今天要偷懶
- 前言
- 填坑
- get()
- post()
- 總結
- 不知道起什么名字
- 干
- 干什么
- 怎么干
前言
沒想到點贊這么快就到100了……
那就說到做到,說更就更!
今天就來把之前寫的時候的一些坑,給大家填嘍~
填坑
不知道大家有沒有注意到啊,我們之前使用requests模塊的時候,后面有時候跟的是get(),有時候跟的是post(),各位細心的小伙伴不會沒注意到吧,不會吧不會吧,竟然沒有一個人問這個問題,難道你們都懂了嗎……


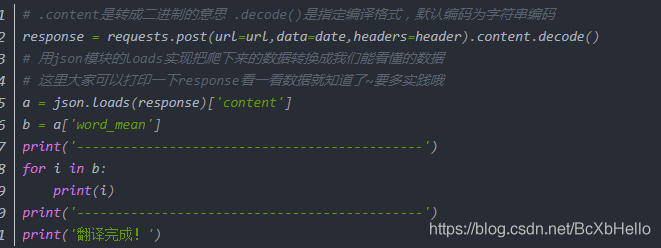
吶,看上面的三幅圖,都是我們之前敲過的代碼,聰明的你一定發現了requests.get()和requests.post()是不一樣的!為什么呢?他倆長的都不一樣,

今天,就讓我們來說一說get和post的區別吧!
get()
子曰,學而時習之,不亦樂乎,學習使我快樂!我愛學習!誰也阻止不了我學習!我要學習!!!

剛才抒發了一下內心想學習的欲望,俗話說得好,首先要有想法,然后腳踏實地的去做,才能慢慢成功,
我真傻,真的,一開始學requests的時候,啥也沒說,啪一下就拿出來了requests.get()這個東西,很快啊,那能咋整嘛,結果過了幾天又給我蹦出來一個requests.post(),還跟我說年輕人你耗子尾汁,我再去看以前的東西,竟是迷糊了去,唉,如果我當初剛學的時候就好好百度一下,也不會到現在這般迷茫,

廢話不多說,首先要知道一點,get()和post()都是對url發起的一種請求,那么什么時候用get()呢?這就要用到我們的抓包工具啦~相信細心的小伙伴已經發現了,
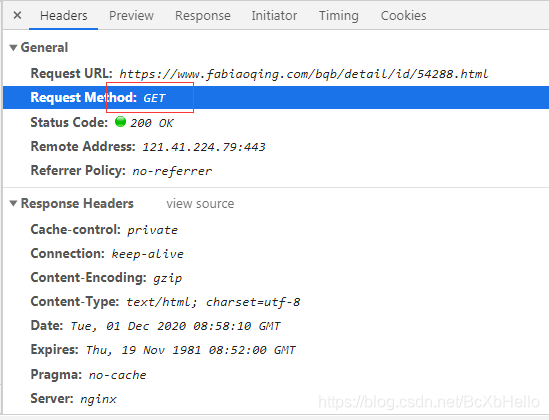
在url對應的Headers里有個GET,這就說明了這個頁面是要用get方式請求的,
post()
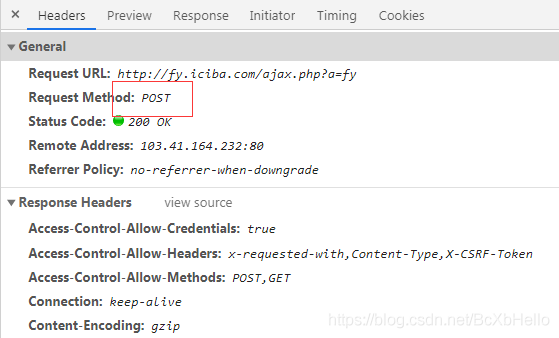
同樣,如果你發現url對應的Headers里有個POST的話,就說明我們要用post方法進行請求,
完了……
你以為到這里就結束了??
大錯特錯了!
之前看評論發現有些小伙伴不喜歡穿衣服就進去搶銀行哈,headers都不帶,保安立馬把你打飛,

總結
我們之前爬那個翻譯網站的時候,就用到了post(),不知道大家有沒有注意,那一次我們不但發起了請求,還給服務器傳遞了幾個引數:
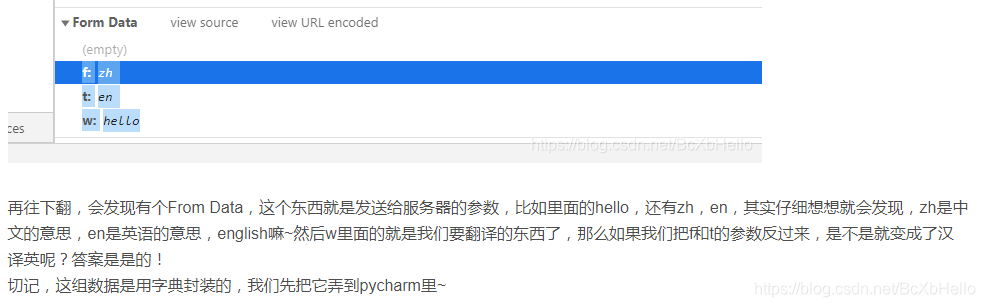
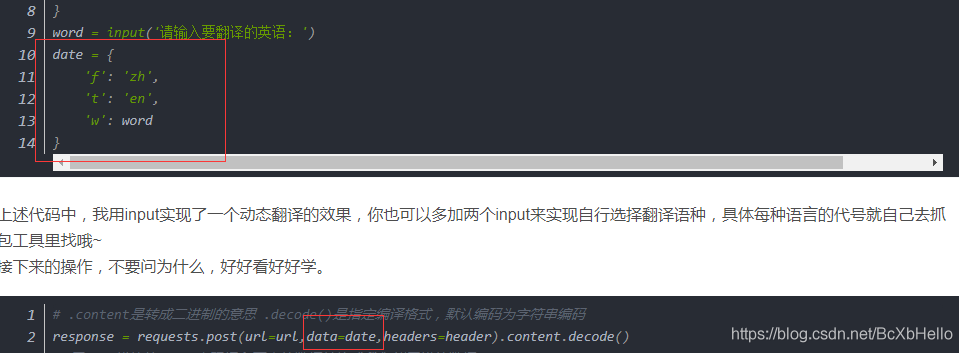
之前小澤的data打錯了,打成了date,就有小伙伴也跟著打錯了,然后報錯了,hhh
說明學好英語真的很重要!!!
大家可以看到,在post()里,我們有url=,還有headers=,還有一個data=,那么post()跟get()的區別到底在哪里呢??

直接上代碼截圖
通過截圖大家會發現,get()里面有個params=,這就是它們的區別哦!
發給服務器的引數里面,在get()里要用params=,在post()里面要用data=,不是date!!
不知道起什么名字
你以為這就完了嗎?
說實話本來是想偷懶的,但是轉念一想,還是負責任一次叭,畢竟不能對大家蹭蹭進去就不管了!

相信大家安裝模塊的時候啊,總會遇到各種黃色的東西還有紅色的東西,對我們幼小的心靈造成了極大的打擊!
這里教給大家一個方便快捷的方法,從此跟下得慢、總報錯說拜拜!
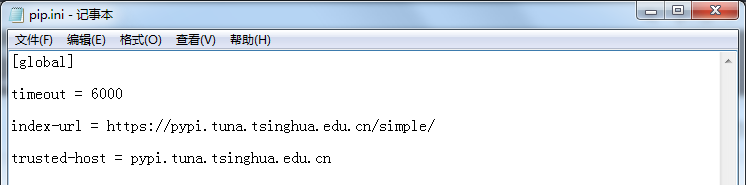
打開我的電腦,在地址欄中輸入 %APPDATA% 按回車跳轉到目標目錄,在目錄下創建一個pip檔案夾,在里面創建一個pip.txt檔案,然后把擴展名改成ini,
在里面輸入呢,如下的東西啊:
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple/
trusted-host = pypi.tuna.tsinghua.edu.cn
從此以后下片 下模塊就快的飛起啦!蕪湖~
干
說干就干,水是不可能水的,看到這里的老鐵還不感動的淚流滿面然后給個贊嗎!!為什么粉絲數量可以比贊的數量多!!小澤想要贊,嗚嗚……
干什么
豆瓣電影
打開它!
還記得我們學爬蟲是為了什么嗎?
爬 取 數 據 !
如果我們連高分的動作片都不能爬取到,那我們學爬蟲還有什么意義,
所以今天的任務目標:爬取豆瓣電影中動作電影的排行,
怎么干
又到了緊張刺激的分析環節啦~
首先打開豆瓣電影主頁:
去找右邊的更多榜單
在彈出的頁面里找到動作這兩個字,沒有島國!
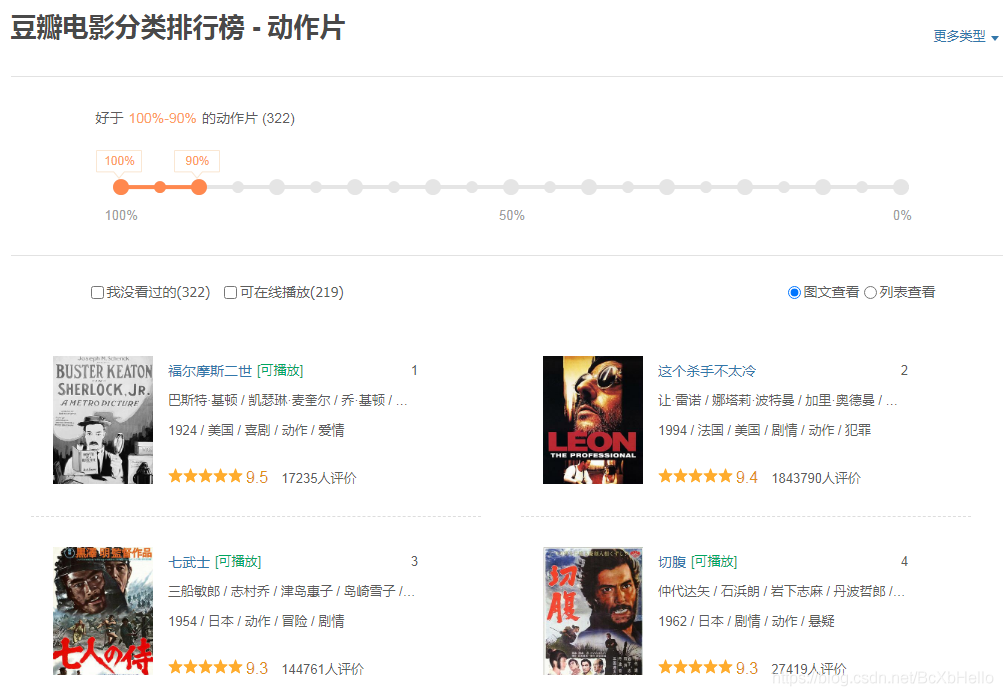
好的,跳到了這里,
開 始 分 析 !
大家試著往下拉,會不會發現一直拉不到最下面?
也就是說,這些資料是阿賈克斯!
不要問我阿賈克斯是什么…lol玩過沒,武器大師啊!!
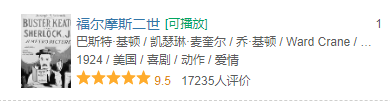
我們理想中的應該是把每一部電影的電影名字和相關主演還有地區,標簽那些爬下來對吧,那我們先試著只爬一個!
按照之前學過的思路來:
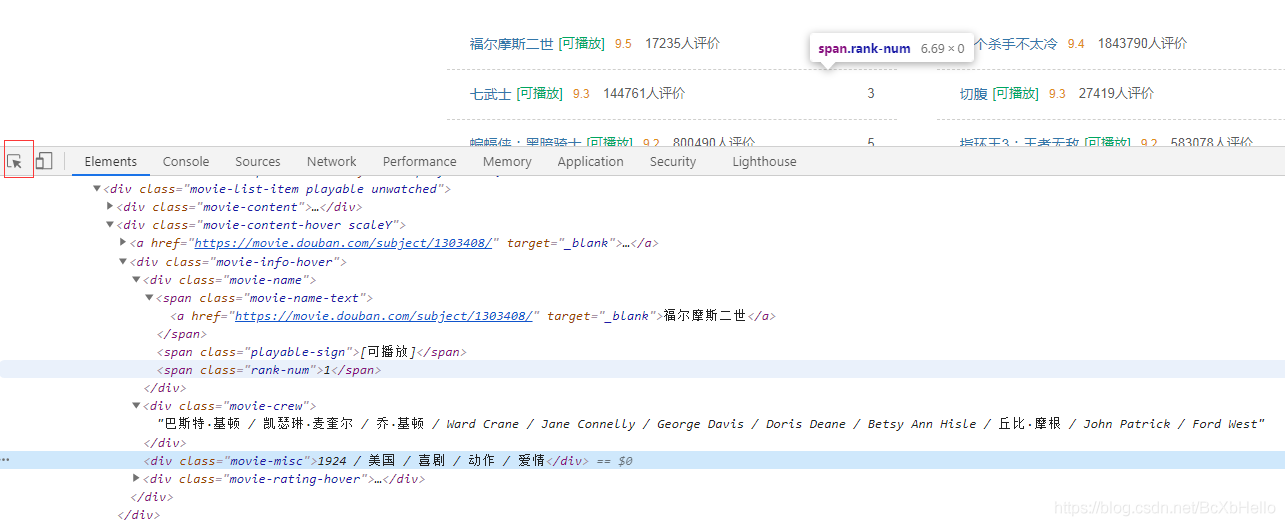
用我們的金手指點一下第一個頁面,然后我們就會發現我們要的東西都在這里面,接下來的操作,如果看不懂的話,就罰你回去看我之前寫的內容一百遍哦,oh不對,這怎么能是懲罰呢~ 簡直是美妙的福音!
# 匯入模塊
import requests
from lxml import etree
# get請求的url
get_url = 'https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action='
# 偽裝頭,穿衣服!誰不穿拉出去斃了!
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 發起get請求,把回傳的資料text化存到response里
response = requests.get(url=get_url,headers=header).text
# 樹化回傳的網頁資料
tree = etree.HTML(response)
movie_name = tree.xpath('//div[@id="content"]//span[@class="movie-name-text"]/a/text()')
print(movie_name)
如果根據之前學的,上面的代碼應該是可以成功列印出第一部電影的名字的,
但是運行之后…

xpath運算式是沒有錯的,那說明了什么:
說明了這個資料,是不存在的!
你看到的,不一定是你看到的,也許你沒看到的,才是你看到的!!

還記得之前說的阿賈克斯不,既然我們已經發現這個網站是動態的網站了,那就要用抓包工具去捕獲資訊對吧!
其實仔細一想,這么大的一個電影網站肯定不會直接把電影資料寫在網頁上讓我們爬下來啊,就像我們看游戲的那些排名,都是動態從資料庫里加載出來的,對吧!
所以這些電影排名如果是死的話,那程式員每過一段時間都要重新改一改排行,該多難受啊……
思路明確,我們打開抓包工具,去找一下服務器回傳的資料在哪里!
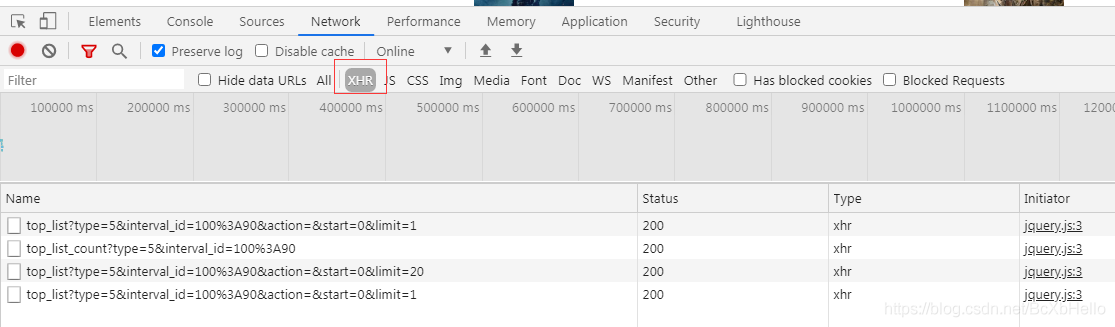
記得重繪一下頁面哦~
看到了嘛,XHR里面就可以找到我說的那個阿賈克斯請求!
不過有四個誒…
一一打開看一下好了:
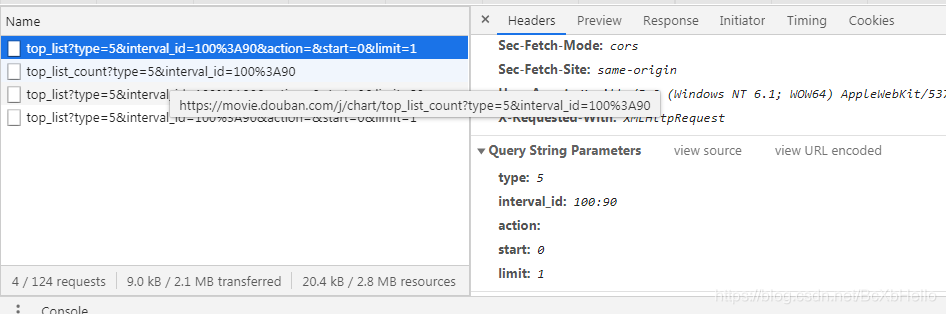
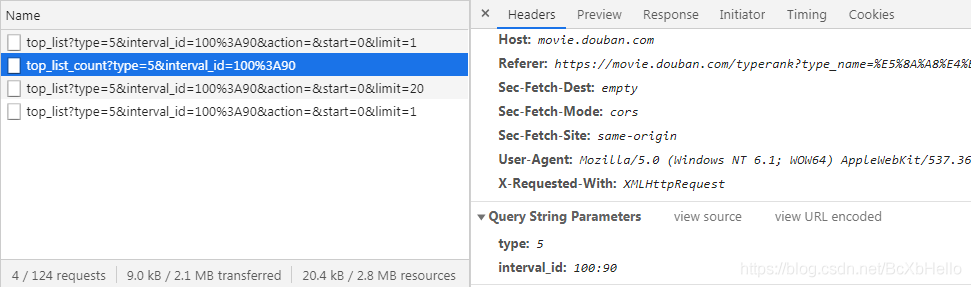
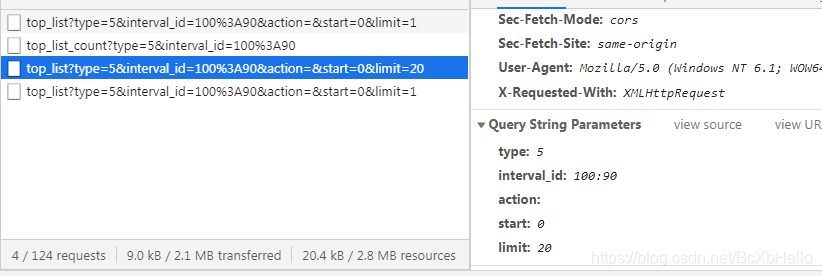
最后一個跟第一個是一樣的哦,通過抓包工具可以看到,這幾個阿賈克斯請求都給服務器傳遞了有引數對吧,
接著我們再看response:
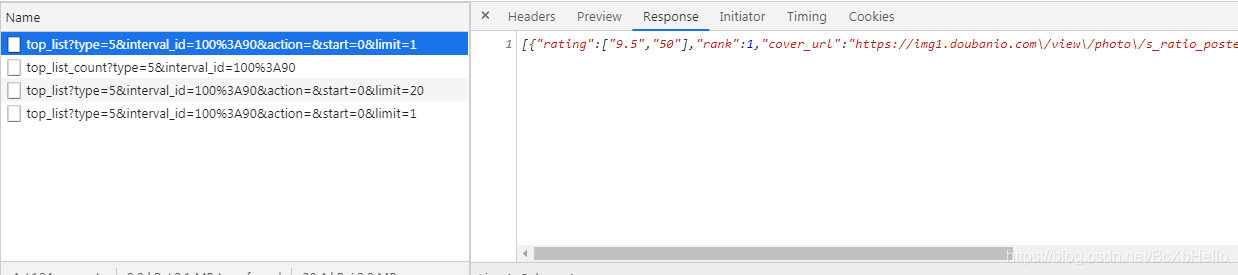
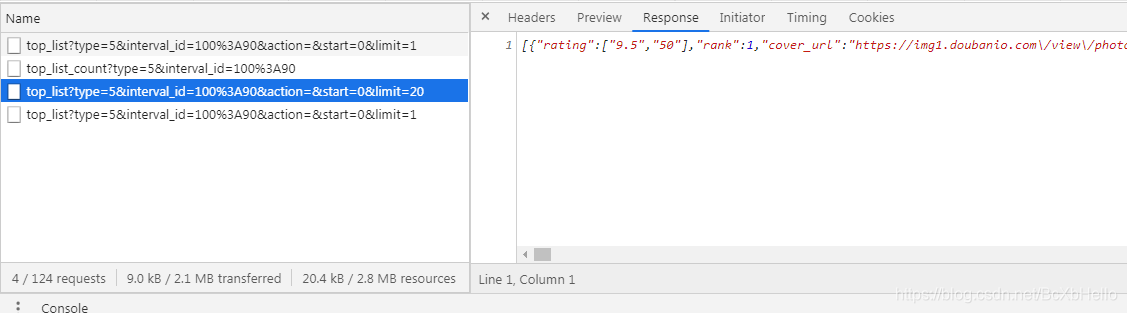
粗略的翻看一下,發現第三個里面包含了我們要的所有資訊,對吧!
再把它給服務器傳遞的引數單獨拿出來看一看:
params = {
'type':'5', # 很明顯是分類
'interval_id':'100:90', # 還記得開頭的好于100%-90%的動作片嗎
'action':'',
'start': '0', #從第幾個開始
'limit':'20' #每次讀取多少個
}
那么如果改了type傳遞的引數,是不是就可以拿到不同分類的資料呢?是的!
那么如果改了start傳遞的引數,是不是就可以拿到不同開頭的資料呢?是的!
那么如果改了limit傳遞的引數,是不是就可以拿到不同數量的資料呢?是的!
這可比我們之前的笨方法快多了!
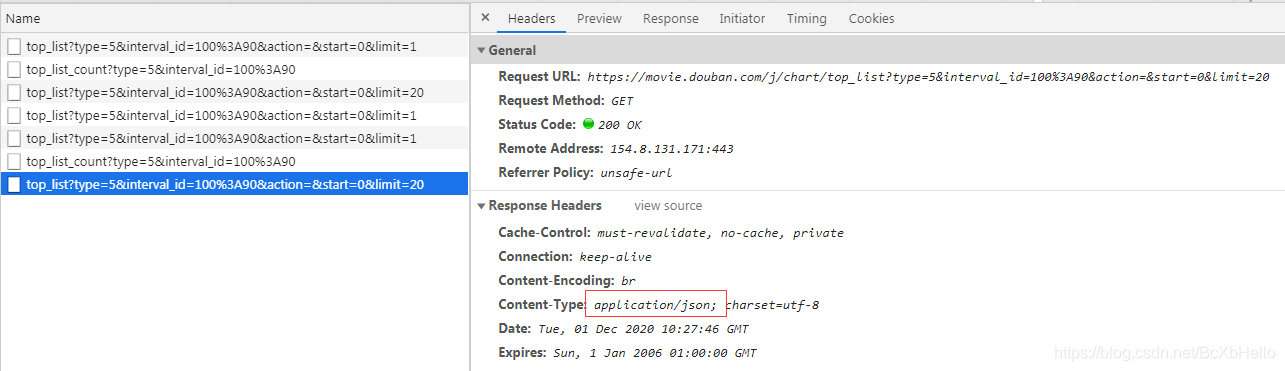
還有一個點要注意,那就是服務器那邊發來的是什么樣的資料!
還記得之前我們用過json編碼決議翻譯網站嗎,今天又要用到啦,看上圖,回傳的檔案是json格式的吧,那我們就需要用json去決議,對吧!
接下來,讓我們找到正確的url吧!
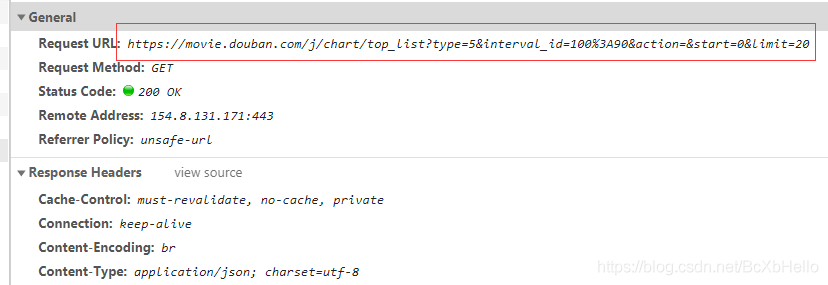
觀察這行url,看到里面有type=,action=之類的,像不像我們之前找到的引數呢?沒錯,就是這樣的,既然這樣,我們是可以傳遞引數的,那是不是就是說可以在這串url上簡化一下,把https://movie.douban.com/j/chart/top_list?后面的東西都給刪掉呢?當然是可以的!
萬事開頭難,要學會接受,
# 匯入模塊
import json
import requests
get_url = 'https://movie.douban.com/j/chart/top_list?'
params = {
'type':'5',
'interval_id':'100:90',
'action':'',
'start': '0', #從第幾個開始
'limit':'20' #每次讀取多少個
}
# 穿衣服!
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
那么,上面的代碼就是我們要提前準備好的東西了吧,然后……開干!
response = requests.get(url=get_url,params=params,headers=header).content.decode()
a = json.loads(response)
print(a)
這一類操作呢,之前在爬取翻譯網站的時候也做過,所以不多解釋,如果有人不會的話就留言哦,不要光關注不點贊!!!!!

求求各位關注的帥哥美女們每一篇都給來個贊吧T-T

回到主題,運行一下我們會發現:
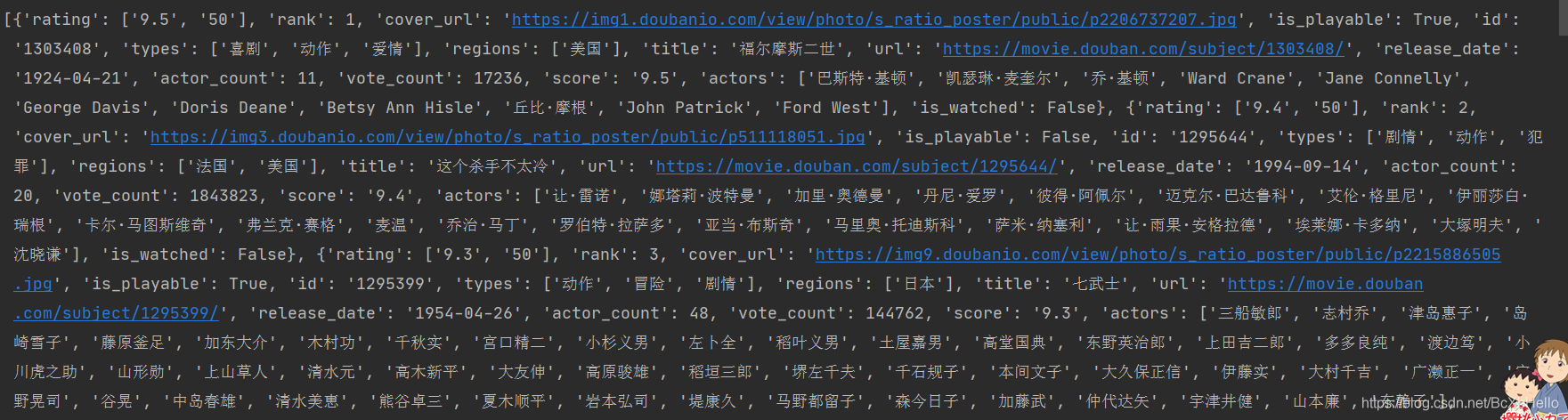
果然被我們攔截到了!
看一下串列:

我們要的評分,是在串列里的字典里的’rating’鍵對應的值對吧,以此類推,我們來把得到的資料提取一下:
# 遍歷a串列中的每一個字典
for i in a:
pingfen = i['rating'][0]
paiming = i['rank']
is_playable = i['is_playable']
fenlei = i['types']
fenleis = ''
for a in fenlei:
fenleis += a
fenleis += ' '
diqu = i['regions'][0]
mingzi = i['title']
riqi = i['release_date']
zhuyan = i['actors']
zhuyans = ''
for b in zhuyan:
zhuyans += b
zhuyans +=' '
if is_playable == True:
zhuangtai = '可播放'
dizhi = i['url']
print('電影名字:'+mingzi)
print('排名:',paiming)
print('狀態::' + zhuangtai)
print('鏈接:' + dizhi)
print('評分:' + pingfen)
print('主演:' + zhuyans)
print('上映日期:' + riqi + '/上映地區:' + diqu +'/分類:' + fenleis)
print('-------------------------------------------------------------------')
else:
zhuangtai = '不可播放'
print('電影名字:' + mingzi)
print('排名:',paiming)
print('狀態::' + zhuangtai)
print('評分:' + pingfen)
print('主演:' + zhuyans)
print('上映日期:' + riqi + '/上映地區:' + diqu + '/分類:' + fenleis)
print('-------------------------------------------------------------------')
上述操作呢,都屬于基礎哈,如果不懂的話留言問~
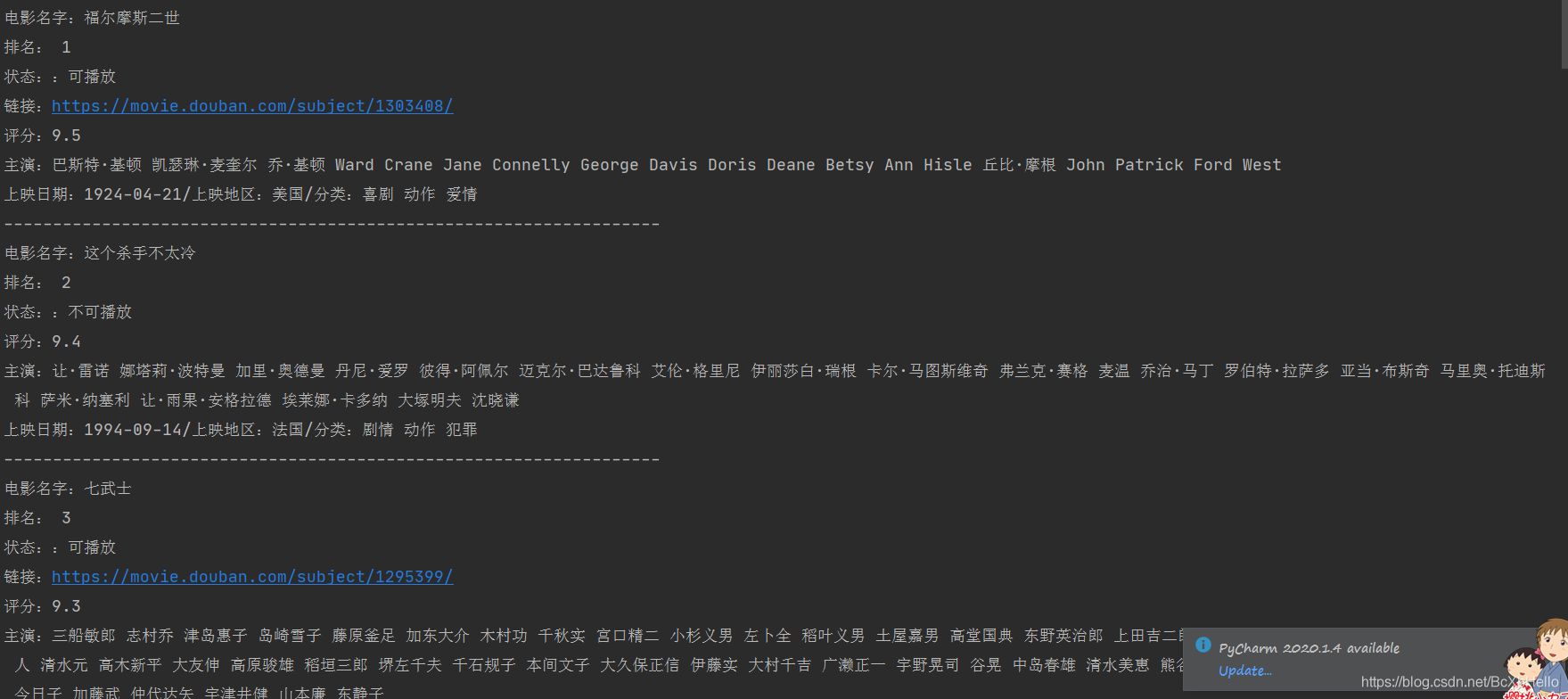
這就是效果圖嘍!
呼呼,好累鴨,
看到這里了你還不給個贊嘛~~
下一期200贊再更新哦!!
200贊!!

各位姥爺們早點睡覺哦,今天就搞到這里了,頂不住了……
200贊!!!!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229320.html
標籤:其他
上一篇:Unity實作BStar尋路