文章目錄
- 判別模型與生成模型.
- 樸素貝葉斯分類器.
- NB-classifier引數估計.
- 拉普拉斯平滑.
- 貝葉斯決策論與風險最小化.
判別模型與生成模型.
- 考慮一個0-1標簽的二分類問題,假設0代表螞蟻,1代表大象,
- 【Logistic Regression】給定一組資料集,邏輯回歸能夠學習到一個分類器,當一個新樣本 x x x 到來時,它能夠給出該樣本屬于每一類的概率,并選擇其中概率更大的那一個作為預測分類輸出,邏輯回歸分類器對條件概率 P ( y ∣ x ) P(y|x) P(y∣x) 進行建模,嘗試找到一個分類邊界,能夠將兩類樣本分隔開,最終處理得到一個從輸入特征空間到類標簽{0,1}的映射,
- 【Another approach】首先關注代表大象的那一部分資料,學習一個模型E來表示大象是什么樣;然后關注表示螞蟻的那一部分資料,再學習一個模型A來表示螞蟻是什么樣的,當一個新樣本到來時,我們將其放入模型E和模型A,看看該樣本是更像螞蟻還是大象,
- 像對數幾率回歸這種,直接根據樣本對標簽進行建模,即嘗試獲得 P ( y ∣ x ) P(y|x) P(y∣x) 條件概率分布的模型叫做判別學習演算法-Discriminative Learning Algorithms;而第二種思路則是著眼于不同的y,對于該類樣本的特征進行學習,也就是嘗試對 P ( x ∣ y = k ) P(x|y=k) P(x∣y=k) 進行學習(本質上是在學習聯合概率分布 P ( x , y ) P(x,y) P(x,y) ),例如y=1時,對于條件概率分布 P ( x ∣ y = 1 ) P(x|y=1) P(x∣y=1) 進行建模,這樣的模型叫做生成學習演算法-Generative Learning Algorithm,
- 在生成學習演算法中,如果完成了對于先驗概率分布
P
(
y
)
P(y)
P(y) 以及條件概率分布
P
(
x
∣
y
)
P(x|y)
P(x∣y) 的建模,就可以通過貝葉斯公式來獲得后驗概率分布
P
(
y
∣
x
)
P(y|x)
P(y∣x),籍此來對新樣本進行分類,貝葉斯公式如下:
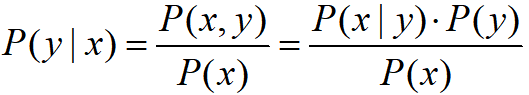
- 分母上的概率分布
P
(
x
)
P(x)
P(x) 可以通過全概率公式得出,不失其一般性,我們考慮上面提到的二分類問題,有如下公式:
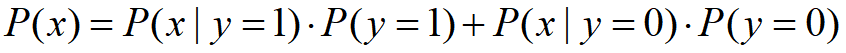
- 實際的分類程序中,在完成了對于先驗概率分布
P
(
y
)
P(y)
P(y) 以及條件概率分布
P
(
x
∣
y
)
P(x|y)
P(x∣y) 的建模后,并不需要關心
P
(
x
)
P(x)
P(x) 是否求出,因為選出后驗概率最大的
y
y
y 與其無關,
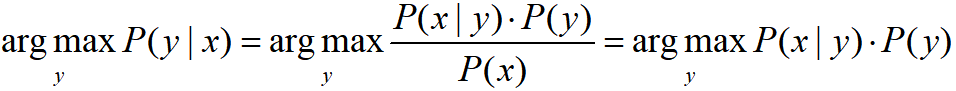
樸素貝葉斯分類器.
- Naive Bayes Classifier考慮輸入特征取值都是離散值的情況,并對條件概率分布
P
(
x
∣
y
)
P(x|y)
P(x∣y) 做出條件獨立性的假設,這是一個相當強的假設,描述如下:
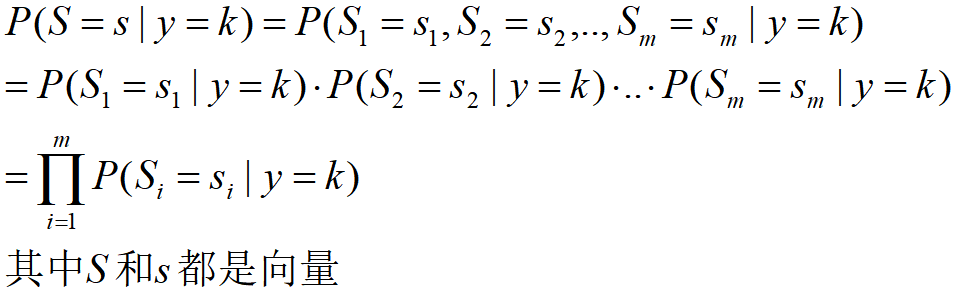
- 假定輸入向量
x
=
[
x
1
,
x
2
,
.
.
,
x
m
]
T
x=[x_1,x_2,..,x_m]T
x=[x1?,x2?,..,xm?]T,即共有
m
m
m 個特征,通過我們學習得到的貝葉斯分類器來計算其后驗概率
P
(
y
=
c
k
∣
X
=
x
)
P(y=c_k|X=x)
P(y=ck?∣X=x),即得到如下推導:
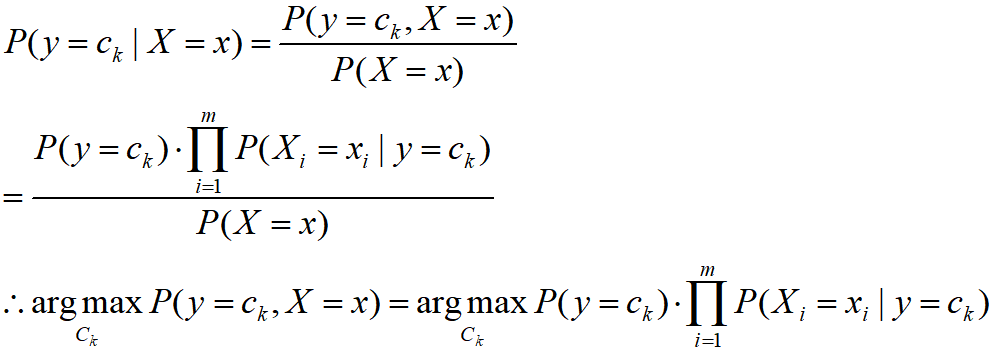
- 注意上圖中 C k C_k Ck?代表類別,計算得到的后驗概率中最大的 C k C_k Ck? 就是該輸入樣本的所屬類別,分母 P ( X = x ) P(X=x) P(X=x) 對于所有的 C k C_k Ck? 而言都是相同的,所以在尋找最大值時,可以忽略,
- 關于條件獨立性假設(也稱樸素貝葉斯假設),之所以說其是一個很強的假設,是因為實際中的屬性之間幾乎不存在獨立的情況,以經典應用【垃圾郵件過濾器】為例,如果這封郵件中出現了詞匯【Computer】,那么其中很大概率會出現【electronic】【science】【network】等等一系列與之有關的詞匯,也就是說 P ( n e t w o r k ∣ C o m p u t e r ) ≠ 0 P(network|Computer)≠0 P(network∣Computer)?=0,但即使有這樣一個很強的假設,實際應用中樸素貝葉斯分類器在很多問題上的表現還是很不錯,
NB-classifier引數估計.
- 樸素貝葉斯分類演算法中需要學習聯合概率分布 P ( X , y ) P(X,y) P(X,y),更具體地說,需要學習先驗概率分布 P ( y ) P(y) P(y) 以及條件概率分布 P ( x ∣ y ) P(x|y) P(x∣y),關于這兩個分布的學習,在監督學習中,一種很自然的想法是基于樣本的極大似然估計,
- 簡單來說就是統計樣本中的分布,將其作為真實分布的估計,構建出一個樸素貝葉斯分類器,具體公式如下:
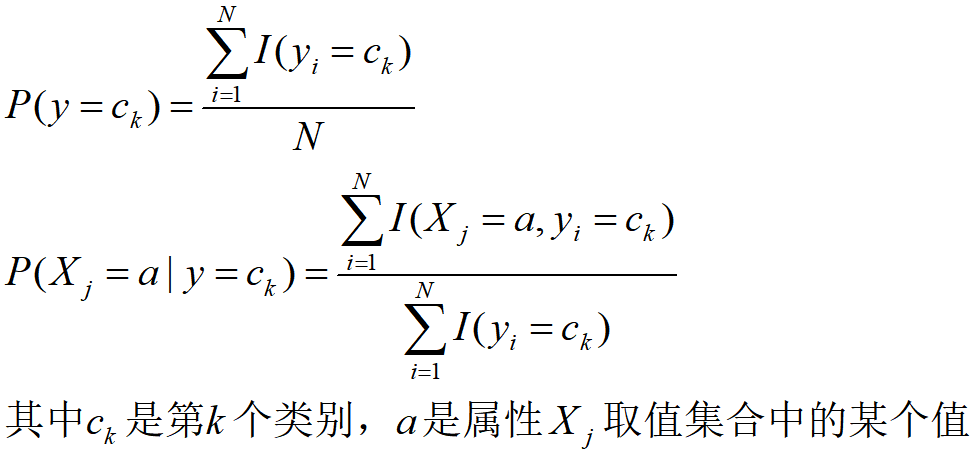
拉普拉斯平滑.
- 如果輸入樣本中的某個屬性值,是訓練集中從未出現過的,那么上面給出的引數估計以及后驗概率計算就會變為:
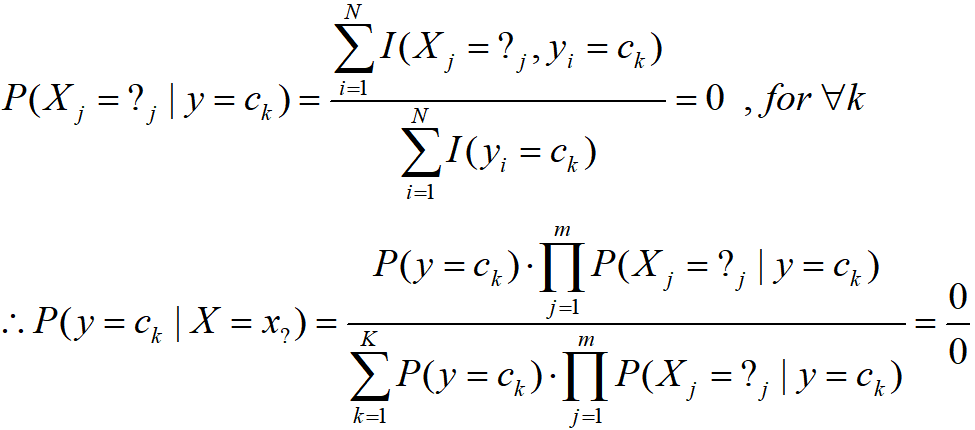
- 這是一個未定式,將導致后續的預測無法進行,解決方法之一是采用Laplace Smoothing,即在基于樣本估計條件概率分布
P
(
x
∣
y
)
P(x|y)
P(x∣y) 時在分子、分母上都加一個正常數,從而避免出現訓練集中未出現屬性值被估計為0的情況,應用拉普拉斯平滑后的貝葉斯分類器引數估計如下:
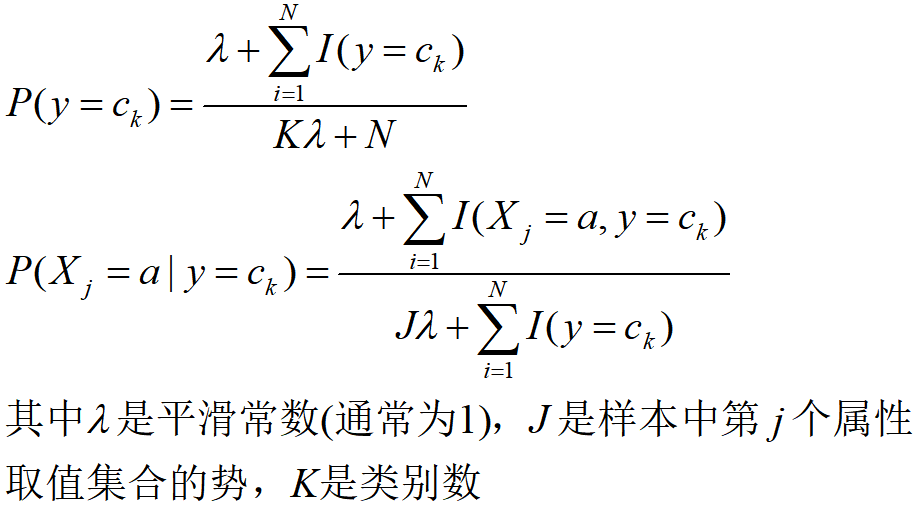
貝葉斯決策論與風險最小化.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/232668.html
標籤:其他
上一篇:前端中的演算法1:二分查找