論文地址:Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
使用同方差不確定性優化多任務損失優化
- 一、 摘要
- 二、 介紹
- 三、 多任務學習
- 1. 同方差不確定性
- 2. 多任務似然回歸
- 四、 結論
一、 摘要
(沒有具體研究實體分割,所以本博客并沒有過多關心關于分割的模型與任務)
有些深度網路需要多任務來同時進行多個回歸和分類目標,經過觀察發現給予不同任務一個損失權重極大的影響著總體任務的表現,但是人工的搜索這個權重是極其困難和消費資源的,為此本論文提出了一個考慮每個任務同方差的不確定性來學習這些權重,這允許我們在分類和回歸設定中同時學習不同單位或尺度的不同引數,實驗證明本模型可以學習多任務權重,并且優于進行單任務獨立建模訓練,
創新:
- 利用同方差不確定性同時學習不同數量和單元的分類和回歸損失的一種新穎多任務損失
- 建立統一的組合語意分割、定位分割和深度回歸體系結構
- 證明模型損失權重的重要性,并且能夠解決并獲得良好的引數,
二、 介紹
多任務學習的目的是通過從一個共享表示中學習多個目標來提高學習效率和預測精度,
以前同時學習多個任務的方法使用一個樸素的加權損失總和,其中損失的權重是一致的,或者手動調整,但是我們發現這個模型的表現很大程度依賴于這些權重,人工微調以及搜索來優化網路十分昂貴且難以解決本質問題,每個任務的最佳權重取決于測量尺度(例如米、厘米或毫米)和最終任務噪聲的大小,
作者將同方差不確定性解釋為任務相關的加權,并展示如何推導一個有原則的多任務損失函式,該函式可以學會平衡各種回歸和分類損失,
三、 多任務學習
以前主要任務的簡要運算式:
L
total
=
∑
i
w
i
L
i
(1)
L_{\text {total}}=\sum_{i} w_{i} L_{i} \tag{1}
Ltotal?=i∑?wi?Li?(1)
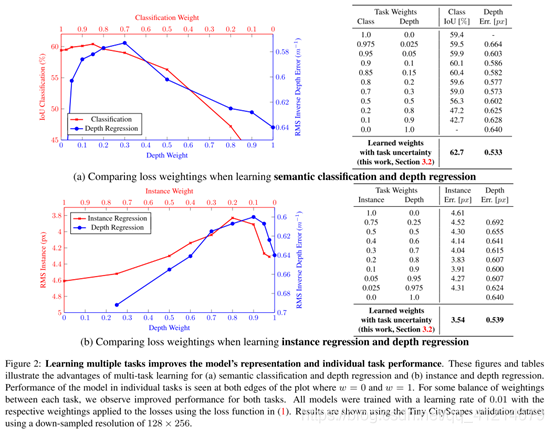
只是簡單的對每個子任務線性求和,但是這樣存在很多問題,例如模型對于權重引數很敏感,如下圖2:
1. 同方差不確定性
在貝葉斯模型中,不確定性主要有兩種型別:
- 認知不確定性是模型中的不確定性,它捕獲了我們的模型由于缺乏訓練資料而不知道的東西,這可以用增加的訓練資料來解釋,
- 任意不確定性抓住了我們對資料無法解釋的資訊的不確定性,任意不確定性可以用觀察所有解釋變數的能力來解釋,而且精確度越來越高,
任意不確定性又可分為兩種:
- 依賴資料或異方差不確定性,它依賴于輸入資料,并被預測為模型輸出,
- 任務依賴或同方差不確定性,它不依賴于輸入資料,它不是一個模型輸出,而是一個對所有輸入資料保持不變,并在不同任務之間變化的數量,因此,它可以被描述為任務依賴的不確定性
在多任務學習問題中,我們可以使用同方差不確定性作為加權損失的基礎,
2. 多任務似然回歸
在本節中,推導了一個基于同方差不確定性高斯似然最大化的多任務損失函式,讓
f
W
(
x
)
f^W (x)
fW(x)表示輸入
x
x
x在基于引數
W
W
W的神經網路的輸出,定義以下概率模型,對于回歸任務,將概率定義為高斯分布,其均值由模型輸出給出:
p
(
y
∣
f
W
(
x
)
)
=
N
(
f
W
(
x
)
,
σ
2
)
(2)
p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=\mathcal{N}\left(\mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma^{2}\right)\tag{2}
p(y∣fW(x))=N(fW(x),σ2)(2)
噪聲標量 σ σ σ,代表輸出需要攜帶多少噪聲,
為了進行分類,我們經常通過
s
o
f
t
m
a
x
softmax
softmax函式壓縮模型輸出,由概率向量得到的樣本:
p
(
y
∣
f
W
(
x
)
)
=
Softmax
?
(
f
W
(
x
)
)
(3)
p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=\operatorname{Softmax}\left(\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \tag{3}
p(y∣fW(x))=Softmax(fW(x))(3)
在多個模型輸出的情況下,通常定義對輸出進行因式分解的可能性,給出一些充分的統計資訊,我們定義
f
W
(
x
)
f^W (x)
fW(x)作為我們的充分統計量,并獲得以下多任務似然:
p
(
y
1
,
…
,
y
K
∣
f
W
(
x
)
)
=
p
(
y
1
∣
f
W
(
x
)
)
…
p
(
y
K
∣
f
W
(
x
)
)
(4)
p\left(\mathbf{y}_{1}, \ldots, \mathbf{y}_{K} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=p\left(\mathbf{y}_{1} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \ldots p\left(\mathbf{y}_{K} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \tag{4}
p(y1?,…,yK?∣fW(x))=p(y1?∣fW(x))…p(yK?∣fW(x))(4)
y 1 , … , y K y_1,…,y_K y1?,…,yK?為模型(例如語意分割,深度回歸)輸出,
最大似然推導中,最大化模型的對數似然,
例如回歸任務中,對數似然可以被表達為:
log
?
p
(
y
∣
f
W
(
x
)
)
∝
?
1
2
σ
2
∥
y
?
f
W
(
x
)
∥
2
?
log
?
σ
(5)
\log p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \propto-\frac{1}{2 \sigma^{2}}\left\|\mathbf{y}-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right\|^{2}-\log \sigma \tag{5}
logp(y∣fW(x))∝?2σ21?∥∥?y?fW(x)∥∥?2?logσ(5)
然后,我們最大化和模型引數 W W W和噪聲參數 σ σ σ有關的對數似然,
假設模型輸出由兩向量
y
1
y_1
y1?和
y
2
y_2
y2?組成(兩個回歸任務),服從高斯分布:
p
(
y
1
,
y
2
∣
f
W
(
x
)
)
=
p
(
y
1
∣
f
W
(
x
)
)
?
p
(
y
2
∣
f
W
(
x
)
)
=
N
(
y
1
;
f
W
(
x
)
,
σ
1
2
)
?
N
(
y
2
;
f
W
(
x
)
,
σ
2
2
)
(6)
\begin{aligned} p\left(\mathbf{y}_{1}, \mathbf{y}_{2} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) &=p\left(\mathbf{y}_{1} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \cdot p\left(\mathbf{y}_{2} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \\ &=\mathcal{N}\left(\mathbf{y}_{1} ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_{1}^{2}\right) \cdot \mathcal{N}\left(\mathbf{y}_{2} ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_{2}^{2}\right) \end{aligned} \tag{6}
p(y1?,y2?∣fW(x))?=p(y1?∣fW(x))?p(y2?∣fW(x))=N(y1?;fW(x),σ12?)?N(y2?;fW(x),σ22?)?(6)
這導致了我們多任務模型的最小化目標
L
(
W
,
σ
1
,
σ
2
)
\mathcal{L}(W,σ_1,σ_2)
L(W,σ1?,σ2?)
=
?
log
?
p
(
y
1
,
y
2
∣
f
W
(
x
)
)
∝
1
2
σ
1
2
∥
y
1
?
f
W
(
x
)
∥
2
+
1
2
σ
2
2
∥
y
2
?
f
W
(
x
)
∥
2
+
log
?
σ
1
σ
2
=
1
2
σ
1
2
L
1
(
W
)
+
1
2
σ
2
2
L
2
(
W
)
+
log
?
σ
1
σ
2
(7)
\begin{aligned} &=-\log p\left(\mathbf{y}_{1}, \mathbf{y}_{2} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)\\ &\propto \frac{1}{2 \sigma_{1}^{2}}\left\|\mathbf{y}_{1}-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right\|^{2}+\frac{1}{2 \sigma_{2}^{2}}\left\|\mathbf{y}_{2}-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right\|^{2}+\log \sigma_{1} \sigma_{2}\\ &=\frac{1}{2 \sigma_{1}^{2}} \mathcal{L}_{1}(\mathbf{W})+\frac{1}{2 \sigma_{2}^{2}} \mathcal{L}_{2}(\mathbf{W})+\log \sigma_{1} \sigma_{2} \end{aligned} \tag{7}
?=?logp(y1?,y2?∣fW(x))∝2σ12?1?∥∥?y1??fW(x)∥∥?2+2σ22?1?∥∥?y2??fW(x)∥∥?2+logσ1?σ2?=2σ12?1?L1?(W)+2σ22?1?L2?(W)+logσ1?σ2??(7)
L
1
(
W
)
=
∥
y
1
?
f
w
(
x
)
∥
2
\mathcal{L}_{1}(\mathbf{W})=\left\|\mathbf{y}_{1}-\mathbf{f}^{\mathbf{w}}(\mathbf{x})\right\|^{2}
L1?(W)=∥y1??fw(x)∥2表示第一個輸出變數
y
1
y_1
y1?的損失,
L
2
\mathcal{L}_{2}
L2?同理,
引數 σ 1 , σ 2 σ_1,σ_2 σ1?,σ2?相當于損失 L 1 ( W ) \mathcal L_1 (W) L1?(W)和 L 2 ( W ) \mathcal L_2 (W) L2?(W)基于資料的自適應權重,因為當 σ 1 σ_1 σ1?(變數 y 1 y_1 y1?的噪聲)增加時, L 1 ( W ) \mathcal L_1 (W) L1?(W)的權重下降,相應的噪聲減小,對應損失權重上升,損失最后一項充當噪聲的調節器,抑制噪聲的過大增加,
這種構造可以簡單地擴展到多元回歸輸出,
對于分類函式,我們通過對縮放后的輸出進行
s
o
f
t
m
a
x
softmax
softmax函式作為分類似然:
p
(
y
∣
f
W
(
x
)
,
σ
)
=
Softmax
?
(
1
σ
2
f
W
(
x
)
)
(8)
p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma\right)=\operatorname{Softmax}\left(\frac{1}{\sigma^{2}} \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \tag{8}
p(y∣fW(x),σ)=Softmax(σ21?fW(x))(8)
σ
σ
σ是一個正的縮放值,可以理解為一個
B
o
l
t
z
?
m
a
n
n
Boltz- mann
Boltz?mann分布(
G
i
b
b
s
Gibbs
Gibbs分布),輸入由
σ
2
σ^2
σ2進行縮放,這個縮放可以固定也可以被學習,其中引數的大小決定了離散分布的“均勻”(平坦)程度,這個輸出的對數似然可以寫成:
log
?
p
(
y
=
c
∣
f
W
(
x
)
,
σ
)
=
1
σ
2
f
c
W
(
x
)
?
log
?
∑
c
′
exp
?
(
1
σ
2
f
c
′
W
(
x
)
)
(9)
\begin{aligned} \log p\left(\mathbf{y}=c \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma\right) &=\frac{1}{\sigma^{2}} f_{c}^{\mathbf{W}}(\mathbf{x}) \\ &-\log \sum_{c^{\prime}} \exp \left(\frac{1}{\sigma^{2}} f_{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right) \end{aligned} \tag{9}
logp(y=c∣fW(x),σ)?=σ21?fcW?(x)?logc′∑?exp(σ21?fc′W?(x))?(9)
f
c
W
(
x
)
f_c^W (x)
fcW?(x)表示向量
f
W
(
x
)
f^W (x)
fW(x)的第
c
c
c個元素,
假設模型多輸出由一個連續輸出
y
1
y_1
y1?和離散輸出
y
2
y_2
y2?組成,分別由高斯似然和
s
o
f
t
m
a
x
softmax
softmax似然建模進行聯合損失得
L
(
W
,
σ
1
,
σ
2
)
\mathcal L(W,σ_1, σ_2)
L(W,σ1?,σ2?)
=
?
log
?
p
(
y
1
,
y
2
=
c
∣
f
W
(
x
)
)
=
?
log
?
N
(
y
1
;
f
W
(
x
)
,
σ
1
2
)
?
Softmax
?
(
y
2
=
c
;
f
W
(
x
)
,
σ
2
)
=
1
2
σ
1
2
∥
y
1
?
f
W
(
x
)
∥
2
+
log
?
σ
1
?
log
?
p
(
y
2
=
c
∣
f
W
(
x
)
,
σ
2
)
=
1
2
σ
1
2
L
1
(
W
)
+
1
σ
2
2
L
2
(
W
)
+
log
?
σ
1
+
log
?
∑
c
′
exp
?
(
1
σ
2
2
f
c
′
W
(
x
)
)
(
∑
c
′
exp
?
(
f
c
′
W
(
x
)
)
)
1
σ
2
2
≈
1
2
σ
1
2
L
1
(
W
)
+
1
σ
2
2
L
2
(
W
)
+
log
?
σ
1
+
log
?
σ
2
(10)
\begin{array}{l} =-\log p\left(\mathbf{y}_{1}, \mathbf{y}_{2}=c \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \\ =-\log \mathcal{N}\left(\mathbf{y}_{1} ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_{1}^{2}\right) \cdot \operatorname{Softmax}\left(\mathbf{y}_{2}=c ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_{2}\right) \\ =\frac{1}{2 \sigma_{1}^{2}}\left\|\mathbf{y}_{1}-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right\|^{2}+\log \sigma_{1}-\log p\left(\mathbf{y}_{2}=c \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_{2}\right) \\ =\frac{1}{2 \sigma_{1}^{2}} \mathcal{L}_{1}(\mathbf{W})+\frac{1}{\sigma_{2}^{2}} \mathcal{L}_{2}(\mathbf{W})+\log \sigma_{1} \\ \quad+\log \frac{\sum_{c^{\prime}} \exp \left(\frac{1}{\sigma_{2}^{2}} f_{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right)}{\left(\sum_{c^{\prime}} \exp \left(f_{c^{\prime}} \mathbf{W}(\mathbf{x})\right)\right)^{\frac{1}{\sigma_{2}^{2}}}} \\ \approx \frac{1}{2 \sigma_{1}^{2}} \mathcal{L}_{1}(\mathbf{W})+\frac{1}{\sigma_{2}^{2}} \mathcal{L}_{2}(\mathbf{W})+\log \sigma_{1}+\log \sigma_{2} \end{array} \tag{10}
=?logp(y1?,y2?=c∣fW(x))=?logN(y1?;fW(x),σ12?)?Softmax(y2?=c;fW(x),σ2?)=2σ12?1?∥∥?y1??fW(x)∥∥?2+logσ1??logp(y2?=c∣fW(x),σ2?)=2σ12?1?L1?(W)+σ22?1?L2?(W)+logσ1?+log(∑c′?exp(fc′?W(x)))σ22?1?∑c′?exp(σ22?1?fc′W?(x))?≈2σ12?1?L1?(W)+σ22?1?L2?(W)+logσ1?+logσ2??(10)
L 1 ( W ) = ∥ y 1 ? f w ( x ) ∥ 2 \mathcal{L}_{1}(\mathbf{W})=\left\|\mathbf{y}_{1}-\mathbf{f}^{\mathbf{w}}(\mathbf{x})\right\|^{2} L1?(W)=∥y1??fw(x)∥2表示 y 1 y_1 y1?的歐幾里得損失, L 2 ( W ) = ? log ? S o f t m a x ( y 2 , f W ( x ) ) \mathcal L_2(W)=-\log Softmax(y_2,f^W(x)) L2?(W)=?logSoftmax(y2?,fW(x))為關于 y 2 y_2 y2?的交叉熵損失( f W ( x ) f^W(x) fW(x)未被縮放),使用 W W W、 σ 1 σ_1 σ1?和 σ 1 σ_1 σ1?進行優化,最后的 ≈ ≈ ≈,當 σ 2 → 1 σ_2→1 σ2?→1時候趨近 = = =,
最后一個目標可以被看作是學習每個產出損失的相對權重,縮放值 σ 2 σ_2 σ2?越大,則損失 L 2 ( W ) \mathcal L_2 (W) L2?(W)貢獻越小,縮放受 log ? σ 2 \log σ_2 logσ2?規范,縮放太大,則目標會被懲罰,
如此,這個函式就可以被隨意的由離散和連續損失函式進行組合,這個損失是平滑可微的,并且是很好的形式,使得任務權值不會收斂到零,不同于 ( 1 ) (1) (1)有可能將損失很快的收斂到0,
實驗中,訓練網路去預測 l o g log log變數 s ∶ = l o g σ 2 s{∶=} log σ_2 s∶=logσ2?,因為這個變數比直接回歸 σ 2 σ_2 σ2?在數學上更加的穩定,損失避免了除以 0 0 0,
四、 結論
證明了對損失項的正確加權對于多任務學習問題是至關重要的,同時證明了同方差(任務)不確定性是損失賦權的有效方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231091.html
標籤:AI
上一篇:冷啟動問題的一點嘗試LCE