各位大佬好,最近我又抑郁了,比上不足,我比上不足,Life is harder.
For Recommendation in Deep learning QQ Group 277356808
For Visual in deep learning QQ Group 629530787
I'm here waiting for you
不接受這個網頁的私聊/私信!!!
說了多少次不接受網頁的私信與私聊還是有人這樣私信,我看了也不回的,您繼續就好了,評論一下會死?加群詳聊會見光死?老子又不是和你相親,
有些公號的文章罵我,翻譯paper誰不會,老子其實不是秀,我翻譯下至少當時“假裝理解”了,是不是真的懂不知道,但過后還可以自己再看下啊,不然又要重頭看,那樣太累了,另外至少我翻譯時不會想很多雜亂的破事,至少我可以靜下來,別亂指責別人,總有你不了解的事,
寫在前面——
當你迷茫、困惑時,不妨想想來時的路,那么推薦到底是為了解決什么問題呢?在資訊流APP中,有視頻,文章,gif,小視頻等內容,推薦的任務就是將這些分發給每個用戶,如果item很少(比如1000以下),這時候其實用不上推薦,過不了兩天用戶都走了,用戶為啥走,這時的主要原因是內容少或者內容很差(沒有吸引力,這時候不能怪推薦演算法),那么留住用戶或者裝逼的說法,留存率啥的,第一條關鍵因素不就是好的內容相當夠嗎?當item數量上來后,這時候不可能每個用戶都會看完這么多資訊,APP老板也不會這么做,因為累死也看不完,這就是資訊過載,就是資訊量遠超個人消費,可能會有人想,內容多了,那就只給用戶看一部分,這樣就有很多item浪費了,沒有發揮它的價值,也有的說,隨機分發吧,這樣item都可能推出去,這樣是不錯,但對留存和停留時長可能并不是最佳,想要最好的效果,那就投其所好(或者說讀心術),知道它喜歡的東西,推給它可能喜歡的東西,這樣是不是相對好一點,但這樣其實也是有問題的,總有很多item還是推不出,推出的可能都是熱門,推不出的原因可以從內容質量、曝光時間、分發用戶等方面考慮,但絕大部分情況下很多都直接歸為了內容質量不行,其實很有可能這個item沒有分配給match它的用戶,這不就是相親嗎?得相互看上才可,推出的熱門則需要過濾下,注意用戶的長期行為即可,但用戶的長期行為記錄長了,可能訓練模型有點困難,100個item?甚至1000個item,更甚的還有1萬的,這真的是大佬級別的才能做的,訓練時間和記憶體都是很大的問題,詳見這里,
初探秘境——about item cold-start
假如你做的APP通過預先加載安裝到手機(預置)或者通過其他鏈接(比如廣告)安裝到了手機,這時候最關鍵的問題就是用戶的第一印象,用戶一看,刷了幾次,內容一般,沒有吸引力(舊事重提),可能就走了,這就是用戶冷啟動,可能有人覺得我是不是傻了,這里說內容冷啟動啊,其實沒有,用戶是冷的,只能通過熱的item才能將它暖熱(做個廣告,本人暖被窩能力超強,哈哈),這個暖也不一定就是熱點(搞笑,獵奇等等),也可能是其他方法(不表),當一個新的item引入APP,沒有過去的歷史資訊很難將它推給合適的用戶,均等機會推送可能影響APP的體驗,那么在僅僅有冷的item統計資訊情況下怎么再次分發這些item呢?寡人愚見,只有這些而無互動,沒有user,沒時間資訊,這就只能用一些統計資訊,哪個點擊的多,哪個停留時間長,哪個分享/點贊/收藏的多來判斷,其他方法就力不從心,資訊太少則只能用簡單的統計來做,從長遠來看,本文也是這個出發點,那么盡量不給新用戶推新item,而是給老用戶預熱item,將冷的item暖熱后再推給新用戶,所以這里必然要有user引數,沒有user怎么知道item的一些特征,僅僅靠其本質特征(tag之類)并不能解決所有問題,因而定義問題,對于n個items,可以表示為,m表示每個item的特征維度,u個users與n個item的互動表示為
,其中(i,j)表示user j對item i感興趣(點擊等行為),在測驗時,給定新的item q,
,目標就是預測哪個用戶對該新item感興趣,臥槽,這個是內容冷啟動的概念嗎?完全和上面的“item統計”做法毫無關聯啊,一點相關性都沒有,不妨先順著這個paper來,其實上面都是我扯淡的,只有問題定義才是別人說的,我想大部分粉絲也就看到這里就走了,可你肯定不知道我后面還有大招吧,哈哈哈
先不要急著否定一個人,不妨等他表演結束,給他一個show的機會,
Collective Factorization背后的意圖
在上面問題定義后,item是與一些描述(自身特征等比如topic/tag)和一些消費它的用戶有關,以新聞為例說明,每個新聞文章都有一些words,也有一些用戶的評論,這種資訊可以表示為兩個矩陣,一個是document-term矩陣,另一個是document-user矩陣
,這里的定義與上面相同,document就是item,n表示item的個數,v就是詞典大小(注意這里就是NLP中概念vocabulary size),u是用戶個數,Xs可以是個布爾矩陣,或者document中的TF-IDF詞分數,Xu則反映用戶是否給一個文章進行評論,如果將Xs分解為兩個低緯的矩陣,就會得知該文章中有哪些topic,以及哪些文章屬于這些topic,同樣,可以分解Xu為用戶有哪些群體特征,以及哪些文章對這些群體有吸引力,臥槽,這特么不是一般LFM就能表示的嗎?臥槽,以為多么高大上的,然而,如果分解是相互獨立的,也就是說分解到不同隱空間,那么在topic和群體之間就沒有什么相關性,因而LCE的idea就是將它兩個分解到同一個隱空間,換言之,每個因素可以由一些words(topic等)表示,也可由一些用戶群體表示,因此,同時分解到同一個低緯度空間,綜合可以表達為一個目標函式:其實也就是一個優化問題
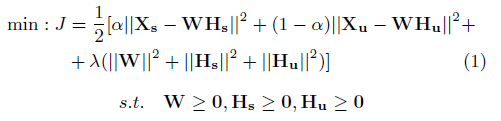
這是常見的形式,最后一項是正則項,為了解的光滑性及避免過擬合,這里有兩個考慮,一個是低緯空間,一個是線性近似,一個很自然的假設在此:流形假設,如果兩個資料點在無論什么角度是相近的,那么他們在其他低緯度也是相近的,這個假設是很重要的,在維度減少和半監督學習中,最近的相關研究表明,譜圖理論及流形學習可以有效擬合一些資料點,通過一些近鄰圖,邊可以是2值的,也可以是權值的,這樣,一個矩陣A可以用于度量兩個點的距離,collective Factorization將每個點映射到一個低緯的表達wi也就是W矩陣的每行,一個很自然的度量兩個低緯表達的距離的方法是計算其歐拉距離|wi-wj|^2,A是xi和xj的區域距離,因而可以將A作為低緯表達的光滑性引數:
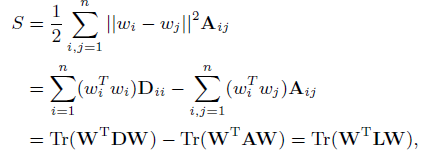
D是對角矩陣,每個輸入都是A的行和,例如.L=D-A是圖拉普拉斯矩陣,Tr是跡運算,也就是計算矩陣對角元素的和,因而1式可以修改為2式,
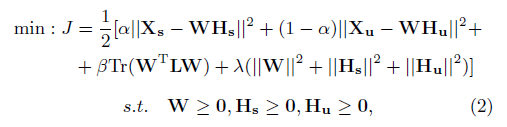
其實也就是增加一項,用于降維及光滑性考慮,這就是LCE優化問題,其實沒啥,,,哈哈
優化方法
針對上面非凸問題的優化,期望一個演算法能夠找到全域最優的點是不現實的,因此,推導一個迭代演算法(基于多個更新規則)獲得一個穩定點,這里不再貼出來了,估計也沒人去推導啥的,作為一個搬磚工,那就是了解即可,詳細推導見這里,
Inference
一旦模型訓練好,得到引數W,Hs和Hu,那就可以預測了,例如,給定一文章的詞袋(NLP中專用術語bag of words)向量,qs,預測qu可能會留下評論,首先將qs映射到同一隱空間(通過求解最小二乘qs=w*Hs,這是個超定問題),其中的w在同一隱空間,然后由w和Hu得到qu<——w*Hu,其中qu的每個元素代表用戶多大可能去評論這個new文章,效果如下,肯定是LCE最好了,不然這個文章還會讓你看到?
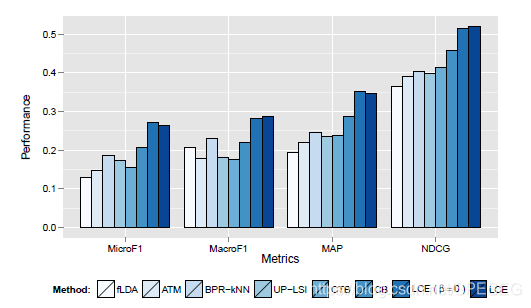
另外這個圖也說明,加不加上面的Tr專案都可以,有可能不加反而好很多,為了技算效率考慮,我覺得不加就可以了,但下面試驗是有的,
引數分析——消融試驗
LCE模型有三個重要的引數,一個k——隱向量的維度,alpha——權重,lambda——控制光滑解,其中k也控制著模型的復雜度,小的k欠擬合,大的k過擬合,效果都不好,所以需要試驗,
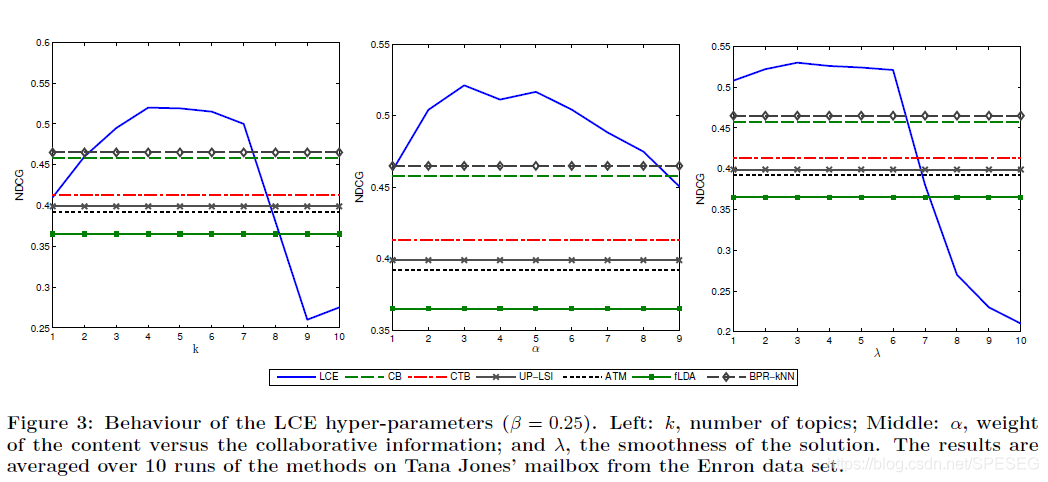
paper說了,beta和lambda表現特性差不多,所以就沒給,我可以大膽推測,其實beta等于0效果也不差,你看看lambda的效果,k和alpha取4或5都不錯,但下文計算CPU運行時間卻說k是10^2量級,這個,,,兩個k不一樣意思還是上圖的k缺少了量級?有點懵逼啊,下圖是訓練時間,
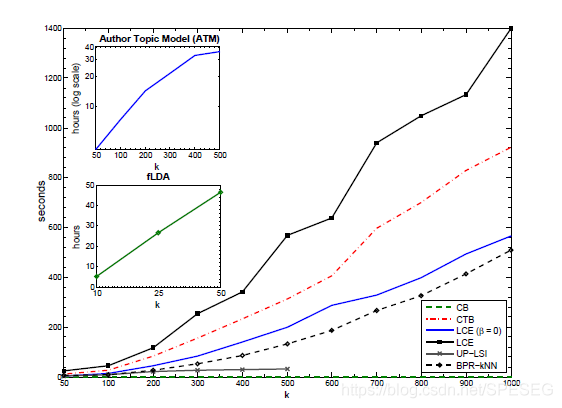
這里是用MATLAB寫的代碼,不知道有沒有大佬看的上,或者你搞成個python/Cpp版本的給我用用,哈哈,大致看了下代碼并不復雜,按照我的思路搞個baseline不難,刪掉beta項,去掉lambda項,這就容易多了,轉成python版本也不難,我們下次再見,愿我們終有會面之時,而你還記得我們曾經討論的話題,
像迷幻,如夢初醒的一對眼,
似夜晚,星光一般璀璨,
是常在心間,濃情從未淡,
這份愛的感嘆,這一生不褪減,
【20201206-19:26補充】
我特么發完就看到有個博文與此LCE對比,肯定啊,因為這是7年前的paper了,我覺得這個理論上好理解,而且很好回答面試中的問題,如果你用高大上的問題,難免會給自己挖坑,一問三不知很可怕,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231090.html
標籤:AI
上一篇:【AI 工程】Hidden Technical Debt in Machine Learning Systems(一)
下一篇:多任務損失優化:Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics