今天是持續寫作的第 17 / 100 天,
如果你有想要交流的想法、技術,歡迎在評論區留言,
從本文開始,將通過一個個的案例帶你進入無編碼學爬蟲領域,玩轉 Web Scraper,萬物皆可爬,
此類教程涉及圖片比較多,學習的時候大量的依賴實操,所以在后續本系列內容將轉換為視頻載體提供給大家,

目標網站分析
本次要爬取的網站為:https://www.chuanboyi.com/zimeiti/search-catid-1-page-1.html,選擇本案例的原因是要解決一般分頁資料如何抓取的問題,
什么是一般分頁,例如本案例中資料的分頁方式就是通過底部的數字進行分頁,

通過點擊分頁跳轉鏈接發現分頁規則為,頁面的規則每個網站都不同,多點擊幾次一般都可以找到對應的規律:
https://www.chuanboyi.com/zimeiti/search-catid-1-page-1.html
https://www.chuanboyi.com/zimeiti/search-catid-1-page-2.html
https://www.chuanboyi.com/zimeiti/search-catid-1-page-3.html
https://www.chuanboyi.com/zimeiti/search-catid-1-page-4.html
首先創建一個新的爬蟲,sitemap 與 start url 書寫好即可,常規套路先測驗任意一頁的資料,實作之后再擴展到所有目標資料,
進入 selector 頁面,新增加一個選擇器,注意點選的時候至少點選 2 個元素,如果發現元素選擇沒有達到預期,例如下圖所示內容,繼續勾選直到選擇的資料是你期望的資料即可(希望動圖能給你增強理解),
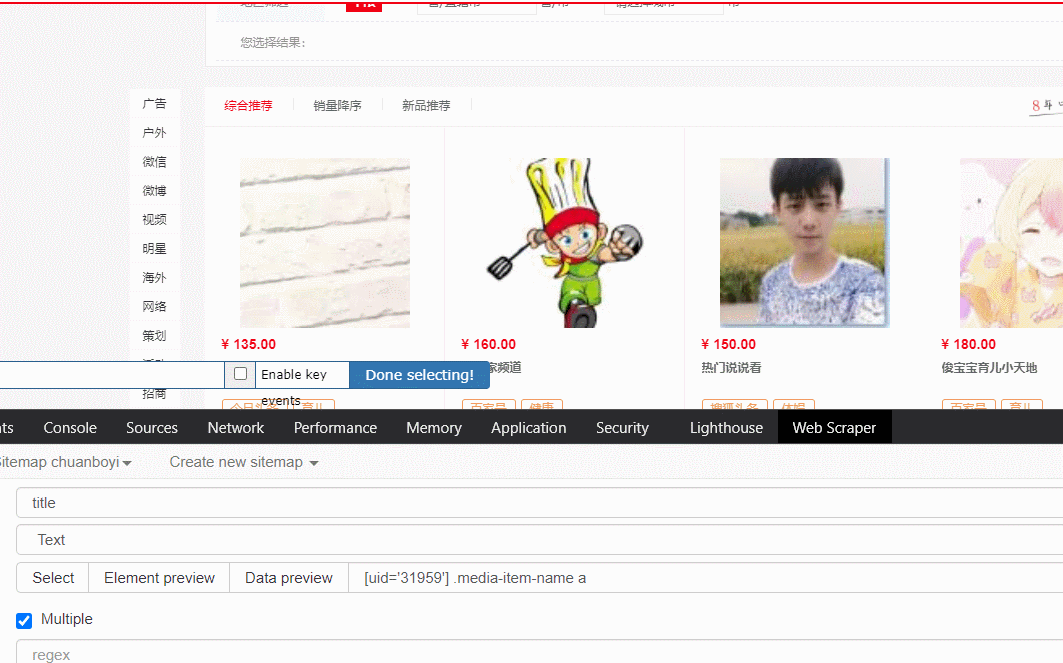
最終實作的效果是三個紅圈中的資料全部存在并且正確, Save Selector,
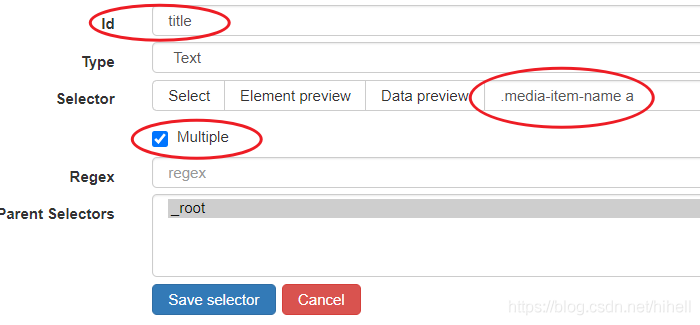
相同的手法在創建一個 price 選擇器,
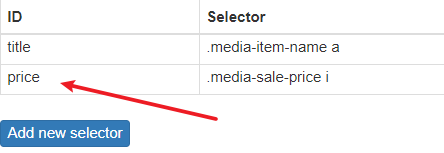
撰寫完畢如果需要修改注意是點擊右側的 Edit ,不要直接點擊選擇器,直接點擊選擇器會進入到子選擇器添加界面,撰寫的程序中還需要不斷的點擊 Data preview 去確定資料是否正確,

點擊 Element preview 會在頁面中通過紅色背景標記出選擇的資料,
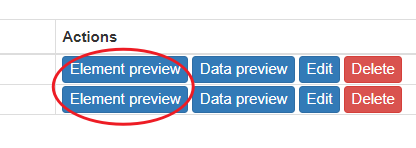
單頁資料已經拿到了,接下來修改一下 metadata,
Edit metadata 是什么意思? 非常簡單,就是可以修改
sitemap資訊,包含標題和起始地址,
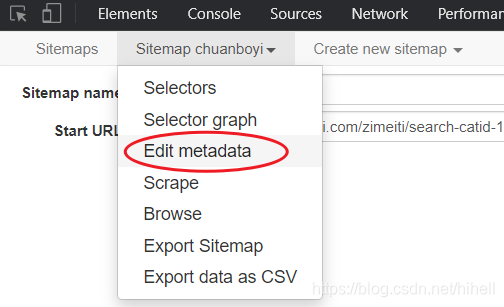
修改待抓取地址為多個,可以設定一個范圍的 URL,范圍 URL 設定格式為:
http://example.com/page/[1-3]
如果設定為上述內容,那在爬取的時候回批量生成 3 個地址,
http://example.com/page/1
http://example.com/page/2
http://example.com/page/3
也可以讓數字編碼按照 [001-100] 這樣的規律生成或者按照 [0-100:10],該內容表示生成 0-100 的數字,但是間隔 10 個數字,也就是生成的是 0,10,20,...,100,
以上設定需要預先知道總頁碼是多少,知道總頁碼之后就可以直接獲取到目標資料了,
運行代碼之后,在你的任務欄會出現一個蜘蛛網圖示,注意不要關閉了,

運行程序中還會出現一個小瀏覽器,左上角的頁碼在不斷的變動,表示資料在反復抓取,瀏覽器運行完畢會自動關掉,不要手動關閉(關閉爬蟲程式就停止運行了),

爬蟲運行完畢,會出現如下問題,實際資料發現如果設定多個選擇器,會導致鏈接爬取兩邊,資料并沒有放在一起,呈現的效果如下圖,還需要進行調整,
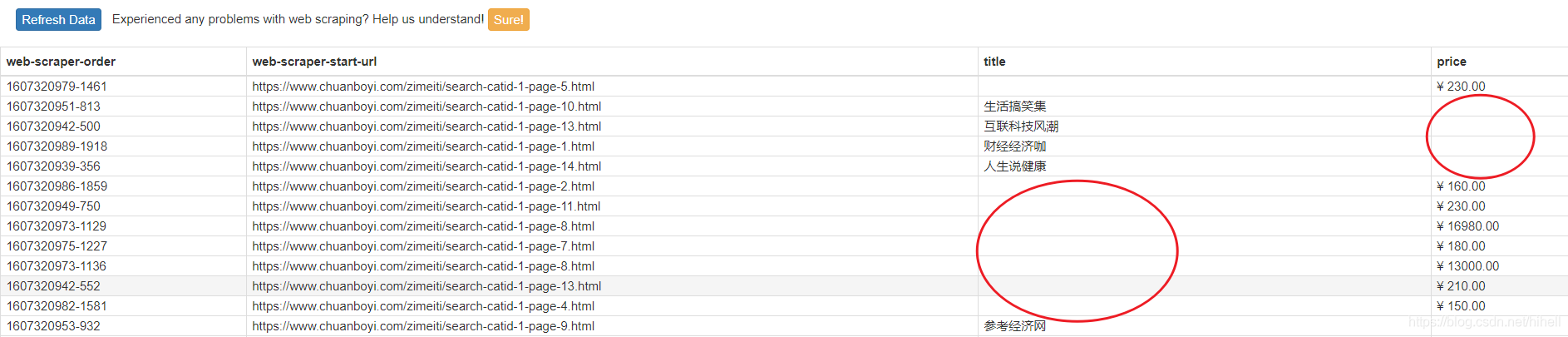
以下調整程序希望可以仔細練習,新知識要來嘍!
修改爬蟲,增加子選擇器
上文在選擇內容的時候出現了一點點小問題,資料抓取的不是我們期望的格式,咱希望抓到 title 和 price 在一行,此時就需要父選擇器與子選擇器搭配使用了,
啥叫父選擇器?網頁中的各個元素都可以看成一個盒子,盒子里面有各種東西,可以有小盒子,小盒子里面才放著目標資料,
這種一層一層的嵌套就出現了父級與子級的概念,大盒子就是父級,小盒子就是子級,如果小盒子里面再有一個小盒子呢?子子孫孫無窮盡也,
emmm 不是,其實很多時候,按照父級->子級->子級的子級,這樣是就能解決很多問題了,
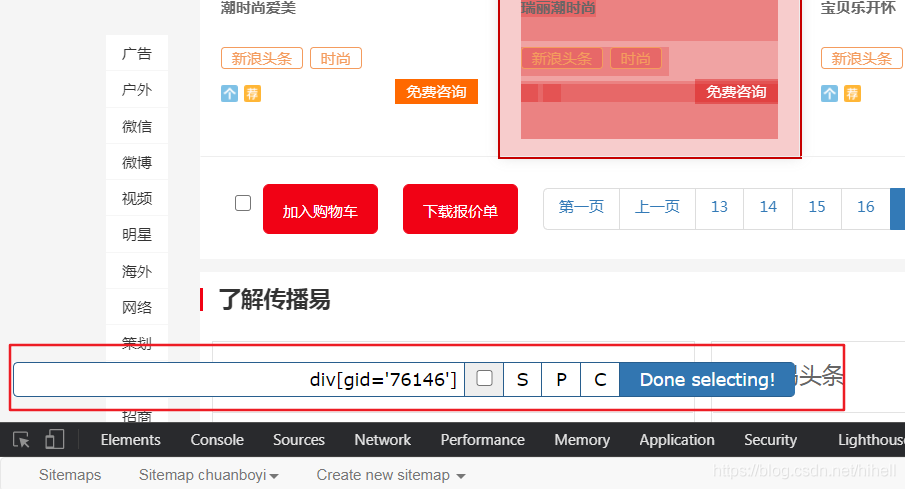
細心的你可能已經注意到每次選擇元素之后,都需要點擊一下一個按鈕,就是下圖的 Done selecting,完成選擇按鈕,在這個按鈕的左邊有三個東東,分別是 S,P,C,含義都在下面,使用的時候按鍵盤操作即可,一般微操的時候會用,
- S:Select,按下鍵盤的 S 鍵,選擇選中的元素
- P:Parent,按下鍵盤的 P 鍵,選擇選中元素的父節點
- C:Child,按下鍵盤的 C 鍵,選擇選中元素的子節點
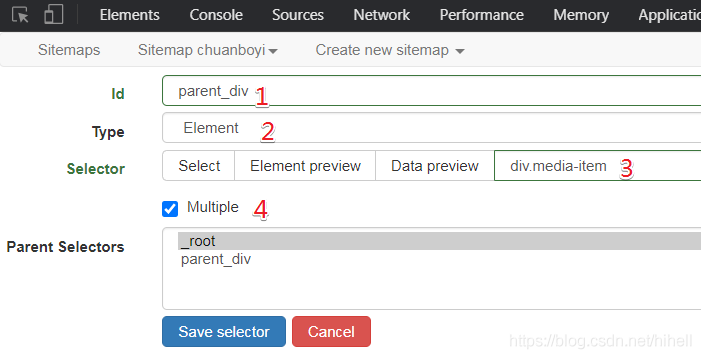
點擊 select 之后,框選最外層的大元素,也就是選擇一個目標區域最大的盒子,如下圖所示,
以下 4 個位置相關的內容都核對好,重點注意位置 2,此時我們選擇的是 Element 是由于上述動圖選擇的內容是后續的父級元素,所以此處為 Element內容,
目前對于這個 Type 下拉串列已經使用了 2 個選項了,一個是 Text,表示選擇文本,一個是 Element 表示選中標簽,別急后面還有好幾種,
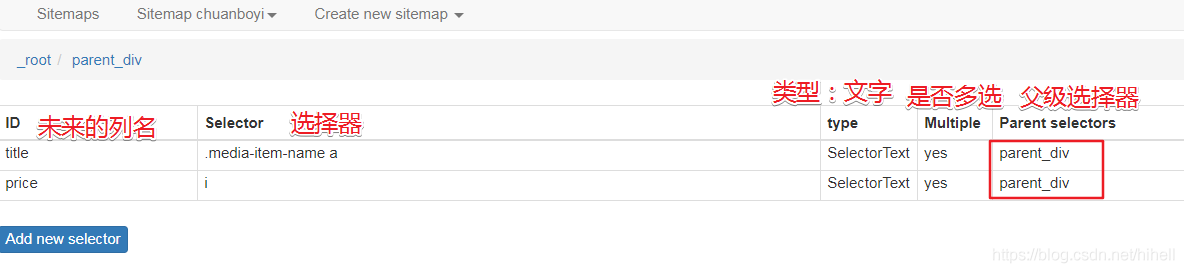
接下來的操作需要注意,要在父級標簽里面添加子元素選擇器,具體使用參考下圖,

下圖中尤其注意父級選擇器,title 和 price 的父級選擇器都是剛才創建好的 parent_div,如果剛才父級選擇器中的 Type 設定的是 Text,這里是沒有辦法選擇 parent_div 的,
設定為上述內容之后發現選擇的資料格式還是不正確,最終呈現的依舊是交錯資料,問題出現在多選位置,
目標資料二次調整
點擊下圖所示按鈕,出現其結構圖,
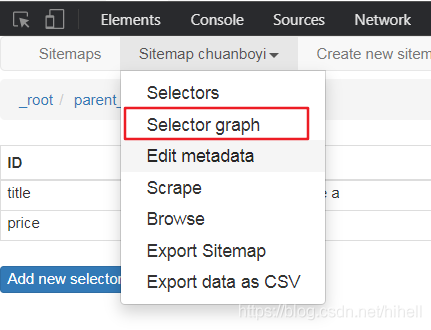
查看當前 sitemap 的選擇器圖,根節點是什么,包含幾個選擇器,選擇器下包含的子選擇器,如果是實心圓圈表示可以展開,

上述爬取資料已經說過是出現在多選位置上,如果使用父級 + 子級選擇器,最后的子級需要單選,因為一個父級元素中大概率有且僅有一個目標子元素,修改成如下內容,

點擊運行爬蟲程式,
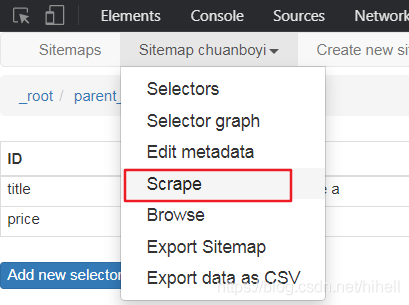
得到的資料如下圖所示,目標資料沒有任何問題,最終在把所有的頁面都匹配出來就可以完成任務了,
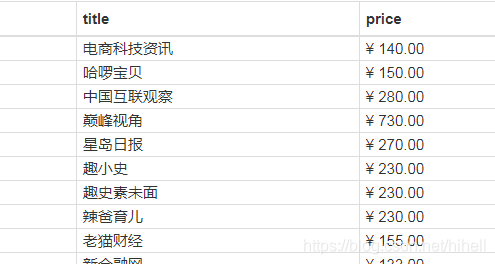
運行效果截圖,注意頁碼即可,
最侄訓取到了 1000 條資料,與期望值相同,案例完成,

寫在后面
逐步上路,使用 Web Scraper 會越來越有意思的,視頻課準備中,元旦前后應該可以首發 CSDN 平臺了,
想學 Python 爬蟲,可以訂閱橡皮擦專欄哦~
🈲🈲🈲🈲 《爬蟲百例教程》點擊發現驚喜 🈲🈲🈲🈲
如果你想跟博主建立親密關系,可以關注博主,或者關注博主公眾號“非本科程式員”,了解一個非本科程式員是如何成長的,
博主 ID:夢想橡皮擦,希望大家點贊、評論、收藏,
 CSDN認證博客專家
大學老師
高級產品經理
互聯網從業者
CSDN認證博客專家
大學老師
高級產品經理
互聯網從業者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/231980.html
標籤:AI
上一篇:資料結構(廿五) -- C語言版 -- 圖 - 圖的遍歷 -- 鄰接矩陣 - 深度/廣度優先遍歷/搜索(DFS、BFS)