今天來給Hadoop的部分收收尾,這是《破繭成蝶——Hadoop篇》系列的最后一篇文章了,因為HA需要用到Zookeeper,所以在講解了Zookeeper的部分內容后,才重新回過頭來看Hadoop的HA部分,關注專欄《破繭成蝶——Zookeeper篇》,查看更多Zookeeper相關的內容~
目錄
一、HA概述
二、HDFS HA
2.1 HDFS HA作業機制
2.1.1 作業要點
2.1.2 作業機制
2.2 HDFS HA配置
2.2.1 環境準備
2.2.2 集群節點規劃
2.2.3 配置Zookeeper集群
2.2.4 配置HDFS HA
2.2.5 啟動HDFS HA集群
2.2.6 配置自動故障轉移
三、Yarn HA
3.1 規劃集群
3.2 配置Yarn HA
一、HA概述
HA(High Available),即高可用(7*24小時不中斷服務),實作高可用最關鍵的策略是消除單點故障,HA嚴格來說應該分成各個組件的HA機制:HDFS的HA和YARN的HA,Hadoop2.0之前,在HDFS集群中NameNode存在單點故障(SPOF),NameNode主要在以下兩個方面影響HDFS集群:(1)NameNode機器發生意外,如宕機,集群將無法使用,直到管理員重啟,(2)NameNode機器需要升級,包括軟體、硬體升級,此時集群也將無法使用,
HDFS HA功能通過配置Active/Standby兩個NameNode實作在集群中對NameNode的熱備來解決上述問題,如果出現故障,如機器崩潰或機器需要升級維護,這時可通過此種方式將NameNode很快的切換到另外一臺機器,
二、HDFS HA
2.1 HDFS HA作業機制
2.1.1 作業要點
1、元資料管理方式需要改變,
(1)記憶體中各自保存一份元資料;
(2)Edits日志只有Active狀態的NameNode節點可以做寫操作;
(3)兩個NameNode都可以讀取Edits;
(4)共享的Edits放在一個共享存盤中管理(qjournal和NFS兩個主流實作);
2、需要一個狀態管理功能模塊,
實作了一個zkfailover,常駐在每一個namenode所在的節點,每一個zkfailover負責監控自己所在NameNode節點,利用zk進行狀態標識,當需要進行狀態切換時,由zkfailover來負責切換,切換時需要防止brain split現象的發生,
3、必須保證兩個NameNode之間能夠ssh無密碼登錄,
4、隔離(Fence),即同一時刻僅僅有一個NameNode對外提供服務,
2.1.2 作業機制
1、自動故障轉移為HDFS部署增加了兩個新組件:ZooKeeper和ZKFailoverController(ZKFC)行程,ZooKeeper是維護少量協調資料,通知客戶端這些資料的改變和監視客戶端故障的高可用服務,HA的自動故障轉移依賴于ZooKeeper的以下功能:
(1)故障檢測:集群中的每個NameNode在ZooKeeper中維護了一個持久會話,如果機器崩潰,ZooKeeper中的會話將終止,ZooKeeper通知另一個NameNode需要觸發故障轉移,
(2)現役NameNode選擇:ZooKeeper提供了一個簡單的機制用于唯一的選擇一個節點為active狀態,如果目前現役NameNode崩潰,另一個節點可能從ZooKeeper獲得特殊的排外鎖以表明它應該成為現役NameNode,
2、ZKFC是自動故障轉移中的另一個新組件,是ZooKeeper的客戶端,也監視和管理NameNode的狀態,每個運行NameNode的主機也運行了一個ZKFC行程,ZKFC負責:
(1)健康監測:ZKFC使用一個健康檢查命令定期地ping與之在相同主機的NameNode,只要該NameNode及時地回復健康狀態,ZKFC認為該節點是健康的,如果該節點崩潰,凍結或進入不健康狀態,健康監測器標識該節點為非健康的,
(2)ZooKeeper會話管理:當本地NameNode是健康的,ZKFC保持一個在ZooKeeper中打開的會話,如果本地NameNode處于active狀態,ZKFC也保持一個特殊的znode鎖,該鎖使用了ZooKeeper對短暫節點的支持,如果會話終止,鎖節點將自動洗掉,
(3)基于ZooKeeper的選擇:如果本地NameNode是健康的,且ZKFC發現沒有其它的節點當前持有znode鎖,它將為自己獲取該鎖,如果成功,則它已經贏得了選擇,并負責運行故障轉移行程以使它的本地NameNode為Active,故障轉移行程與前面描述的手動故障轉移相似,首先如果必要保護之前的現役NameNode,然后本地NameNode轉換為Active狀態,
2.2 HDFS HA配置
2.2.1 環境準備
包括:修改IP,更改主機名、主機映射,關閉防火墻,關閉安全子系統,配置免秘鑰登錄,安裝JDK配置環境變數等等,這些在前文中都有說道,在這就不再贅述了,可以參考《二、Linux下搭建Hadoop的運行環境》,
2.2.2 集群節點規劃
| master | slave01 | slave02 |
| NameNode | NameNode |
|
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
|
| ResourceManager |
|
| NodeManager | NodeManager | NodeManager |
2.2.3 配置Zookeeper集群
步驟同《二、Linux安裝Zookeeper》中分布式安裝Zookeeper的步驟,
2.2.4 配置HDFS HA
1、首先在/opt/modules目錄下新建ha目錄,并將hadoop-2.7.2目錄拷貝到ha目錄下:
2、在hadoop-env.sh中配置JAVA_HOME:

3、配置core-site.xml檔案
<configuration>
<!-- 把兩個NameNode的地址組裝成一個集群namenodecluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenodecluster</value>
</property>
<!-- 指定hadoop運行時產生檔案的存盤目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/ha/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
4、配置hdfs-site.xml檔案
<configuration>
<!-- 完全分布式集群名稱 -->
<property>
<name>dfs.nameservices</name>
<value>namenodecluster</value>
</property>
<!-- 集群中NameNode節點都有哪些 -->
<property>
<name>dfs.ha.namenodes.namenodecluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.namenodecluster.nn1</name>
<value>master:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.namenodecluster.nn2</name>
<value>slave01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.namenodecluster.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.namenodecluster.nn2</name>
<value>slave01:50070</value>
</property>
<!-- 指定NameNode元資料在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave01:8485;slave02:8485/namenodecluster</value>
</property>
<!-- 配置隔離機制,即同一時刻只能有一臺服務器對外回應 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔離機制時需要ssh無秘鑰登錄-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 宣告journalnode服務器存盤目錄-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/ha/hadoop-2.7.2/data/jn</value>
</property>
<!-- 關閉權限檢查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 訪問代理類:client,mycluster,active配置失敗自動切換實作方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>5、將設定好的檔案分發到其他節點
xsync /opt/modules/ha2.2.5 啟動HDFS HA集群
1、首先啟動journalnode服務:
sbin/hadoop-daemons.sh start journalnode
2、在nn1上格式化NameNode并啟動:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
3、在nn2上同步nn1的元資料資訊并啟動,這里需要注意的是:NameNode只能格式化一次!
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode4、瀏覽器訪問進行測驗
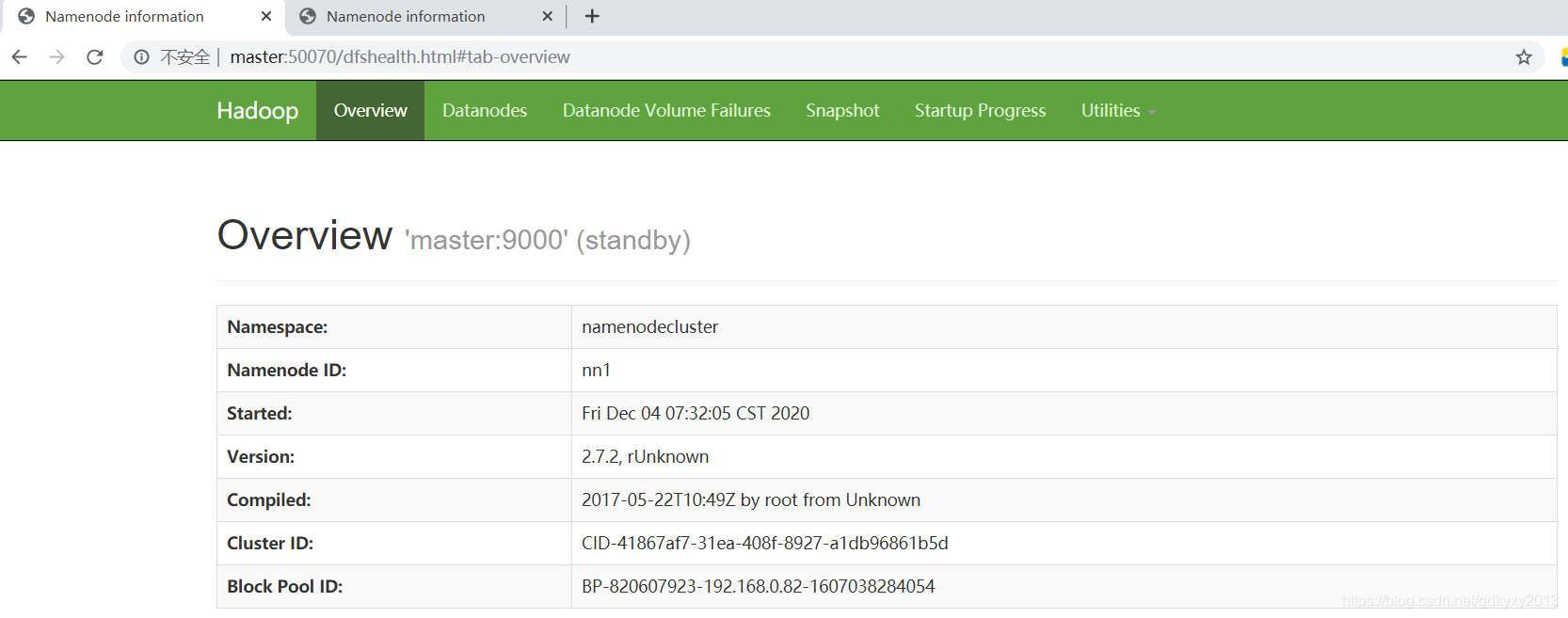
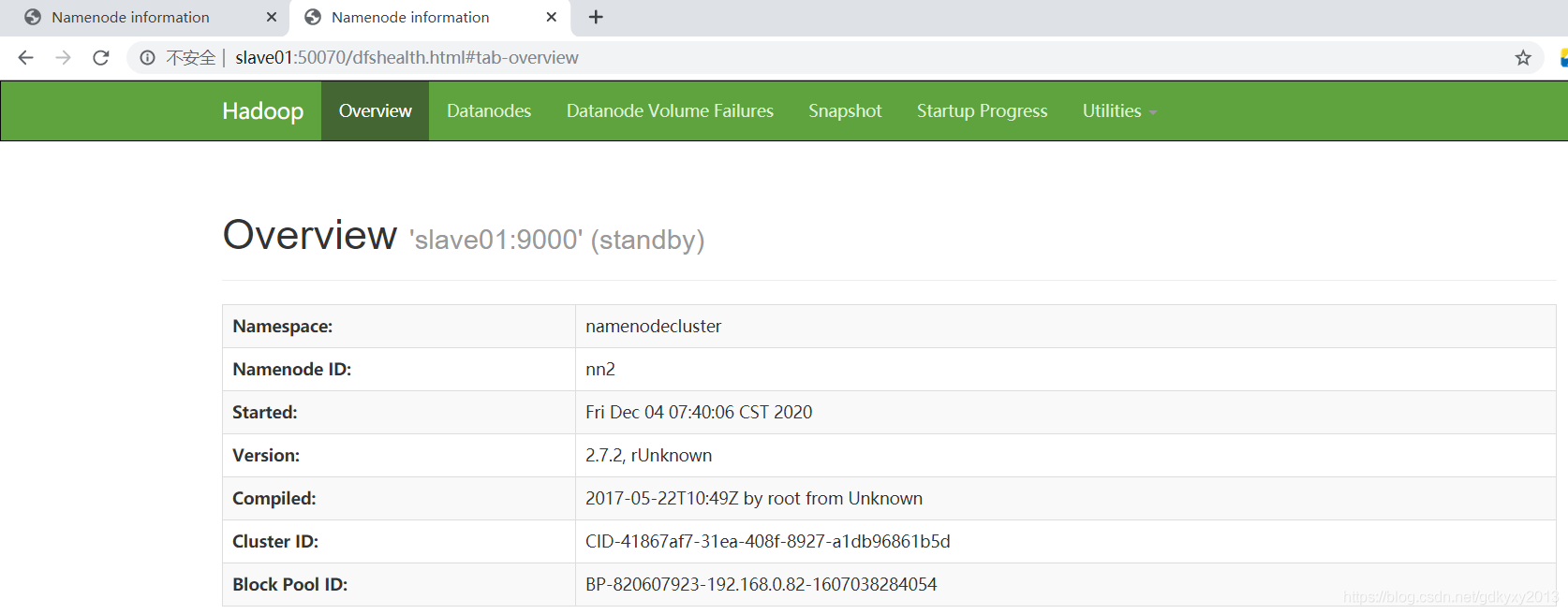
5、在nn1上啟動所有的DataNode
sbin/hadoop-daemons.sh start datanode6、將nn1的NameNode更改為Active
bin/hdfs haadmin -transitionToActive nn1再次重繪瀏覽器:
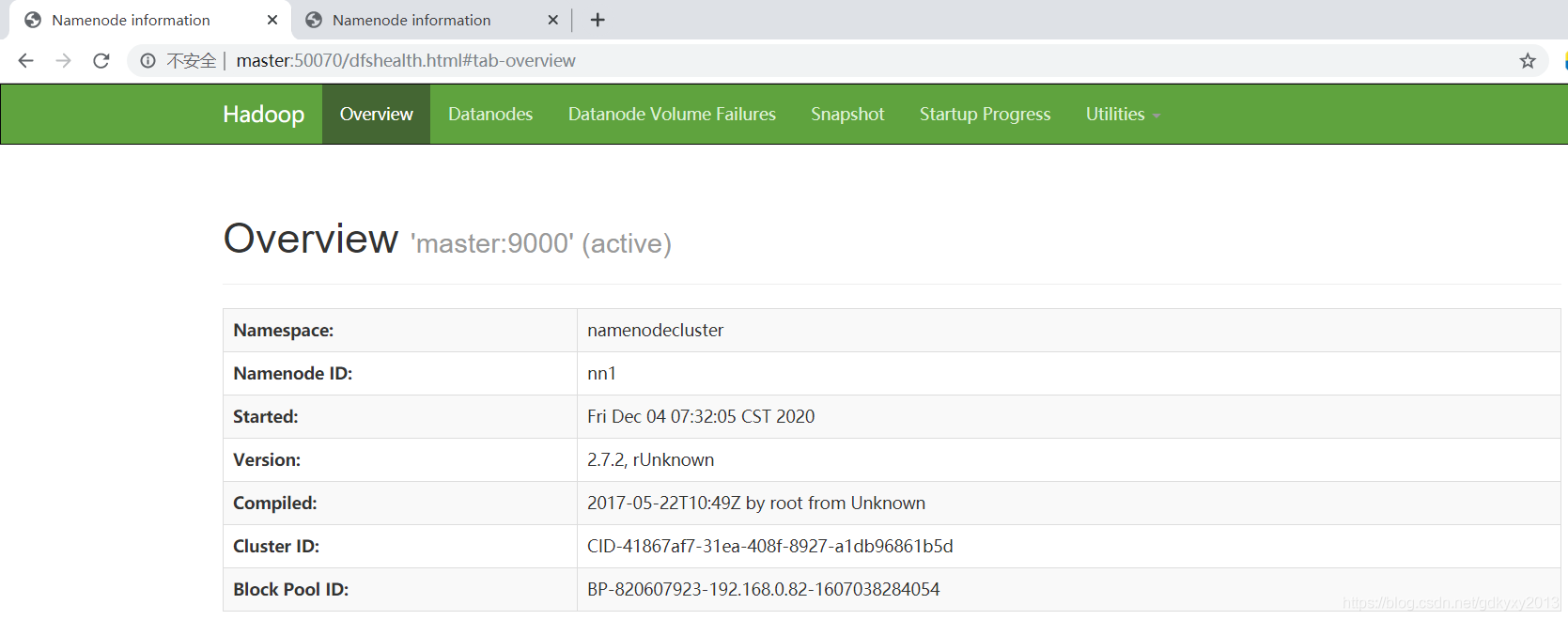
也可以使用命令查看nn1是否為Active:
bin/hdfs haadmin -getServiceState nn1
2.2.6 配置自動故障轉移
1、修改hdfs-site.xml組態檔,在下方添加如下內容:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>2、在core-site.xml檔案中增加如下內容:
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave01:2181,slave02:2181</value>
</property>配置完之后別忘了將修改的檔案分發到其余的機器,
3、 洗掉目錄下的data和logs檔案,
rm -rf ./data ./logs
4、啟動服務
(1)首先啟動Zookeeper集群和journalnode服務,
bin/zkServer.sh start
sbin/hadoop-daemons.sh start journalnode(2)格式化NameNode,同樣的,只在一臺機器上格式化即可,
bin/hdfs namenode -format(3)初始化HA在Zookeeper中狀態,值得注意的是,只需要在其中一臺機器上執行就可以了,
bin/hdfs zkfc -formatZK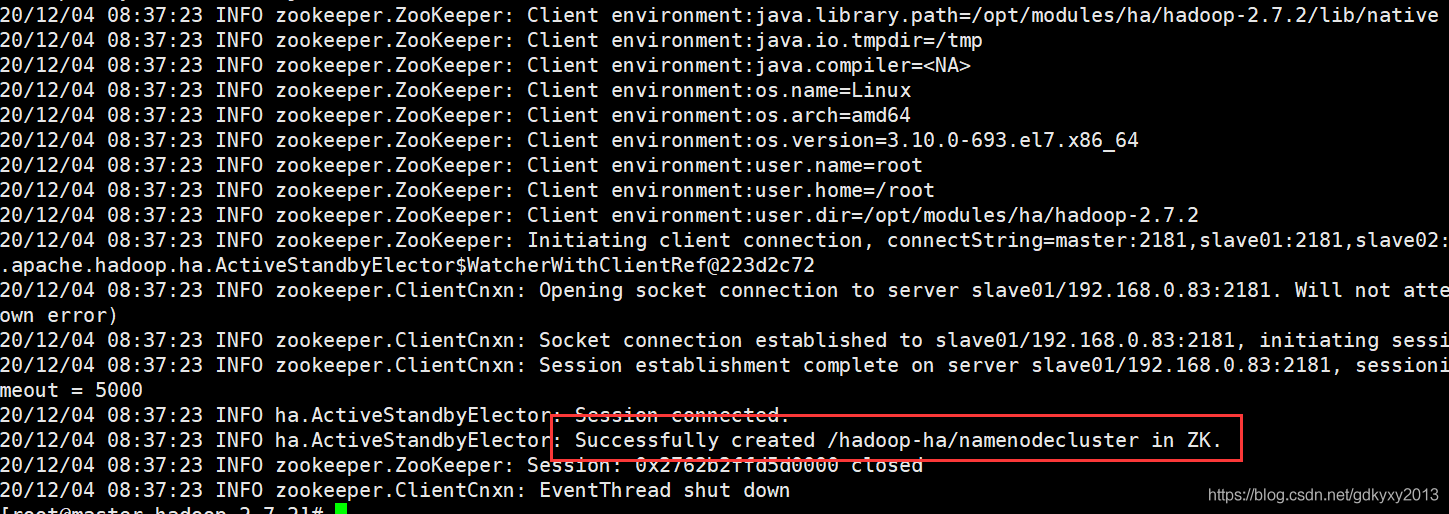
此處,相當于在Zookeeper中新建了一個Node,如下所示:

(4)啟動HDFS服務
sbin/start-dfs.sh(5)在nn2上執行如下命令同步nn1的元資料資訊
bin/hdfs namenode -bootstrapStandby(6)單獨啟動nn2的NameNode
sbin/hadoop-daemon.sh start namenode5、測驗驗證
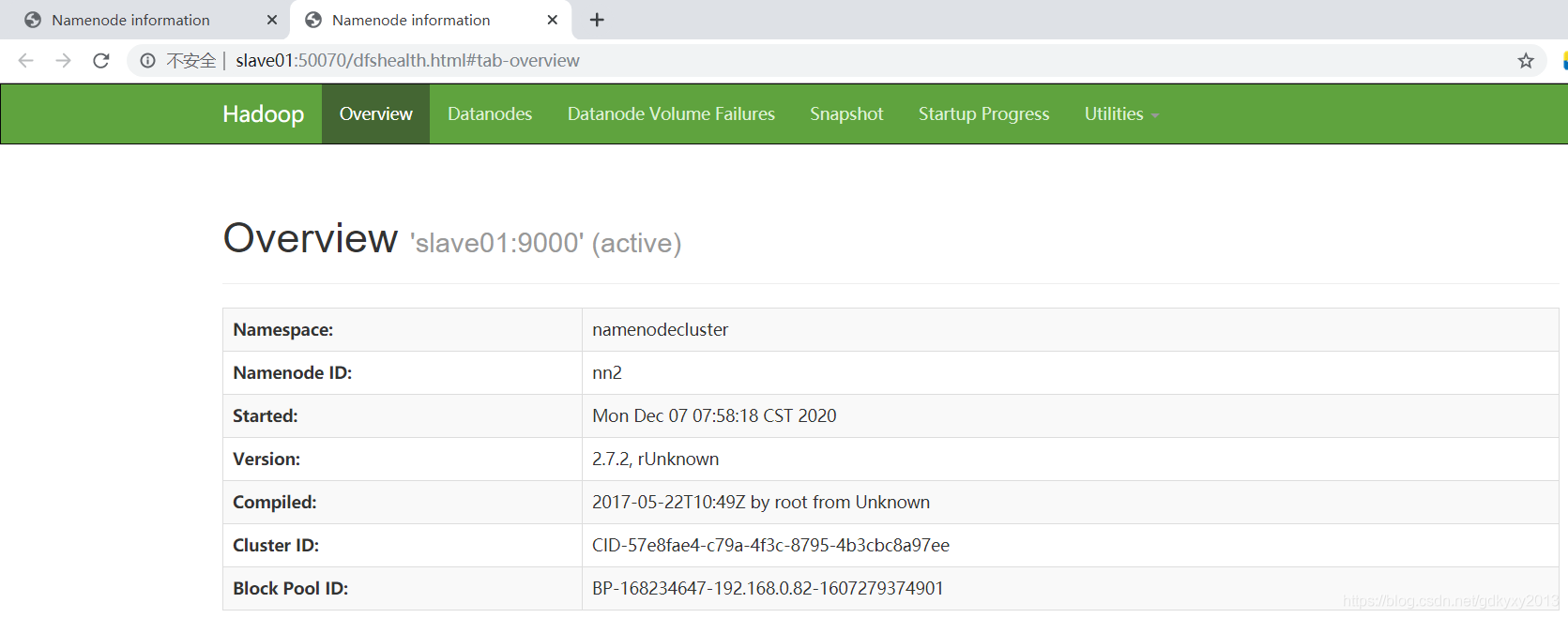
目前,是master節點的NameNode處于Active的狀態,現在我們手動殺死master節點的NameNode,發現slave01節點上的NameNode自動的由Standby轉換為Active,
三、Yarn HA
3.1 規劃集群
| hadoop102 | hadoop103 | hadoop104 |
| NameNode | NameNode |
|
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| ResourceManager | ResourceManager |
|
| NodeManager | NodeManager | NodeManager |
3.2 配置Yarn HA
1、在yarn-site.xml中添加如下配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--啟用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--宣告兩臺resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave01</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave01:2181,slave02:2181</value>
</property>
<!--啟用自動恢復-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的狀態資訊存盤在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>2、將修改的內容同步到其余各個節點,
3、啟動服務
(1)啟動Zookeeper
bin/zkServer.sh start(2)啟動hdfs相關服務
sbin/start-dfs.sh(3)啟動yarn服務
sbin/start-yarn.sh
此時,需要去另外一潭訓器上啟動ResourceManager,
sbin/yarn-daemon.sh start resourcemanager4、查看狀態
bin/yarn rmadmin -getServiceState rm1
通過頁面訪問,不管輸入的是master還是slave01,都會跳轉到active狀態的節點上,這里是master:

本文到此也就結束了,你們在此程序中存在什么問題,歡迎留言,讓我看看你們都遇到了什么問題~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231118.html
標籤:其他