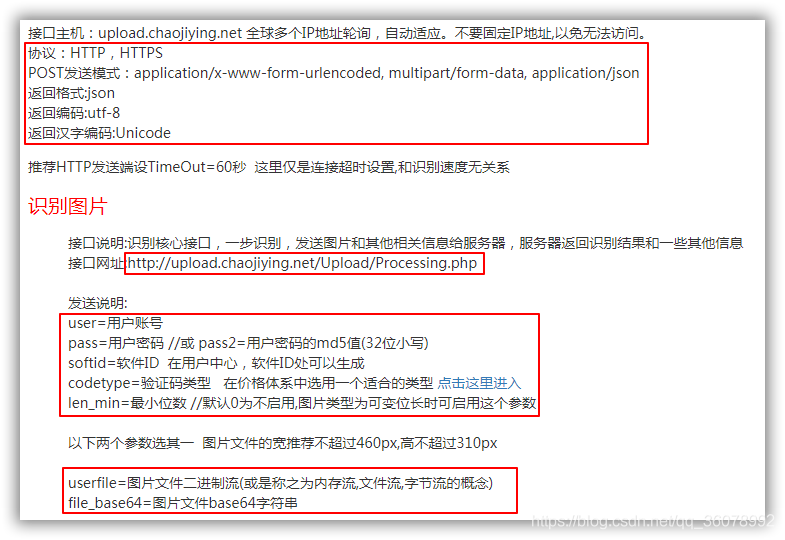
查看介面開發檔案,在超級鷹的檔案中,我們可以很容易找到 介面地址,請求方式,引數設定等資訊
-
撰寫代碼
import base64 import requests def vaifyCode_API(path): # 圖片處理 with open(path, 'rb') as f: img_content = f.read() img = base64.b64encode(img_content) # 引數構造 data = { 'user': '賬號', 'pass': '密碼', 'softid': '軟體ID', 'codetype': '1902', # 驗證碼型別 'file_base64': img, # 圖片base64字串 } url = 'http://upload.chaojiying.net/Upload/Processing.php' # 發起請求 data = requests.post(url=url, data=data).json() # 回傳識別結果 return data.get('pic_str') result = vaifyCode_API('1.jpg') print(result) -
識別結果

小結
添加了干擾資訊的字符驗證碼可以有效增加識別難度和錯誤率,除了斜線和噪點外,還可以使用字符扭曲,角度旋轉和文字重疊等方法,
對于復雜驗證碼的識別,本文僅介紹了打碼平臺的使用,此外我們還可以借助深度學習來對驗證碼進行識別作業,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229173.html
標籤:其他
上一篇:局域網練習