參考大佬文章
https://blog.csdn.net/weixin_43622131/article/details/110565692
https://blog.csdn.net/weixin_43622131/article/details/110621405
說在前面
以下實驗程序都是在使用docker搭建好spark集群的前提條件下進行,如果你的spark集群還沒有搭建成功,可以參考我的上一篇博客
https://blog.csdn.net/weixin_45548774/article/details/110206515
下面是正式的實驗內容
啟動spark集群
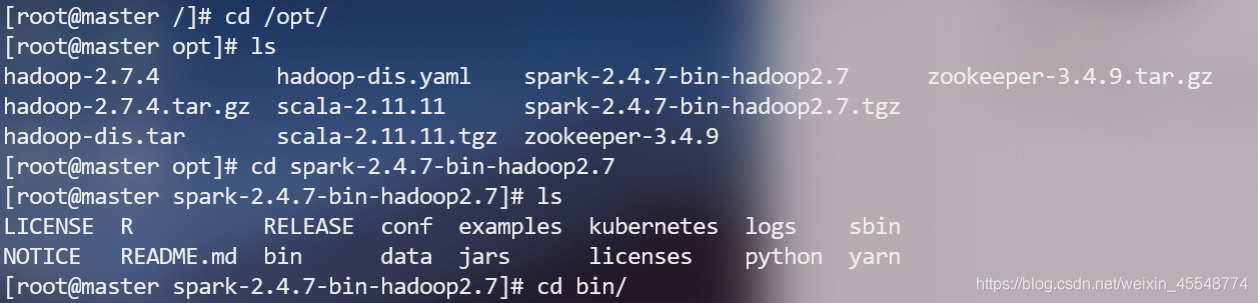
1本機啟動集群do
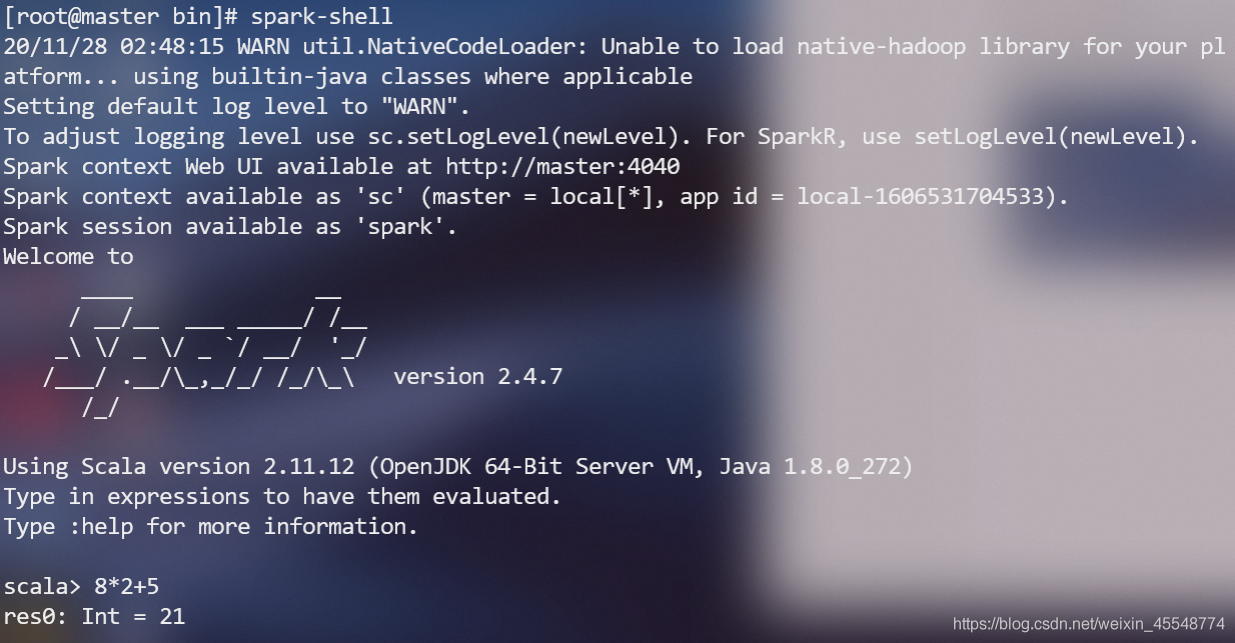
直接運行
spark-shell
或者進入spark安裝目錄,打開spark-shell
2通過yarn啟動spark集群
使用命令
spark-shell --master yarn
或者
spark-shell --master yarn-client
這期間可能會遇到如下問題:
1 Name node is in safe mode.
這是因為在分布式檔案系統啟動的時候,開始的時候會有安全模式,當分布式檔案系統處于安全模式的情況下,檔案系統中的內容不允許修改也不允許洗掉,直到安全模式結束,安全模式主要是為了系統啟動的時候檢查各個DataNode上資料塊的有效性,同時根據策略必要的復制或者洗掉部分資料塊,運行期通過命令也可以進入安全模式,
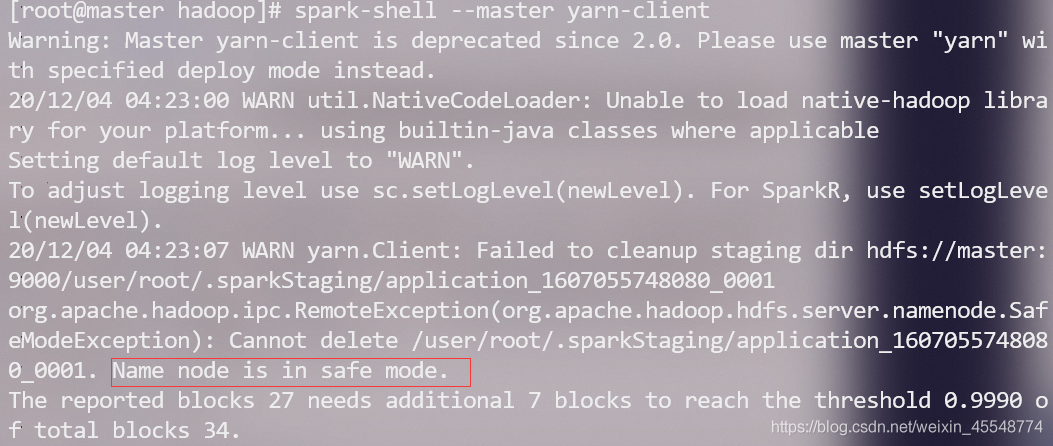
通過以下命令來解決:
hadoop dfsadmin -safemode leave
2

出現這個問題可以
參考博客
https://www.cnblogs.com/yy3b2007com/p/9247621.html
上面說的很清楚
確保集群可以正常啟動后就可以開始進入正題了!!!
Windows中使用IDEA寫程式,手動生成jar包,手動提交到docker搭建的spark集群上運行
配置IDEA的環境
1 下載IDEA
這里給出官網鏈接https://www.jetbrains.com/idea/download/#section=windows
下載后安裝即可
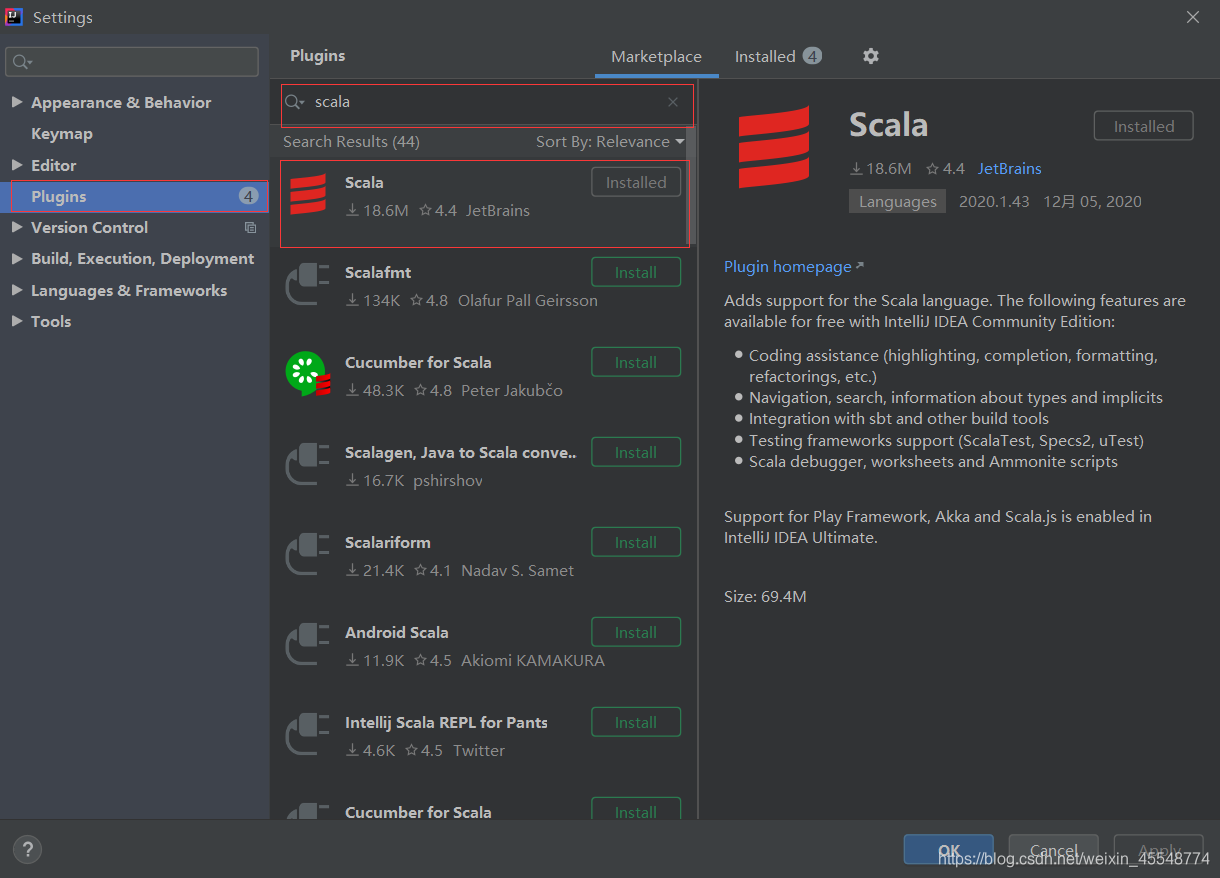
2 在IDEA中下載scala
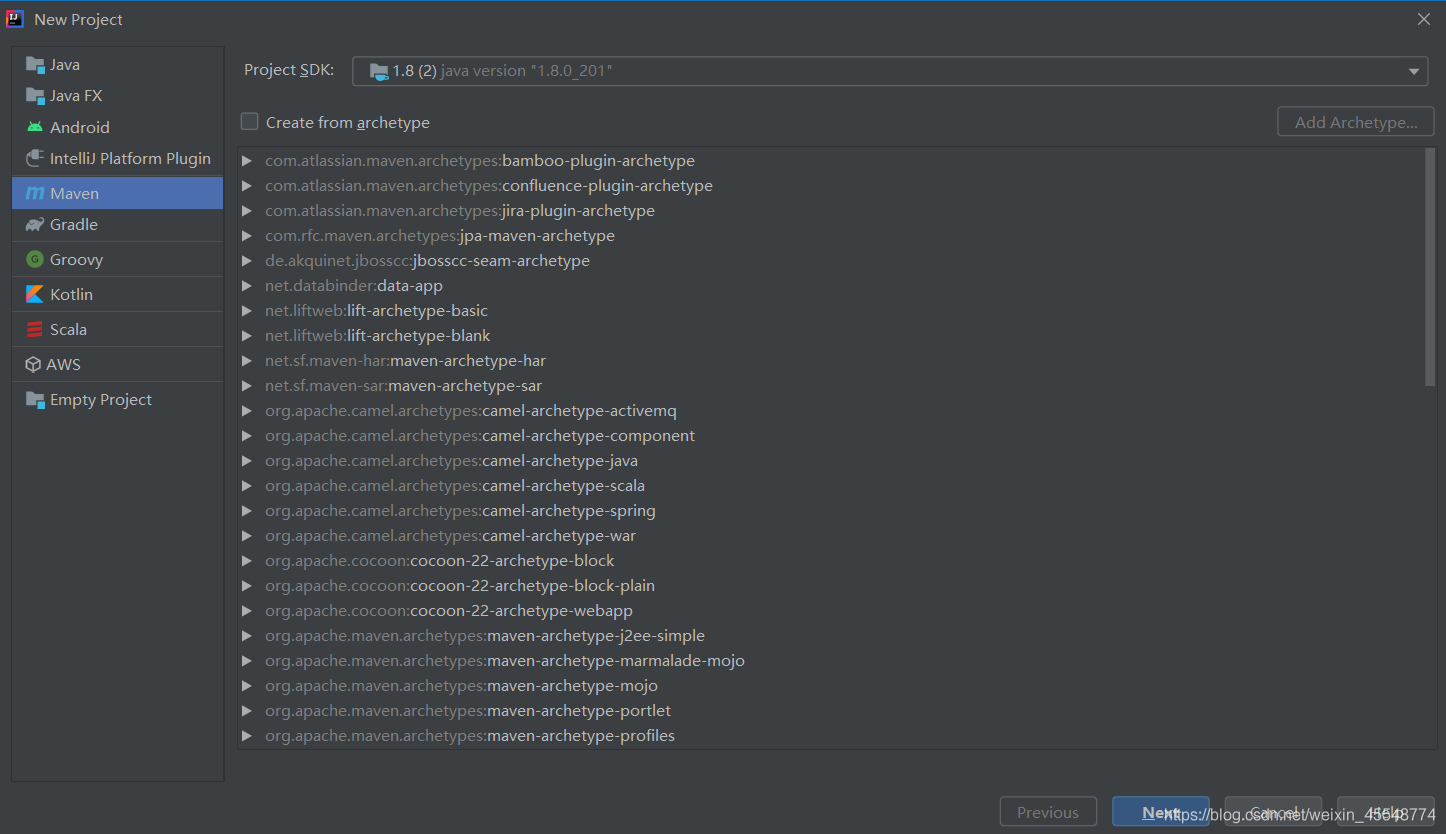
3 在IDEA中創建scala工程
填寫資訊
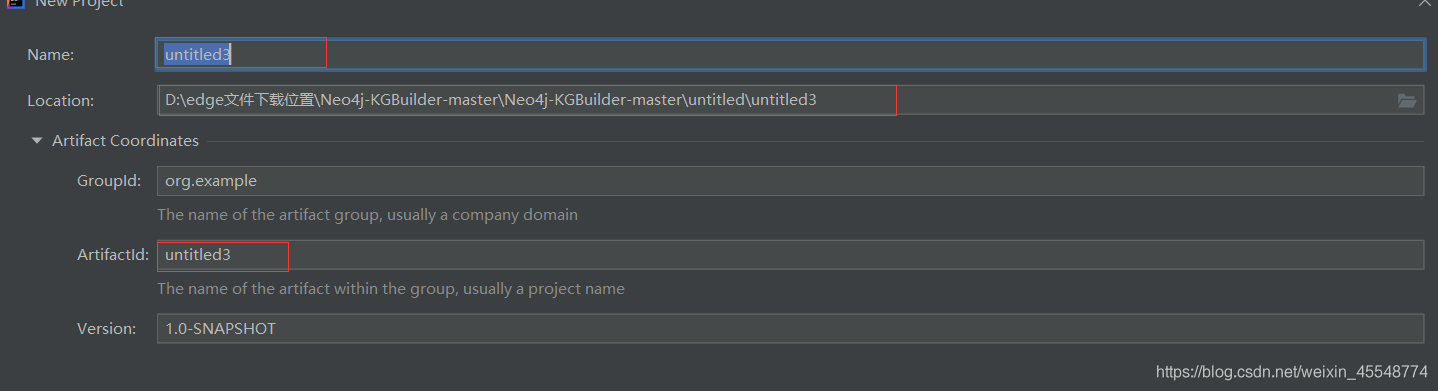
標紅的地方可以自己修改,其他不變即可,點擊finish
新建scala檔案夾,并設定為源目錄
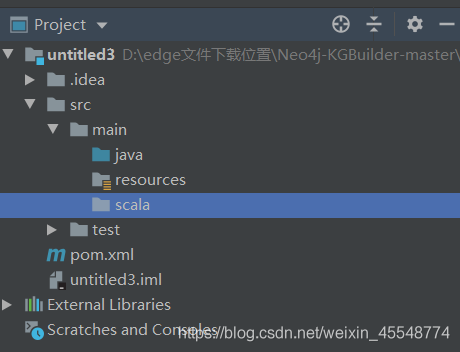
右鍵scala
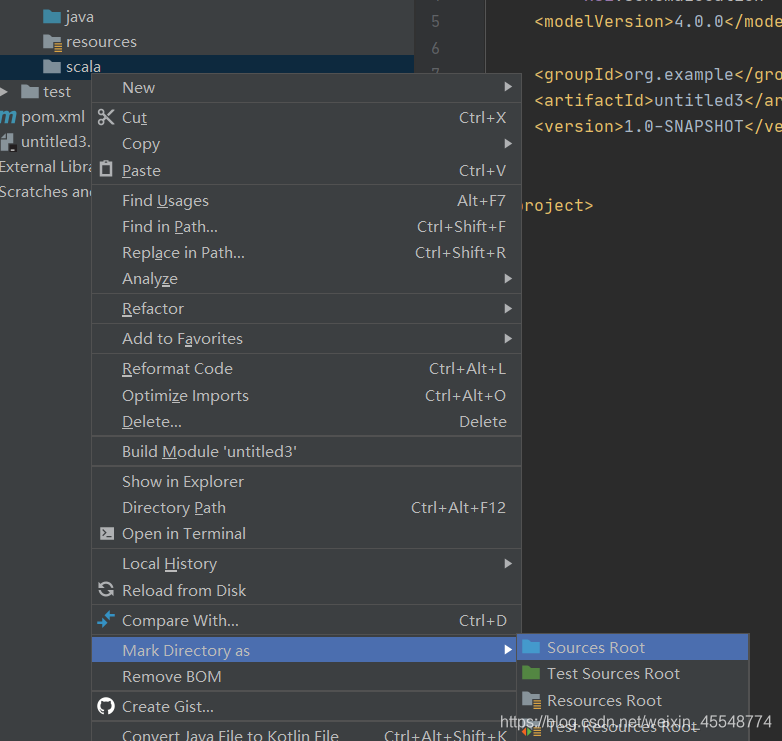
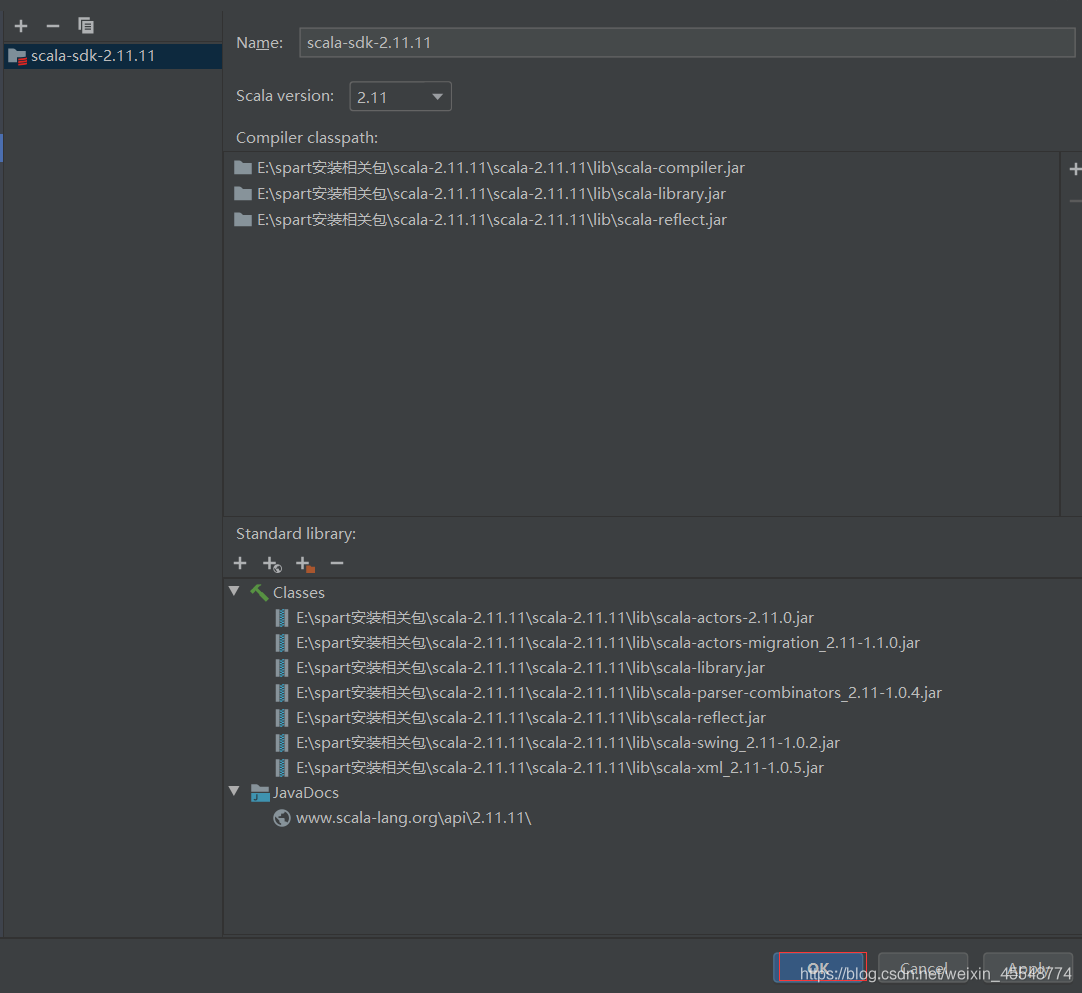
4 匯入scala環境
點擊File中的Project Structure,進入到下圖頁面,添加scala的SDK,可以從下面鏈接中下載
鏈接:https://pan.baidu.com/s/11DYs4lS-wZjtnHRuFC9_DQ
提取碼:u18t
下載后解壓即可
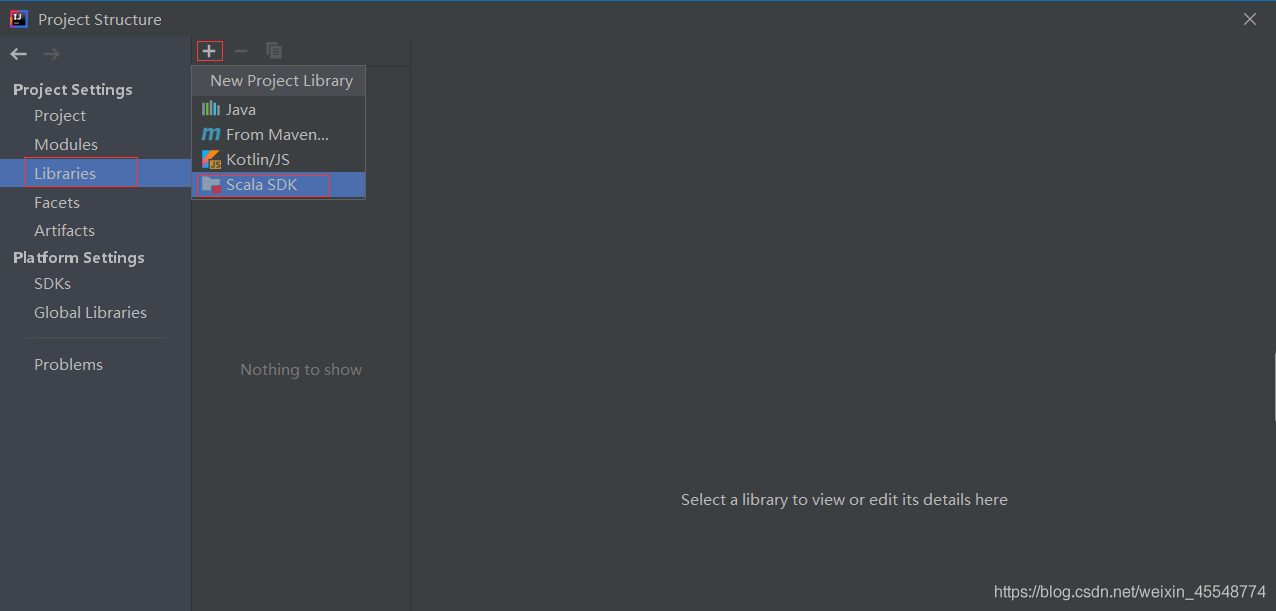
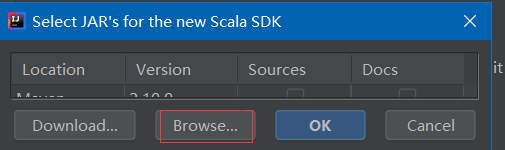
點擊Browse
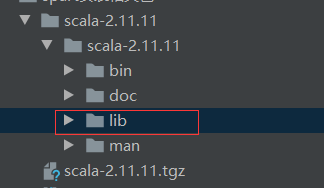
在下載的檔案中選擇lib,點擊ok即可
5 撰寫pom檔案
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled3</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11</scala.version>
<hadoop.version>2.7.4</hadoop.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project>
6 將spark原始碼里的jars包直接加到library中
點擊Modules然后點擊添加
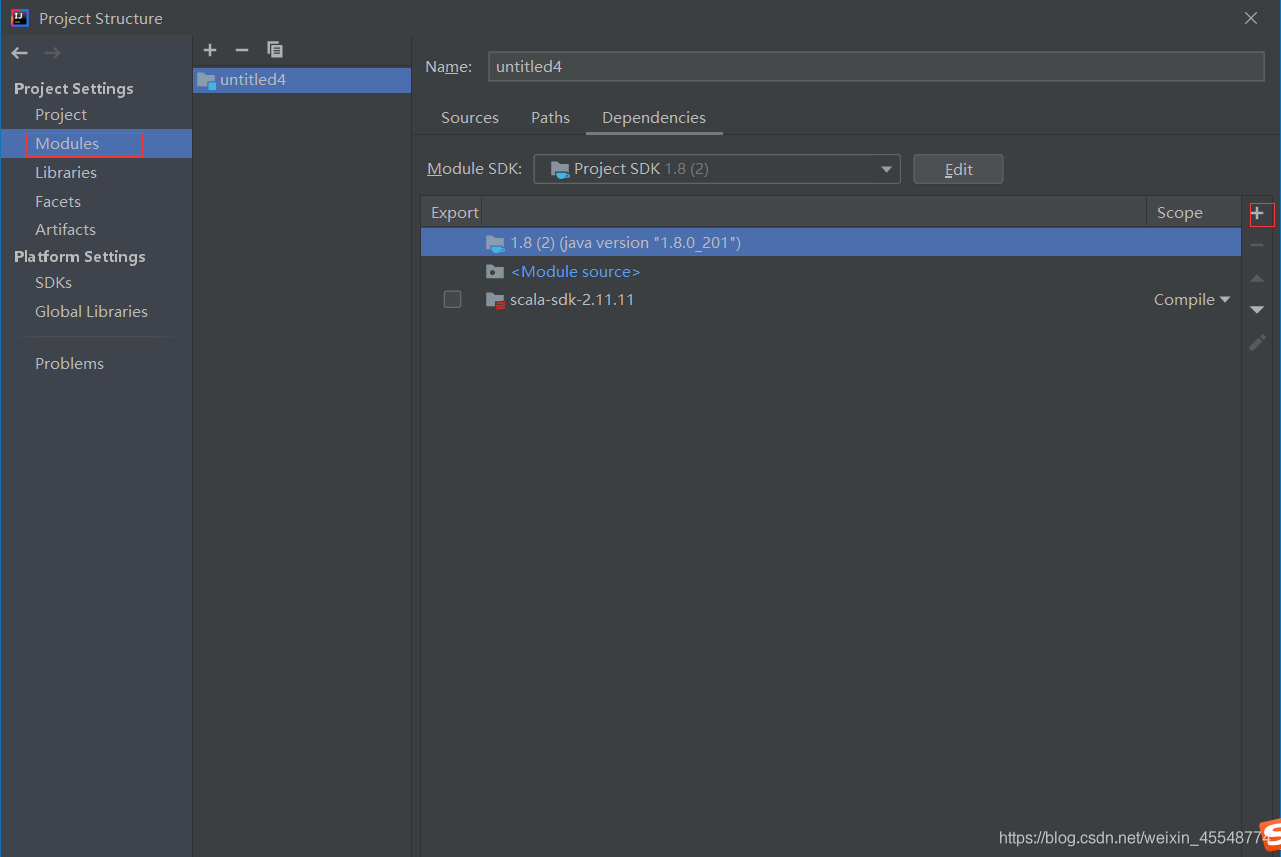
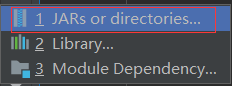
將下載jars匯入就可以了,jars可以在下面鏈接中下載
鏈接:https://pan.baidu.com/s/1GFiIvteJu2m94GdjcYxViA
提取碼:kx8o
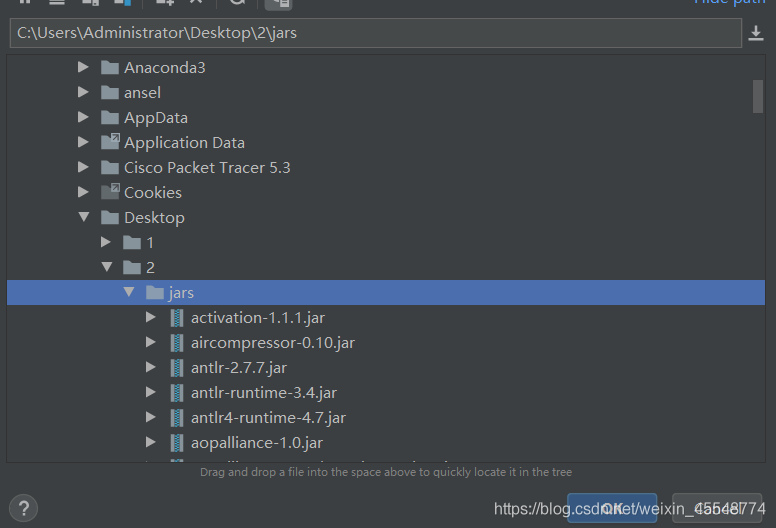
上傳之后環境就基本配置完成了
7 運行一個scala程式
新建scala的class,

點擊Object,輸入名字
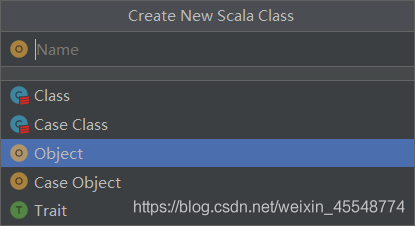
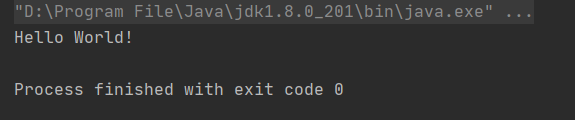
建成之后,運行第一個scala程式
object Hello_World {
def main(args: Array[String]) {
println("hello")
}
}
打包scala程式
進入這個
然后
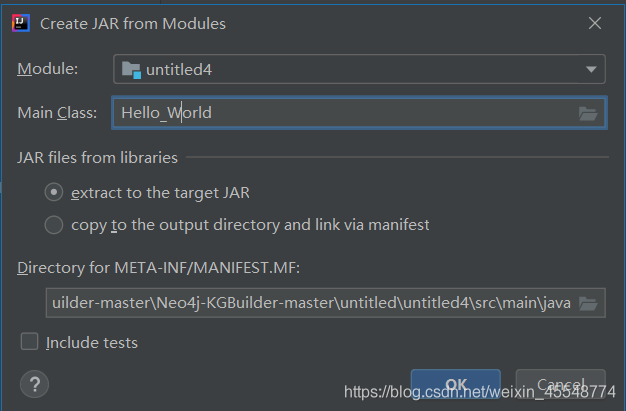
點擊build
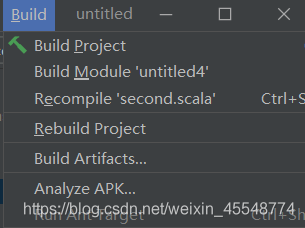
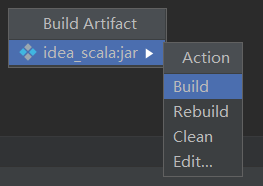
產生對應jar包
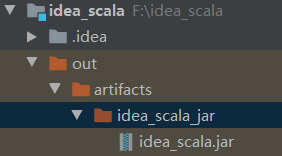
至此就完成了通過IDEA手動生成jar包的程序
手動提交到spark集群上執行
首先將生成jar復制下來,通過下面這條命令傳入到集群中
docker cp C:\Users\Administrator\Desktop\untitled2.jar master:/opt
之后啟動spark集群,進入到/opt目錄下
使用如下命令運行jar包,Hello_World是主類的名稱
spark-submit --class Hello_World --master yarn untitled2.jar
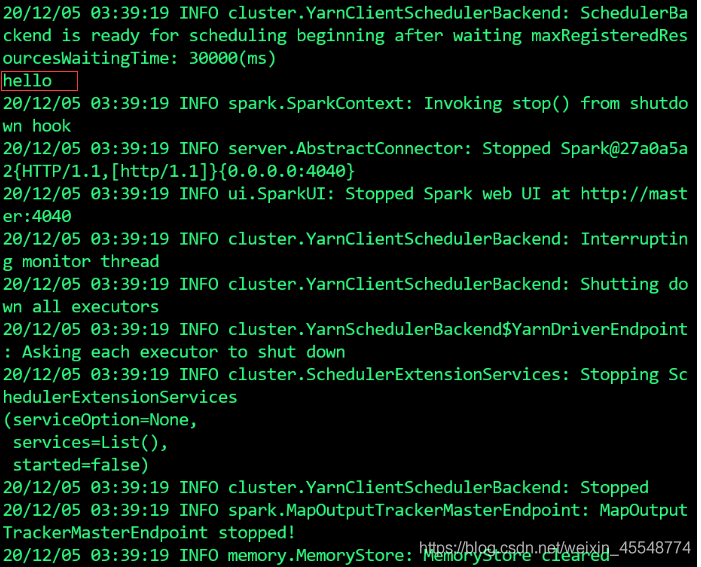
至此就完成了整個的流程
Windows中使用IDEA寫程式,自動提交到docker搭建的spark集群上運行
1 搭建IDEA環境,這里和上面的內容相同,不再贅述
2 啟動本機docker中的spark環境
start-all.sh
start-dfs.sh
start-yarn.sh
3 創建一個scala類,寫入下面的示例代碼
/**
* Created by zf on 12/3/20.
*/
import scala.math.random
import org.apache.spark._
/** Computes an approximation to pi */
object SparkPi2 {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi").set("spark.executor.memory", "512m")
.set("spark.driver.host","10.0.75.1")//這個ip很重要,我因為這個ip沒有設定正確卡了好長時間,我使用的是docker,這個ip就要設定為本機在docker分配的虛擬網卡中的ip地址,如果設定成其他網卡的ip會被主機拒絕訪問
.set("spark.driver.cores","1")
.setMaster("spark://127.0.0.1:7077") //這里應設為master的ip加上配置spark時設定的埠,一般都為7077,頭面的是windows本機的ip或者直接使用127.0.0.1
.setJars(List("D:\\edge檔案下載位置\\Neo4j-KGBuilder-master\\Neo4j-KGBuilder-master\\untitled\\untitled2\\out\\artifacts\\untitled2_jar\\untitled2.jar"))
//這里是jar包存放的位置
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y < 1) 1 else 0
}.reduce(_ + _)
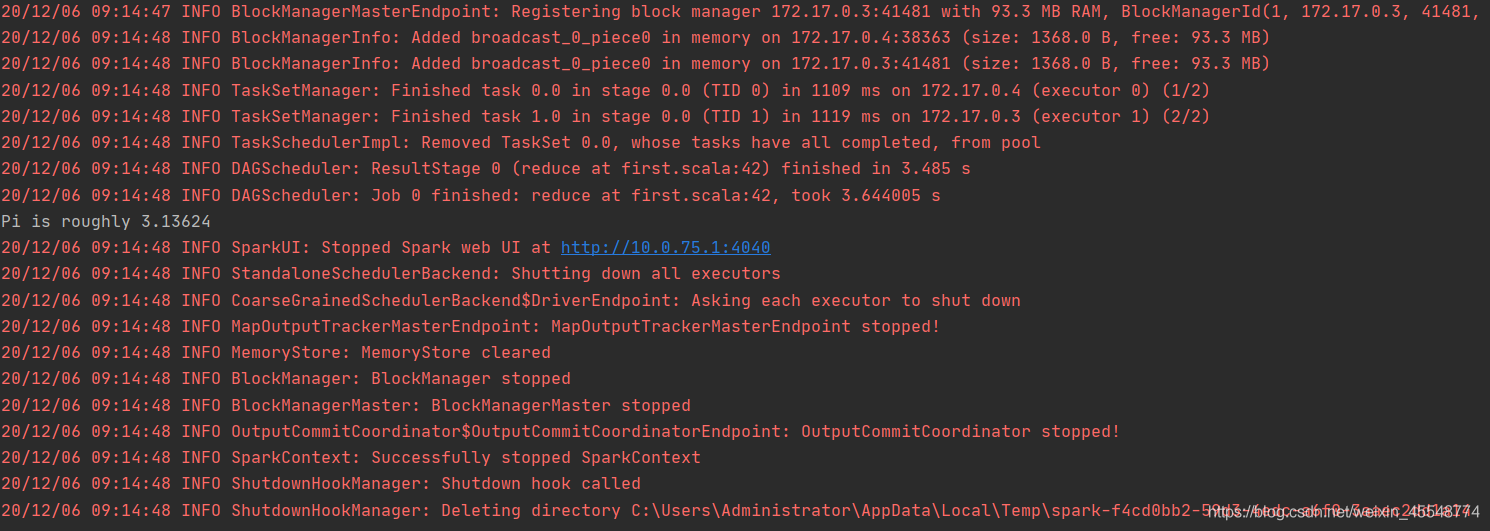
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
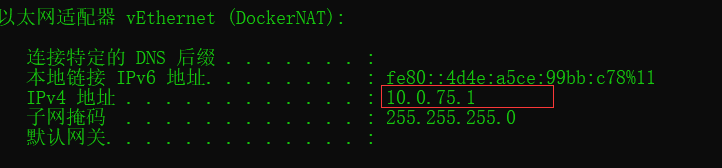
.set("spark.driver.host","10.0.75.1")
這里的10.0.75.1可以在cmd中使用ipconfig在下面找到,注意必須是這個ip地址
4 極有可能出現的錯誤:
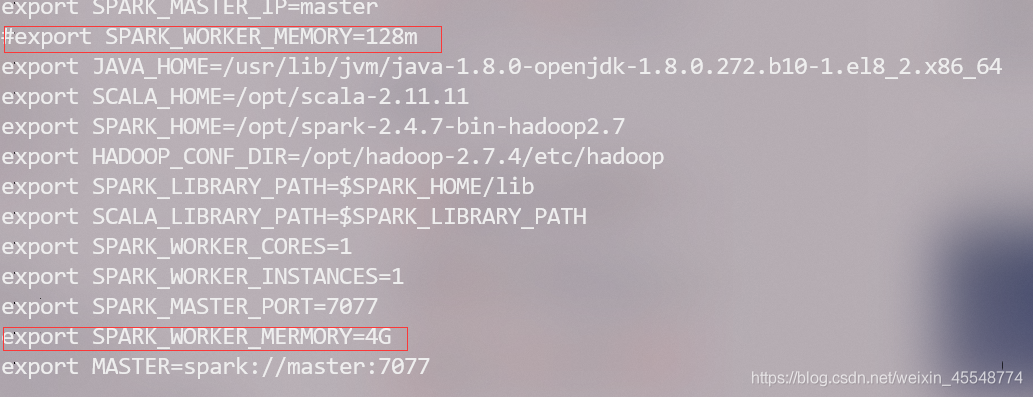
1 如果出現spark運行報錯:check your cluster UI to ensure that workers are registered and have sufficient resources,那證明你的spark集群上記憶體不夠了,需要添加記憶體,
找到spark-env.sh檔案,查看配置,看看是不是記憶體容量設定的過小了,我最設定的是128m,過小導致運行出現了問題,后來改成了4G問題就解決了,
注意master和slave節點都要檢查!!!
2 修改代碼之后,最后都rebuild一下
此時一定要rebulid一下
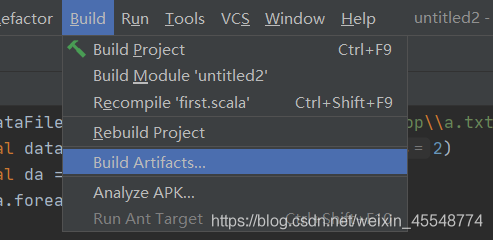
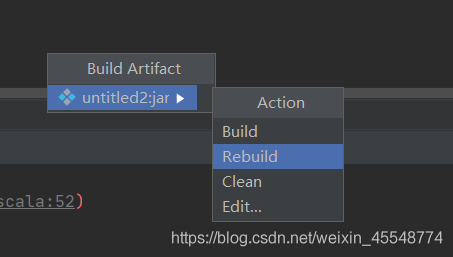
都配置完成之后,運行程式就大功告成了
5自動運行程式結果
RDD編程初級實踐
1 啟動spark-shell
2 據給定的實驗資料,在spark-shell中通過編程來計算題目內容
資料下載:
鏈接:https://pan.baidu.com/s/1lDnee9CxLKU31Zu5gFoIzw
提取碼:6vzx
首先將資料加載到master中,使用
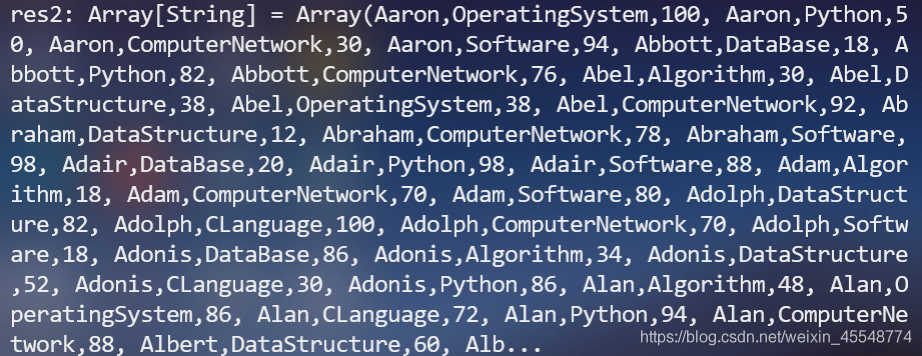
var rdd=sc.textFile("file:///usr/mydata/Data01.txt")
將資料對出,使用
rdd.collect
將資料列印出來查看
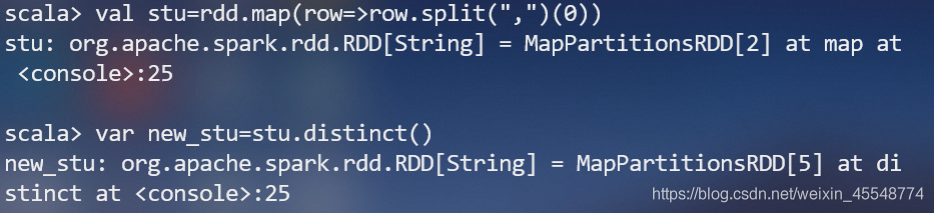
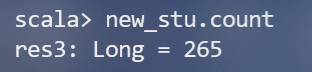
(1)該系總共有多少學生;(首先將資料按照“,”進行分割,由于一個學生可能選修多門課,所以還要對資料進行去重)
(2)該系共開設來多少門課程;
同第一問到的思路一樣,取出課程進行去重處理之后進行統計即可,

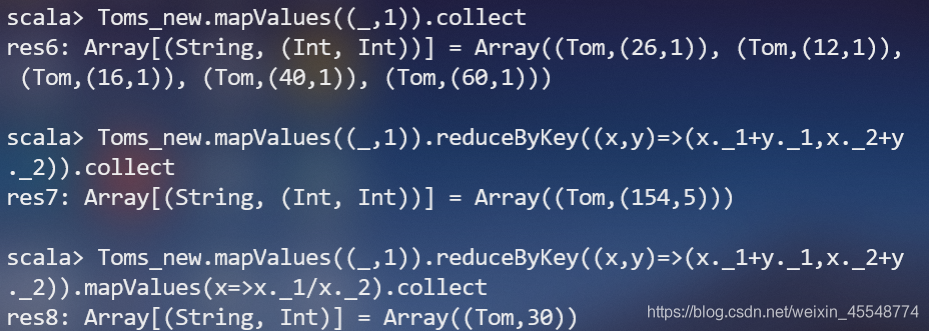
(3)Tom同學的總成績平均分是多少;

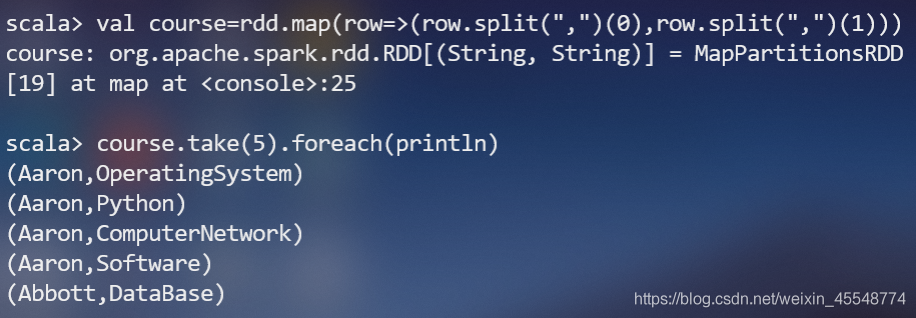
(4)求每名同學的選修的課程門數;

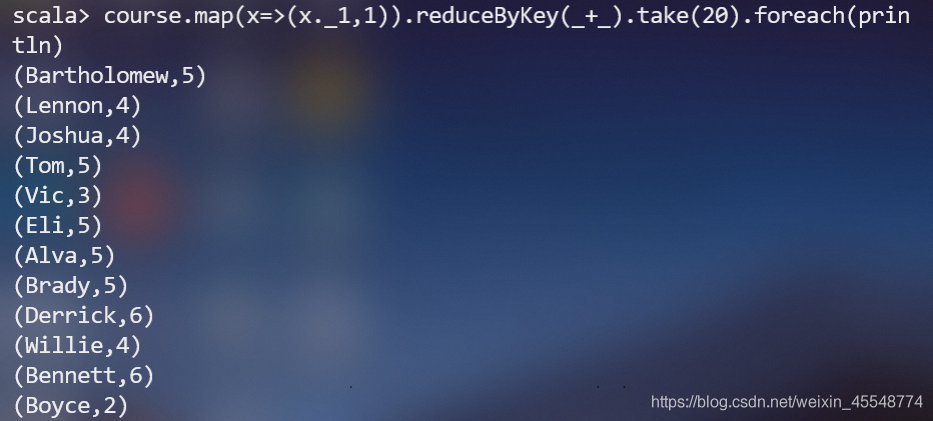
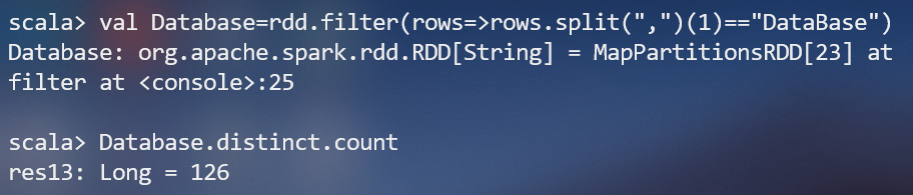
(5)該系DataBase課程共有多少人選修;
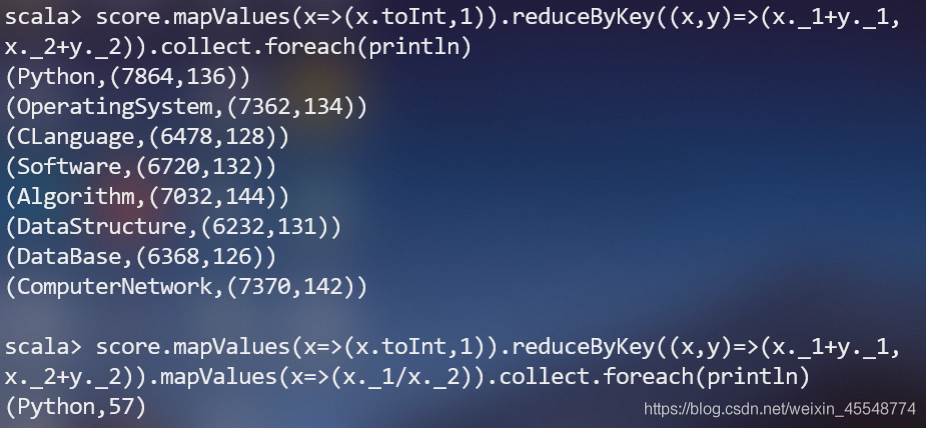
(6)各門課程的平均分是多少;


(7)使用累加器計算共有多少人選了DataBase這門課,


3 應用程式實作資料去重
對于兩個輸入檔案A和B,撰寫Spark獨立應用程式,對兩個檔案進行合并,并剔除其中重復的內容,得到一個新檔案C,下面是輸入檔案和輸出檔案的一個樣例,供參考,
輸入檔案A的樣例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
輸入檔案B的樣例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
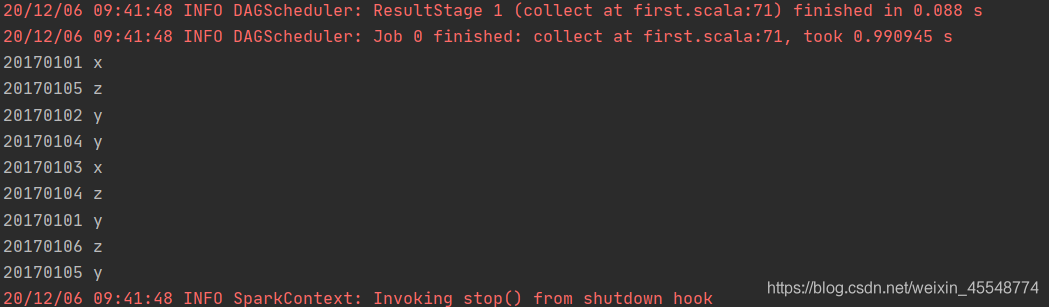
根據輸入的檔案A和B合并得到的輸出檔案C的樣例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
首先創建a.txt和b.txt,檔案中輸入上面對應的內容,最后將結果輸入到檔案C.txt中
代碼如下(這里使用自動運行的方式)
import java.io.FileWriter
import java.net.InetAddress
import org.apache.spark._
object first {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("first").set("spark.executor.memory", "512m")
// .set("spark.driver.host", "10.0.75.1")
.set("spark.driver.cores", "2")
.setMaster("local") //spark://127.0.0.1:7077
.setJars(List("D:\\edge檔案下載位置\\Neo4j-KGBuilder-master\\Neo4j-KGBuilder-master\\untitled\\untitled2\\out\\artifacts\\untitled2_jar\\untitled2.jar")) // maven打的jar包的路徑
.set("spark.driver.allowMultipleContexts", "true")
// .set("spark.driver.port","50516")
val sc = new SparkContext(conf)
// 讀取檔案A
var A = sc.textFile("C:\\Users\\Administrator\\Desktop\\a.txt")
// 讀取檔案B
var B = sc.textFile("C:\\Users\\Administrator\\Desktop\\b.txt")
// 對檔案A和B進行整合并去重
var C = (A ++ B).distinct
var results = C.collect()
// 將結果輸出到C.txt中
val out = new FileWriter("C:\\Users\\Administrator\\Desktop\\C.txt",true)
for(item<-results){
out.write(item+"\n")
println(item)
}
out.close()
}
}
運行結果
4 應用程式實作平均值問題
每個輸入檔案表示班級學生某個學科的成績,每行內容由兩個欄位組成,第一個是學生名字,第二個是學生的成績;撰寫Spark獨立應用程式求出所有學生的平均成績,并輸出到一個新檔案中,下面是輸入檔案和輸出檔案的一個樣例,供參考,
Algorithm成績:
小明 92
小紅 87
小新 82
小麗 90
Database成績:
小明 95
小紅 81
小新 89
小麗 85
Python成績:
小明 82
小紅 83
小新 94
小麗 91
平均成績如下:
? (小紅,83.67)
? (小新,88.33)
? (小明,89.67)
? (小麗,88.67)
新建三個檔案
將題目要求的資料輸入到對應的檔案夾中去(這里注意檔案中的編碼形式為utf-8)
代碼如下(采用自動運行的方式):
import java.io.FileWriter
import java.net.InetAddress
import org.apache.spark._
object first {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("first").set("spark.executor.memory", "512m")
// .set("spark.driver.host", "10.0.75.1")
.set("spark.driver.cores", "2")
.setMaster("local") //spark://127.0.0.1:7077
.setJars(List("D:\\edge檔案下載位置\\Neo4j-KGBuilder-master\\Neo4j-KGBuilder-master\\untitled\\untitled2\\out\\artifacts\\untitled2_jar\\untitled2.jar")) // maven打的jar包的路徑
.set("spark.driver.allowMultipleContexts", "true")
// .set("spark.driver.port","50516")
val sc = new SparkContext(conf)
// 讀取檔案Algorithm.txt
var A = sc.textFile("C:\\Users\\Administrator\\Desktop\\Algorithm.txt")
// 讀取檔案Database.txt"
var B = sc.textFile("C:\\Users\\Administrator\\Desktop\\Database.txt")
// 讀取檔案Python.txt
var C = sc.textFile("C:\\Users\\Administrator\\Desktop\\Python.txt")
// 對三個檔案進行整合
var all = A ++ B ++ C
print(all.collect)
// // 將每個名字作為鍵,值為一個鍵值對,該鍵值對的鍵為成績,值為1(用于后面計算平均值計數用)
val student_grade = all.map(row=>(row.split(" ")(0),(row.split(" ")(1).toInt,1)))
// 對上述RDD做聚合,值的聚合回傳一個二元組,第一個元素是該學生所有課的成績求和,第二個元素是該學生選修課的數目,然后再做一個映射
// 將人名作為第一個元素,所有課的總成績除以選修課程的數目得到該學生的平均成績作為第二個元素
val student_ave = student_grade.reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).map(x=>(x._1,x._2._1/x._2._2))
var results = student_ave.collect
// 將結果輸出到output.txt中
val out = new FileWriter("C:\\Users\\Administrator\\Desktop\\result.txt",true)
for(item<-results){
out.write(item+"\n")
println(item)
}
out.close()
}
}
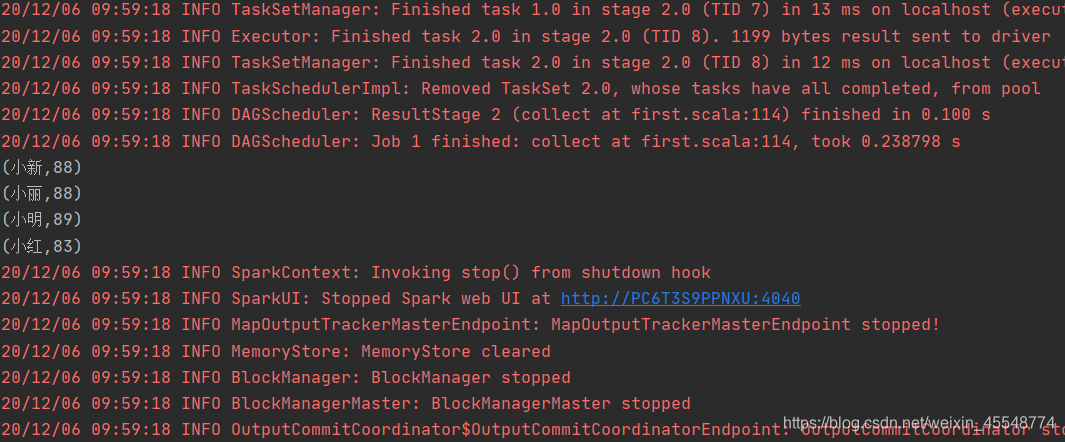
運行結果
5 采用手動打包上傳集群的方式實作2的內容
首先建立a.txt和b.txt,將其上傳到hdfs上
hadoop fs -put /opt/spark/b.txt /
hadoop fs -put /opt/spark/a.txt /
代碼如下:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
import java.io._
object first {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("first")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val A = sc.textFile("/a.txt")
// 讀取檔案B
val B = sc.textFile("/b.txt")
//val data = sc.textFile(dataFile,2)
val c = (A ++ B).distinct
val da = c.distinct()
da.coalesce(1,true).saveAsTextFile("/result")
//da.saveAsTextFile("file:///opt/spark/c.txt")
val res=da.collect()
for(item<-res) {
println(item)
}
}
}
將代碼打成jar包上傳到集群中
docker cp C:\Users\Administrator\Desktop\untitled2.jar master:/opt
之后運行程式
spark-submit --class first --master yarn-client untitled2.jar
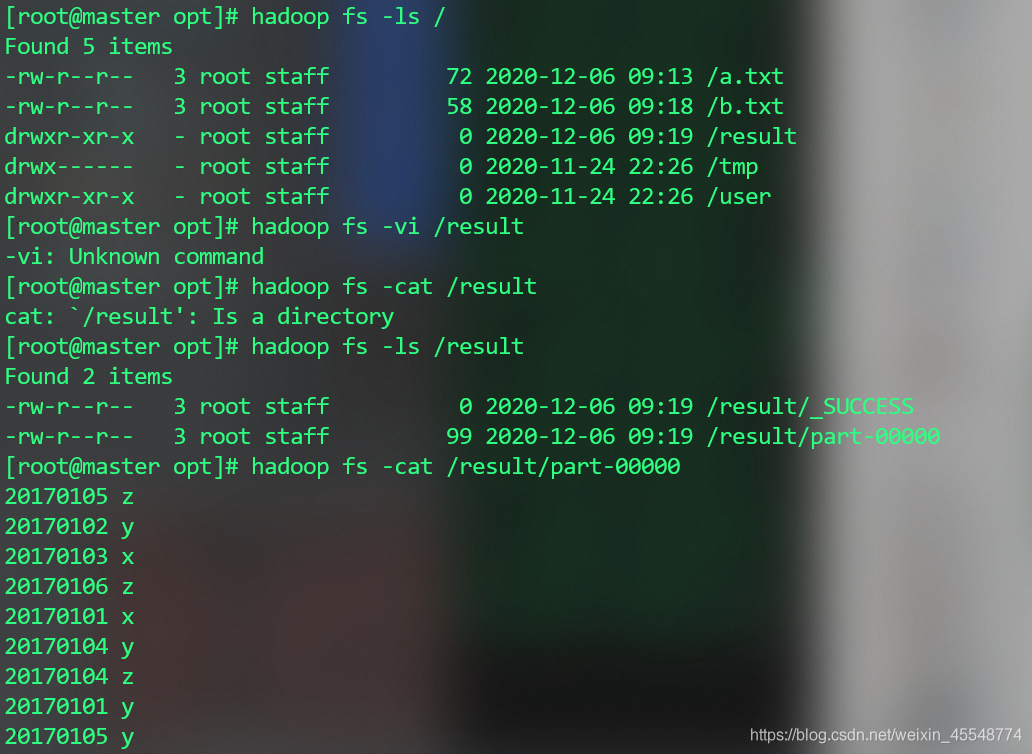
查看運行結果
由于寫的比較匆忙,內容比較多,其中可能出現以下小問題,歡迎大家批評指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231120.html
標籤:其他
上一篇:呼叫MapReduce對檔案中各個單詞出現次數進行統計
下一篇:阿里春招實習Java后臺開發面經