*歡迎關注【百度NLP】官方公眾號,及時獲取自然語言處理領域核心技術干貨!!
**閱讀原文:https://mp.weixin.qq.com/s/K_7_LgMZf1MuS4IJI6gdsw
開放域問答(Open-domain QA)一直是自然語言處理領域的重要研究課題,百度從面向端到端問答的檢索模型出發,提出了RocketQA訓練方法,大幅提升了對偶式檢索模型的效果,為實作端到端問答邁出了重要的一步,RocketQA已逐步應用在百度搜索、廣告等核心業務中,并將在更多場景中發揮作用,
近日,百度提出了面向端到端問答的檢索模型訓練方法RocketQA,該方法針對模型訓練中存在的問題,通過跨批次負采樣(cross-batch negatives)、去噪的強負例采樣(denoised hard negative sampling)與資料增強(data augmentation)等技術,大幅提升了對偶式檢索模型的效果,RocketQA不僅在多個問答相關資料集中取得了SOTA,同時也重繪了微軟MSMARCO資料集段落排序任務的榜單,超越谷歌、微軟、Facebook、阿里、美團、卡內基梅隆大學、清華大學、滑鐵盧大學等企業和高校位居第一,為實作“端到端問答”邁出了重要的一步,
論文名稱:RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
論文地址:https://arxiv.org/abs/2010.08191
一、開放域問答系統
開放域問答(Open-domain QA)是自然語言處理領域的重要研究課題,它的任務是,基于用戶用自然語言提出的問題,從海量候選文本中快速、精準地找出答案,開放領域問答在智能搜索、智能助手、智能客服等多個場景下,都發揮著重要作用,特別是近些年,隨著各種智能手機、智能音箱的普及,智能搜索快速進化,通過開放域問答系統直接給出唯一的精準答案(如圖 1 所示),可以幫助用戶在這些小屏和無屏設備上更快速、準確地獲取有用資訊,
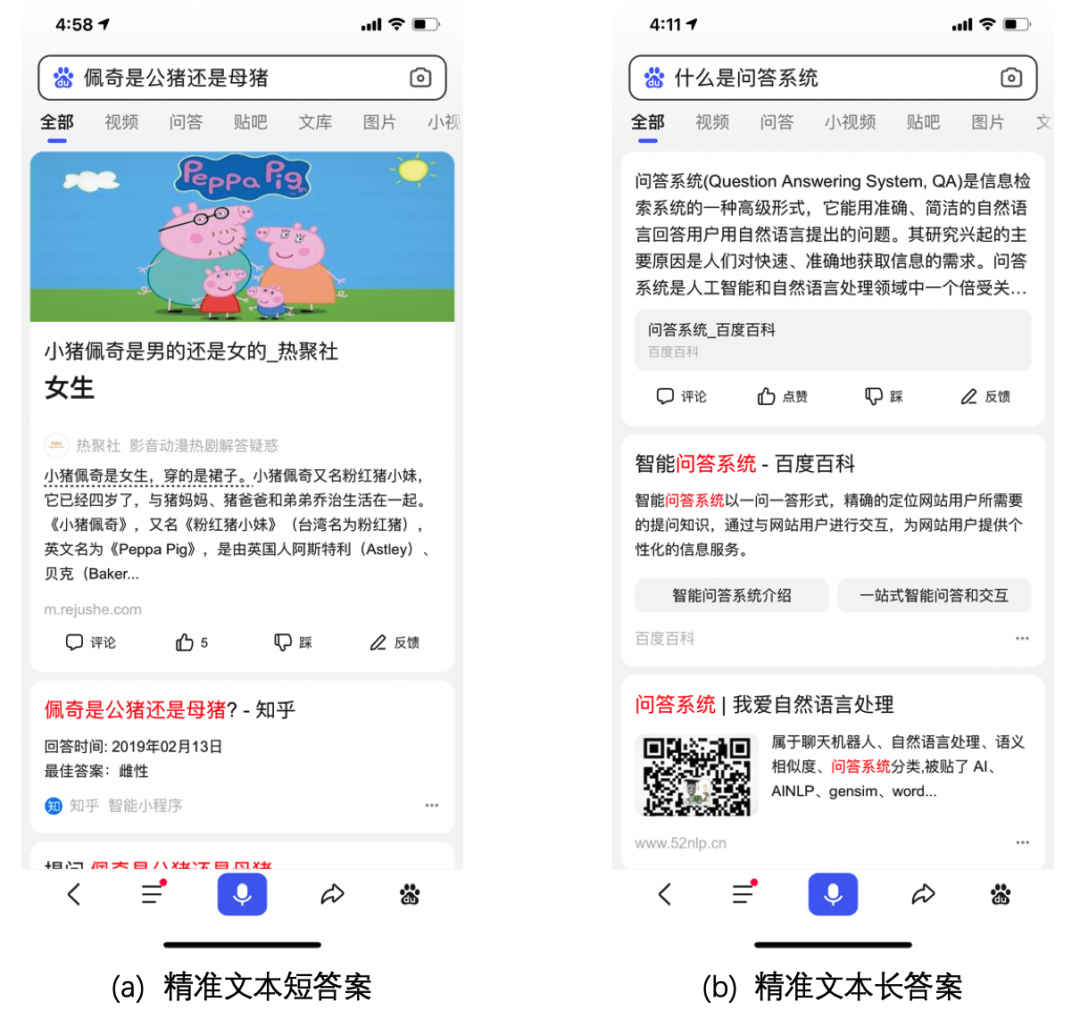
圖1:百度搜索的TOP1結果:將問題的答案展現在搜索結果的首位,提升用戶體驗
傳統的開放域問答主要采用級聯的檢索式問答系統,包含了段落檢索、段落排序、答案定位等多個步驟,隨著近些年預訓練語言模型的發展,研究人員開始探索基于深度語意表示的對偶式檢索模型(dual-encoder),希望其能夠替代傳統的檢索式問答系統中級聯的檢索和排序等模塊,與基于機器閱讀理解模型的答案定位一起實作“端到端問答”,
不同于傳統的級聯式問答系統,“端到端問答”摒棄了傳統系統中繁雜的構件,系統復雜性大大降低,并且其中每個模塊(段落檢索和答案定位)都是可學習的,這樣的設計能夠讓整個系統實作端到端訓練,這意味著問答系統可以基于用戶實時的反饋實作在線訓練,而不是只在封閉的資料集上閉門造車,這是智能問答技術的發展趨勢,可能會引發問答系統的新一代技術變革,
基于此,百度從面向端到端問答的檢索模型出發,針對對偶式檢索模型訓練中存在的問題,提出了RocketQA訓練方法,并基于百度自研的預訓練模型ERNIE進行訓練,大幅提升了對偶式檢索模型的效果,為實作端到端問答邁出了重要的一步,
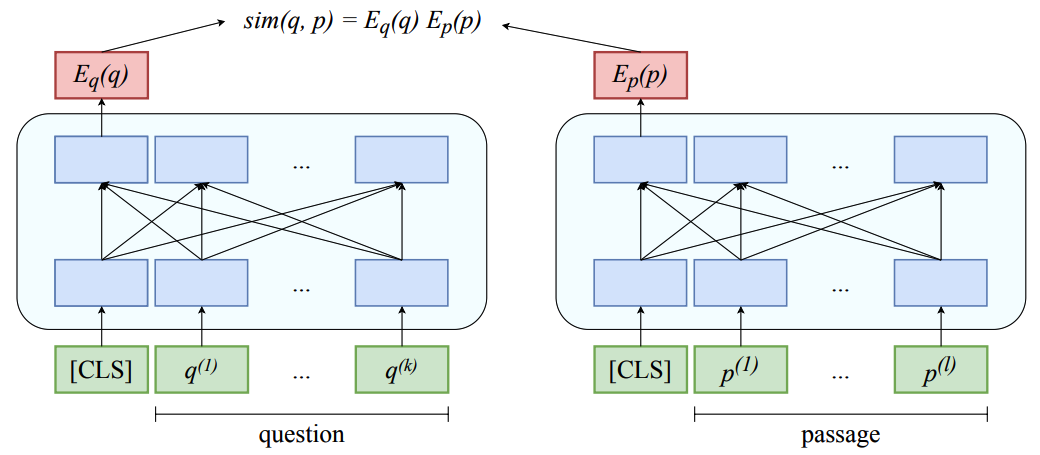
圖2:基于稠密向量表示的對偶模型
二、RocketQA:一種對偶式檢索模型增強訓練方法
不同于傳統的檢索模型使用基于關鍵詞的稀疏表示對問題和候選段落進行建模,基于深度語意表示的對偶式檢索模型(如圖 2 所示)通過兩個對稱的網路分別對問題和候選段落進行編碼并計算語意相似度,這樣能夠利用強大的網路結構進行更深層次的學習,同時基于預訓練語言模型,使語意理解更加豐富,在過去的作業中,對偶模型大多采用批次內負采樣 (in-batch negatives) 的方式進行訓練,將批次內其他問題的正確答案作為當前問題的錯誤答案(負例),從而減少重復計算和提高訓練效率,然而,由于檢索場景不同于常見的分類問題,對偶式檢索模型的訓練仍然存在如下的挑戰:
訓練場景和預測場景中樣本數量存在較大差異
在開放域問答的應用場景中,模型需要從大規模的候選集合中找出問題的答案,但是按照批次內負采樣的方法訓練時,每個問題的候選段落個數與批次大小相同,受到單GPU顯存大小的限制,訓練程序中見到的候選段落遠小于預測時的候選段落,從而導致模型即使在訓練時表現良好,在實際應用當中卻差強人意,
資料集中存在大量漏標注的正確答案
開放域問答場景下候選段落的數量往往非常大,標注出問題的全部正確答案幾乎是不可能的,在MSMARCO資料集中,候選段落的總數為880萬,但每個問題平均只標注了1.1個正確答案,研究人員發現,在使用對偶模型檢索出的首條結果中,70% 的錯誤結果其實是漏標的正確答案,這種情況下,構造訓練資料中的強負例時很容易引入假負例(false negative),給模型訓練帶來負面影響,
相對于開放域全集,人工標注訓練資料的規模小、成本大
盡管目前已有較多大規模的問答資料集,但是相較于開放域的用戶問題來說,仍然是冰山一角,有限的標注資料集無法覆寫到全面的領域和型別,導致模型泛化性差,想要增大標注資料的規模和質量,需要很高的人工成本,
因此百度提出了一種對偶式檢索模型的增強訓練方法RocketQA,通過跨批次負采樣、去噪的強負例采樣與資料增強三項技術,解決上述挑戰,接下來將對這三個技術進行詳細的介紹,
2.1 跨批次負采樣(cross-batch negatives)
采用傳統的批次內負采樣方法訓練時,每個問題的候選段落個數與批次大小相同,為了進一步增加訓練程序中候選段落的數量,百度提出了跨批次負采樣方法(如圖 3 所示),該方法能夠在使用多GPU并行訓練時,將其它GPU批次內的全部段落作為當前問題的負樣本,這樣可以直接復用各個GPU上已經計算好的段落表示,不額外增加計算量;同時基于飛槳分布式訓練擴展工具包FleetX的all-gather算子實作,只需要使用很少的通信量和記憶體開銷,就達到了增加每個問題候選段落的目的,隨著GPU個數的增加,每個問題的候選段落個數線性增加,訓練場景中的任務難度也更加接近真實場景,百度在MSMARCO資料集上進行了實驗,在使用跨批次負采樣后,隨著訓練時候選段落數量增加,模型的效果穩步提升(如圖 4 所示),
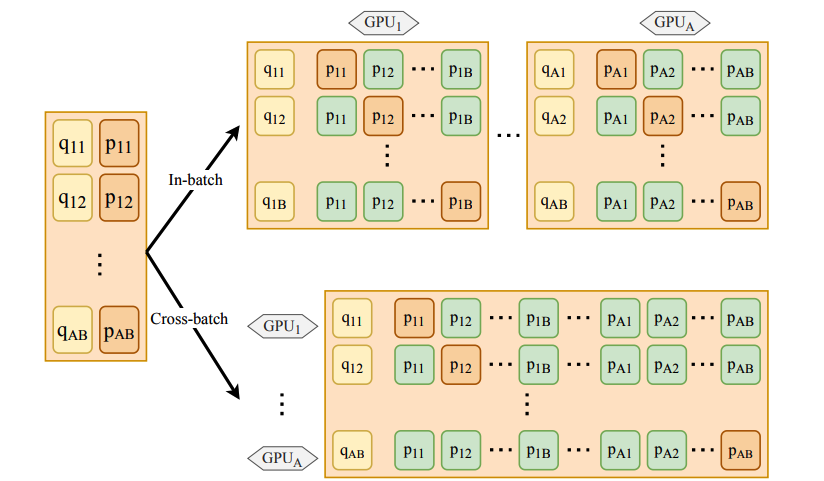
圖3:批次內負采樣(上)和跨批次負采樣(下)的對比
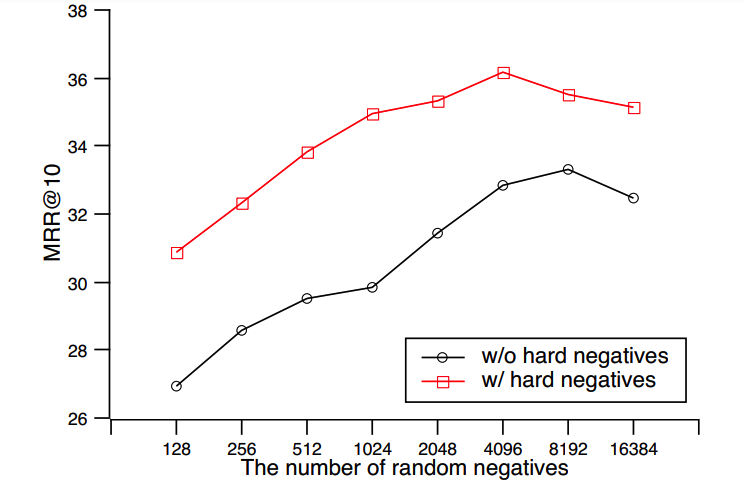
圖4:MSMARCO資料集中,訓練階段候選段落的個數對模型效果的影響
2.2 去噪的強負例采樣(denoised hard negative sampling)
在對偶模型的訓練中,適當增加訓練資料中的強負例的難度,有助于提升模型效果,一般的做法是,從一個排序的候選段落中進行采樣,越靠前的負例對模型來說難度越大,但是由于難以避免的漏標注情況,直接采樣很大概率會引入假負例,為了解決這一問題,百度使用互動模型(cross-encoder)的打分作為監督資訊進行去噪,在選擇強負例時,避開互動模型給出高置信度的樣例,相較于對偶模型,互動模型具有結構上的優勢,能夠編碼更多的互動資訊,從而給出可靠的監督信號,幫助對偶模型選取更可靠的強負例,如表1的第三行和第四行所示,去噪的強負例采樣可以顯著提升模型效果,
2.3 資料增強(data augmentation)
互動模型可以過濾強負例中的噪聲,也可以用來選取未標注的正確答案,因此,當引入大量無標注的問題時,便可以利用互動模型以極低的成本得到大量弱監督資料,進一步增強對偶模型的能力,在MSMARCO資料集的實驗中,百度引入了Yahoo!Answers和ORCAS資料集中的150萬未標注問題,用互動模型在對偶模型檢索出的候選段落上進行打分,并根據置信度選取正負樣本,如表1第四行和第五行所示,通過這種方式,對偶模型的效果得到進一步提升,

表1:MSMARCO資料集中,去噪的強負例采樣與資料增強策略對模型效果的影響
2.4 訓練流程和實驗結果
上述三項技術是層層遞進的關系,將它們整合成一套完整的訓練方法,類比多級火箭,稱之為RocketQA,其完整實作流程如圖5所示,在實作中,使用了百度研發并開源的大規模英文預訓練模型ERNIE初始化模型引數,然后使用標注資料進行微調,
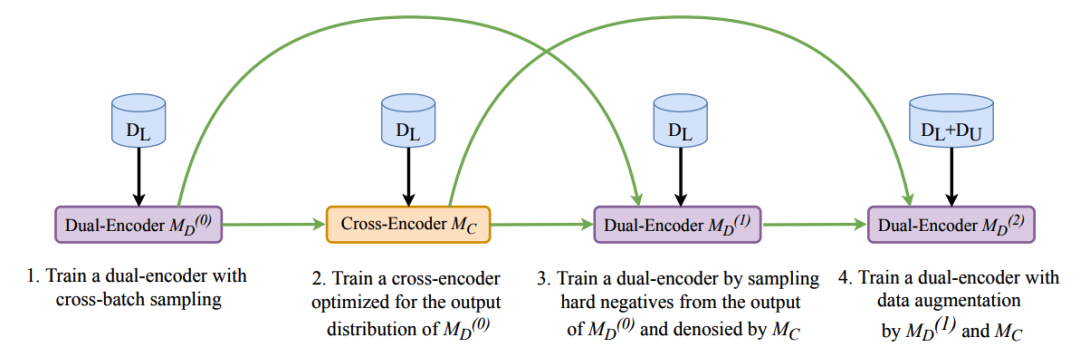
圖5:RocketQA訓練流程
如表2所示,最終的實驗結果表明,RocketQA在微軟MSMARCO和谷歌Natural Question資料集的效果均大幅超過了已經發表的最好的檢索模型,同時,百度也在答案抽取任務上驗證了RocketQA檢索結果的有效性,如表3所示,在RocketQA做檢索的基礎上,使用訓練好的閱讀理解模型,百度在Natural Questions的答案抽取任務上取得了42.0的EM值,超過了已有的相關作業,而這其中的增益來自檢索效果的提升,
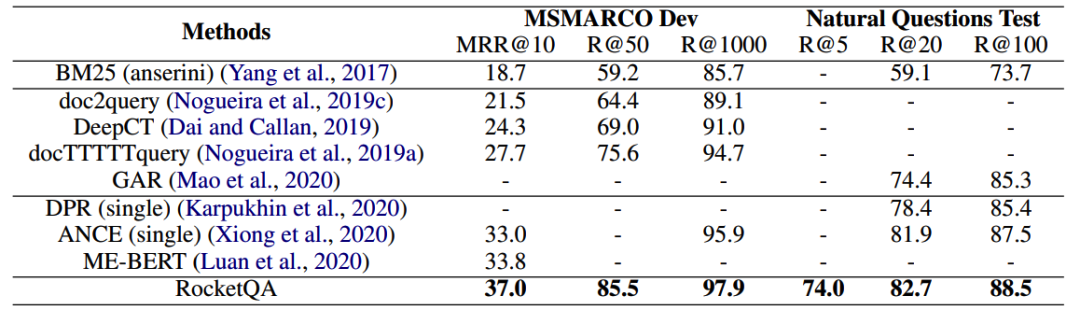
表2:RocketQA在微軟MSMARCO和谷歌Natural Questions資料集上段落檢索的效果
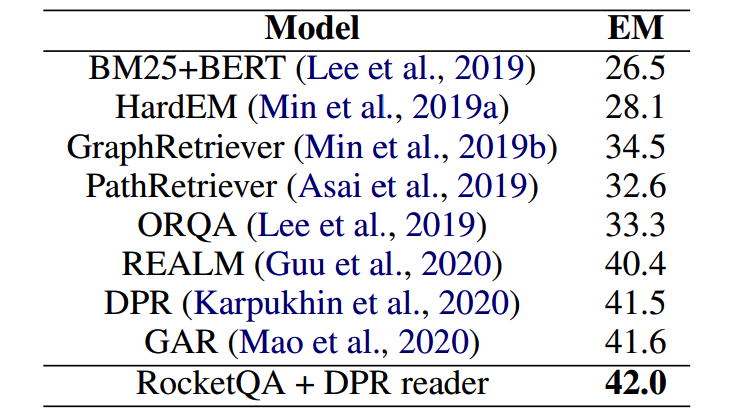
表3:RocketQA在Natural Questions資料集上做閱讀理解任務的效果
三、RocketQA在MSMARCO段落排序任務中奪得第一
MSMARCO(Microsoft Machine Reading Comprehension)是微軟提出的大規模閱讀理解資料集,包含約100萬問題、880萬相關段落以及人工標注的問題答案,資料集的問題來自Bing搜索引擎的日志, 是真實搜索場景中用戶提出的問題,段落來自Bing的搜索結果,基于MSMARCO資料集,微軟舉辦了包括閱讀理解、段落排序在內的多個問答相關任務的評測任務,由于資料集規模大、貼近真實場景,MSMARCO的各項任務已經吸引了包括Google、微軟、Facebook、阿里巴巴等知名企業,以及清華、CMU等國內外著名高校的參與,如圖6所示,百度基于 RocketQA檢索模型的結果進一步訓練了段落重排序模型,在MSMARCO的段落排序(Passage Ranking)任務中排名第一,超越了谷歌、微軟、Facebook、阿里、美團、卡內基梅隆大學、清華大學、滑鐵盧大學等企業和高校,
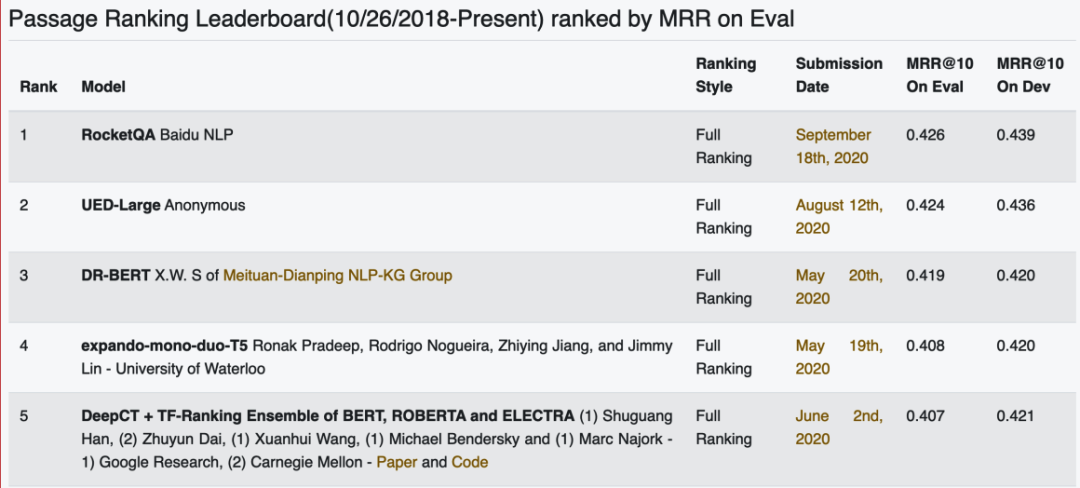
圖6:微軟MSMARCO Passage Ranking資料集leaderboard截圖
四、飛槳分布式訓練加持RocketQA
飛槳框架通過持續迭代升級,在分布式訓練方面真正做到了從產業實踐中來,回到開源社區和產業實踐中去,在飛槳框架最新版本中,分布式訓練繼承了之前版本高性能、高擴展的能力,在易用性方面進行了精心的優化,
paddle.distributed.fleet是飛槳框架2.0新API體系下通用分布式訓練API,千億規模稀疏引數服務器和大規模GPU多機多卡訓練都可以通過幾行代碼輕松配置完成,DistributedStrategy作為用戶配置并行策略的統一入口,支持大規模異步訓練、自動混合精度、深度梯度壓縮、重計算、梯度累計、計算算子自動融合、通信梯度智能融合以及自動并行等功能,極大的滿足了研究人員日常訓練的加速需求,飛槳框架的最新版本同時也開放了能夠面向高級編程用戶的分布式底層通信介面paddle.distrbuted,使用戶能夠自主構建諸如自動并行、模型并行等高級并行訓練功能,目前,飛槳大規模分布式訓練已經在百度日常業務中進行過深入錘煉,并每天都在根據業務的痛點進行改進和優化,
RocketQA的實作完全基于飛槳深度學習框架,特別在研發演算法的程序中飛槳的高性能并行訓練助力了各種想法的快速嘗試,研究人員在使用飛槳官方提供的paddle.distributed.fleet進行訓練的同時,也采用了飛槳分布式訓練擴展工具 FleetX,FleetX作為飛槳框架分布式訓練擴展工具,提供資料分片并發下載,快速定義模型,快速提交集群任務等功能,極大的提升了研發人員的使用效率,RocketQA采用paddle.distributed.fleet API提供的經典資料并行訓練方案,并采用自動混合精度、算子融合進行縱向擴展性的提升,同時采用梯度融合,計算與通信自動并發等策略提升橫向的擴展性,從而大幅度提升實驗效率,
為了實作RocketQA的跨批次負采樣,對單卡能夠見到的負樣本規模有較大的需求,研究人員使用了飛槳paddle.distributed提供的底層集合通信操作all-gather算子,將資料并行訓練中各塊卡的隱層向量進行匯總,擴大單卡可以見到的負例數量達到GPU卡數倍;為了進一步增加每塊卡可以見到的全域負例樣本,研究人員還使用了重計算(recompute)策略,該策略以20%左右的計算開銷將整個模型的訓練使用的顯存占用從O(N)降低到O(LogN),在該模型中使用Recompute使訓練資料批次大小提升5倍以上,對訓練計算圖的改寫結果如圖7所示,這樣,跨批次負采樣方法與傳統的純資料并行方法相比,實作了負例數量5xGPU卡數的倍數增長,從而加快了收斂速度和收斂效果,
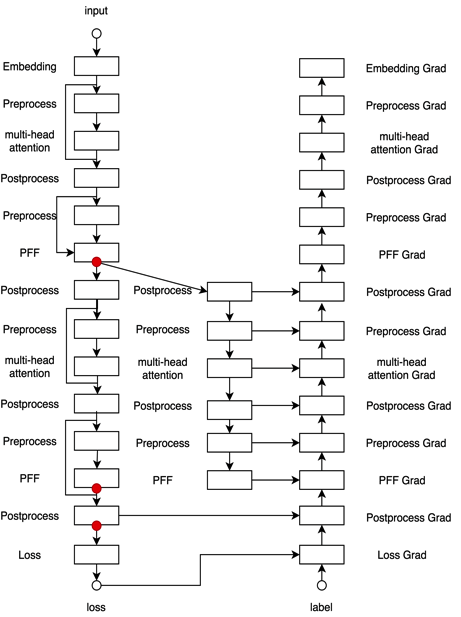
圖7:Multi-Head Self Attention利用重計算后的計算圖
五、總結
百度提出的RocketQA訓練方法,通過對經典對偶模型進行優化訓練,顯著提升了模型的檢索能力,為實作端到端問答邁出了重要一步,目前,RocketQA已逐步應用在百度搜索、廣告等核心業務中,并將在更多場景中發揮作用,
百度自然語言處理(Natural Language Processing,NLP)以『理解語言,擁有智能,改變世界』為使命,研發自然語言處理核心技術,打造領先的技術平臺和創新產品,服務全球用戶,讓復雜的世界更簡單,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232623.html
標籤:其他