影像分類和面部識別
- 總覽
- 在機器學習中的主要步驟
- 機器學習的訓練和測驗
- 面部識別 (Face Recognition)
- 人類方法
- 應用
- 面部特征 (本地local和整體holistic)
- 配置資訊 (Configure Information)
- 計算機視覺方法
- 面部識別系統
- 早期設計
- 特征臉 (Eigenfaces)
- 主成分分析 PCA
- 特征臉演算法
- 特征臉演算法 - 檢測
- 線性判別分析 (Linear Discriminated Analysis - LDA)
- 區域二進制模式 (Local Binary Patterns)
- 人臉歸一化 (Normalization of Faces)
總覽
給定影像或物件的影像,標識影像或物件所代表的物件的類別,

在機器學習中的主要步驟
- 特征提取(feature extraction): 手動設計的特征(hand-crafted features),比如幾何特征(Geometry-based),形狀,
基于外觀 (apperance-based), 全域 (即 特征臉 eigenfaces,顏色直方圖 color histogram,BOW) 和/或 區域 (即SIFT, BOF),
基于學習(Learning-based), - 分類 (Classifer): 通常涵蓋在機器學習或模式識別(pattern recognition)中,貝葉斯,K-NN,SVM,MLP等,
機器學習的訓練和測驗
資料集:
- 有標簽的(labelled),帶有基本事實 (ground truth) 的資料樣本,
- 無標簽的(unlabelled),不帶基本事實的資料樣本,
被分為:
- 訓練集
- 驗證集
- 測驗集
不平衡資料集(unbalance dataset): 每個類別的資料樣本數量明顯不同,
性能標準:
- 范圍 (Scope),類別數量,
- 穩鍵性,對噪聲,明度變化,比例改變穩鍵,
- 高效 efficiency,節省計算資源(時間和空間)
- 有效性 effectiveness (準確性和混淆矩陣)
面部識別 (Face Recognition)
人類方法

從靜止影像 (still images) 或視頻序列中檢測人臉,將檢測到的面部與存盤在資料庫中的面部進行比較,確認或拒絕所獲取的身份 (claimed identity identification),從資料庫確定身份,
應用
- 攜帶ID (面部識別),
- 語音識別 (通過唇讀增強 lip-reading),
- 通過面部表情表達情感,
- 訪問控制和安全 (access control and security),
- 智能卡 (smart cards),
- 執法 (law enforcement),
- 監視 (surveillance),
面部特征 (本地local和整體holistic)
- 個體面部成分 (individual facial components),區域特征,
- 組件之間的關系,整體配置 (holistic configuration),

與未對齊的兩半對齊后,執行此任務要困難得多, 大概是因為整體處理 (holistic processing) 與基于特征的處理 (feature-based processing) 相互作用(在這種情況下會干擾 interferes)

由于整體資訊發生變化,人臉反轉(face inversion)會干擾人臉識別,
面部關鍵點:
- 眼睛 -> 嘴巴 -> 鼻子,
- 使用側面像 (profiles) 時,獨特的鼻子形狀可能更重要,
- 臉的上半部分比較有用,
- 眉毛至少和眼睛一樣重要,
配置資訊 (Configure Information)
我們是否需要精確測量屬性,例如眼間距離,嘴巴寬度和鼻子長度?
更改x和y維度上的特征距離 (interfeature distance) 和距離比率 (distance ratio) 后,仍然可以識別,

同一維度內的距離比例保持不變
邊緣和線段:
- 視覺輸入的初始表示,也是捕獲影像的最重要方面,
- 對照明變化具有不變性,
- 但是還不足夠,
一些研究表明物件識別是對視點變化具有不變性(viewpoint invariant)的,
一些實驗表明,面部記憶與視點高度相關(viewpoint-dependent),
從一個側面的視點到另一種視點的泛化性 (generalization) 很差,而從一個四分之三的視點到另一視點的泛化性是很好的,
計算機視覺方法
面部感知是整體分析還是區域特征分析的結果?
- 整體方法: 使用整個面部區域作為輸入,
- 區域方法: 使用區域特征(如 幾何/外觀)
- 混合方法 (hybrid methods): 同時使用區域特征以及整個面部區域,
面部特征的重要性, 特征的權重不同
視點不變研究, 處理姿勢問題 (pose problem)
面部識別系統
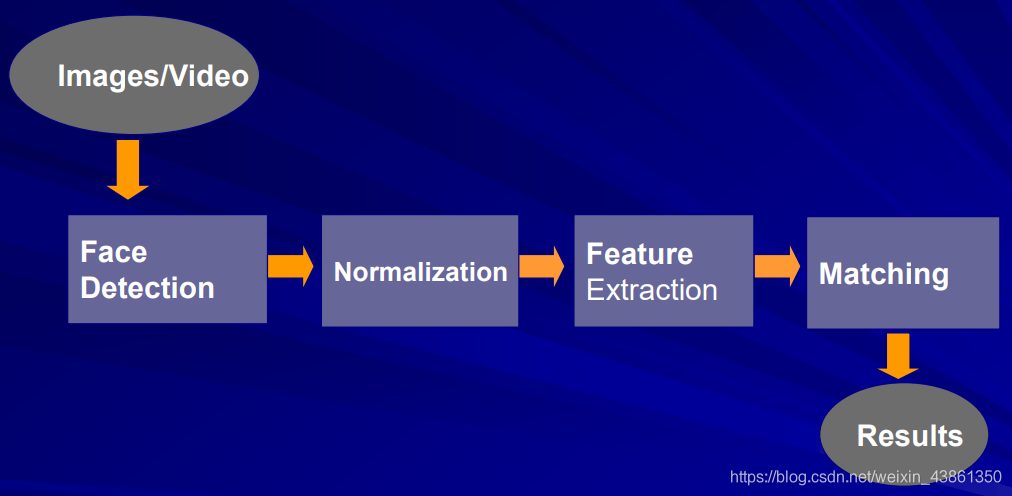
早期設計
基于幾何的方法 (geometric-based) 被廣泛使用
- 幾何特征:兩只眼睛之間的距離,嘴唇的粗細……
- 從參考面手動提取
- 存盤為模板以供以后匹配
- 提供有限的結果
- 通常使用少至10張影像的資料集進行實驗,
特點:
- 不受光照變化的影響
- 不需要多個訓練樣本
- 幾何特征不可靠(由于運動和視圖)
- 測量和位置需要手動計算(最大的缺點)
特征臉 (Eigenfaces)
Sirovich和Kirby在1987年開發了使用特征臉進行識別的方法,1991年由Turk和Alex Pentland在人臉識別中使用,自動面部識別技術 (automated facial recognition) 的第一個成功例子,
這是一個基于主成分分析(Principle Components Analysis, PCA)的整體方法,快速且相對簡單,
主成分分析 PCA
是一種識別資料模式并以突出其相似性和差異性 (similarities and differences) 的方式表示資料的方法,可以尋找可以有效表示資料的方向,其能夠減少資料的維度 (reduce the dimension of the data) 并用于加快計算時間,
例子:
這是一個二維的資料集
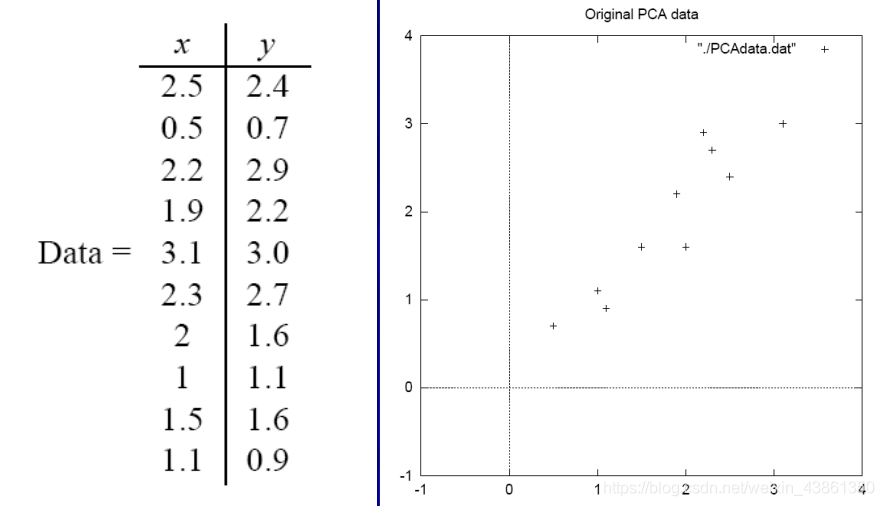
將所有資料與其均值相減
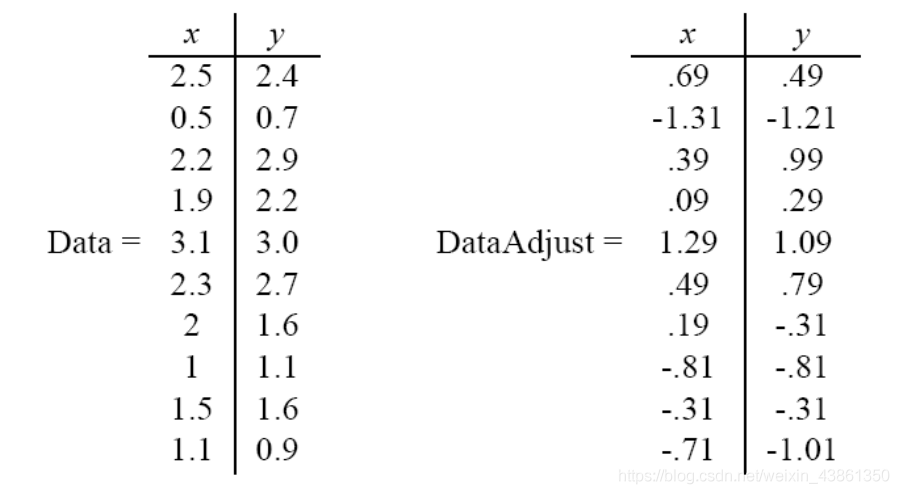
接著,求協方差矩陣(covariance matrix)
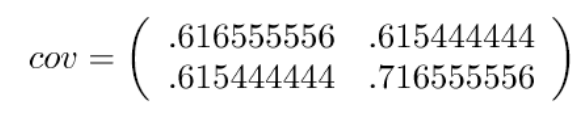
接著求協方差矩陣的特征向量 (eigenvectors) 和特征值 (eigenvalues)
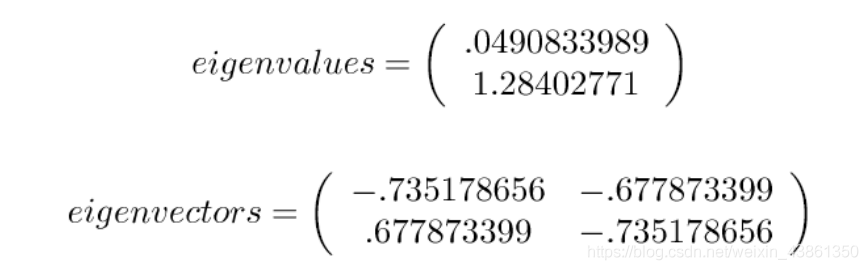
特征向量之一穿過點的中間,就像畫一條最擬合的線,接著該特征向量向我們展示了這些資料如何沿著這條線關聯,第二個特征向量為我們提供了資料中另一個不那么重要的模式,即所有的點都遵循主線,但會偏離主線的一定量,
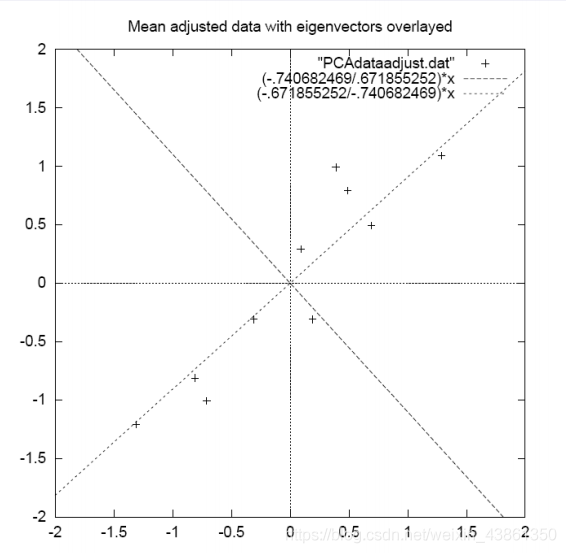
接著,我們可以使用兩個特征向量來轉換資料,將原始資料以特征向量為軸進行旋轉,現在,我們將資料點歸類為每條線的貢獻的組合,
在此分解中,不會有任何資訊丟失,
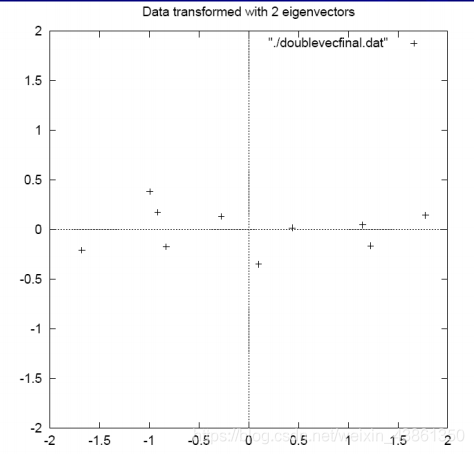
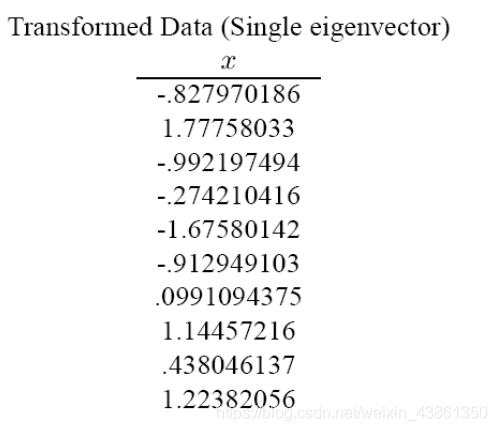
或者我們可以采用特征值最大的特征向量,此時較小特征向量的貢獻被去除,
基本上,我們已經對資料進行了轉換,以便根據它們之間的模式來表達,模式 (pattern) 是最緊密地描述資料之間關系的線,
特征臉演算法
假設: 影像是N x N = N2,M是資料庫中影像的數量,P是資料庫中人物的數量,
現在我們的訓練集有八張圖

計算“平均臉”(average face)


讓訓練集中的所有臉減去"平均臉"
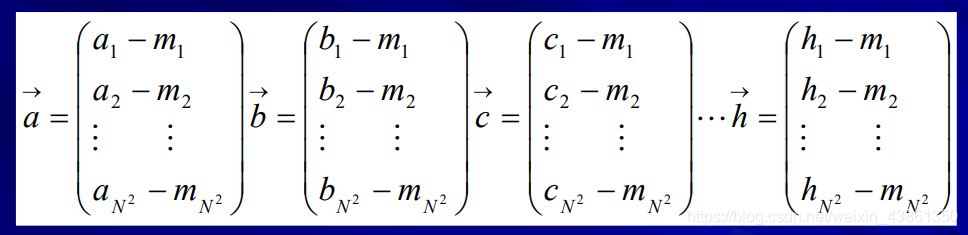
接著建立A矩陣,該矩陣存放了所有資料庫中所有臉部資訊,
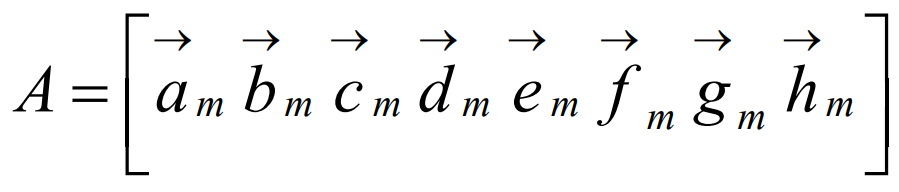
接著,計算A的協方差矩陣 (covariance matrix)
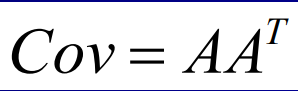
接著查找協方差矩陣的特征值 eigenvalue (矩陣很大, 計算量很大),我們最多對M個特征值感興趣,(減小矩陣的尺寸, 線性代數的技巧)
計算另一個矩陣
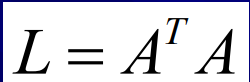
查找M個特征值和特征向量,其中,Cov和L的特征向量是等效的,每個特征向量都稱為訓練資料的特征臉 (AAT)
特征臉 (eigenface):

根據 L 的特征向量構建矩陣V,
協方差矩陣(Cov)的特征向量是影像空間與L的特征向量的線性組合,
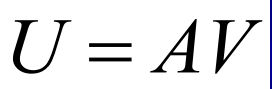
特征向量表示臉部的變化(variation in the faces),
計算每張臉在臉部空間上的投影 (projection onto the face space),
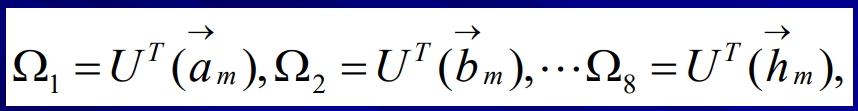
計算出閾值
特征臉演算法 - 檢測
輸入值,測驗臉部圖片(稱為測驗臉)

讓測驗臉減去"平均臉"
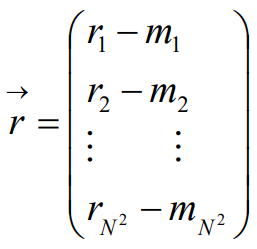
計算測驗臉在臉部空間的投射
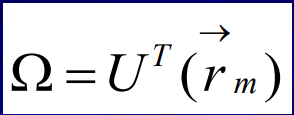
計算測驗臉與所有已知臉之間的臉部空間距離,臉部將會識別為臉部空間中最接近的臉部,
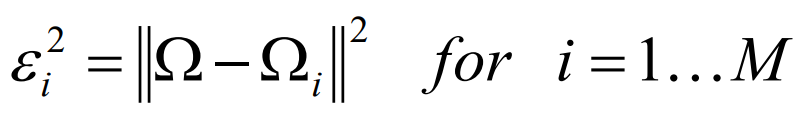
為了驗證,會將該距離與之前計算的閾值相對比,若小于該閾值,則確認這是一張已知臉,
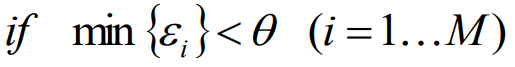
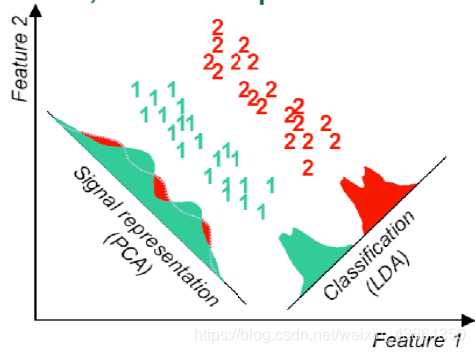
線性判別分析 (Linear Discriminated Analysis - LDA)
這個方法是特征臉的擴展,其通過最大化類間方差(maximising the between-class variance)和最小化類內方差 (minimising the within-class variance) 來尋找線性變化,當每個類別有多個樣本時,分類性能會提高,
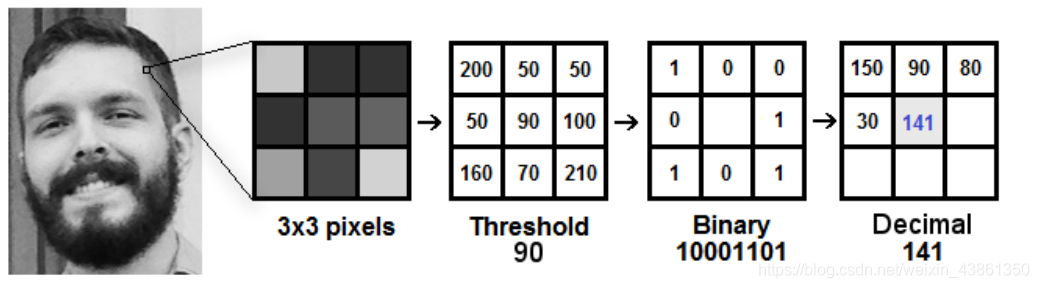
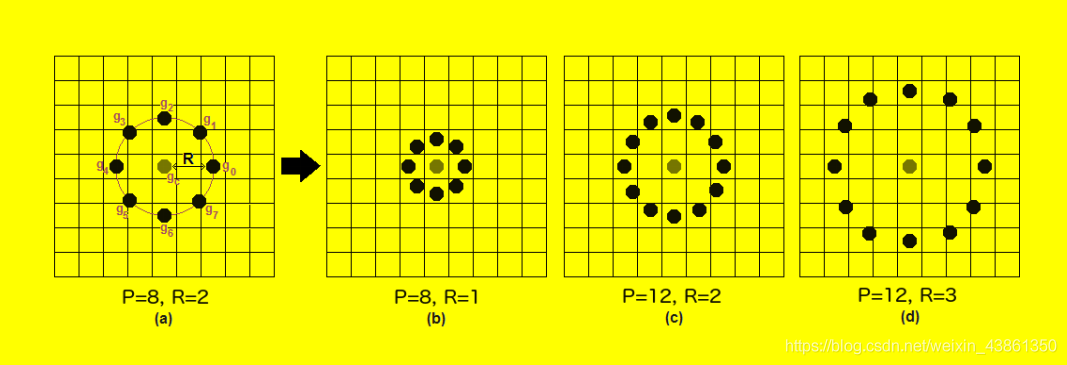
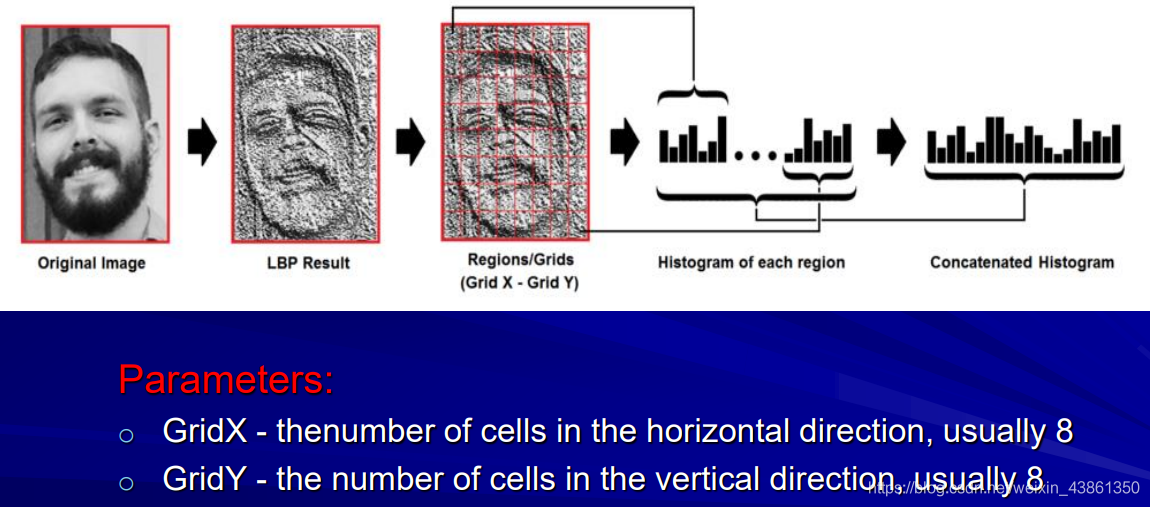
區域二進制模式 (Local Binary Patterns)
人臉歸一化 (Normalization of Faces)
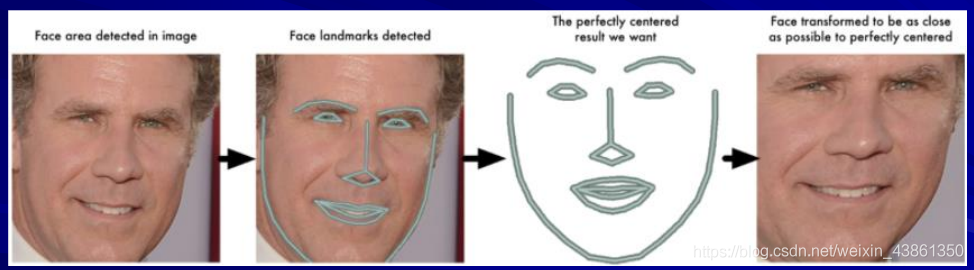
有時我們會遇到臉部并不正對鏡頭,而是面對著其他方向的情況,為了使系統能夠正確識別非正臉面部,我們需要做人臉歸一化,
如何做到:使用臉部地標(face landmarks),

結合仿射變換 Affine Transformation (平移,旋轉,縮放和剪切),使外眼角 (outer eye corners) 和鼻子對齊,將識別到的臉部地標轉化為正對著鏡頭的版本,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232631.html
標籤:AI
上一篇:前端的自動化重構