背景
在一些影像相關的專案中,重復圖識別是很重要的,就比如熱圖排行榜(需要識別出重復圖);涉及影像深度學習的專案(訓練資料需要剔除重復圖);圖片原創&視頻原創(需要識別出重復圖)等等,
什么是相同圖片
什么是相同圖片?相信在不同場景下,這個答案是不一樣,有些場景把肉眼看起來一樣的圖片當作相同圖片,有些場景把用濾鏡處理過的圖片也當作相同圖片,而有些場景下只把原圖當作相同圖片,
這里按照相同程度劃分,相同程度從高到低,其實可以分為3個等級:
- 絕對原圖
- 肉眼相同
- 抄襲原圖
接下來我們逐一詳細介紹下這3類,
絕對原圖
這個等級,圖片相同的程度是最高的,就如下面2張圖片,1.png通過直接copy的方式產生的2.png

它們從圖片內容已經無法判斷是否是原圖,只能從檔案的角度識別,一般來說都是直接md5判斷2個圖片,如下所示:

它屬于用圖片檔案進行hash處理,
PS:一般來說,所有場景都會先用md5來過濾一邊,因為它演算法復雜度很低,根本不用理解圖片
肉眼相同
這個等級的場景最多,比如圖片訓練資料去重,熱圖排行榜等等,
就如下圖所示,1.png經過壓縮、resize、轉碼等圖片處理的方式產生的3.jpg:

它們肉眼看起來是相同,但是絕對不是原圖,md5無法識別這種情況,只能影像的感知hash處理,感知hash主要有3種(AHash、DHash、PHash),它們都是用圖片內容進行hash處理,只是hash方式不同,下面逐一介紹一波:
AHash
這種感知hash最簡單,演算法復雜度也最低,它只需要處理2步 預處理 + 二值化,
- 具體流程圖如下所示:
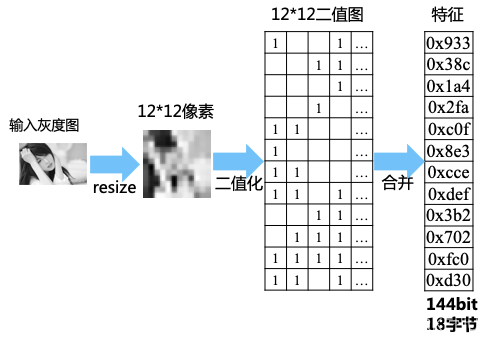
它的二值化方式比較簡單,只是比較了像素點跟均值,所以效果一般般,
- python原始碼如下:
def ahash(image, hash_size=8):
image = image.convert("L").resize((hash_size, hash_size), Image.ANTIALIAS)// 1、【預處理】轉灰度圖,resize
pixels = numpy.asarray(image)
avg = np.mean(pixels)//2、計算均值,這里也可以用中值
diff = pixels > avg // 3、【二值化】大于均值為1,小于等于均值為0
return diff
DHash
這種感知hash的復雜度也很低,重點是它比AHash的效果好,主要原因它二值化方式考慮上了相鄰像素的差值,演算法更加魯棒,(當然這只是一種思想,我們也可以比較固定的2個像素點的大小,每個像素點都有一個與之對應的像素點),
演算法流程圖如下(跟AHash差不多,差別在于二值化方式不一樣):
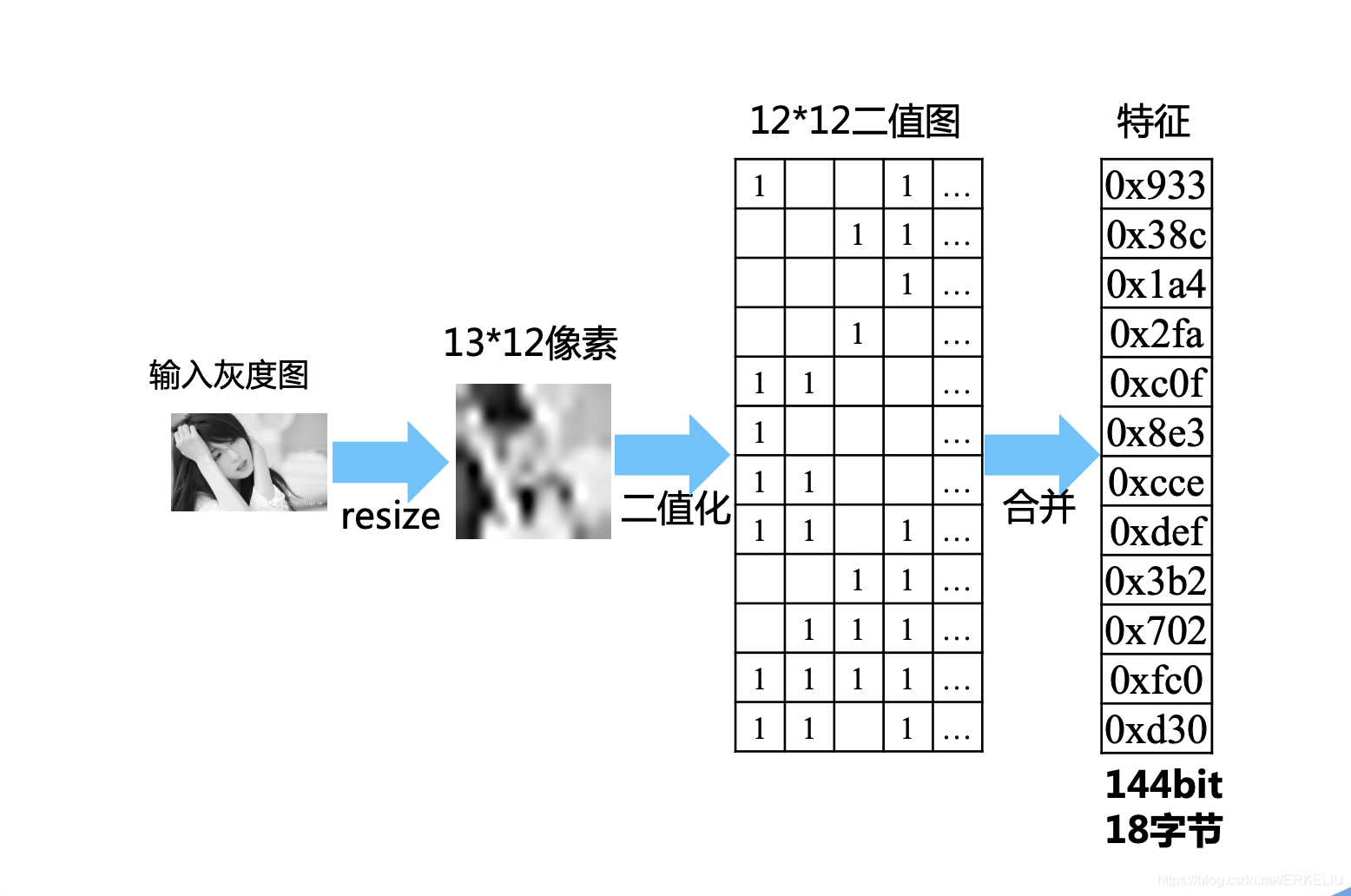
- python原始碼如下:
def dhash(image, hash_size=8):
image = image.convert("L").resize((hash_size + 1, hash_size), Image.ANTIALIAS)// 1、【預處理】轉灰度圖,resize
pixels = numpy.asarray(image)
diff = pixels[:, 1:] > pixels[:, :-1] //2、【二值化】相鄰2個元素對比,右邊大于左邊為1,右邊小于等于左邊為0,(也可以改成上下2個元素的對比,或者固定2個元素之間的對比)
return diff
Phash
Phash是目前效果最好,它引入了DCT變換,去除圖片中的高頻資訊,把注意力集中在低頻資訊中,這是由于人眼對于細節資訊不是很敏感,具體演算法原理見下一篇,
phash有很多種改版,下面只給出效果最好的一種,它的演算法流程圖如下:
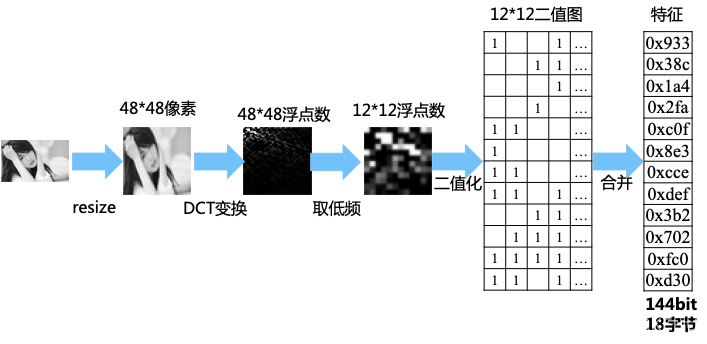
- python 原始碼如下:
def phash(image, hash_size=8, highfreq_factor=4):
import scipy.fftpack
img_size = hash_size * highfreq_factor
image = image.convert("L").resize((img_size, img_size), Image.ANTIALIAS)// 1、【預處理】轉灰度圖,resize
pixels = numpy.asarray(image)
dct = scipy.fftpack.dct(scipy.fftpack.dct(pixels, axis=0), axis=1) //DCT變換
dctlowfreq = dct[:hash_size, :hash_size] //2、只留下直流&&低頻變數
med = numpy.median(dctlowfreq) //取中值
diff = dctlowfreq > med //3、【二值化】大于中值為1,小于等于中值為0
return diff
抄襲原圖
這種場景也挺多的,而且其中每個場景都有自己獨特的要求,就比如一個視頻平臺,它的視頻原創專案,把加濾鏡、換音頻、裁剪等方式也判定為相同圖片的話,感知hash已經不適用,必須用上影像深度學習了,
一般來說也不需要很強的模型,但是必須針對性的訓練特定場景,就比如濾鏡,logo,黑邊等場景,
濾鏡就如下圖所示,1.png經過一個濾鏡產生了4.png:

還有一種場景是游戲領域的視頻去重,由于游戲背景都一樣,只有小小的一塊人物或者名字不同,也是需要針對性的加資料訓練的,
這里的話,深度學習 MoCo 可能會合適一些,
總結
重復圖在影像相關的專案中基本都會用到,不同的場景用不同的演算法,
| 復雜度 | 適用場景 | |
|---|---|---|
| MD5 | 超級低 | 絕對原圖 |
| 感知Hash | 低 | 肉眼相同 |
| 深度學習 | 高 | 特定場景相同 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232358.html
標籤:其他
上一篇:PHash從0到1
下一篇:MySQL開發規范與使用技巧總結