
“神仙姐姐”CycleGAN
在“風格遷移四部曲系列”的《風格遷移的“精神始祖”Conditional GAN》文章中,已經跟大伙一起在MNIST手寫資料集上手擼了CGAN,讓GAN學會了“認標簽,寫數字”,然后,我們將CGAN“擬合條件概率分布”的思想發揚光大,在文章《用CGAN做影像轉換的鼻祖pix2pix》中,讓GAN學會了“看圖學畫風”,并用學會的圖片風格渲染新圖片,到這里GAN是不是已經有了點藝術家的氣質了~
但是,前面介紹的兩個GAN只能算是“阿朱、阿碧”那樣的小丫鬟,本專案介紹的CycleGAN才是真正的大小姐“王姑娘”,既然Pix2Pix也能干風格遷移的活兒,為什么就和CycleGAN丫鬟小姐不同命呢?打個比方,非是兩個丫頭不夠聰明(Pix2Pix效果不夠好),而是她們不認識字(適用范圍窄),武功秘籍都得大俠念給她們聽才能記得(得讓訓練集的兩組圖片一一對應才能訓練),王姑娘則從小接受書香門第的全面素質教育(CycleGAN經朱俊彥大神悉心改造),自家的武功秘籍還能可勁兒看(網上的圖片按域特征分成兩組就能喂給CycleGAN),自然識得天下武功(CycleGAN應用發揚光大),再說,Pix2Pix效果再驚艷,也不能老蹭人家分割任務的資料集用吧,比如,下面這個將照片轉變為大師畫作的任務中,只要備好了一組照片和一組大師的作品作為資料集,CycleGAN就能輕松搞定:

而Pix2Pix要求“訓練的兩組圖片要一一對應”,照片是什么內容畫作也得是同一內容,結果就悲催了,總不能讓大師照著照片給模型畫訓練集吧~
試想一下,用CycleGAN做一個游戲貼圖的渲染器,把生化危機的場景貼圖都換成自己學校風格的建筑,把“群眾演員”的貼圖換成藍精靈...哈哈哈...
喜歡這個主意,就趕快抄起Paddle一起GAN吧~
CycleGAN的介紹
1.CycleGAN的原理
CycleGAN,即回圈生成對抗網路,出自發表于 ICCV17 的論文《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,和它的兄長Pix2Pix(均為朱大神作品)一樣,用于影像風格遷移任務,以前的GAN都是單向生成,CycleGAN為了突破Pix2Pix對資料集圖片一一對應的限制,采用了雙向回圈生成的結構,因此得名CycleGAN,
首先,CycleGAN也是一個GAN模型,通過判別器和生成器的對抗訓練,學習資料集圖片的像素概率分布來生成圖片,原理已經在前面的文章《通俗理解經典GAN》中詳細介紹過了,
要完成X域到Y域的圖片風格遷移,就要求GAN網路既要擬合Y域圖片的風格分布分布,又要保持X域圖片對應的內容特征,打個比方,用草圖風格的貓圖片生成照片風格的貓圖片時,要求生成的貓咪“即要活靈活現,又要姿勢不變”,“擬合資料分布”本來就是GAN干的活兒,而“保持原圖片特征”在Pix2Pix上是這么實作的(詳解可參考《用CGAN做影像轉換的鼻祖pix2pix》):
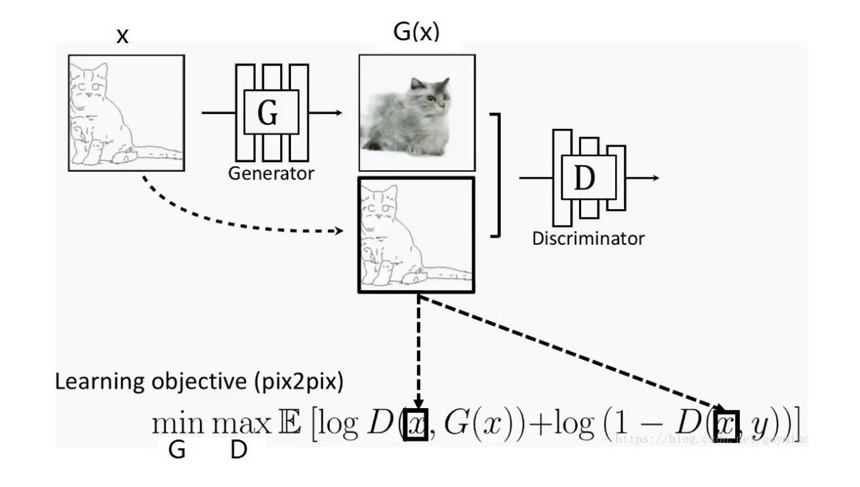
因為Pix2Pix是一個CGAN,所以,我們通過用X域圖片當約束條件來限制Pix2Pix的輸出Y域風格圖片時保有X域圖片的特征,
而送入CycleGAN的兩組(X域Y域)圖片沒有一一對應關系,即使我們將X域圖片當成限制條件輸入到一個CGAN中,也起不到限制模型輸出保有X域圖片特征的作用,因為,送入的兩組圖片完全是隨機配在一起,CGAN學不到任何聯系,因此,CycleGAN采取了一個絕妙的設計:通過添加“回圈生成”并優化一致性損失(Consistency Loss)來代替CGAN中使用的約束條件來限制生成器保有原域圖片特征,這樣就不需要訓練集圖片一一對應了,
2.CycleGAN的流程
下面,我們就來看看回圈生成網路(CycleGAN)到底是怎么“回圈起來”的:
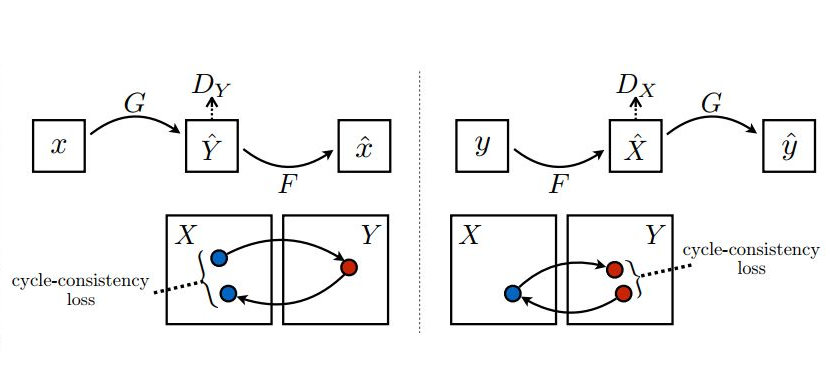
上圖左半部分,將原域圖片x送入(x2y方向)生成器G生成目標域圖片y^,然后再將生成的目標域圖片y^送入(y2x方向)生成器F反過來生成原域圖片x^,生成x^的目的就是用它與輸入的真圖片x來算L1 Loss,我們知道Pix2Pix優化時除了使用GAN Loss(對抗損失)外,還加入了生成器輸入圖片和輸出圖片的L1 Loss來對齊生成圖片與輸入圖片的宏觀輪廓(所謂低頻資訊),同樣的邏輯,我們也能在CycleGAN中用L1 Loss來對齊“回圈生成”的x^與輸入的原圖片x的內容自然,x生成的y^的輪廓也是和x對齊的了,這就達到了(原論文中的例子)“馬變斑馬,花紋變,姿勢不變”的目的了,(我在網上看到的CycleGAN資料都沒有點明這一點的,所以只好自行腦補,歡迎指正,)
在這個x->y^->x^的生成程序中,可以通過判別器Dy與生成器(x2y)G進行對抗訓練,那么這個鏈條上的反向生成器(y2x)F怎么辦?當然是加個判別器Dx與它進行對抗訓練了,這樣CycleGAN就有了兩個方向相反的生成器,兩個分別判別x域、y域圖片的判別器,但要注意一個問題:就像GAN的生成器和判別器不能同時訓練一樣,Cyc1eGAN的兩個生成器、兩個判別器也只能一個一個訓練,這就形成了CycleGAN訓練的兩條“環路”,
第一條就是剛才分析的上圖左半部份的程序,在這個程序中先訓練判別器Dy,再訓練生成器G,判別器Dx和生成器F在上圖右半部份的程序再訓練,如此回圈往復進行訓練,生成的圖片是這樣的:

上圖就是本專案訓練的CycleGAN的部分訓練輸出,這是一個在selfie2anime資料集上訓練的,將妹子照片轉換成二次元風格圖片CycleGAN,
3.CycleGAN的結構
接下來,我們再看看這兩對判別器、生成器怎么擺:
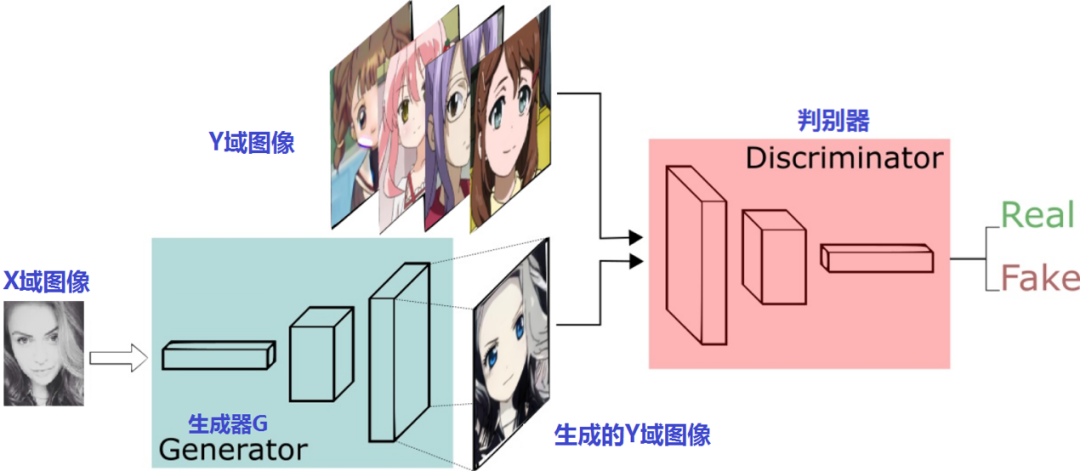
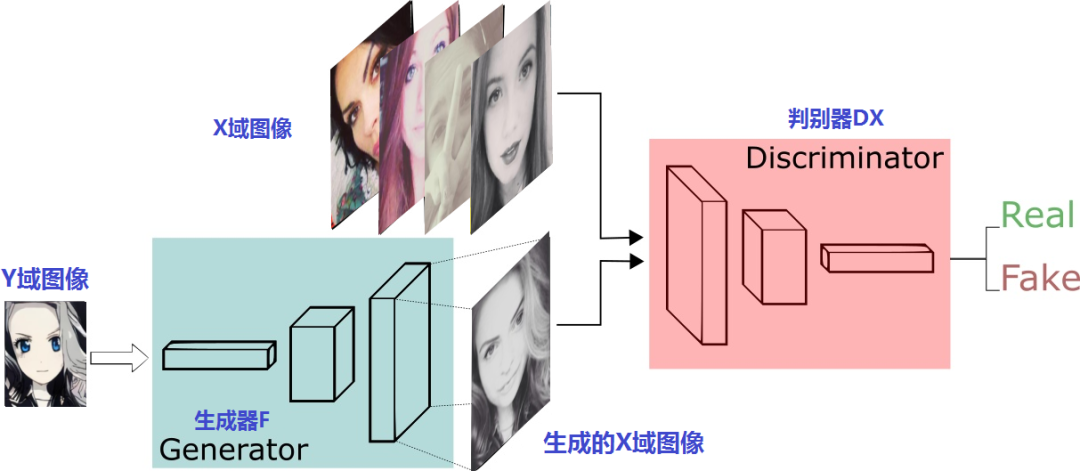
上半部份是生成器G和判別器Dy進行x2y的訓練程序,下半部份是生成器F和判別器Dx進行y2x的訓練程序,很像是兩個風格遷移方向相反Pix2Pix模型,只是這兩個GAN是普通GAN,不是Pix2Pix那樣的CGAN,這一點,從生成器和判別器的輸入就可以看出來,輸入的只有原域圖片并沒有像Pix2Pix一樣融合條件圖片,
4.CycleGAN的loss函式
前面分析了CycleGAN的原理,我們已經知道了CycleGAN的loss由對抗損失(稱為gan loss或adversarial loss)和回圈一致性損失(consitency loss)組成,下面看看公式:
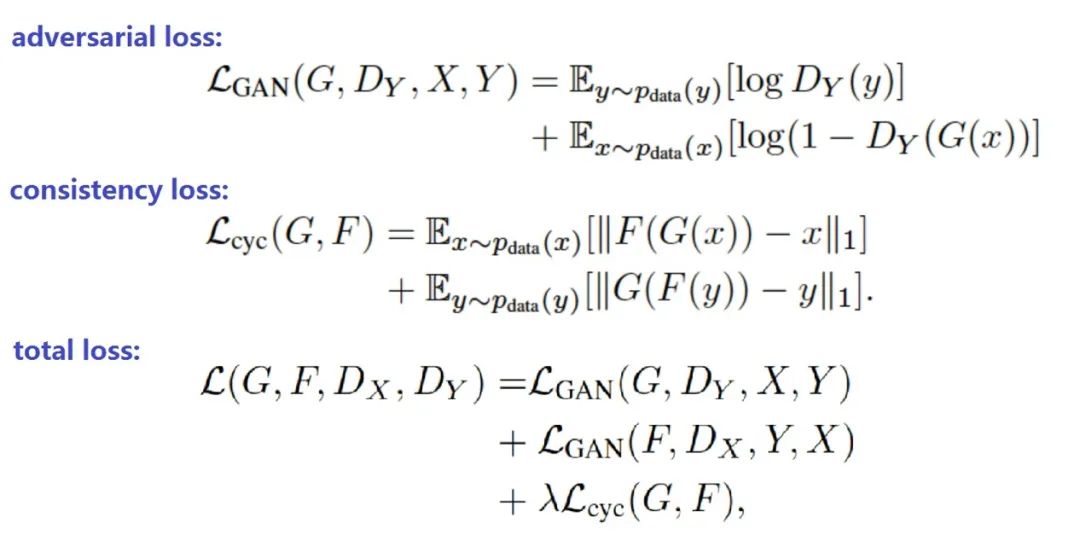
上面公式中:
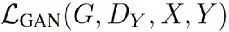 指的是x2y程序的對抗損失(adversarial loss)
指的是x2y程序的對抗損失(adversarial loss)
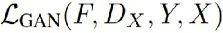 指的是y2x程序的對抗損失(adversarial loss)
指的是y2x程序的對抗損失(adversarial loss)
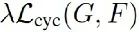 指的是生成器G和生成器F的回圈一致性損失,
指的是生成器G和生成器F的回圈一致性損失,
其中為回圈一致性損失(consitency loss)的縮放系數,是一個超引數,
實際上,原論文的代碼還加入了本體映射損失(identity loss),只是默認設定為關閉,CycleGAN正常訓練時,生成器G輸入x,生成y^,計算生成器G的本體映射損失(identity loss)時,生成器G輸入y,生成y^,然后用y與y^的L1 loss作為G的identity loss,相應地,生成器F的identity loss則是輸入的x與生成的x^的L1 loss,優化CycleGAN時,如果啟用identity loss則將這兩部分加到模型總loss中,與回圈一致性損失(consistency loss)一樣,也使用縮放系數超參控制其在總loss中所占比重,
論文中提到,CycleGAN使用identity loss的目的是在遷移的程序中保持原色調,下面是使用identity loss的對比效果:

上面圖片最右邊一列使用identity loss后果然糾正了生成器的色偏,
CycleGAN的實作
下面,我們就來用Paddle的動態圖模式,實作這個將妹子照片轉化為二次元風格的“討喜神器”(單方精妙、小心煉制、謹慎使用~),
1.資料集準備
將selfie2anime資料集解壓到/home/aistudio/data/data50363/路徑下,trainA檔案夾下存盤照片風格訓練集圖片,trainB檔案夾下存盤卡通風格訓練集圖片,testA和testB分別存盤照片風格和卡通風格的測驗集圖片,資料集的讀取器和上個文章《用CGAN做影像轉換的鼻祖pix2pix》一樣使用Paddle套件代碼庫里的腳本,與其不同的是,得益于CycleGAN的訓練資料適應能力,我們無需每次送入模型一對對應的圖片,只需送入兩個單獨的讀取器從兩組圖片中各自shuffle后輸出的任意兩張圖片,這樣,還能通過打亂順序增加模型的泛化能力,
此外,為了實作模型的更佳效果,還使用了明暗、對比度、飽和度、拉伸、旋轉等資料增強效果,具體的使用原因我們在最后的對比分析中再詳細解釋,
# 解壓資料集,首次運行后注釋
# !unzip -qa -d /home/aistudio/data/data50363/ /home/aistudio/data/data50363/selfie2anime_textlist.zip
import paddle.fluid as fluid
import data_reader_epoch as data_reader
import paddle
import matplotlib.pylab as plt
%matplotlib inline
import numpy as np
def show_pics(pics, heatmap=np.zeros((1, 1))):
plt.figure(figsize=(3 * len(pics), 3), dpi=80)
for i in range(len(pics)):
pics[i] = (pics[i][0].transpose((1,2,0)) + 1) / 2
plt.subplot(1, len(pics), i + 1)
plt.imshow(pics[i])
plt.xticks([])
plt.yticks([])
def open_pic(file_name='./data/data50363/testA/female_11846.jpg'):
img = Image.open(file_name).resize((256, 256), Image.BILINEAR)
img = (np.array(img).astype('float32') / 255.0 - 0.5) / 0.5
img = img.transpose((2, 0, 1))
img = img.reshape((-1, img.shape[0], img.shape[1], img.shape[2]))
return img
class CFG:
def __init__(self):
self.batch_size = 1
self.image_size = 256
self.crop_size = 244
self.crop_type = 'Random'
self.use_gpu = True
self.shuffle = True
self.dataset = '/home/aistudio/data/data50363/'
self.model_net = 'CycleGAN'
self.data_dir = './data'
self.run_test = True
cfg = CFG()
reader = data_reader.data_reader(cfg)
A_reader, B_reader, a_reader_test, b_reader_test, batch_num, a_id2name, b_id2name = reader.make_data()
data_a = next(A_reader())
data_b = next(B_reader())
data_a = data_a[0]
data_b = data_b[0]
show_pics([data_a, data_b])

上面的代碼列印了reader輸出的兩張圖片,左邊的是A組照片風格的圖片,右邊的是B組卡通風格的圖片,訓練集的讀取器會執行shuffle,所以每次執行輸出的圖片會不同,也不會有固定的匹配關系,
2.輔助函式
下面的代碼保存訓練程序中列印的圖片,幫助我們觀察模型的訓練情況,訓練時保存的圖片存在./output/pics/檔案夾下,測驗時保存的圖片存在./output/pics_test/檔案夾下,檔案名為訓練的迭代次數,保存圖片的頻率隨輪數降低,因為訓練前期輸出的圖片變化較大,
from PIL import Image
def save_pics(pics, file_name='tmp', save_path='./output/pics/'):
for i in range(len(pics)):
pics[i] = pics[i][0]
pic = np.concatenate(tuple(pics), axis=2)
pic = pic.transpose((1,2,0))
pic = (pic + 1) / 2
pic = np.clip(pic * 256, 0, 255)
img = Image.fromarray(pic.astype('uint8')).convert('RGB')
img.save(save_path+file_name+'.jpg')
# save_pics([data_a, data_b])
3.判別器和生成器
CycleGAN有兩個結構一樣的判別器和兩個結構一樣的生成器,所以我們只需要定義一個判別器和一個生成器,后面train程序使用時實體化成不同物件就可以了,
CycleGAN和上個Pix2Pix專案一樣,使用的PatchGAN判別器和ResNet的殘差塊兒組成的生成器,
由于CycleGAN的判別器和生成器使用的是普通GAN,而非像Pix2Pix一樣的CGAN,它的判別器和生成器輸入的圖片資料的維度不同,不需要拼接用作“限制條件”的圖片,
import paddle.fluid as fluid
from paddle.fluid.dygraph import Conv2D, Linear, Dropout, BatchNorm, Pool2D, Conv2DTranspose, InstanceNorm, SpectralNorm
import numpy as np
class Disc(fluid.dygraph.Layer):
def __init__(self):
super(Disc, self).__init__()
# self.conv1 = Conv2D(6, 64, 4, stride=2, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.conv1 = Conv2D(3, 64, 4, stride=2, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in1 = InstanceNorm(64)
self.conv2 = Conv2D(64, 128, 4, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in2 = InstanceNorm(128)
self.conv3 = Conv2D(128, 256, 4, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in3 = InstanceNorm(256)
self.conv4 = Conv2D(256, 512, 4, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in4 = InstanceNorm(512)
self.conv5 = Conv2D(512, 1, 4, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
def forward(self, x):
x = self.conv1(x)
x = self.in1(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv2(x)
x = self.in2(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv3(x)
x = self.in3(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv4(x)
x = self.in4(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv5(x)
return x
# 定義生成器使用的殘差塊
class Residual(fluid.dygraph.Layer):
def __init__(self, input_output_dim, use_bias):
super(Residual, self).__init__()
name_scope = self.full_name()
self.conv1 = Conv2D(input_output_dim, input_output_dim, 3, bias_attr=use_bias, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn1 = BatchNorm(input_output_dim)
self.conv2 = Conv2D(input_output_dim, input_output_dim, 3, bias_attr=use_bias, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn2 = BatchNorm(input_output_dim)
def forward(self, x_input):
x = fluid.layers.pad2d(x_input, [1, 1, 1, 1], mode='reflect')
x = self.conv1(x)
x = self.bn1(x)
x = fluid.layers.relu(x)
x = fluid.layers.pad2d(x, [1, 1, 1, 1], mode='reflect')
x = self.conv2(x)
x = self.bn2(x)
return x + x_input
# 定義ResNet版的生成器
class Gen(fluid.dygraph.Layer):
def __init__(self, base_dim=64, residual_num=7):
super(Gen, self).__init__()
self.residual_num = residual_num
self.conv1 = Conv2D(3, base_dim, 7, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn1 = BatchNorm(base_dim)
self.conv2 = Conv2D(base_dim, base_dim * 2, 3, padding=1, stride=2, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn2 = BatchNorm(base_dim * 2)
self.conv3 = Conv2D(base_dim * 2, base_dim * 4, 3, padding=1, stride=2, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn3 = BatchNorm(base_dim * 4)
self.residual_list = []
for i in range(residual_num):
layer = self.add_sublayer('res_'+str(i), Residual(base_dim * 4, False))
self.residual_list.append(layer)
self.convTrans1 = Conv2DTranspose(base_dim * 4, base_dim * 2, 3, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn4 = BatchNorm(base_dim * 2)
self.convTrans2 = Conv2DTranspose(base_dim * 2, base_dim, 3, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn5 = BatchNorm(base_dim)
self.conv4 = Conv2D(base_dim, 3, 7, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
def forward(self, x):
x = fluid.layers.pad2d(x, [3, 3, 3, 3], mode='reflect')
x = self.conv1(x)
x = self.bn1(x)
x = fluid.layers.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = fluid.layers.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x = fluid.layers.relu(x)
for res_layer in self.residual_list:
x = res_layer(x)
x = self.convTrans1(x)
x = self.bn4(x)
x = fluid.layers.relu(x)
x = fluid.layers.pad2d(x, [0, 1, 0, 1], mode='constant', pad_value=0.0)
x = self.convTrans2(x)
x = self.bn5(x)
x = fluid.layers.relu(x)
x = fluid.layers.pad2d(x, [0, 1, 0, 1], mode='constant', pad_value=0.0)
x = fluid.layers.pad2d(x, [3, 3, 3, 3], mode='reflect')
x = self.conv4(x)
x = fluid.layers.tanh(x)
return x4.訓練程序
下面代碼中的ImagePool類是用來快取圖片的佇列的物件,使用這個佇列是CycleGAN論文中用的一個trick,通過使用快取在佇列里的生成器輸出的圖片來訓練判別器,可以保持判別器的穩定性,快取佇列的容量是50,也即隨機使用前50次迭代成的圖片訓練判別器,
train()函式執行訓練和驗證,代碼的各個部分已經注釋,而且和上個Pix2Pix專案大致相同,先訓練判別器DA、DB,再訓練生成器GA、GB,對抗損失和Pix2Pix一樣使用最小二乘損失,
需要關注一下的是“回圈一致性損失”的權重cycle_weight設為30,“本體損失”的權重identity_weight設為10,都是作為train()函式的默認引數值進行設定的,這個權重是經過一些試驗選取的,
import paddle.fluid as fluid
import time
from PIL import Image, ImageEnhance
class ImagePool(object):
def __init__(self, pool_size=50):
self.pool = []
self.count = 0
self.pool_size = pool_size
def pool_image(self, image):
image = image.numpy()
rtn = ''
if self.count < self.pool_size:
self.pool.append(image)
self.count += 1
rtn = image
else:
p = np.random.rand()
if p > 0.5:
random_id = np.random.randint(0, self.pool_size - 1)
temp = self.pool[random_id]
self.pool[random_id] = image
rtn = temp
else:
rtn = image
return fluid.dygraph.to_variable(rtn)
def train(epoch_num=99999, adv_weight=1, cycle_weight=30, identity_weight=10, \
use_gpu=True, load_model=False, model_path='./model/', model_path_bkp='./model_bkp/', \
print_interval=1, max_step=50, model_bkp_interval=5000):
place = fluid.CUDAPlace(0) if use_gpu == True else fluid.CPUPlace()
with fluid.dygraph.guard(place):
# model
g_a = Gen()
g_b = Gen()
d_a = Disc()
d_b = Disc()
# data
reader_a, reader_b, _, _, _, _, _ = reader.make_data()
# optimizer
g_a_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=g_a.parameters())
g_b_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=g_b.parameters())
d_a_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=d_a.parameters())
d_b_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=d_b.parameters())
# image pool
fa_pool, fb_pool = ImagePool(), ImagePool()
total_step_num = np.array([0])
if load_model == True:
ga_para, ga_opt = fluid.load_dygraph(model_path+'gen_b2a')
gb_para, gb_opt = fluid.load_dygraph(model_path+'gen_a2b')
da_para, da_opt = fluid.load_dygraph(model_path+'dis_ga')
db_para, db_opt = fluid.load_dygraph(model_path+'dis_gb')
g_a.load_dict(ga_para)
g_a_optimizer.set_dict(ga_opt)
g_b.load_dict(gb_para)
g_b_optimizer.set_dict(gb_opt)
d_a.load_dict(da_para)
d_a_optimizer.set_dict(da_opt)
d_b.load_dict(db_para)
d_b_optimizer.set_dict(db_opt)
total_step_num = np.load('./model/total_step_num.npy')
step = total_step_num[0]
print('Start time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'start step:', step + 1)
for epoch in range(epoch_num):
for data_a, data_b in zip(reader_a(), reader_b()):
step += 1
# data
data_a, data_b = np.array(data_a[0]), np.array(data_b[0])
# data_a[0] = prepare_a(data_a[0]) # A augment
img_ra = fluid.dygraph.to_variable(data_a)
img_rb = fluid.dygraph.to_variable(data_b)
# train DA
d_loss_ra = fluid.layers.reduce_mean((d_a(img_ra.detach()) - 1) ** 2)
d_loss_fa = fluid.layers.reduce_mean(d_a(fa_pool.pool_image(g_a(img_rb.detach()))) ** 2)
da_loss = (d_loss_ra + d_loss_fa) * 0.5
da_loss.backward()
d_a_optimizer.minimize(da_loss)
d_a.clear_gradients()
# train DB
d_loss_rb = fluid.layers.reduce_mean((d_b(img_rb.detach()) - 1) ** 2)
d_loss_fb = fluid.layers.reduce_mean(d_b(fb_pool.pool_image(g_b(img_ra.detach()))) ** 2)
db_loss = (d_loss_rb + d_loss_fb) * 0.5
db_loss.backward()
d_b_optimizer.minimize(db_loss)
d_b.clear_gradients()
# train GA
ga_gan_loss = fluid.layers.reduce_mean((d_a(g_a(img_rb.detach())) - 1) ** 2)
ga_cyc_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_rb.detach() - g_b(g_a(img_rb.detach()))))
ga_ide_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_ra.detach() - g_a(img_ra.detach())))
ga_loss = ga_gan_loss * adv_weight + ga_cyc_loss * cycle_weight + ga_ide_loss * identity_weight
ga_loss.backward()
g_a_optimizer.minimize(ga_loss)
g_a.clear_gradients()
# train GB
gb_gan_loss = fluid.layers.reduce_mean((d_b(g_b(img_ra.detach())) - 1) ** 2)
gb_cyc_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_ra.detach() - g_a(g_b(img_ra.detach()))))
gb_ide_loss = fluid.layers.reduce_mean(fluid.layers.abs(img_rb.detach() - g_b(img_rb.detach())))
gb_loss = gb_gan_loss * adv_weight + gb_cyc_loss * cycle_weight + gb_ide_loss * identity_weight
gb_loss.backward()
g_b_optimizer.minimize(gb_loss)
g_b.clear_gradients()
# save pictures
if step in range(1, 101):
pic_save_interval = 1
elif step in range(101, 1001):
pic_save_interval = 10
elif step in range(1001, 10001):
pic_save_interval = 100
else:
pic_save_interval = 500
if step % pic_save_interval == 0:
save_pics([img_ra.numpy(), g_b(img_ra).numpy(), g_a(g_b(img_ra)).numpy(), g_b(img_rb).numpy(), \
img_rb.numpy(), g_a(img_rb).numpy(), g_b(g_a(img_rb)).numpy(), g_a(img_ra).numpy()], \
str(step))
test_pic = open_pic()
test_pic_pp = fluid.dygraph.to_variable(test_pic)
save_pics([test_pic, g_b(test_pic_pp).numpy()], str(step), save_path='./output/pics_test/')
# print losses & pictures
if step % print_interval == 0:
print([step], \
'DA:', da_loss.numpy(), \
'DB:', db_loss.numpy(), \
'GA:', ga_loss.numpy(), \
'GB:', gb_loss.numpy(), \
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
show_pics([img_ra.numpy(), g_b(img_ra).numpy(), g_a(g_b(img_ra)).numpy(), g_b(img_rb).numpy()])
show_pics([img_rb.numpy(), g_a(img_rb).numpy(), g_b(g_a(img_rb)).numpy(), g_a(img_ra).numpy()])
# save models regularly
if step % model_bkp_interval == 0:
fluid.save_dygraph(g_a.state_dict(), model_path_bkp+'gen_b2a')
fluid.save_dygraph(g_a_optimizer.state_dict(), model_path_bkp+'gen_b2a')
fluid.save_dygraph(g_b.state_dict(), model_path_bkp+'gen_a2b')
fluid.save_dygraph(g_b_optimizer.state_dict(), model_path_bkp+'gen_a2b')
fluid.save_dygraph(d_a.state_dict(), model_path_bkp+'dis_ga')
fluid.save_dygraph(d_a_optimizer.state_dict(), model_path_bkp+'dis_ga')
fluid.save_dygraph(d_b.state_dict(), model_path_bkp+'dis_gb')
fluid.save_dygraph(d_b_optimizer.state_dict(), model_path_bkp+'dis_gb')
np.save(model_path_bkp+'total_step_num', np.array([step]))
# end train
if step >= max_step + total_step_num[0]:
fluid.save_dygraph(g_a.state_dict(), model_path+'gen_b2a')
fluid.save_dygraph(g_a_optimizer.state_dict(), model_path+'gen_b2a')
fluid.save_dygraph(g_b.state_dict(), model_path+'gen_a2b')
fluid.save_dygraph(g_b_optimizer.state_dict(), model_path+'gen_a2b')
fluid.save_dygraph(d_a.state_dict(), model_path+'dis_ga')
fluid.save_dygraph(d_a_optimizer.state_dict(), model_path+'dis_ga')
fluid.save_dygraph(d_b.state_dict(), model_path+'dis_gb')
fluid.save_dygraph(d_b_optimizer.state_dict(), model_path+'dis_gb')
np.save(model_path+'total_step_num', np.array([step]))
print('End time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'End Step:', step)
return
# 重新訓練
# train(print_interval=1, max_step=1, model_bkp_interval = 2000)
# 繼續訓練
train(load_model=True, print_interval=1, max_step=3, model_bkp_interval = 2000)
Start time : 2020-11-11 21:22:00 start step: 200107
[200107] DA: [0.05124042] DB: [0.04026642] GA: [4.1400466] GB: [3.8985167] 2020-11-11 21:22:01
[200108] DA: [0.01048683] DB: [0.01179506] GA: [9.123032] GB: [4.7860665] 2020-11-11 21:22:01
[200109] DA: [0.00659171] DB: [0.01218848] GA: [12.422014] GB: [13.788451] 2020-11-11 21:22:02
End time : 2020-11-11 21:22:07 End Step: 200109






5.預測程序
使用訓練好的模型在測驗集圖片上運行測驗,評估訓練效果,
import paddle.fluid as fluid
def infer(max_step=10, use_gpu=True, load_model=True, model_path='./model/'):
place = fluid.CUDAPlace(0) if use_gpu == True else fluid.CPUPlace()
with fluid.dygraph.guard(place):
# model
g_b = Gen()
# data
reader_a, reader_b, a_reader_test, _, _, _, _ = reader.make_data()
if load_model == True:
gb_para, gb_opt = fluid.load_dygraph(model_path+'gen_a2b')
g_b.load_dict(gb_para)
step = 0
for data_a in a_reader_test():
step += 1
data_a = np.array(data_a[0])
img_ra = fluid.dygraph.to_variable(data_a)
img_b = g_b(img_ra).numpy() * .9
show_pics([data_a, img_b])
print('(', step, '/', max_step, ')')
if step >= max_step:
return
# infer(max_step=10, use_gpu=False)
infer(max_step=10)
( 1 / 10 )
( 2 / 10 )
( 3 / 10 )
( 4 / 10 )
( 5 / 10 )
( 6 / 10 )
( 7 / 10 )
( 8 / 10 )
( 9 / 10 )
( 10 / 10 )








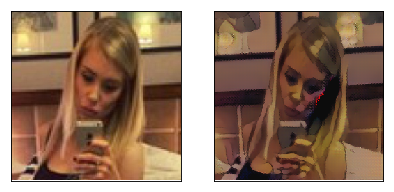
總結
上面運行的效果看上去還不錯吧~實際上,第一次訓練CycleGAN時我用的原論文中“馬變斑馬”資料集上用的引數,訓練一二百萬輪后有些“極端”的畫風是這樣的:



我的天啊!怎么妹子變成了格格巫~
上面的圖片每次迭代輸出一行,左一是A域圖片,左二是A2B圖片,左三是A2B2A的圖片,左四是用B2B(用GB生成器)的圖片,右邊的四張則是B域遷移的A域的相應圖片,這些訓練圖片我已經存到了./output/pics_w10檔案夾下,歡迎同學觀摩各種妖魔鬼怪~(由于版本檔案數的限制圖片沒有復制到新版本中,但模型已經保存到了./model_cycleweight10檔案夾下,大家可以用這個存模型自己生成下)
在./output/pics_test_w10檔案夾下則存盤了每次迭代時用同一張測驗集圖片測驗的結果:


效果似憾訓湊合,但仔細觀察會發現,生成的二次元妹子的左邊嘴角總有一道斜線不知哪里來的,原圖那個位置既沒有線條,也沒有明顯的明暗變化,我嘗試分析原因(雖然咱管這叫煉丹,但還是總忍不住要分析分析~)...后來在一些圖片上找到了線索,比如上面訓練集圖片的第三行的左二A2B圖片看上去,生成的二次元效果還行,但再看左三A2B2A圖片就會發現:經過CycleGAN的回圈生成,妹子的嘴巴這是腫么了~
我推測,這是GAN網路對兩圖圖片進行遷移時五官定位錯誤造成的,第三行訓練集照片上妹子的嘴實際上對應生成了二次元圖片的下巴,從照片上妹子的臉部的比例和生成的二次元臉部長寬比例就能看得出來,這可能是訓練集照片人臉五官的分布比例和卡通五官分布沒有正確對應造成的,從測驗集生成的妹子二次元圖片上左嘴角邊的斜線也能印證:測驗照片上妹子臉比較長,穿越成二次元時發生了五官定位錯誤,左嘴角又生成了一個下巴(狐貍)~
為了解決這個問題,我使用了,拉伸、旋轉等影像增強方法,使模型遷移風格時五官能正確對應,并且,我還將回圈一致性損失在loss中的權重cycle_weight從10調整為30,使風格遷移的程序中更多保持一些原有特征,防止生成妖魔鬼怪~,調整后的模型就是我們專案中訓練的版本,我們看下測驗集那張妹子照片還有沒有“雙下巴”~



安全上壘!二次元妹子成功瘦身,減掉了“雙下巴”,
除了這種資料增強的小trick外,后來的大佬們對GycleGAN的應用也做了很多改進,比如,為了用GTA游戲場景生成街景圖片,用于擴展訓練集,論文CYCADA提出了自己的Semantic Consistency Loss,取得了很好的效果,論文UGATIT則提出了使用“熱圖引導注意力機制”和“AdaLIN歸一化”方法增強了CycleGAN頭像風格遷移任務的效果,
現在有了PaddleGAN這個“神器”,GAN的活再也不用自己干~
附上煉丹套件地址:
https://github.com/PaddlePaddle/PaddleGAN/blob/master/docs/zh_CN/tutorials/pix2pix_cyclegan.md
學習官方大佬優雅的代碼風格也是能給自己漲點的啊~
如在使用程序中有問題,可加入飛槳官方QQ群進行交流:1108045677,
如果您想詳細了解更多飛槳的相關內容,請參閱以下檔案,
·飛槳PaddleGAN專案地址(歡迎Star)·
GitHub:
https://github.com/PaddlePaddle/PaddleGAN
Gitee:
https://Gitee.com/PaddlePaddle/PaddleGAN
·飛槳官網地址·
https://www.paddlepaddle.org.cn/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232632.html
標籤:AI
上一篇:計算機視覺理論筆記 (12) - 影像分類和面部識別 (Image Classification & Face Recognition)