

從“自由揮灑”到“有的放矢”
1、給GAN加個“按鈕”
上一篇《四天搞懂生成對抗網路(一)——通俗理解經典GAN》中,我們實作了一個生成手寫數字的GAN 網路,并且,為了完成我的執念——“集齊常用CV資料增廣的tricks”(后來發現這個想法太navie了,只要大神們不斷造trick發論文,哪有集齊的一天,集不齊也集~~),而嘗試使用生成的手寫數字樣本來提升分類網路的精度,結果自然是緣木求魚,
因為GAN只是擬合原資料集的像素概率分布,生成的樣本并沒有提供新的資訊以優化模型的分類邊界,我理解,樣本插值還能優化一下分類邊界,原始GAN充其量只能添加一點噪聲,或許能增強一點模型泛化能力吧(真做資料增強還得InforGAN、styleGAN這樣的才好,能通過潛空間插值對影像做高級語意的增強,這是后話,),
原始GAN用起來也不方便,為了分別生成0~9的數字,得將原資料集按標簽分為10組,每組用一個模型訓練,一共需要10個模型,訓練時由于每組的資料量少到原來的十分之一,也會發生因樣本太少導致模型無法擬合的現象,所以,意欲降伏GAN的大神給原始GAN裝了個鈕,讓GAN乖乖要啥給啥,這個帶按鈕的改進版就是CGAN,
2、風格遷移網路的“精神始祖”
這個“加個按鈕”的思想,不但馴服了CGAN,而且啟發了后來的一系列用于風格遷移的GAN,包括Pix2Pix、CycleGAN、StarGAN等,從此,GAN更加的好玩,可以給灰度圖片上色修復、把圖片變成藍圖或反之、讓妹子進入二次元、甚至把照片變成印象派大師的作品(鹿鼎小帥哥就在專案《梵高風格影像生成 一起來玩風格遷移呀!》里展示了一個AI大佬的藝術追求~~),這也是為什么我將CGAN的專案放到風格遷移GAN系列中來,本來,我是因為看了UGATIT介紹的注意力加強版的CycleGAN,喜歡得不得了,所以想寫一個介紹從Pix2Pix到CycleGAN的技能樹解鎖筆記,敬獻給感興趣的小伙伴們,后來,收集整理資料時了解到CycleGAN的“爹滴”Pix2Pix其實也是一種CGAN,于CGAN的思想是一脈相承的,所以為了搞清來龍去脈,我們先從CGAN講起...
《梵高風格影像生成 一起來玩風格遷移呀!》AI Studio專案地址:
https://aistudio.baidu.com/aistudio/projectdetail/597606
CGAN(Conditional GAN)介紹
1、CGAN的原理
CGAN的全稱是Conditional Generative Adversarial Nets,即條件生成對抗網路,故名思議,就是通過添加限制條件,來控制GAN生成資料的特征(類別),
當我第一次了解了CGAN原理,我驚詫于它給GAN“加按鈕”的方法竟然如此簡單粗暴,要做僅僅就是“把按鈕加上去”——訓練時將控制生成類別的標簽連同噪聲一起送進生成器的輸入端,這樣在預測時,生成器就會同樣根據輸入的標簽生成指定類別的圖片了,判別器的處理也是一樣,僅僅在輸入加上類別標簽就可以了,
那么,為什么加了標簽,CGAN就乖乖聽話、要啥給啥了呢?原理也是十分簡單,我們知道GAN要干的就是擬合資料的概率分布,而CGAN擬合的就是條件下的概率分布,
看看原始GAN和CGAN的公式對比:
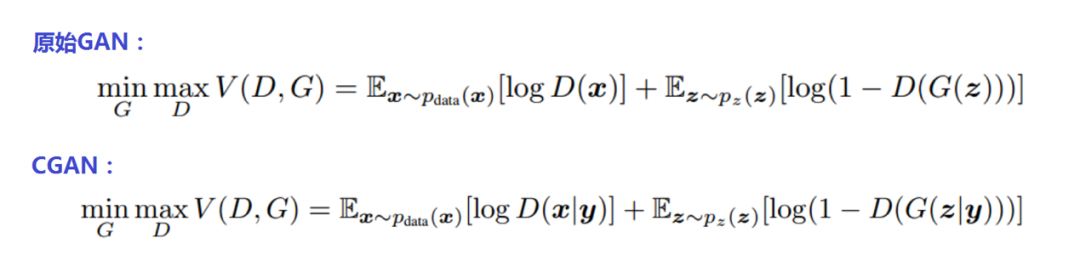
原始GAN的優化目標是在判別器最大化真實資料與生成資料差異的情況下,最小化這個差距(詳細的解釋請參考《四天搞懂生成對抗網路(一)——通俗理解經典GAN》),以訓練生成器,能夠將輸入的正態分布的隨機噪聲z盡可能完美的映射為訓練集資料的概率分布,
而上面CGAN公式中的條件y就是咱給GAN裝的“鈕”,加上了這個條件按鈕,GAN優化的概率期望分布公式就變成了CGAN優化的條件概率期望分布公式,即CGAN優化的目標是:在條件Y下,在判別器最大化真實資料與生成資料差異的情況下,最小化這個差距,訓練CGAN的生成器時要同時送入隨機噪聲z和和條件y(在本專案中y就是MNIST手寫數字資料集的數字標簽),就是這么簡單!
其實,在《四天搞懂生成對抗網路(一)——通俗理解經典GAN》中,我們介紹判別網路與生成網路的區別時曾經分析過:判別網路學習的是輸入x條件下的條件概率分布p(y|x),而生成網路學習的是概率分布p(x),那么我們給生成網路也加上個條件y,學習條件y下的條件概率分布p(x|y)就是CGAN了,
詳細的理論推導請參考原論文《Conditional Generative Adversarial Nets》:
https://arxiv.org/pdf/1411.1784.pdf
那么,下面我們就來看看裝了按鈕(條件y)的CGAN到底有何不同,
2、CGAN的結構
CGAN設計巧妙,而結構也十分簡單、清晰,與經典GAN只有輸入部分稍許不同,
我們看看原始GAN與CGAN的結構對比(包括生成器和判別器),上半部份的是經典GAN,下半部分是CGAN:
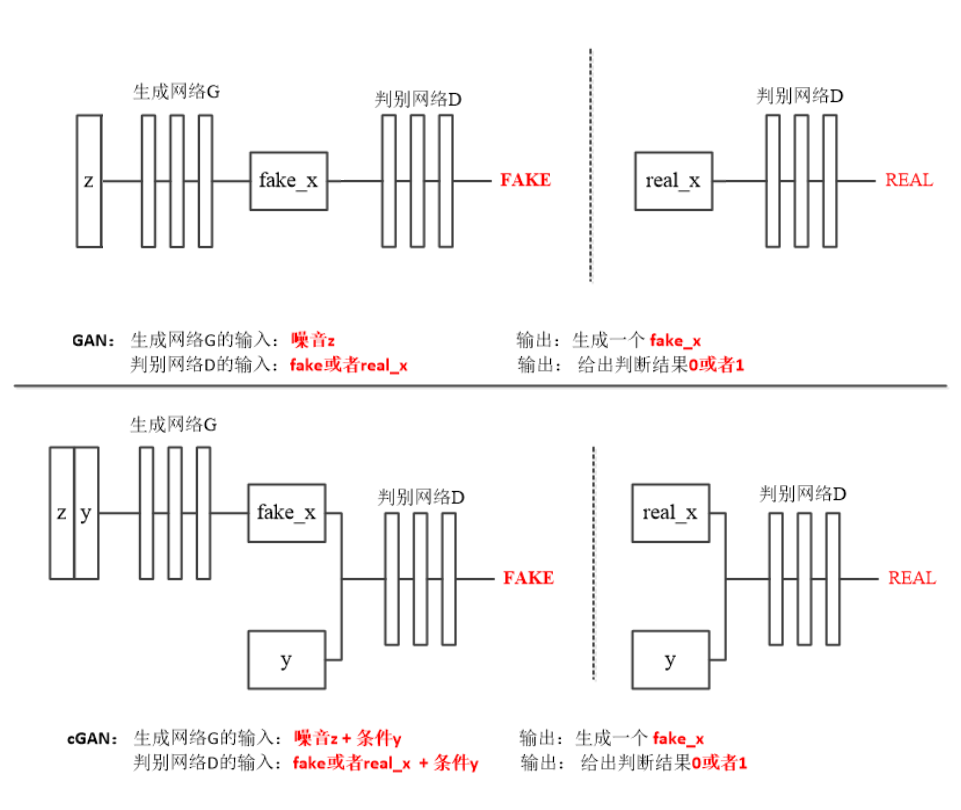
我們先回顧下經典GAN的結構流程(如上圖上半部份所示):
-
訓練判別器,將噪聲z送入生成器,輸出fake_x;將fake_x送入判別器,在更新判別器引數時嘗試拉近判別器的輸出與真標簽1的距離,即最小化判別器輸出與真標簽1的交叉熵損失,再將真圖片送入判別器,更新判別器引數時嘗試拉近判別器的輸出與假標簽0的距離,即最小化判別器輸出與假標簽0的交叉熵損失,這個程序中,用真、“假”圖片訓練判別器的順序不必需固定,真、假標簽取值0、1也無需固定(可相反,效果沒有區別),要注意的是,訓練判別器的程序中,只更新判別器引數,不更新生成器引數,
-
訓練生成器,生成器訓練的程序和判別器基本一樣,只是將生成器輸出的“假圖片”送入判別器后,將判別器的輸出與真標簽(1)拉近,目的就是,使生成器引數更新的方向朝著“騙過判別器的目標”進行,也就是所謂“對抗程序”,當然判別器出掌(判別器更新引數)時,生成器不還手(生成器不更新引數),輪到生成器還手(生成器更新引數)時,判別器也得雙手背后(判別器不更新引數),不然就打成一團,誰也看不到招式(無法正確更新引數,提高生成能力)了~~
我們再看下CGAN給GAN加的“料”(如上圖下半部份所示):
-
先看判別器,如圖,無論是給判別器送入真圖片還是生成器生成的假圖片時,都要加上個“條件y”,也就是分類標簽,判別器輸出沒有變化仍然只是判斷輸入圖片的真偽,老實說,當時我曾想:既然咱都conditional GAN了,這個判別器是不是要輸出分類標簽y來訓練Condition那部分?但轉念一想,不行,判別器還是得判別真偽,不然沒法和生成器對抗了,BUT,后來我發現還真有走這個路線的GAN,叫InfoGAN,這個InfoGAN給生成器配了兩個判別器,一個判真偽,一個分類別,
-
再看生成器,生成器的輸入除了隨機噪聲z外,也加入了“條件y”,到這兒,我又想:既然有了條件標簽,就不用輸入噪聲z了吧~,答案當然是,不行!因為,噪聲z的維度是和生成器輸出圖片的尺寸、復雜度相關的,本專案中輸出圖片尺寸是28×28=784,按理說模型進行映射的輸入、輸出尺寸應該是相等的,但是輸出圖片只是手寫數字,規律比較簡單,輸入的尺寸可以進行一定程度的壓縮,一般噪聲z的維度為幾十到一百就能生成比較理想的圖片細節,如果太低會導致生成器擬合能力不足,生成圖片質量低下,條件z只是一個取值0~9的維度為一的向量,模型擬合像素概率分布的效果可想而知,后面我們介紹的Pix2Pix模型的輸入是一張和輸出尺寸相同的圖片,就不再輸入噪聲z了,
CGAN需要注意的一點是:輸入的條件標簽y不但要在輸入時與噪聲z融合在一起,在生成器和判別器的每一層輸入里都要與特征圖相融合,才能讓模型“學好條件y”,不然,標簽可能不靈~
下面就是我最喜歡的部分了——跑代碼
CGAN碼上實作
1、資料讀取
資料讀取部分與原始GAN略有不同,原始GAN只需讀入圖片資料,而CGAN需要同時讀取圖片數字的label標簽,一起送入判別器和生成器進行訓練,
## 定義資料讀取
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import Conv2D, Pool2D, Linear, Conv2DTranspose
import numpy as np
import matplotlib.pyplot as plt
# 噪聲維度
Z_DIM = 100
BATCH_SIZE = 128
# BATCH_SIZE = 3 # debug
# 噪聲生成,通過由噪聲來生成假的圖片資料輸入,
def z_reader():
while True:
yield np.random.normal(0.0, 1.0, (Z_DIM, 1, 1)).astype('float32')
# 生成真實圖片reader
mnist_generator = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.train(), 30000), batch_size=BATCH_SIZE)
# 生成假圖片的reader
z_generator = paddle.batch(z_reader, batch_size=BATCH_SIZE)
import matplotlib.pyplot as plt
%matplotlib inline
data_tmp = next(mnist_generator())
print('一個batch圖片資料的形狀:batch_size =', len(data_tmp), ', data_shape =', data_tmp[0][0].shape, ', num = ', data_tmp[0][1])
plt.imshow(data_tmp[0][0].reshape(28, 28))
plt.show()
z_tmp = next(z_generator())
print('一個batch噪聲z的形狀:batch_size =', len(z_tmp), ', data_shape =', z_tmp[0].shape)
一個batch圖片資料的形狀:batch_size = 128 , data_shape = (784,) , num = 7
一個batch噪聲z的形狀:batch_size = 128 , data_shape = (100, 1, 1)
2、生成器與判別器
這部分是CGAN代碼的重點,加入的標簽y不是來參觀旅游的(是來當產品經理的~~),它要作為條件約束來限制生成器的輸出,就要深入到模型各層參與訓練程序,
參與的方法就是,將標簽y拼接到生成器和判別器的每層網路生成的特征圖上,拼接時 注意以下兩點:
-
噪聲拼接使用Paddle框架的fluid.layers.concat()函式實作,為了使代碼清晰,我們將拼接特征圖(包括全連接層和噪聲輸出的一維特征圖 與 卷積層輸出的和原始圖片的二維特征圖)與噪聲的代碼封裝在conv_concatenate()函式里,
-
在生成器與判別器的前向計算程序中,除了最后一層的輸出,生成器輸入的噪聲、判別器輸入的圖片都要拼接噪聲,
(注:原論文中作者將標簽embedding在了長度為10的one-hot向量上,本專案中則直接使用了長度為1的float32型別的數值(0~9的分類標簽)與特征圖拼接)
## 定義CGAN
# 定義特征圖拼接
def conv_concatenate(x, y):
# print('---', x.shape, y.shape)
# y = fluid.dygraph.to_variable(y.numpy().astype('float32'))
if len(x.shape) == 2: # 給全連接層輸出的特征圖拼接噪聲
y = fluid.layers.reshape(y, shape=[x.shape[0], 1])
ones = fluid.layers.fill_constant(y.shape, dtype='float32', value=1.0)
elif len(x.shape) == 4: # 給卷積層輸出的特征圖拼接噪聲
y = fluid.layers.reshape(y, shape=[x.shape[0], 1, 1, 1])
ones = fluid.layers.fill_constant(x.shape, dtype='float32', value=1.0)
x = fluid.layers.concat([x, ones * y], axis=1)
# print(ones.shape, x.shape, y.shape, '---')
return x
# 定義生成器
class G(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(G, self).__init__(name_scope)
name_scope = self.full_name()
# 第一組全連接和BN層
self.fc1 = Linear(input_dim=100+1, output_dim=1024)
self.bn1 = fluid.dygraph.BatchNorm(num_channels=1024, act='relu')
# 第二組全連接和BN層
self.fc2 = Linear(input_dim=1024+1, output_dim=128*7*7)
self.bn2 = fluid.dygraph.BatchNorm(num_channels=128*7*7, act='relu')
# 第一組轉置卷積運算
self.convtrans1 = Conv2DTranspose(256, 64, 4, stride=2, padding=1)
self.bn3 = fluid.dygraph.BatchNorm(64, act='relu')
# 第二組轉置卷積運算
self.convtrans2 = Conv2DTranspose(128, 1, 4, stride=2, padding=1, act='relu')
def forward(self, z, label):
z = fluid.layers.reshape(z, shape=[-1, 100])
z = conv_concatenate(z, label) # 拼接噪聲和label
y = self.fc1(z)
y = self.bn1(y)
y = conv_concatenate(y, label) # 拼接特征圖和label
y = self.fc2(y)
y = self.bn2(y)
y = fluid.layers.reshape(y, shape=[-1, 128, 7, 7])
y = conv_concatenate(y, label) # 拼接特征圖和label
y = self.convtrans1(y)
y = self.bn3(y)
y = conv_concatenate(y, label) # 拼接特征圖和label
y = self.convtrans2(y)
return y
# 定義判別器
class D(fluid.dygraph.Layer):
def __init__(self, name_scope):
super(D, self).__init__(name_scope)
name_scope = self.full_name()
# 第一組卷積池化
self.conv1 = Conv2D(num_channels=2, num_filters=64, filter_size=3)
self.bn1 = fluid.dygraph.BatchNorm(num_channels=64, act='leaky_relu')
self.pool1 = Pool2D(pool_size=2, pool_stride=2)
# 第二組卷積池化
self.conv2 = Conv2D(num_channels=128, num_filters=128, filter_size=3)
self.bn2 = fluid.dygraph.BatchNorm(num_channels=128, act='leaky_relu')
self.pool2 = Pool2D(pool_size=2, pool_stride=2)
# 全連接輸出層
self.fc1 = Linear(input_dim=128*5*5+1, output_dim=1024)
self.bnfc1 = fluid.dygraph.BatchNorm(num_channels=1024, act='leaky_relu')
self.fc2 = Linear(input_dim=1024+1, output_dim=1)
def forward(self, img, label):
y = conv_concatenate(img, label) # 拼接輸入圖片和label
y = self.conv1(y)
y = self.bn1(y)
y = self.pool1(y)
y = conv_concatenate(y, label) # 拼接特征圖和label
y = self.conv2(y)
y = self.bn2(y)
y = self.pool2(y)
y = fluid.layers.reshape(y, shape=[-1, 128*5*5])
y = conv_concatenate(y, label) # 拼接特征圖和label
y = self.fc1(y)
y = self.bnfc1(y)
y = conv_concatenate(y, label) # 拼接特征圖和label
y = self.fc2(y)
return y
## 測驗生成網路G和判別網路D
with fluid.dygraph.guard():
g_tmp = G('G')
l_tmp = fluid.dygraph.to_variable(np.array([x[1] for x in data_tmp]).astype('float32'))
tmp_g = g_tmp(fluid.dygraph.to_variable(np.array(z_tmp)), l_tmp).numpy()
print('生成器G生成圖片資料的形狀:', tmp_g.shape)
plt.imshow(tmp_g[0][0])
plt.show()
d_tmp = D('D')
tmp_d = d_tmp(fluid.dygraph.to_variable(tmp_g), l_tmp).numpy()
print('判別器D判別生成的圖片的概率資料形狀:', tmp_d.shape)生成器G生成圖片資料的形狀:(128, 1, 28, 28)
判別器D判別生成的圖片的概率資料形狀:(128, 1)
3、輔助函式
用于列印輸出訓練、預測圖片
## 定義顯示圖片的函式,構建一個18*n大小(n=batch_size/16)的圖片陣列,把預測的圖片列印到note中,
import matplotlib.pyplot as plt
%matplotlib inline
def show_image_grid(images, batch_size=128, pass_id=None):
fig = plt.figure(figsize=(8, batch_size/32))
fig.suptitle("Pass {}".format(pass_id))
gs = plt.GridSpec(int(batch_size/16), 16)
gs.update(wspace=0.05, hspace=0.05)
for i, image in enumerate(images):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(image[0], cmap='Greys_r')
plt.show()
show_image_grid(tmp_g, BATCH_SIZE)
4、訓練程序
CGAN的訓練程序與原始GAN基本沒有區別,只是因為要讓模型輸出的數字較好的受輸入標簽y的約束(避免輸出的數字錯亂),需要較長的訓練迭代步數,使模型更好的學習標簽y與生成數字的對應關系,所以,CGAN采用了LSGAN的loss來穩定訓練程序,避免長時訓練時發生模式崩潰,具體做法如下:
-
去掉判別器最后一層的sigmoid激活函式,
-
使用最小二乘損失代替原來的交叉熵損失,
替換loss函式在代碼上只需修改一句:
將原來的
real_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_real, ones)替換為
real_cost = (p_real - ones) ** 2 #lsgan本專案中每輪迭代時,分別使用真偽資料各訓練一次判別器,再加上訓練一次生成器,所以上面loss函式的修改要在這三處全部實施,
## 訓練CGAN
from visualdl import LogWriter
import time
import random
def train(mnist_generator, epoch_num=10, batch_size=128, use_gpu=True, load_model=False):
# with fluid.dygraph.guard():
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
# 模型存盤路徑
model_path = './output/'
d = D('D')
d.train()
g = G('G')
g.train()
# 創建優化方法
g_optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4, parameter_list=g.parameters())
d_optimizer = fluid.optimizer.AdamOptimizer(learning_rate=2e-4, parameter_list=d.parameters())
# 讀取上次保存的模型
if load_model == True:
g_para, g_opt = fluid.load_dygraph(model_path+'g')
d_para, d_opt = fluid.load_dygraph(model_path+'d')
g.load_dict(g_para)
g_optimizer.set_dict(g_opt)
d.load_dict(d_para)
d_optimizer.set_dict(d_opt)
iteration_num = 0
print('Start time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'start step:', iteration_num + 1)
for epoch in range(epoch_num):
for i, real_data in enumerate(mnist_generator()):
# 丟棄不滿整個batch_size的資料
if(len(real_data) != BATCH_SIZE):
continue
iteration_num += 1
'''
判別器d通過最小化輸入真實圖片時判別器d的輸出與真值標簽ones的交叉熵損失,來優化判別器的引數,
以增加判別器d識別真實圖片real_image為真值標簽ones的概率,
'''
# 將MNIST資料集里的圖片讀入real_image,將真值標簽ones用數字1初始化
ri = np.array([x[0] for x in real_data]).reshape(-1, 1, 28, 28)
rl = np.array([x[1] for x in real_data]).astype('float32')
real_image = fluid.dygraph.to_variable(np.array(ri))
real_label = fluid.dygraph.to_variable(rl)
ones = fluid.dygraph.to_variable(np.ones([len(real_image), 1]).astype('float32'))
# 計算判別器d判斷真實圖片的概率
p_real = d(real_image, real_label)
# 計算判別真圖片為真的損失
# real_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_real, ones)
real_cost = (p_real - ones) ** 2 #lsgan
real_avg_cost = fluid.layers.mean(real_cost)
'''
判別器d通過最小化輸入生成器g生成的假圖片g(z)時判別器的輸出與假值標簽zeros的交叉熵損失,
來優化判別器d的引數,以增加判別器d識別生成器g生成的假圖片g(z)為假值標簽zeros的概率,
'''
# 創建高斯分布的噪聲z,將假值標簽zeros初始化為0
z = next(z_generator())
z = fluid.dygraph.to_variable(np.array(z))
zeros = fluid.dygraph.to_variable(np.zeros([len(real_image), 1]).astype('float32'))
# 判別器d判斷生成器g生成的假圖片的概率
p_fake = d(g(z, real_label), real_label)
# fl = rl
# for i in range(batch_size):
# fl[i] = random.randint(0, 9)
# fake_label = fluid.dygraph.to_variable(fl)
# p_fake = d(g(z, fake_label), fake_label)
# 計算判別生成器g生成的假圖片為假的損失
# fake_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_fake, zeros)
fake_cost = (p_fake - zeros) ** 2 #lsgan
fake_avg_cost = fluid.layers.mean(fake_cost)
# 更新判別器d的引數
d_loss = real_avg_cost + fake_avg_cost
d_loss.backward()
d_optimizer.minimize(d_loss)
d.clear_gradients()
'''
生成器g通過最小化判別器d判別生成器生成的假圖片g(z)為真的概率d(fake)與真值標簽ones的交叉熵損失,
來優化生成器g的引數,以增加生成器g使判別器d判別其生成的假圖片g(z)為真值標簽ones的概率,
'''
# 生成器用輸入的高斯噪聲z生成假圖片
fake = g(z, real_label)
# 計算判別器d判斷生成器g生成的假圖片的概率
p_fake = d(fake, real_label)
# 使用判別器d判斷生成器g生成的假圖片的概率與真值ones的交叉熵計算損失
# g_cost = fluid.layers.sigmoid_cross_entropy_with_logits(p_fake, ones)
g_cost = (p_fake - ones) ** 2 #lsgan
g_avg_cost = fluid.layers.mean(g_cost)
# 反向傳播更新生成器g的引數
g_avg_cost.backward()
g_optimizer.minimize(g_avg_cost)
g.clear_gradients()
if(iteration_num % 100 == 0):
print('epoch =', epoch, ', batch =', i, ', d_loss =', d_loss.numpy(), 'g_loss =', g_avg_cost.numpy())
show_image_grid(fake.numpy(), BATCH_SIZE, epoch)
print('End time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'End Step:', iteration_num)
# 存盤模型
fluid.save_dygraph(g.state_dict(), model_path+'g')
fluid.save_dygraph(g_optimizer.state_dict(), model_path+'g')
fluid.save_dygraph(d.state_dict(), model_path+'d')
fluid.save_dygraph(d_optimizer.state_dict(), model_path+'d')
# train(mnist_generator, epoch_num=1, batch_size=BATCH_SIZE, use_gpu=True)
train(mnist_generator, epoch_num=1, batch_size=BATCH_SIZE, use_gpu=True, load_model=True)
# train(mnist_generator, epoch_num=20, batch_size=BATCH_SIZE, use_gpu=True, load_model=True) #11m
# train(mnist_generator, epoch_num=800, batch_size=BATCH_SIZE, use_gpu=True, load_model=True) #440m
Start time : 2020-11-09 18:34:07 start step: 1
epoch = 0 , batch = 99 , d_loss = [0.00953399] g_loss = [1.1064374]
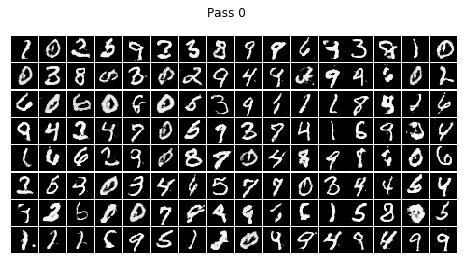
epoch = 0 , batch = 199 , d_loss = [0.01267804] g_loss = [0.87320054]

epoch = 0 , batch = 299 , d_loss = [0.01677028] g_loss = [0.9350312]
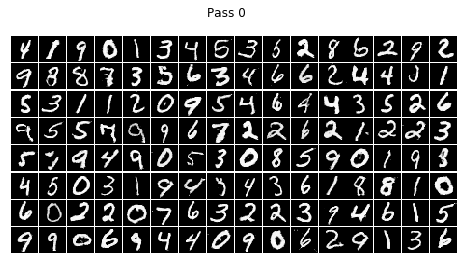
epoch = 0 , batch = 399 , d_loss = [0.01072838] g_loss = [1.0959808]

End time : 2020-11-09 18:34:35 End Step: 468
5、預測程序
趕快用訓練好的模型,按照標簽約束分別生成數字0~9看看效果吧,
## 使用CGAN分別生成數字0~9
def infer(batch_size=128, num=0, use_gpu=True):
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
# 模型存盤路徑
model_path = './output/'
g = G('G')
g.eval()
# 讀取上次保存的模型
g_para, g_opt = fluid.load_dygraph(model_path+'g')
g.load_dict(g_para)
# g_optimizer.set_dict(g_opt)
z = next(z_generator())
z = fluid.dygraph.to_variable(np.array(z))
label = fluid.layers.fill_constant([batch_size], dtype='float32', value=float(num))
fake = g(z, label)
show_image_grid(fake.numpy(), batch_size, -1)
for i in range(10):
infer(batch_size=BATCH_SIZE, num=i)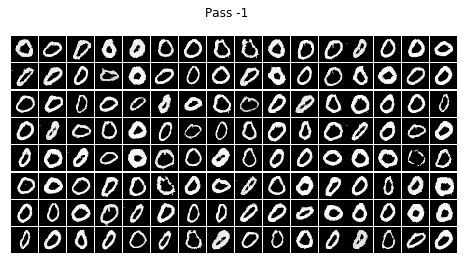

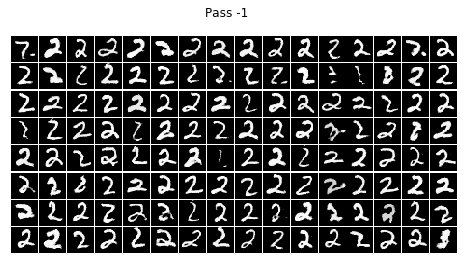
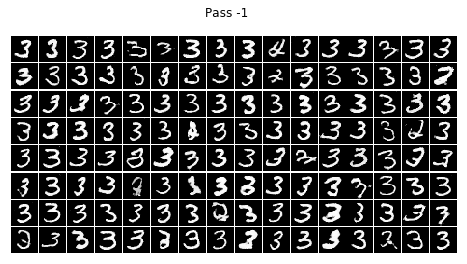
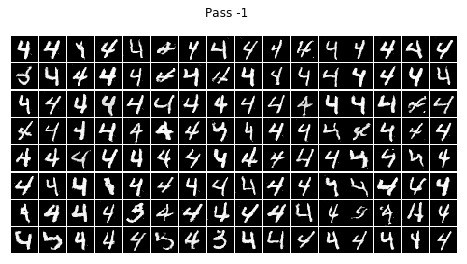
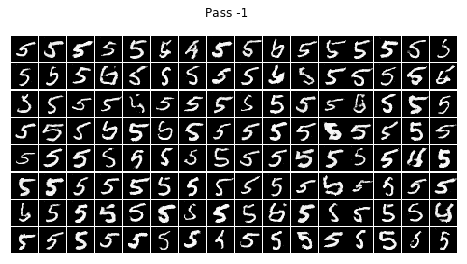
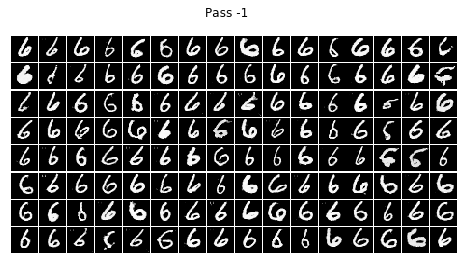

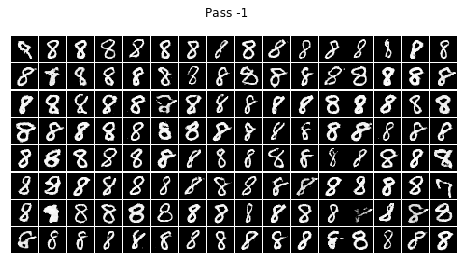
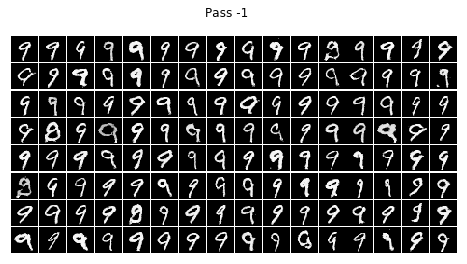
結論
不看廣告看療效~~CGAN已經完全治好了原始GAN的數字混亂,生成的數字都乖乖的按照輸入的標簽齊刷刷的立正站好......
在訓練的程序中我發現,訓練個二十輪后,CGAN就已經能夠像他哥原始GAN那樣生成比較清晰的數字,但標簽控對數字的控制還很不好,按鈕時靈時不靈,生成一個batch size的數字,少一半都站錯了隊,在訓練一個晚上后(輪數沒記錄下來,可以按時間估算),模型總算總算學會了讓生成的數字們按標簽y站好隊,
但是,生成的結果還是不完美,有些生成的數字是四不像,這點還可以理解,畢竟有些訓練集里的字符本身就不是很清楚規整,所以生成的也是那副德行,還有些字符清清楚楚就不屬于生他的標簽(抱錯了吧,哈哈),比如標簽為4的那一組,好幾個3恬不知恥的站在那里礙眼,我推測原因可能如下:
-
可能和生成四不像的原因一樣,是資料集標注錯誤導致的,這樣的話就不是模型的問題了,起碼不是模型精度的問題,
-
也可能是模型訓練得還不充分,再訓練一個晚上也許就調教好了,我真是覺得GAN模型不像分類模型那么好煉,火大火小(過擬合欠擬合)一目了然,GAN同時訓練至少兩個模型,就像水多加面、面多加水,到底熟沒熟經常嘗不出來~~
-
還有一種可能就是控制變數y在訓練的程序中比例占得太小了,輸入的噪聲100維,拼接上了1維y變成101維,控制變數在特征中所占比例才1%,拼接入全連接層特征圖則比例更低,拼接入卷積層特征圖則比例更更低,我想如果像原論文那樣采用one-hot編碼會不會好一點,控制變數y的權重可以擴大10倍,
歡迎各位同學大佬交流心得,指點迷津,在Deep Learnning的道路上互相拔扯,拉人出坑,功德無量~~
這個CGAN專案我們給GAN“加個鈕”,下個Pix2Pix專案我們就試著給GAN“畫張圖”~~
如在使用程序中有問題,可加入飛槳官方QQ群進行交流:1108045677,
如果您想詳細了解更多飛槳的相關內容,請參閱以下檔案,
·飛槳PaddleGAN專案地址(歡迎Star)·
GitHub:
https://github.com/PaddlePaddle/PaddleGAN
Gitee:
https://Gitee.com/PaddlePaddle/PaddleGAN
·飛槳官網地址·
https://www.paddlepaddle.org.cn/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232641.html
標籤:AI