一 TCP 協議是流式協議
很多讀者從接觸網路知識以來,應該聽說過這句話:TCP 協議是流式協議,那么這句話到底是什么意思呢?所謂流式協議,即協議的內容是像流水一樣的位元組流,內容與內容之間沒有明確的分界標志,需要我們人為地去給這些協議劃分邊界,
舉個例子,A 與 B 進行 TCP 通信,A 先后給 B 發送了一個 100 位元組和 200 位元組的資料包,那么 B 是如何收到呢?B 可能先收到 100 位元組,再收到 200 位元組;也可能先收到 50 位元組,再收到 250 位元組;或者先收到 100 位元組,再收到 100 位元組,再收到 200 位元組;或者先收到 20 位元組,再收到 20 位元組,再收到 60 位元組,再收到 100 位元組,再收到 50 位元組,再收到 50 位元組……
不知道讀者看出規律沒有?規律就是 A 一共給 B 發送了 300 位元組,B 可能以一次或者多次任意形式的總數為 300 位元組收到,假設 A 給 B 發送的 100 位元組和 200 位元組分別都是一個資料包,對于發送端 A 來說,這個是可以區分的,但是對于 B 來說,如果不人為規定多長為一個資料包,B 每次是不知道應該把收到的資料中多少位元組作為一個有效的資料包的,而規定每次把多少資料當成一個包就是協議格式規范的內容之一,
經常會有新手寫出類似下面這樣的代碼:
發送端:
1//...省略創建socket,建立連接等部分不相關的邏輯...
2char buf[] = "the quick brown fox jumps over a lazy dog.";
3int n = send(socket, buf, strlen(buf), 0);
4//...省略出錯處理邏輯...
接收端:
1//省略創建socket,建立連接等部分不相關的邏輯...
2char recvBuf[50] = { 0 };
3int n = recv(socket, recvBuf, 50, 0);
4//省略出錯處理邏輯...
5printf("recvBuf: %s", recvBuf);
為了專注問題本身的討論,我這里省略掉了建立連接和部分錯誤處理的邏輯,上述代碼中發送端給接收端發送了一串字符”the quick brown fox jumps over a lazy dog.“,接收端收到后將其列印出來,
類似這樣的代碼在本機一般會作業的很好,接收端也如期列印出來預料的字串,但是一放到局域網或者公網環境就出問題了,即接收端可能列印出來字串并不完整;如果發送端連續多次發送字串,接收端會列印出來的字串不完整或出現亂碼,不完整的原因很好理解,即對端某次收到的資料小于完整字串的長度,recvBuf 陣列開始被清空成 0,收到部分字串后,該字串的末尾仍然是 0,printf 函式尋找以 0 為結束標志的字符結束輸出;亂碼的原因是如果某次收入的資料不僅包含一個完整的字串,還包含下一個字串部分內容,那么 recvBuf 陣列將會被填滿,printf 函式輸出時仍然會尋找以 0 為結束標志的字符結束輸出,這樣讀取的記憶體就越界了,一直找到為止,而越界后的記憶體可能是一些不可讀字符,顯示出來后就亂碼了,
我舉這個例子希望你明白 能對TCP 協議是流式協議有一個直觀的認識,正因為如此,所以我們需要人為地在發送端和接收端規定每一次的位元組流邊界,以便接收端知道從什么位置取出多少位元組來當成一個資料包去決議,這就是我們設計網路通信協議格式的要做的作業之一,
二 如何解決粘包問題
網路通信程式實際開發中,或者技術面試時,面試官通常會問的比較多的一個問題是:網路通信時,如何解決粘包?
有的面試官可能會這么問:網路通信時,如何解決粘包、丟包或者包亂序問題?這個問題其實是面試官在考察面試者的網路基礎知識,如果是 TCP 協議,在大多數場景下,是不存在丟包和包亂序問題的,TCP 通信是可靠通信方式,TCP 協議堆疊通過序列號和包重傳確認機制保證資料包的有序和一定被正確發到目的地;如果是 UDP 協議,如果不能接受少量丟包,那就要自己在 UDP 的基礎上實作類似 TCP 這種有序和可靠傳輸機制了(例如 RTP協議、RUDP 協議),所以,問題拆解后,只剩下如何解決粘包的問題,
先來解釋一下什么是粘包,所謂粘包就是連續給對端發送兩個或者兩個以上的資料包,對端在一次收取中可能收到的資料包大于 1 個,大于 1 個,可能是幾個(包括一個)包加上某個包的部分,或者干脆就是幾個完整的包在一起,當然,也可能收到的資料只是一個包的部分,這種情況一般也叫半包,
無論是半包還是粘包問題,其根源是上文介紹中 TCP 協議是流式資料格式,解決問題的思路還是想辦法從收到的資料中把包與包的邊界給區分出來,那么如何區分呢?目前主要有三種方法:
固定包長的資料包
顧名思義,即每個協議包的長度都是固定的,舉個例子,例如我們可以規定每個協議包的大小是 64 個位元組,每次收滿 64 個位元組,就取出來決議(如果不夠,就先存起來),
這種通信協議的格式簡單但靈活性差,如果包內容不足指定的位元組數,剩余的空間需要填充特殊的資訊,如 \0(如果不填充特殊內容,如何區分包里面的正常內容與填充資訊呢?);如果包內容超過指定位元組數,又得分包分片,需要增加額外處理邏輯——在發送端進行分包分片,在接收端重新組裝包片(分包和分片內容在接下來會詳細介紹),
以指定字符(串)為包的結束標志
這種協議包比較常見,即位元組流中遇到特殊的符號值時就認為到一個包的末尾了,例如,我們熟悉的 FTP協議,發郵件的 SMTP 協議,一個命令或者一段資料后面加上"\r\n"(即所謂的 CRLF)表示一個包的結束,對端收到后,每遇到一個”\r\n“就把之前的資料當做一個資料包,
這種協議一般用于一些包含各種命令控制的應用中,其不足之處就是如果協議資料包內容部分需要使用包結束標志字符,就需要對這些字符做轉碼或者轉義操作,以免被接收方錯誤地當成包結束標志而誤決議,
包頭 + 包體格式
這種格式的包一般分為兩部分,即包頭和包體,包頭是固定大小的,且包頭中必須含有一個欄位來說明接下來的包體有多大,
例如:
1struct msg_header
2{
3 int32_t bodySize;
4 int32_t cmd;
5};
這就是一個典型的包頭格式,bodySize 指定了這個包的包體是多大,由于包頭大小是固定的(這里是 size(int32_t) + sizeof(int32_t) = 8 位元組),對端先收取包頭大小位元組數目(當然,如果不夠還是先快取起來,直到收夠為止),然后決議包頭,根據包頭中指定的包體大小來收取包體,等包體收夠了,就組裝成一個完整的包來處理,在有些實作中,包頭中的 bodySize可能被另外一個叫 packageSize 的字段代替,這個欄位的含義是整個包的大小,這個時候,我們只要用 packageSize 減去包頭大小(這里是 sizeof(msg_header))就能算出包體的大小,原理同上,
在使用大多數網路庫時,通常你需要根據協議格式自己給資料包分界和決議,一般的網路庫不提供這種功能是出于需要支持不同的協議,由于協議的不確定性,因此沒法預先提供具體解包代碼,當然,這不是絕對的,也有一些網路庫提供了這種功能,在 Java Netty 網路框架中,提供了FixedLengthFrameDecoder 類去處理長度是定長的協議包,提供了 DelimiterBasedFrameDecoder 類去處理按特殊字符作為結束符的協議包,提供 ByteToMessageDecoder 去處理自定義格式的協議包(可用來處理包頭 + 包體 這種格式的資料包),然而在繼承 ByteToMessageDecoder 子類中你需要根據你的協議具體格式重寫 decode() 方法來對資料包解包,
這三種包格式,希望讀者能在理解其原理和優缺點的基礎上深入掌握,
推薦視頻講解:
C/C++Linux丨從websocket協議到tcp自定義協議,tcp分包與粘包,明文傳輸
【文章福利】小編推薦自己的linuxC/C++語言交流群:832218493!整理了一些個人覺得比較好的學習書籍、視頻資料共享在群檔案里面,有需要的可以自行添加哦!~
三 解包與處理
在理解了前面介紹的資料包的三種格式后,我們來介紹一下針對上述三種格式的資料包技術上應該如何處理,其處理流程都是一樣的,這里我們以包頭 + 包體 這種格式的資料包來說明,處理流程如下:
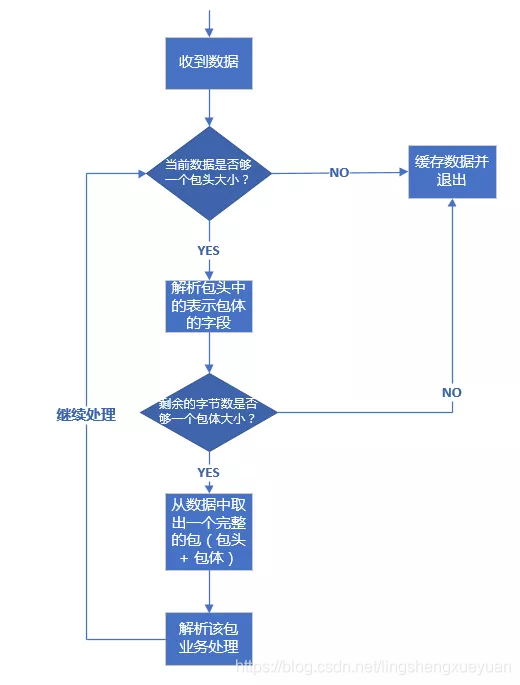
假設我們的包頭格式如下:
1//強制一位元組對齊
2#pragma pack(push, 1)
3//協議頭
4struct msg
5{
6 int32_t bodysize; //包體大小
7};
8#pragma pack(pop)
那么上面的流程實作代碼如下:
1//包最大位元組數限制為10M
2#define MAX_PACKAGE_SIZE 10 * 1024 * 1024
3
4void ChatSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receivTime)
5{
6 while (true)
7 {
8 //不夠一個包頭大小
9 if (pBuffer->readableBytes() < (size_t)sizeof(msg))
10 {
11 //LOGI << "buffer is not enough for a package header, pBuffer->readableBytes()=" << pBuffer->readableBytes() << ", sizeof(msg)=" << sizeof(msg);
12 return;
13 }
14
15 //取包頭資訊
16 msg header;
17 memcpy(&header, pBuffer->peek(), sizeof(msg));
18
19 //包頭有錯誤,立即關閉連接
20 if (header.bodysize <= 0 || header.bodysize > MAX_PACKAGE_SIZE)
21 {
22 //客戶端發非法資料包,服務器主動關閉之
23 LOGE("Illegal package, bodysize: %lld, close TcpConnection, client: %s", header.bodysize, conn->peerAddress().toIpPort().c_str());
24 conn->forceClose();
25 return;
26 }
27
28 //收到的資料不夠一個完整的包
29 if (pBuffer->readableBytes() < (size_t)header.bodysize + sizeof(msg))
30 return;
31
32 pBuffer->retrieve(sizeof(msg));
33 //inbuf用來存放當前要處理的包
34 std::string inbuf;
35 inbuf.append(pBuffer->peek(), header.bodysize);
36 pBuffer->retrieve(header.bodysize);
37 //解包和業務處理
38 if (!Process(conn, inbuf.c_str(), inbuf.length()))
39 {
40 //客戶端發非法資料包,服務器主動關閉之
41 LOGE("Process package error, close TcpConnection, client: %s", conn->peerAddress().toIpPort().c_str());
42 conn->forceClose();
43 return;
44 }
45 }// end while-loop
46}
上述流程代碼的處理程序和流程圖中是一致的,pBuffer 這里是一個自定義的接識訓沖區,這里的代碼,已經將收到的資料放入了這個緩沖區,所以判斷當前已收取的位元組數目只需要使用這個物件的相應方法即可,上述代碼有些細節我需要強調一下:
取包頭時,你應該拷貝一份資料包頭大小的資料出來,而不是從緩沖區 pBuffer 中直接將資料取出來(即取出來的資料從 pBuffer 中移除),這是因為倘若接下來根據包頭中的欄位得到包體大小時,如果剩余資料不夠一個包體大小,你又得把這個包頭資料放回緩沖區,為了避免這種不必要的操作,只有緩沖區資料大小夠整個包的大小(代碼中:header.bodysize + sizeof(msg))你才需要把整個包大小的資料從緩沖區移除,這也是這里的 pBuffer->peek() 方法 peek 單詞的含義(中文可以翻譯成“瞟一眼”或者“偷窺”),
通過包頭得到包體大小時,你一定要對 bodysize 的數值進行校驗,我這里要求 bodysize 必須大于 0 且不大于 10 * 1024 * 1024(即 10 M),當然,實際開發中,你可以根據你自己的需求要決定 bodysize 的上下限(包體大小是 0 位元組的包在某些業務場景下是允許的),記住,一定要判斷這個上下限,因為假設這是一個非法的客戶端發來的資料,其 bodysize 設定了一個比較大的數值,例如 1 * 1024 * 1024 * 1024(即 1 G),你的邏輯會讓你一直快取該客戶端發來的資料,那么很快你的服務器記憶體將會被耗盡,作業系統在檢測到你的行程占用記憶體達到一定閾值時會殺死你的行程,導致服務不能再正常對外服務,如果你檢測了 bodysize 欄位的是否滿足你設定的上下限,對于非法的 bodysize,直接關閉這路連接即可,這也是服務的一種自我保護措施,避免因為非法資料包帶來的損失,
不知道你有沒有注意到整個判斷包頭、包體以及處理包的邏輯放在一個 while 回圈里面,這是必要的,如果沒有這個 while 回圈,當你一次性收到多個包時,你只會處理一個,下次接著處理就需要等到新一批資料來臨時再次觸發這個邏輯,這樣造成的結果就是,對端給你發送了多個請求,你最多只能應答一個,后面的應答得等到對端再次給你發送資料時,這就是對粘包邏輯的正確處理,
以上邏輯和代碼是最基本的粘包和半包處理機制,也就是所謂的技術上的解包處理邏輯(業務上的解包處理邏輯后面章節再介紹),希望讀者能理解他們,在理解了他們的基礎之上,我們可以給解包拓展很多功能,例如,我們再給我們的協議包增加一個支持壓縮的功能,我們的包頭變成下面這個樣子:
1#pragma pack(push, 1)
2//協議頭
3struct msg
4{
5 char compressflag; //壓縮標志,如果為1,則啟用壓縮,反之不啟用壓縮
6 int32_t originsize; //包體壓縮前大小
7 int32_t compresssize; //包體壓縮后大小
8 char reserved[16]; //保留欄位,用于將來拓展
9};
10#pragma pack(pop
)
修改后的代碼如下:
1void ChatSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receivTime)
2{
3 while (true)
4 {
5 //不夠一個包頭大小
6 if (pBuffer->readableBytes() < (size_t)sizeof(msg))
7 {
8 //LOGI << "buffer is not enough for a package header, pBuffer->readableBytes()=" << pBuffer->readableBytes() << ", sizeof(msg)=" << sizeof(msg);
9 return;
10 }
11
12 //取包頭資訊
13 msg header;
14 memcpy(&header, pBuffer->peek(), sizeof(msg));
15
16 //資料包壓縮過
17 if (header.compressflag == PACKAGE_COMPRESSED)
18 {
19 //包頭有錯誤,立即關閉連接
20 if (header.compresssize <= 0 || header.compresssize > MAX_PACKAGE_SIZE ||
21 header.originsize <= 0 || header.originsize > MAX_PACKAGE_SIZE)
22 {
23 //客戶端發非法資料包,服務器主動關閉之
24 LOGE("Illegal package, compresssize: %lld, originsize: %lld, close TcpConnection, client: %s", header.compresssize, header.originsize, conn->peerAddress().toIpPort().c_str());
25 conn->forceClose();
26 return;
27 }
28
29 //收到的資料不夠一個完整的包
30 if (pBuffer->readableBytes() < (size_t)header.compresssize + sizeof(msg))
31 return;
32
33 pBuffer->retrieve(sizeof(msg));
34 std::string inbuf;
35 inbuf.append(pBuffer->peek(), header.compresssize);
36 pBuffer->retrieve(header.compresssize);
37 std::string destbuf;
38 if (!ZlibUtil::UncompressBuf(inbuf, destbuf, header.originsize))
39 {
40 LOGE("uncompress error, client: %s", conn->peerAddress().toIpPort().c_str());
41 conn->forceClose();
42 return;
43 }
44
45 //業務邏輯處理
46 if (!Process(conn, destbuf.c_str(), destbuf.length()))
47 {
48 //客戶端發非法資料包,服務器主動關閉之
49 LOGE("Process error, close TcpConnection, client: %s", conn->peerAddress().toIpPort().c_str());
50 conn->forceClose();
51 return;
52 }
53 }
54 //資料包未壓縮
55 else
56 {
57 //包頭有錯誤,立即關閉連接
58 if (header.originsize <= 0 || header.originsize > MAX_PACKAGE_SIZE)
59 {
60 //客戶端發非法資料包,服務器主動關閉之
61 LOGE("Illegal package, compresssize: %lld, originsize: %lld, close TcpConnection, client: %s", header.compresssize, header.originsize, conn->peerAddress().toIpPort().c_str());
62 conn->forceClose();
63 return;
64 }
65
66 //收到的資料不夠一個完整的包
67 if (pBuffer->readableBytes() < (size_t)header.originsize + sizeof(msg))
68 return;
69
70 pBuffer->retrieve(sizeof(msg));
71 std::string inbuf;
72 inbuf.append(pBuffer->peek(), header.originsize);
73 pBuffer->retrieve(header.originsize);
74 //業務邏輯處理
75 if (!Process(conn, inbuf.c_str(), inbuf.length()))
76 {
77 //客戶端發非法資料包,服務器主動關閉之
78 LOGE("Process error, close TcpConnection, client: %s", conn->peerAddress().toIpPort().c_str());
79 conn->forceClose();
80 return;
81 }
82 }// end else
83
84 }// end while-loop
85}
這段代碼先根據包頭的壓縮標志欄位判斷包體是否有壓縮,如果有壓縮,則取出包體大小去解壓,解壓后的資料才是真正的業務資料,整個程式執行流程圖如下:
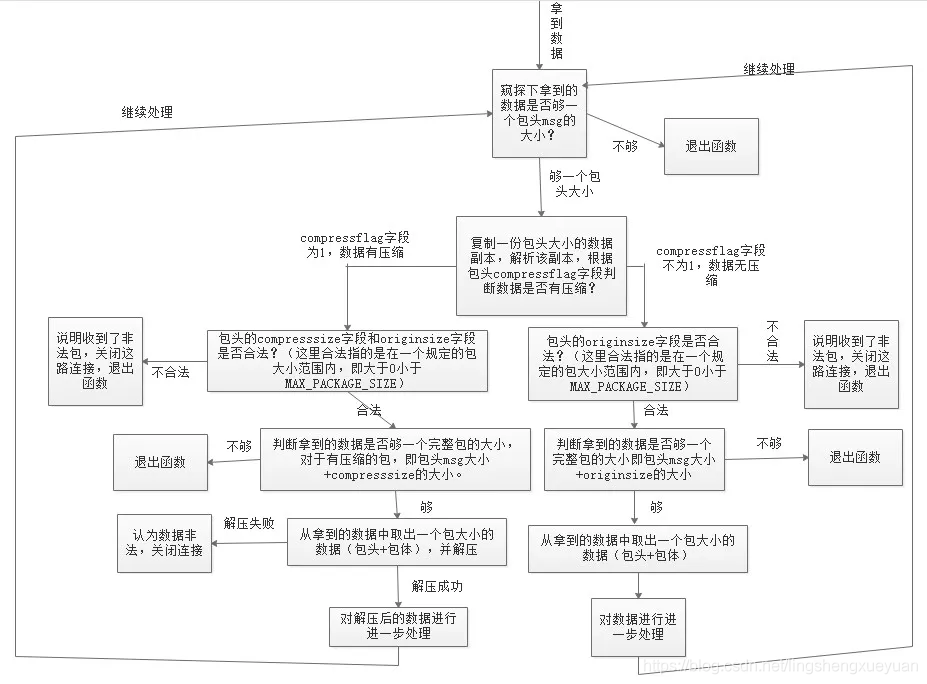
代碼中有一個接識訓沖區變數 pBuffer,關于接識訓沖區如何設計,我們將在后面的文章中詳細介紹,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/229332.html
標籤:其他
上一篇:表格化資料挖掘