萬物皆可Embedding系列會結合論文和實踐經驗進行介紹,前期主要集中在論文中,后期會加入實踐經驗和案例,目前已更新:
- 萬物皆可Vector之語言模型:從N-Gram到NNLM、RNNLM
- 萬物皆可Vector之Word2vec:2個模型、2個優化及實戰使用
- Item2vec中值得細細品味的8個經典tricks和thinks
后續會持續更新Embedding相關的文章,歡迎持續關注「搜索與推薦Wiki」
Item2vec:論文《Item2Vec:Neural Item Embedding for Collaborative Filtering》
來自于微軟2016年發表在RecSys上的,因為word2vec和item2vec是在做推薦系統程序中比較常用的兩個演算法,所以該部分先介紹item2vec,然后再展開其他xxx2vec,
Item2vec其本質就是Word2vec中的skip-gram+Negative sampling(簡稱為SGNS),關于什么是SGNS可以參考之前介紹的word2vec篇幅的內容,
下面陳列一些從論文中可以學習到的經典的tricks
1、為什么選擇的是SGNS而不是其它的組合
Item2vec為什么采用Skp-Gram + Negative Sampling這種組合呢?因為效果好,而在很多文章中也提到了SGNS這種組合下的實際業務提升要好一些(但并不能一刀切,只是說大多數業務場景下SGNS的效果好,但還是要視具體的情況而定)
2、實驗場景的選擇
對于這種item相似的演算法,如何選擇合適的實驗場景呢?Item2vec論文中提到的是使用Windows10 App Store的「看了又看」推薦場景,即某個App的相似App推薦場景,這種場景下,對Item相似類演算法進行是很合適的,
但是比如把item sim items加入到典型的「recall -> rank」場景中,其實達到的效果并沒有那么好,但不能說不合適,這取決于截斷的數目,即每個item取多少相似的item,因為在召回中并不會區分 item之間的順序,比如top100,把100個item全部加到召回池中,并不會區分這100個item之間的順序,這就會在一定程度上丟失掉這種相似的資訊,極端情況下,假設我們的item總數為1000個,而召回時將item的相似item1000全部加入到召回池中,這種極端情況下就失去了個性化的意義,
因此選擇一個合適的業務實驗場景去評估我們的演算法是極其重要的,否則得出的結論也沒有什么說服力!
3、負采樣不代表是均勻的隨機負采樣
均勻的隨機負采樣就代表采樣時對所有的負樣本采樣的概率是一樣的,但其實這是不符合實際的資料分布概率的,
因此論文中也使用到了一種非均勻的隨機負采樣技術,其運算式為:
p
(
d
i
s
c
a
r
d
|
w
)
=
1
?
ρ
f
(
w
)
p(discard | w) = 1- \sqrt { \frac{\rho}{f(w)}}
p(discard|w)=1?f(w)ρ?
?
其中:
- f ( w ) f(w) f(w) 表示的是 i t e m ? w item \,w itemw的頻次
- ρ \rho ρ 表示是人為設定的引數,是一個經驗值(論文中針對App Store資料集的設定值是 1 0 ? 3 10^{-3} 10?3,音樂資料集設定值是 1 0 ? 5 10^{-5} 10?5)
4、Item2vec基于SGNS的改進點
其改進點為修改window size為set的長度,即從原來的定長變成了變長,其它的保持不變,
Item2vec丟失了集合中的時間和空間資訊,
5、Item2vec的等效表達方法
論文中特意指出采用保持word2vec的SGNS不變,僅將set集合中的item進行隨機的排序可以達到和Item2vec同樣的效果,相關的實驗也對此進行了佐證,
因此在很大程度上方面了 Item2vec的等效表達,即采樣Word2vec的演算法代碼同意可以得到Item2vec中的Item的embedding表示,
6、基于Item Embedding計算相似性的實驗思路
a)聚類資料可視化
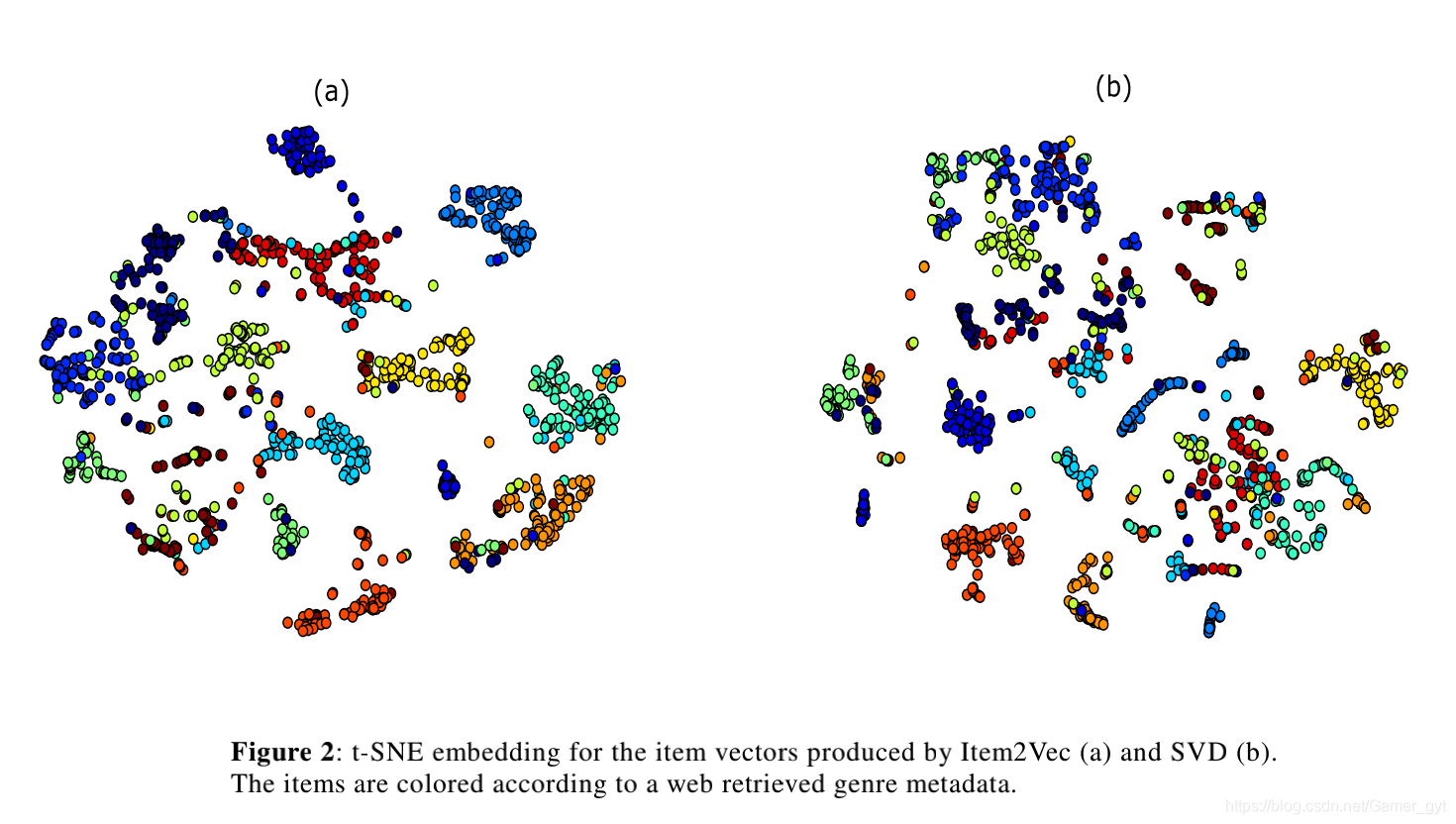
依據embedding進行item聚類,并在二維空間中進行資料展示,觀察效果,比如論文中使用的t-SNE進行可視化,如下圖所示,(a) 為基于Item2vec產出的item embedding進行的聚類可視化,(b)為基于SVD產出的item vector進行的聚類可視化,肉眼可見(a)要比(b)的效果好很多,
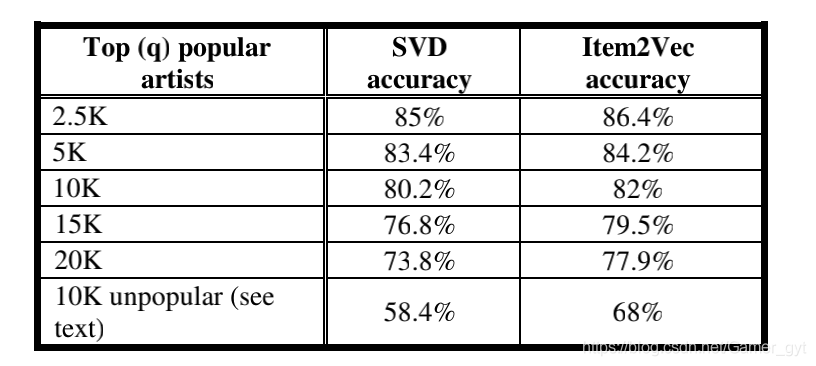
b)top N item的型別一致性檢驗
首先基于KNN選取每個item的相似items,top N個,然后根據型別一致性檢驗統計top N中的一致性占比,繼而進行對比分析,
在進行型別一致性檢驗時,這里選擇了一些比較受歡迎的item,論文中關于「受歡迎」和「不受歡迎」的item定義方法為:如果一個item被用戶互動次數少于15,則被認為是不受歡迎的,
實驗結果如下圖所示:
7、聚類可視化的分析和帶給我的思考(精華)
在上邊提到了使用聚類可視化進行item2vec的效果表達,論文中指出上圖(a)中那些同色的簇類中被其它顏色簇類污染的item中,有很多是標簽打錯或者型別交叉引起的,
那么這里是否可以通過可視化和分析對作品的標簽或者其它屬性進行反饋和修正呢?比如說上標簽打錯的item反饋給運營,讓運營進行評估和修正,然后繼續使用類似的方法進行評估,再反饋修正,以此達到一個良性的回圈,從而解決運營打標簽,人工再校驗的復雜流程和容易出錯的問題,
歡迎留言探討!
8、實驗引數的學習
論文中提到了了Item2vec進行實驗時的引數值,這也為我們在實際業務中進行相關嘗試,提供了初始的、經驗上的模型引數值,
- 迭代次數:20
- 負采樣數:1:15
- embedding維度:App資料集為40,Music資料集為100
- 人工設定值 ρ \rho ρ:App資料集為 1 0 ? 3 10^{-3} 10?3,Music資料集為 1 0 ? 5 10^{-5} 10?5
OK,以上就是從Item2vec論文中學習到的知識,希望對你有幫助!

掃一掃 關注微信公眾號!號主 專注于搜索和推薦系統,嘗試使用演算法去更好的服務于用戶,包括但不局限于機器學習,深度學習,強化學習,自然語言理解,知識圖譜,還不定時分享技術,資料,思考等文章!
 CSDN認證博客專家
圖書作者
推薦系統研究者
CSDN認證博客專家
圖書作者
推薦系統研究者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232633.html
標籤:AI