聚集索引
我們先建如下的一張表
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '學號',
`name` varchar(10) NOT NULL COMMENT '學生姓名',
`age` int(11) NOT NULL COMMENT '學生年齡',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB;
插入如下sql
insert into student (`name`, `age`) value('a', 10);
insert into student (`name`, `age`) value('c', 12);
insert into student (`name`, `age`) value('b', 9);
insert into student (`name`, `age`) value('d', 15);
insert into student (`name`, `age`) value('h', 17);
insert into student (`name`, `age`) value('l', 13);
insert into student (`name`, `age`) value('k', 12);
insert into student (`name`, `age`) value('x', 9);
資料如下
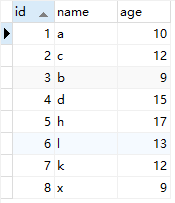
mysql是按照頁來存盤資料的,每個頁的大小為16k,
在MySQL中可以通過執行如下陳述句,看到一個頁的大小
show global status like 'innodb_page_size'
結果為16384,即16kb
在InnoDB存盤引擎中,是以主鍵為索引來組織資料的,記錄在頁中按照主鍵從小到大的順序以單鏈表的形式連接在一起,
可能有小伙伴會問,如果建表的時候,沒有指定主鍵呢?
如果在創建表時沒有顯示的定義主鍵,則InnoDB存盤引擎會按如下方式選擇或創建主鍵,
- 首先判斷表中是否有非空的唯一索引,如果有,則該列即為主鍵,如果有多個非空唯一索引時,InnoDB存盤引擎將選擇建表時第一個定義的非空唯一索引作為主鍵
- 如果不符合上述條件,InnoDB存盤引擎自動創建一個6位元組大小的指標作為索引
頁和頁之間以雙鏈表的形式連接在一起,并且下一個資料頁中用戶記錄的主鍵值必須大于上一個資料頁中用戶記錄的主鍵值
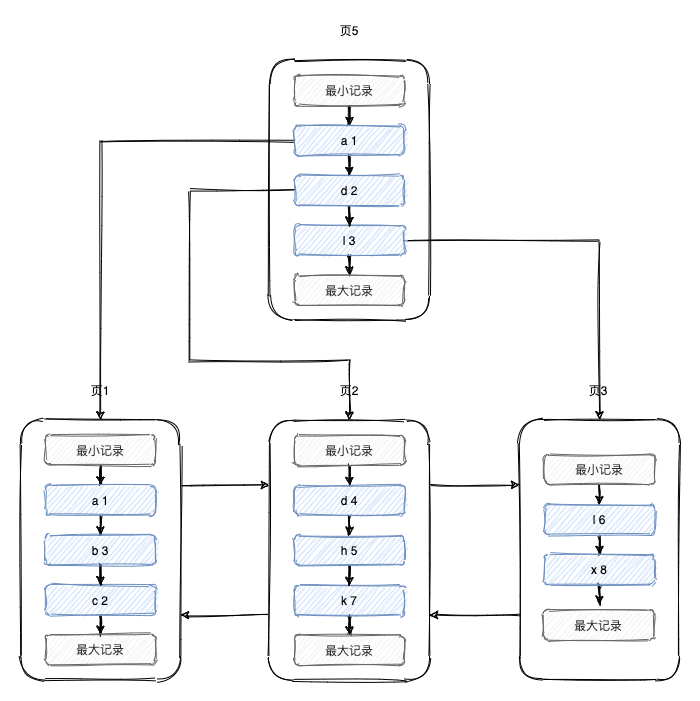
假設一個頁只能存放3條資料,則資料存盤結構如下,
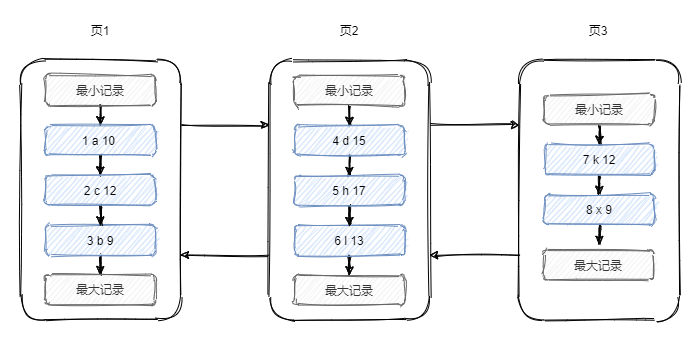
可以看到我們想查詢一個資料或者插入一條資料的時候,需要從最開始的頁開始,依次遍歷每個頁的鏈表,效率并不高,
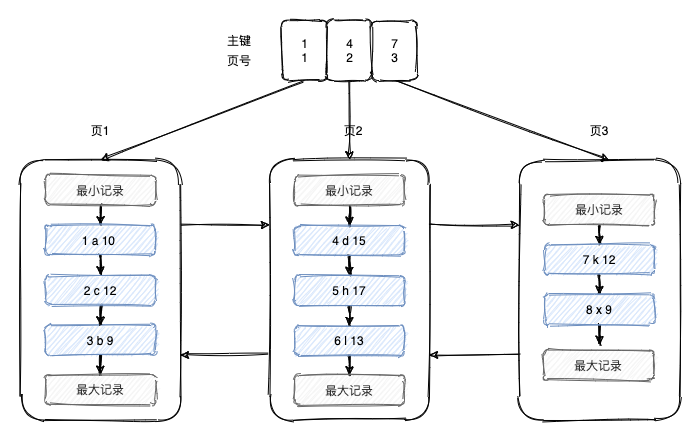
我們可以給這頁做一個目錄,保存主鍵和頁號的映射關系,根據二分法就能快速找到資料所在的頁,但這樣做的前提是這個映射關系需要保存到連續的空間,如陣列,如果這樣做會有如下幾個問題
- 隨著資料的增多,目錄所需要的連續空間越來越大,并不現實
- 當有一個頁的資料全被洗掉了,則相應的目錄項也要洗掉,它后面的目錄項都要向前移動,成本太高
我們可以把目錄資料放在和用戶資料類似的結構中,如下所示,目錄項有2個列,主鍵和頁號,
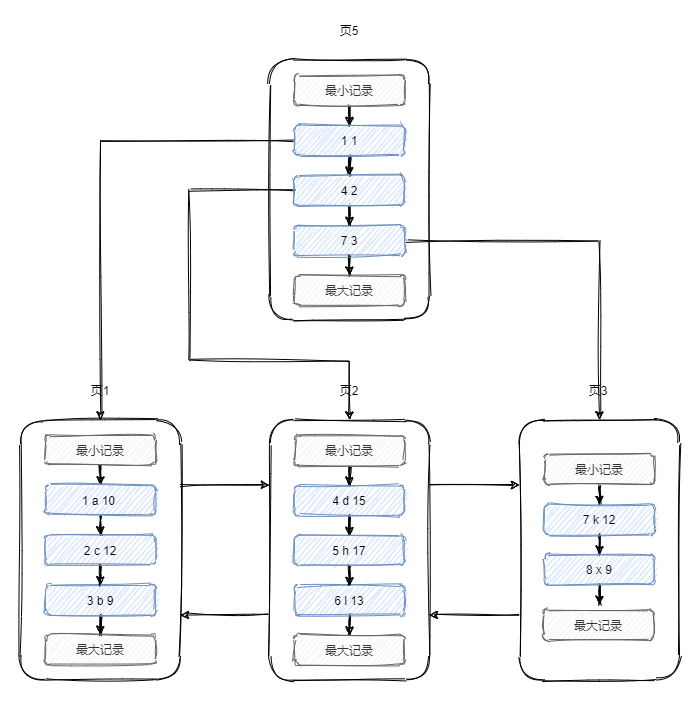
資料很多時,一個目錄項肯定很多,畢竟一個頁的大小為16k,我們可以對資料建立多個目錄專案,在目錄項的基礎上再建目錄項,如下圖所示
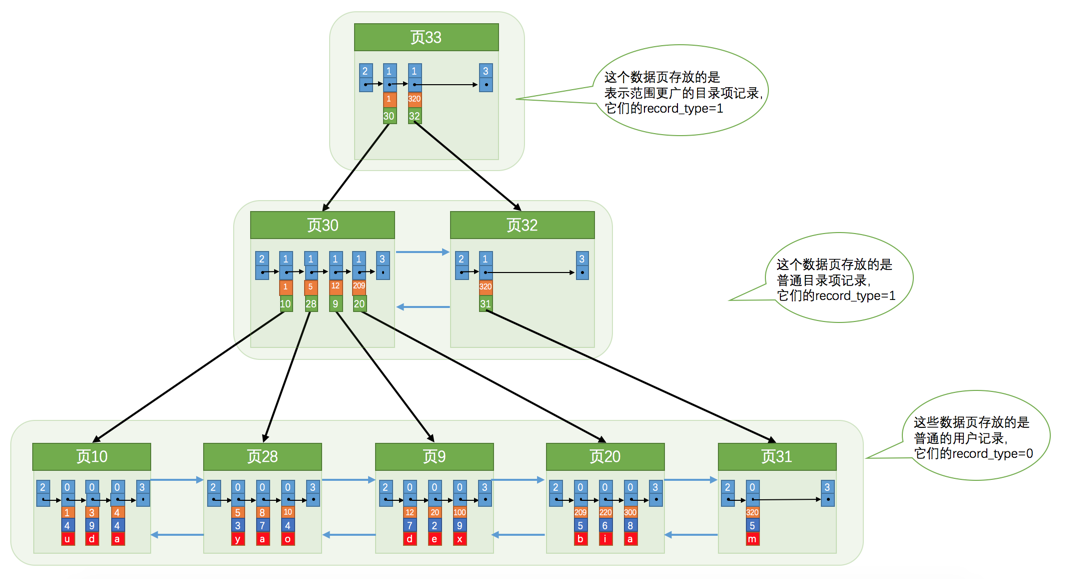
圖片來自《MySQL 是怎樣運行的:從根兒上理解 MySQL》
這其實就是一顆B+樹,也是一個聚集索引,即資料和索引在一塊,葉子節點保存所有的列值
以 InnoDB 的一個整數欄位索引為例,這個 N 差不多是 1200,這棵樹高是 4 的時候,就可以存 1200 的 3 次方個值,這已經17 億了,考慮到樹根的資料塊總是在記憶體中的,一個 10 億行的表上一個整數欄位的索引,查找一個值最多只需要訪問 3次磁盤,其實,樹的第二層也有很大概率在記憶體中,那么訪問磁盤的平均次數就更少了,《MySQL實戰45講》
非聚集索引
非聚集索引葉子節點的值為索引列+主鍵
當我們查詢name為h的用戶資訊時(學號,姓名,年齡),因為name上建了索引,先從name非聚集索引上,找到對應的主鍵id,然后根據主鍵id從聚集索引上找到對應的記錄,
從非聚集索引上找到對應的主鍵值然后到聚集索引上查找對應記錄的程序為回表
聯合索引/索引覆寫
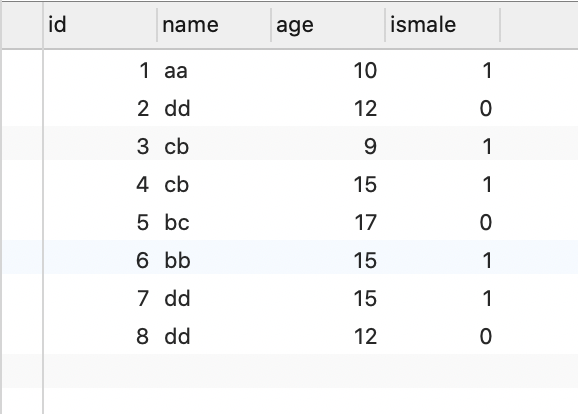
假設teacher表定義如下,在name和age列上建立聯合索引
CREATE TABLE `teacher` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '教師編號',
`name` varchar(10) NOT NULL COMMENT '教師姓名',
`age` int(11) NOT NULL COMMENT '教師年齡',
`ismale` tinyint(3) NOT NULL COMMENT '是否男性',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`, `age`)
) ENGINE=InnoDB;
插入如下sql
insert into teacher (`name`, `age`, `ismale`) value('aa', 10, 1);
insert into teacher (`name`, `age`, `ismale`) value('dd', 12, 0);
insert into teacher (`name`, `age`, `ismale`) value('cb', 9, 1);
insert into teacher (`name`, `age`, `ismale`) value('cb', 15, 1);
insert into teacher (`name`, `age`, `ismale`) value('bc', 17, 0);
insert into teacher (`name`, `age`, `ismale`) value('bb', 15, 1);
insert into teacher (`name`, `age`, `ismale`) value('dd', 15, 1);
insert into teacher (`name`, `age`, `ismale`) value('dd', 12, 0);
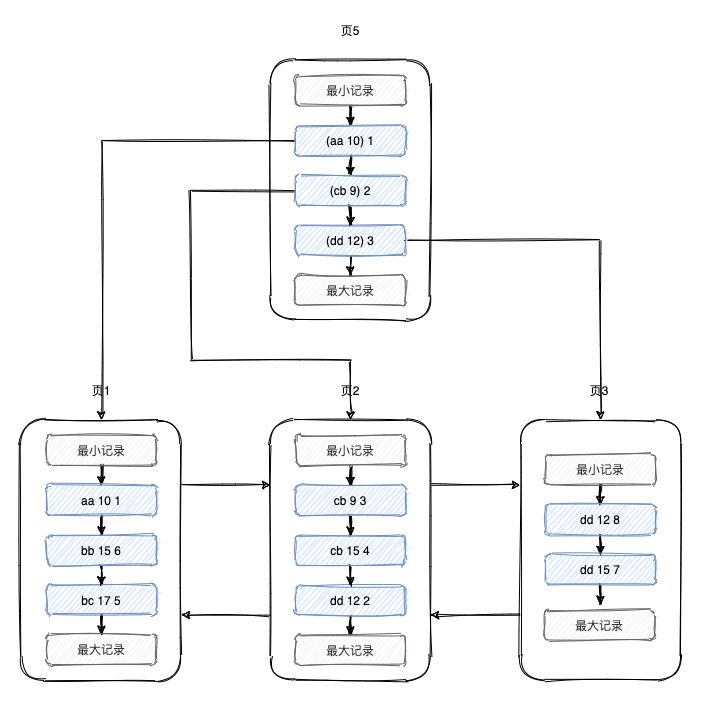
對name和age列建立聯合索引
目錄頁由name列,age列,頁號這三部分組成,目錄會先按照name列進行排序,當name列相同的時候才對age列進行排序,
資料頁由name列,age列,主鍵值這三部分組成,同樣的,資料頁會先按照name列進行排序,當name列相同的時候才對age列進行排序,
當執行如下陳述句的時候,會有回表的程序
select * from student where name = 'aa';
當執行如下陳述句的時候,沒有回表的程序
select name, age from student where name = 'aa';
為什么不需要回表呢?
因為idx_name_age索引的葉子節點存的值為主鍵值,name值和age值,所以從idx_name_age索引上就能獲取到所需要的列值,不需要回表,即索引覆寫
索引下推
當執行如下陳述句的時候
select * from student where name like '張%' and age = 10 and ismale = 1;
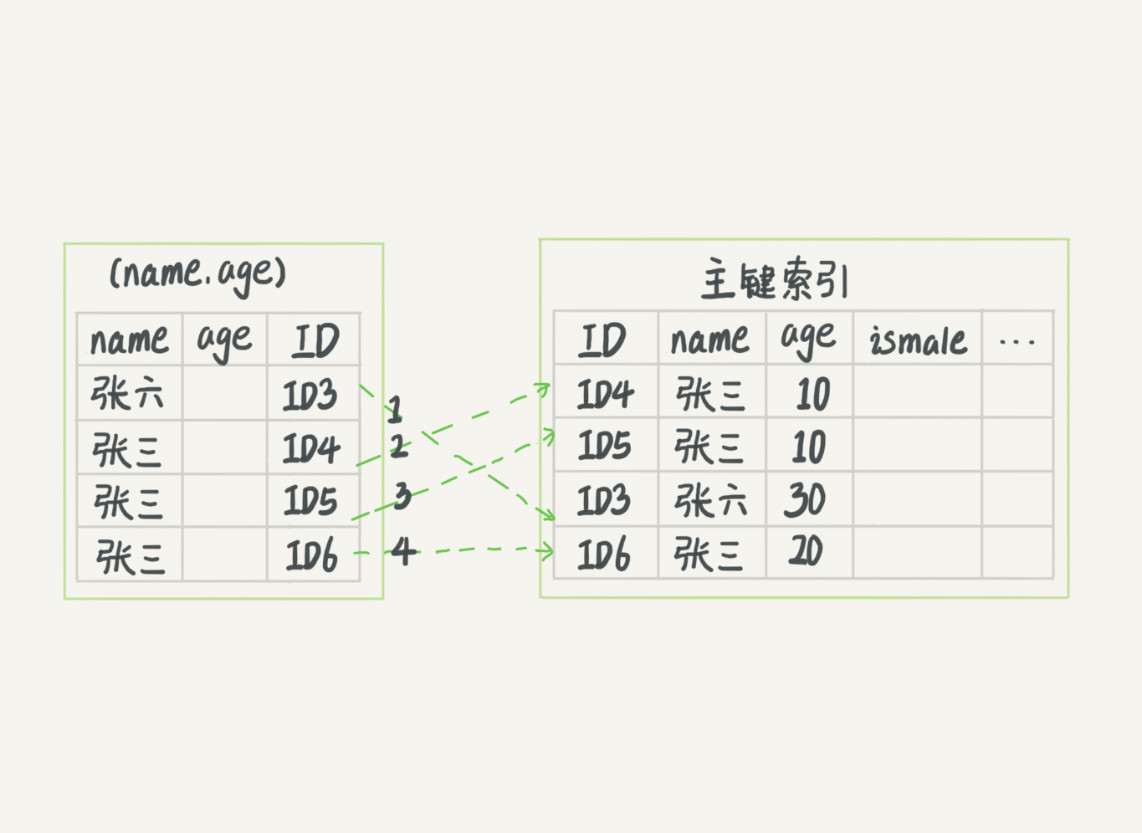
在5.6版本之前的執行程序如下,先從idx_name_age索引上找到對應的主鍵值,然后回表找到對應的行,判斷其他欄位的值是否滿足條件
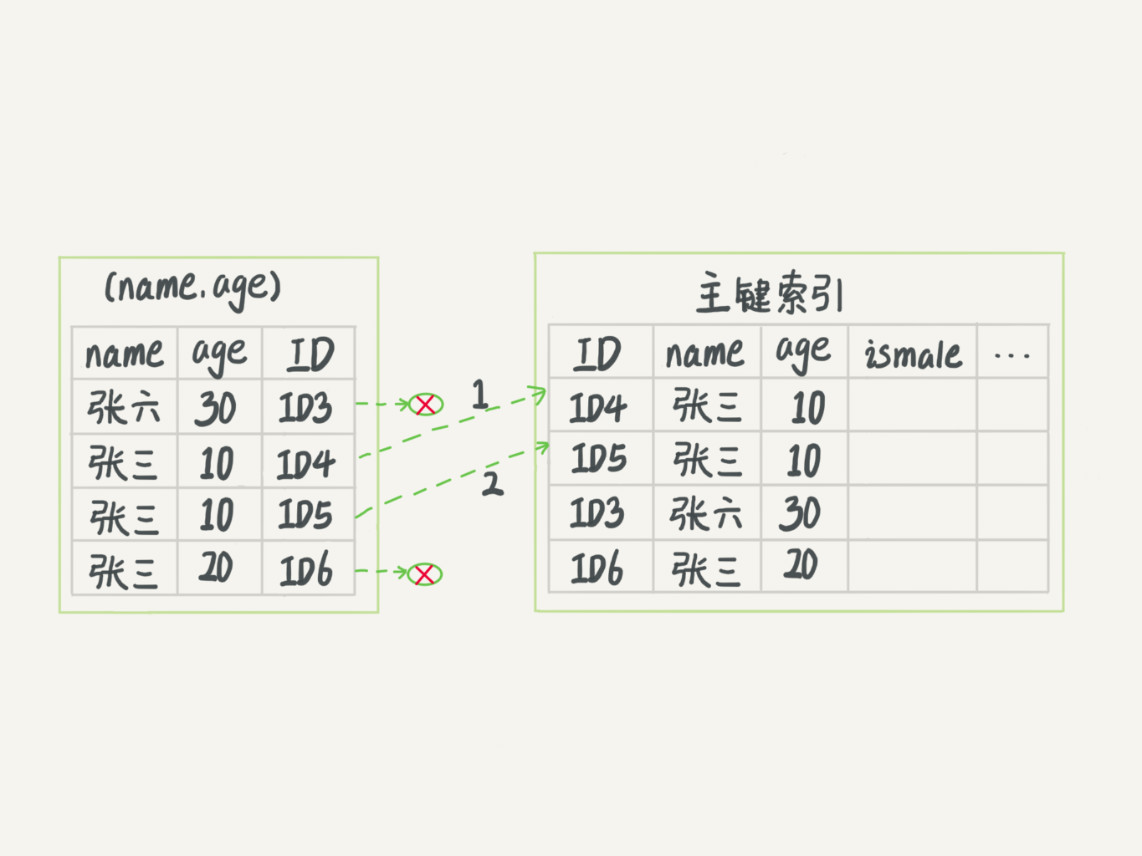
在5.6引入了索引下推優化,可以在遍歷索引的程序中,對索引中包含的欄位做判斷,直接過濾掉不滿足條件的資料,減少回表次數,如下圖
參考博客
《MySQL 是怎樣運行的:從根兒上理解 MySQL》
圖示演算法
[0]https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
[1]https://blog.csdn.net/qq_35190492/article/details/106915564
[2]https://blog.csdn.net/qq_35571554/article/details/82759668
聯合索引
[3]https://www.cnblogs.com/rjzheng/p/12557314.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233090.html
標籤:AI
上一篇:學習周報_1