呼叫MapReduce對檔案中各個單詞出現次數進行統計
實驗配置:系統:Ubuntu Kylin | 環境:Hadoop | 軟體:Eclipse文章目錄
- 一、安裝Linux
- 二、準備作業
- 1.創建Hadoop賬戶
- 2.設定hadoop密碼 :
- 3.為hadoop用戶增加管理員權限
- 4.更新 apt
- 5.安裝vim
- 6.配置SSH
- 三.安裝Java環境
- 1.安裝JDK
- 2.驗證JDK安裝情況
- 3.設定JAVA壞境變數
- 四.安裝Hadoop
- 五.Hadoop偽分布式配置
- 1.修改組態檔
- 2.格式化 NameNode
- 3.開啟NameNode和DataNode守護行程
- 4.校驗安裝
- 五.呼叫MapReduce執行WordCount對單詞進行計數
- 1.準備作業
- 2.配置 Hadoop-Eclipse-Plugin
- 3.創建MapReduce專案
- 4.WordCount統計
- 六.總結
- 七.參考材料
一、安裝Linux
一般來說,如果要做服務器,我們選擇CentOS或者Ubuntu Server;如果做桌面系統,我們選擇Ubuntu Desktop,但是在學習Hadoop方面,雖然兩個系統沒有多大區別,但是個人在學習生活中常用Ubuntu,所以本實驗采用Ubuntu Kylin版本,相關下載檔案可以從參考資料[1]中獲取,
二、準備作業
1.創建Hadoop賬戶
1.首先按 ctrl+alt+t 打開終端視窗,輸入如下命令創建新用戶 :
sudo useradd -m hadoop -s /bin/bash
這條命令創建了可以登陸的 hadoop 用戶,并使用 /bin/bash 作為 shell,
2.設定hadoop密碼 :
sudo passwd hadoop
3.為hadoop用戶增加管理員權限
sudo adduser hadoop sudo
最后注銷當前用戶(點擊螢屏右上角的齒輪,選擇注銷),回傳登陸界面,在登陸界面中選擇剛創建的 hadoop 用戶進行登陸,
4.更新 apt
用 hadoop 用戶登錄后,先更新一下 apt,后續將使用 apt 安裝軟體,如果沒更新可能有一些軟體安裝不了,按 ctrl+alt+t 打開終端視窗,執行如下命令:
sudo apt-get update
5.安裝vim
后續需要更改一些組態檔,這里采用的是 vim(vi增強版,基本用法相同),相對于vi更有辨識度,編輯起來更好用,
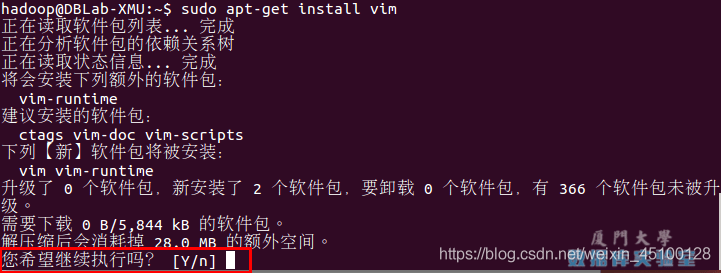
sudo apt-get install vim
安裝軟體時若需要確認,在提示處輸入 y 即可,
6.配置SSH
集群、單節點模式都需要用到 SSH 登陸(類似于遠程登陸,你可以登錄某臺 Linux 主機,并且在上面運行命令),Ubuntu 默認已安裝了 SSH client,此外還需要安裝 SSH server
sudo apt-get install openssh-server
安裝后,可以使用如下命令登陸本機:
ssh localhost
此時會有如下提示(SSH首次登陸提示),輸入 yes ,然后按提示輸入密碼 hadoop,這樣就登陸到本機了,

但這樣登陸是需要每次輸入密碼的,我們需要配置成SSH無密碼登陸比較方便,
首先退出剛才的 ssh,就回到了我們原先的終端視窗,然后利用 ssh-keygen 生成密鑰,并將密鑰加入到授權中:
exit # 退出剛才的 ssh localhost
cd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhost
ssh-keygen -t rsa # 會有提示,都按回車就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授權
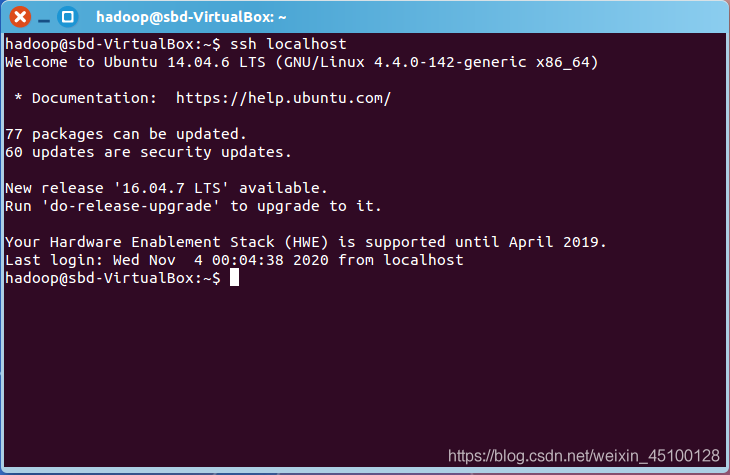
此時再用 ssh localhost 命令,無需輸入密碼就可以直接登陸了,如下圖所示,
三.安裝Java環境
1.安裝JDK
Hadoop3.1.3需要JDK版本在1.8及以上,需要按照下面步驟來自己手動安裝JDK1.8,
我們已經把JDK1.8的安裝包jdk-8u162-linux-x64.tar.gz放在了百度云盤,可以點擊這里到百度云盤下載(提取碼:lnwl),
接下來在Linux命令列界面中,執行如下Shell命令(注意:當前登錄用戶名是hadoop):
cd /usr/lib
sudo mkdir jvm #創建/usr/lib/jvm目錄用來存放JDK檔案
cd ~ #進入hadoop用戶的主目錄
cd Downloads #注意區分大小寫字母,剛才已經通過FTP軟體把JDK安裝包jdk-8u162-linux-x64.tar.gz上傳到該目錄下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK檔案解壓到/usr/lib/jvm目錄下
2.驗證JDK安裝情況
JDK檔案解壓縮以后,可以執行如下命令到/usr/lib/jvm目錄查看一下:
cd /usr/lib/jvm
ls
3.設定JAVA壞境變數
cd ~
vim ~/.bashrc
通過vim編輯器,打開環境變數配置.bashrc檔案,在檔案開頭添加如下幾行內容:
(vim編輯器中,按“i”進去編輯模式,按“:wq”保存并回傳終端)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc檔案并退出vim編輯器,然后,繼續執行如下命令讓.bashrc檔案的配置立即生效:
source ~/.bashrc
驗證安裝情況
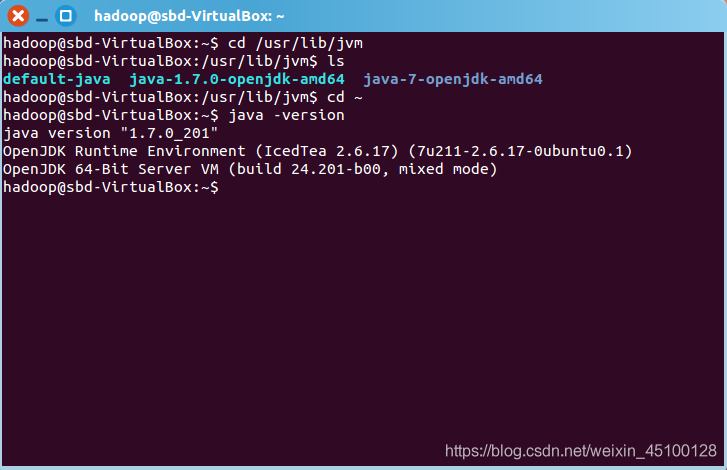
java -version
若回傳如下資訊,則代表JAVA環境配置成功
(圖為java1.7版本)
四.安裝Hadoop
Hadoop安裝檔案,可以到Hadoop官網下載hadoop-3.1.3.tar.gz,
也可以直接點擊這里從百度云盤下載軟體(提取碼:lnwl)
我們選擇將 Hadoop 安裝至 /usr/local/ 中:
sudo tar -zxf ~/下載/hadoop-3.1.3.tar.gz -C /usr/local # 解壓到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 將檔案夾名改為hadoop
sudo chown -R hadoop ./hadoop # 修改檔案權限
Hadoop 解壓后即可使用,輸入如下命令來檢查 Hadoop 是否可用,成功則會顯示 Hadoop 版本資訊:
cd /usr/local/hadoop
./bin/hadoop version
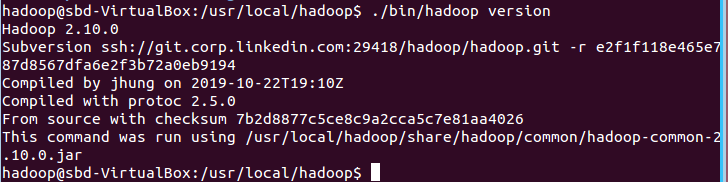
(圖為hadoop 2.10.0版本)
五.Hadoop偽分布式配置
1.修改組態檔
Hadoop 的組態檔位于 /usr/local/hadoop/etc/hadoop/ 中,偽分布式需要修改2個組態檔 core-site.xml 和 hdfs-site.xml ,Hadoop的組態檔是 xml 格式,每個配置以宣告 property 的 name 和 value 的方式來實作,
cd /usr/local/hadoop/etc/hadoop/
在進行修改組態檔前,需要創建相應的檔案夾進行存放,以防后續操作無法啟動Hadoop
sudo mkdir /usr/local/hadoop/tmp
sudo mkdir /usr/local/hadoop/tmp/dfs/name
sudo mkdir /usr/local/hadoop/tmp/dfs/data
完成前面的作業后,開始配置core-site.xml 和 hdfs-site.xml,首先對core-site.xml進行修改
vim core-site.xml
在組態檔中找到下面這個標簽對
<configuration>
</configuration>
修改為下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同理修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
2.格式化 NameNode
配置完core-site.xml 和 hdfs-site.xml,我們需要對NameNode進行格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功的話,會看到 “successfully formatted” 的提示,具體回傳資訊類似如下:
2020-01-08 15:31:31,560 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.3
*************************************************************/
......
2020-01-08 15:31:35,677 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name **has been successfully formatted**.
2020-01-08 15:31:35,700 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2020-01-08 15:31:35,770 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .
2020-01-08 15:31:35,810 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-01-08 15:31:35,816 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2020-01-08 15:31:35,816 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop/127.0.1.1
*************************************************************/
3.開啟NameNode和DataNode守護行程
cd /usr/local/hadoop
./sbin/start-dfs.sh #start-dfs.sh是個完整的可執行檔案,中間沒有空格
若出現如下SSH提示,輸入yes即可,
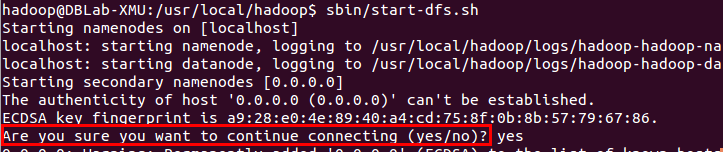
4.校驗安裝
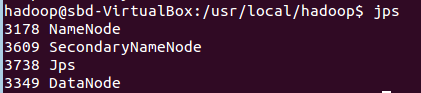
當程式啟動完成后,可以通過命令 jps 來判斷是否成功啟動,若成功啟動則會列出如下行程: “NameNode”、”DataNode” 和 “SecondaryNameNode”,
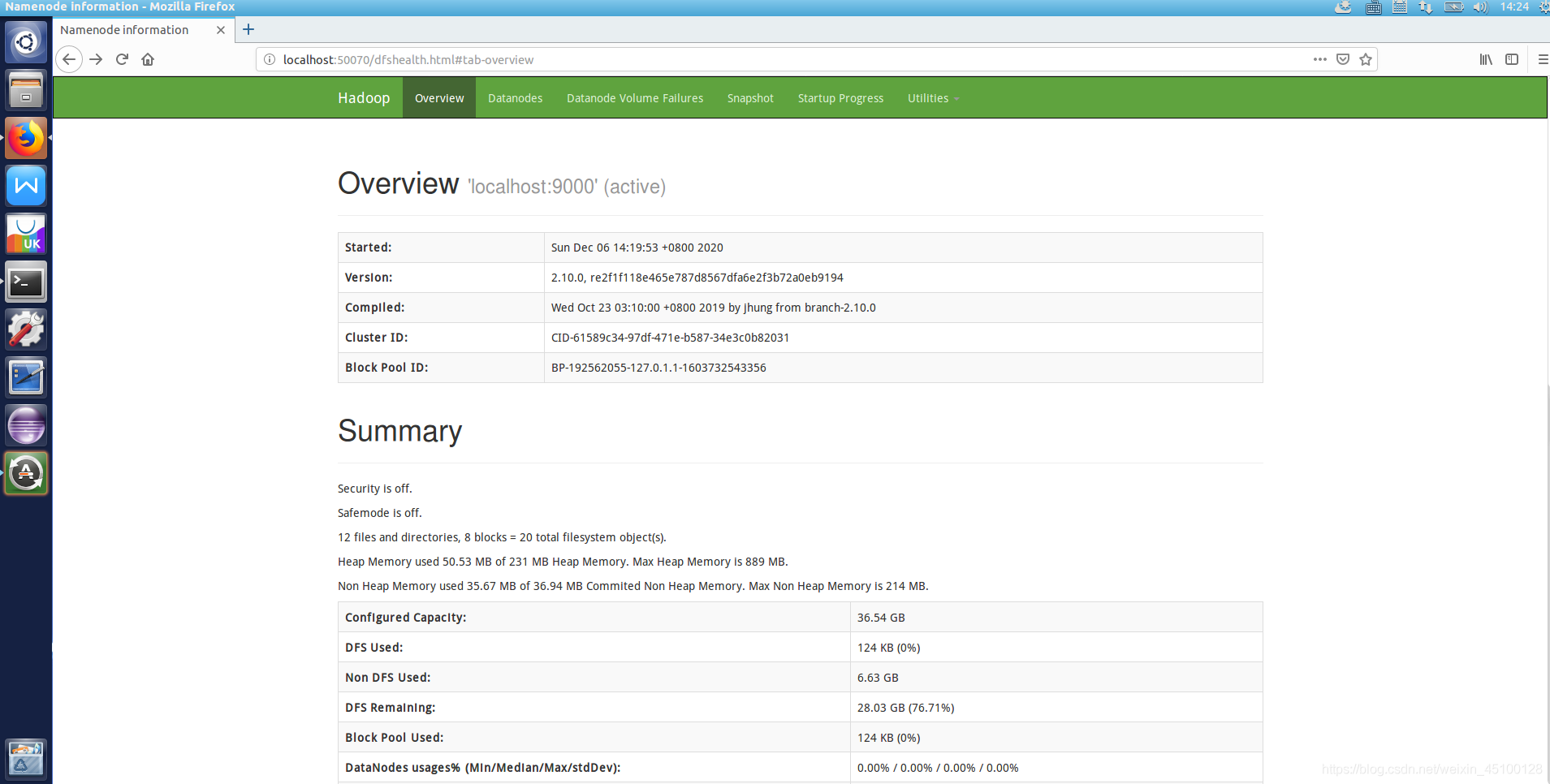
成功啟動后,可以訪問 Web 界面 http://localhost:50070查看 NameNode 和 Datanode 資訊,還可以在線查看 HDFS 中的檔案,
五.呼叫MapReduce執行WordCount對單詞進行計數
1.準備作業
首先,準備一個不少于10000萬單詞的文本檔案,內容不限,可從各大英語文獻網下載,將這個檔案放置于hadoop檔案夾中,以便實驗,
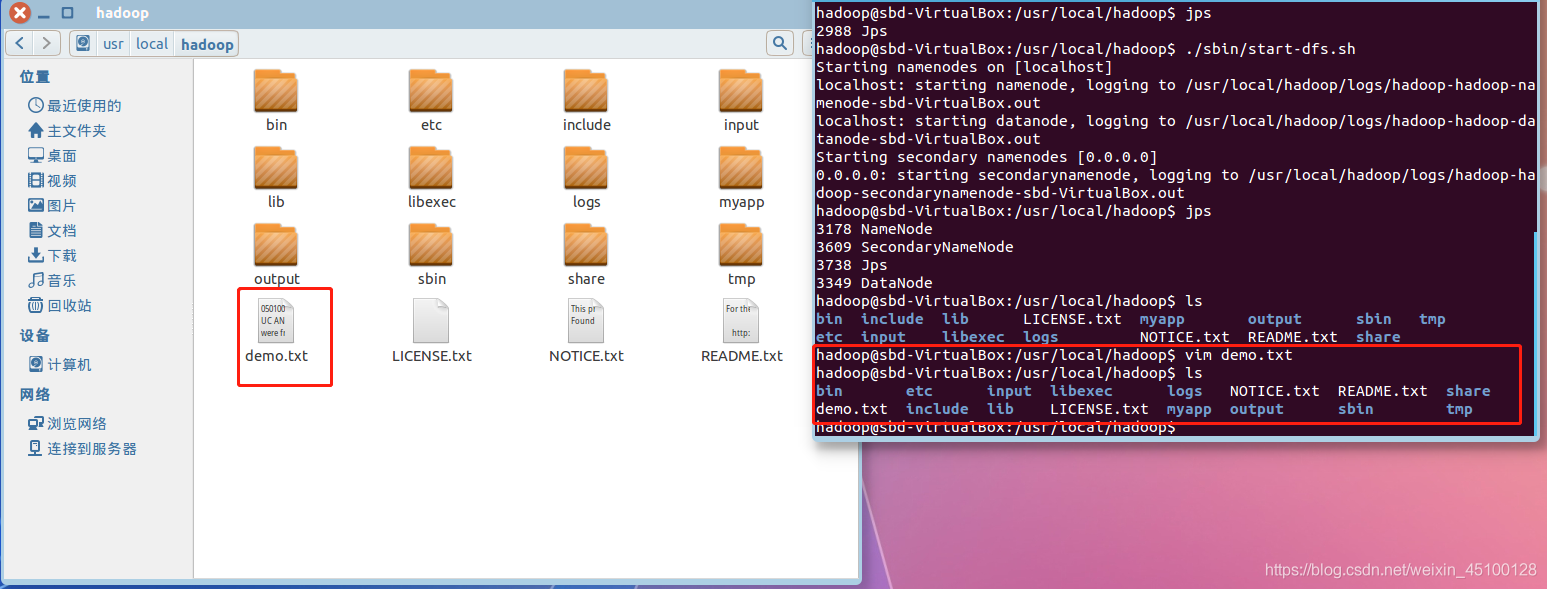
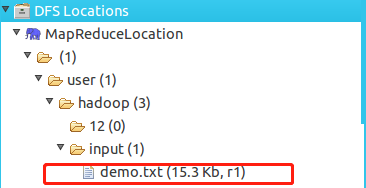
圖中demo.txt為實驗檔案
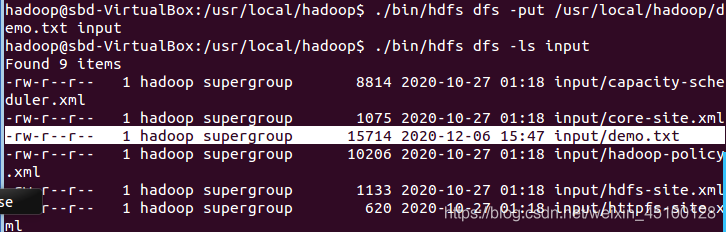
接著,將實驗的文本檔案上傳到HDFS中(請確保Hadoop為開啟狀態)
./bin/hdfs dfs -put /usr/local/hadoop/demo.txt input
操作完成后呼叫ls命令查看檔案上傳情況
./bin/hdfs dfs –ls input
上傳成功后可以在檔案中看到實驗檔案
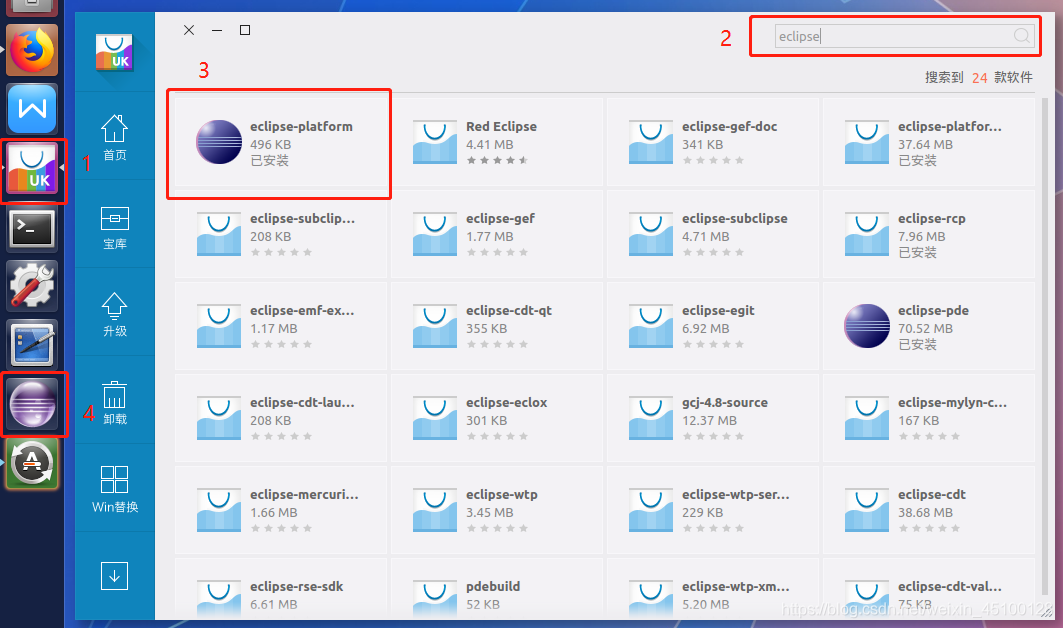
完成上傳后,我們需要安裝Eclipse,我們利用Ubuntu左側邊欄自帶的軟體中心安裝軟體,在Ubuntu左側邊欄打開軟體中心,在搜索框輸入Eclipse找到對應檔案下載即可,
下載后執行如下命令,將 Eclipse 安裝至 /usr/lib 目錄中:
sudo tar -zxf ~/下載/eclipse-java-mars-1-linux-gtk*.tar.gz -C /usr/lib
圖中eclipse-java-mars-1-linux-gtk*.tar.gz為檔案名,按實際情況輸入
安裝完Eclipse,我們還需要安裝 hadoop-eclipse-plugin,用于在 Eclipse 上編譯和運行 MapReduce 程式,可下載 Github 上的hadoop2x-eclipse-plugin (備用下載地址:http://pan.baidu.com/s/1i4ikIoP),
下載后,將 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar (還提供了 2.2.0 和 2.4.1 版本)復制到 Eclipse 安裝目錄的 plugins 檔案夾中,運行 eclipse -clean 重啟 Eclipse 即可(添加插件后只需要運行一次該命令,以后按照正常方式啟動就行了),
unzip -qo ~/下載/hadoop2x-eclipse-plugin-master.zip -d ~/下載 # 解壓到 ~/下載 中
sudo cp ~/下載/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar /usr/lib/eclipse/plugins/ # 復制到 eclipse 安裝目錄的 plugins 目錄下
/usr/lib/eclipse/eclipse -clean # 添加插件后需要用這種方式使插件生效
2.配置 Hadoop-Eclipse-Plugin
當執行完最后一條命令后,系統會自動打開Eclipse,打開后我們看到左邊的Project Explorer里出現了DFS Locations
接下來我們對插件進行進一步配置,
第一步:選擇 Window 選單下的 Preference,
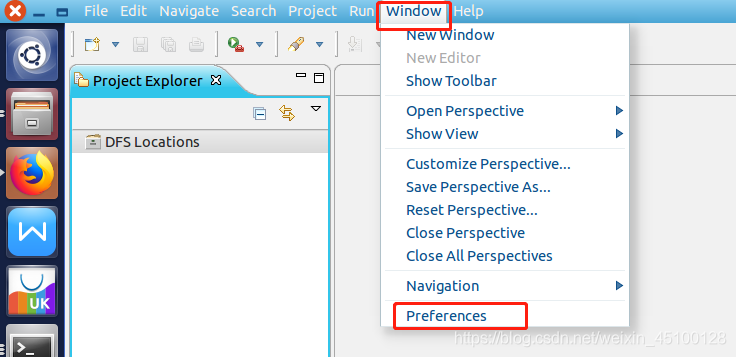
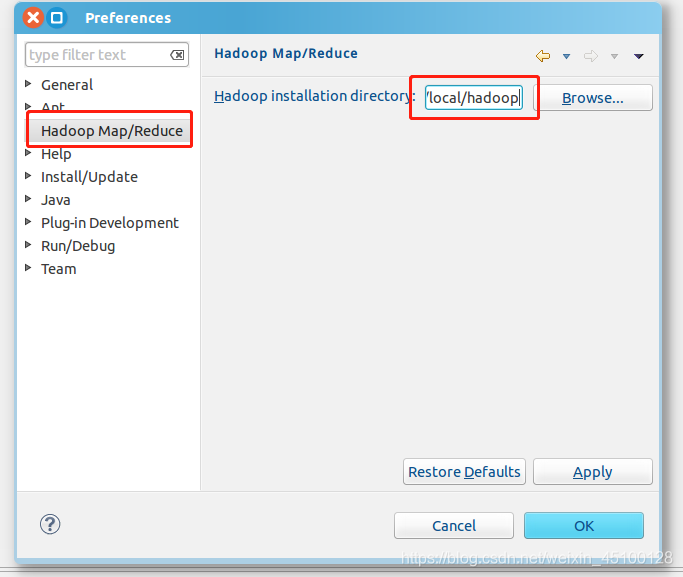
在表單的左側找到 Hadoop Map/Reduce 選項,填入Hadoop 的安裝地址/usr/local/hadoop
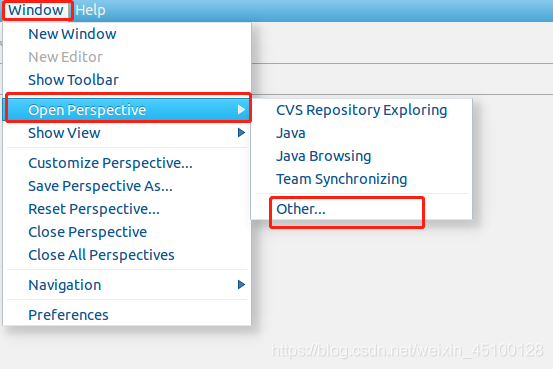
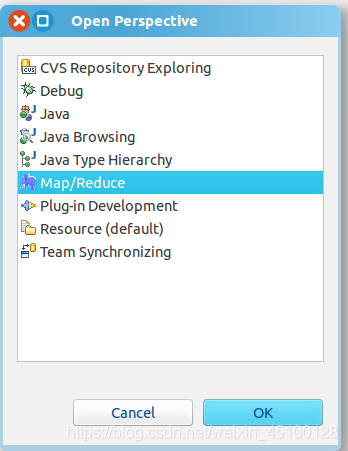
第二步:切換 Map/Reduce 開發視圖,選擇 Window 選單下選擇 Open Perspective -> Other,選擇 Map/Reduce 選項即可進行切換,
第三步:建立與 Hadoop 集群的連接,點擊 Eclipse軟體右下角的 Map/Reduce Locations 面板,在面板中單擊右鍵,選擇 New Hadoop Location,
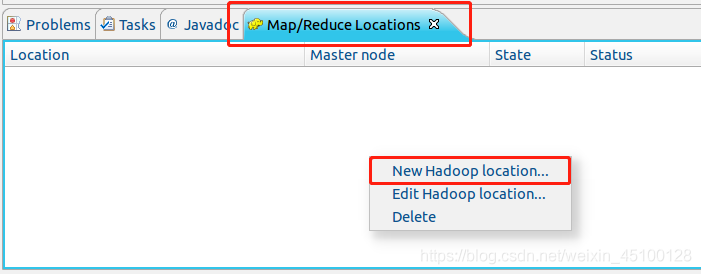
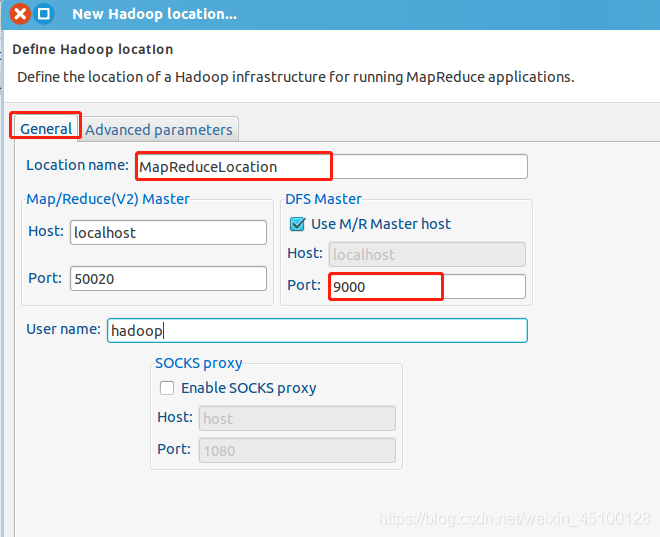
在彈出來的 General 選項面板中,General 的設定要與 Hadoop 的配置一致,由于我使用的Hadoop偽分布式配置,設定 fs.defaultFS 為 hdfs://localhost:9000,所以此處DFS Master 的 Port 要改為 9000,Map/Reduce(V2) Master 的 Port 用默認的即可,Location Name 隨意填寫,
配置好后,我們就能在左側的Project Explorer中找到我們的實驗檔案,
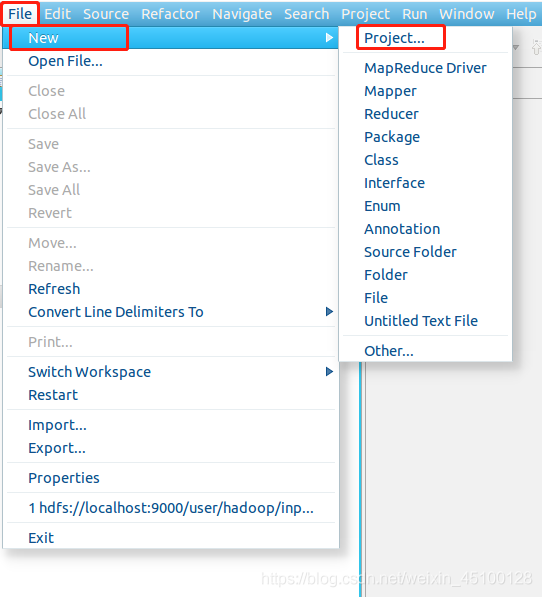
3.創建MapReduce專案
首先,點擊File選單,選擇New——Project
選擇Map/Reduce Project,點擊Next
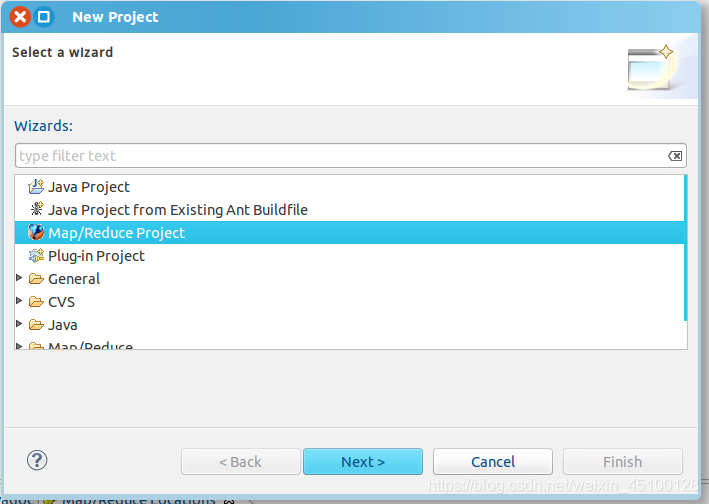
填寫專案名稱,此處用本實驗WordCount作為專案名,填寫完后點擊Finish即可,
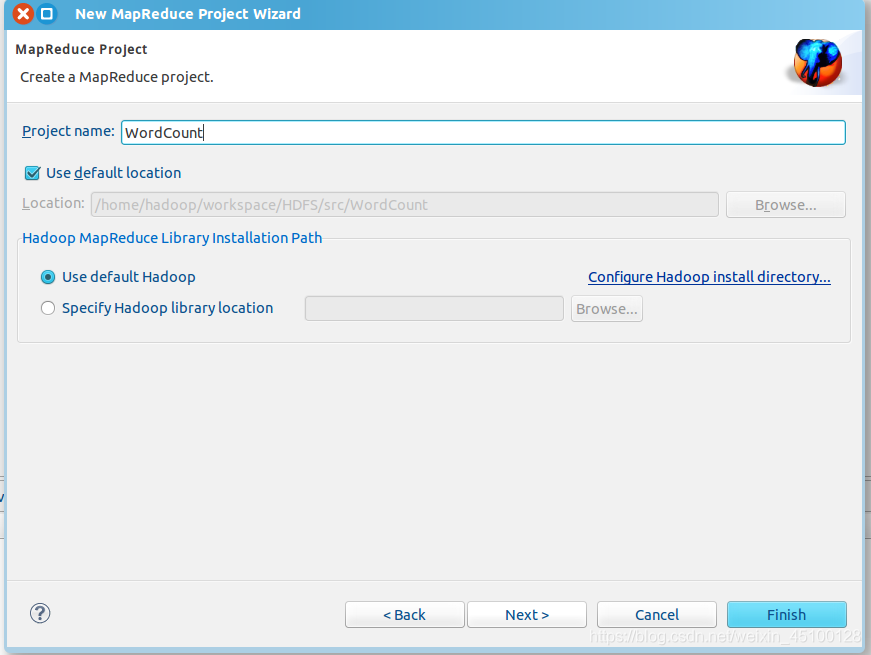
接下來在左側的Project Explorer中找到剛剛建好的WordCount檔案夾,右擊src選擇New-Class創建一個類,
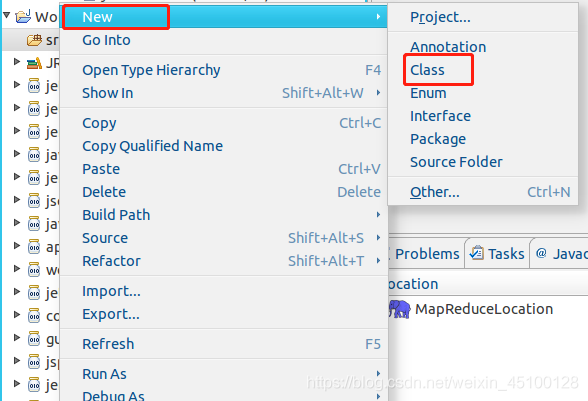
在彈出的class視窗中填入相應資訊, Package 處填寫 org.apache.hadoop.examples;在 Name 處填寫 WordCount
4.WordCount統計
Class創建完成后,將下面代碼復制進剛創建好的WordCount.java檔案中
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs=new String[]{"input","output"};
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator<IntWritable> i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
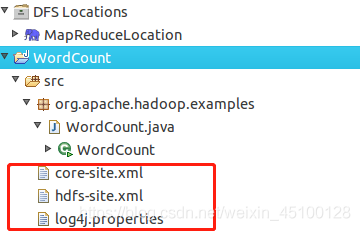
在運行 MapReduce 程式前,需要將 /usr/local/hadoop/etc/hadoop 中將有修改過的組態檔(如偽分布式需要 core-site.xml 和 hdfs-site.xml),以及 log4j.properties 復制到 WordCount 專案下的 src 檔案夾(~/workspace/WordCount/src)中,在終端中輸入下列幾行內容:
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src
復制完成后,務必右鍵點擊 WordCount 選擇 refresh 進行重繪(不會自動重繪,需要手動重繪),可以看到檔案結構如下所示:
完成上面的作業后,在上方找到啟動按鈕,點擊Run As——Run on Hadoop啟動MapReduce程式
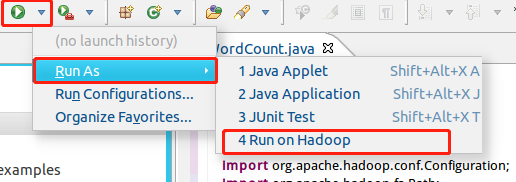
不過由于沒有指定引數,運行時會提示 “Usage: wordcount “,需要通過Eclipse設定一下運行引數,
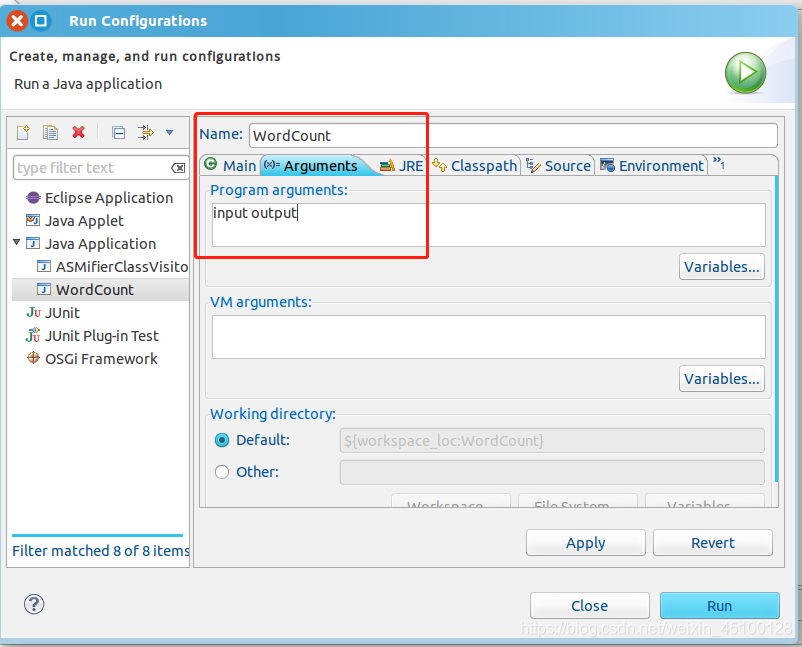
右鍵點擊剛創建的 WordCount.java,選擇 Run As -> Run Configurations,在此處可以設定運行時的相關引數(如果 Java Application 下面沒有 WordCount,那么需要先雙擊 Java Application),切換到 “Arguments” 欄,在 Program arguments 處填寫 “input output” 就可以了,
當程式執行完畢后,我們就可以在左側output——part-r-00000這個檔案中看到輸出結果了
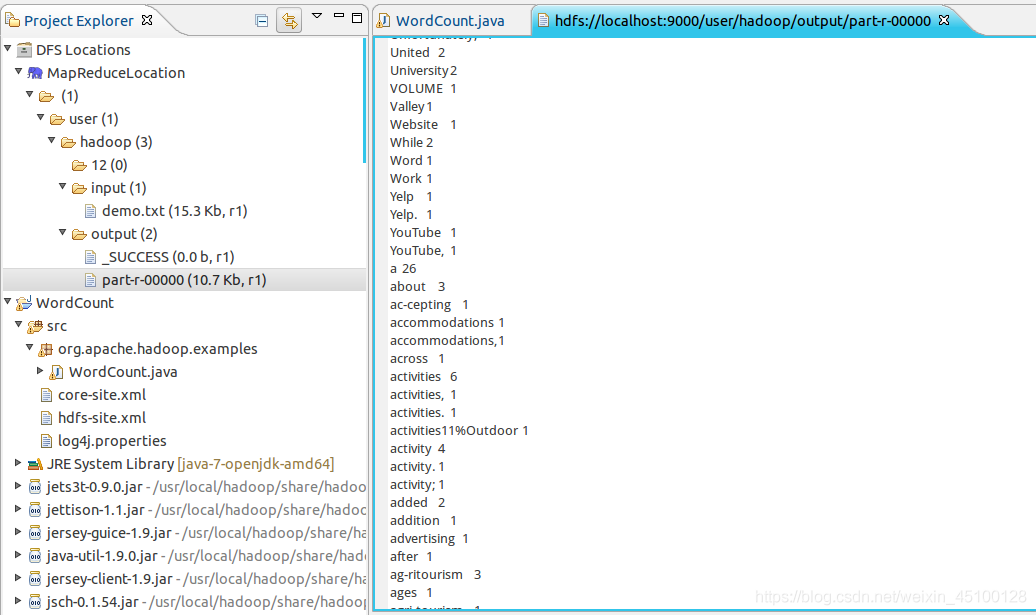
也可以通過輸入下面命令進行查看
cd /usr/local/haddop
./bin/hdfs dfs -cat output/part-r-00000
輸入下面命令,可以把HDFS中檔案下載到本地檔案系統中的“/home/hadoop/下載/”這個目錄下
./bin/hdfs dfs -get output/part-r-00000 /home/hadoop/下載
六.總結
通過本次實驗操作,從Ubuntu的安裝到WordCount案例完成,系統地將每個部分進行深化決議,包括如何配置Hadoop、MapReduce,Eclipse等,同時將本人之前遇到的困難進行解決希望對正在觀看這篇文章的你有所幫助,同時本人也處于學習程序,有錯誤的地方歡迎指出,
七.參考材料
[1] http://dblab.xmu.edu.cn/blog/285/
[2] http://dblab.xmu.edu.cn/blog/290-2/
[3] http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231119.html
標籤:其他
下一篇:#Windows通過IDEA撰寫程式自動加手動上傳到docker搭建的spark集群上運行加簡單的RDD編程!!!!