在今天的文章中,我們將講述如何運用 Elasticsearch 的 ingest 節點來對資料進行結構化并對資料進行處理,
資料集
在我們的實際資料采集中,資料可能來自不同的來源,并且以不同的形式展展現:
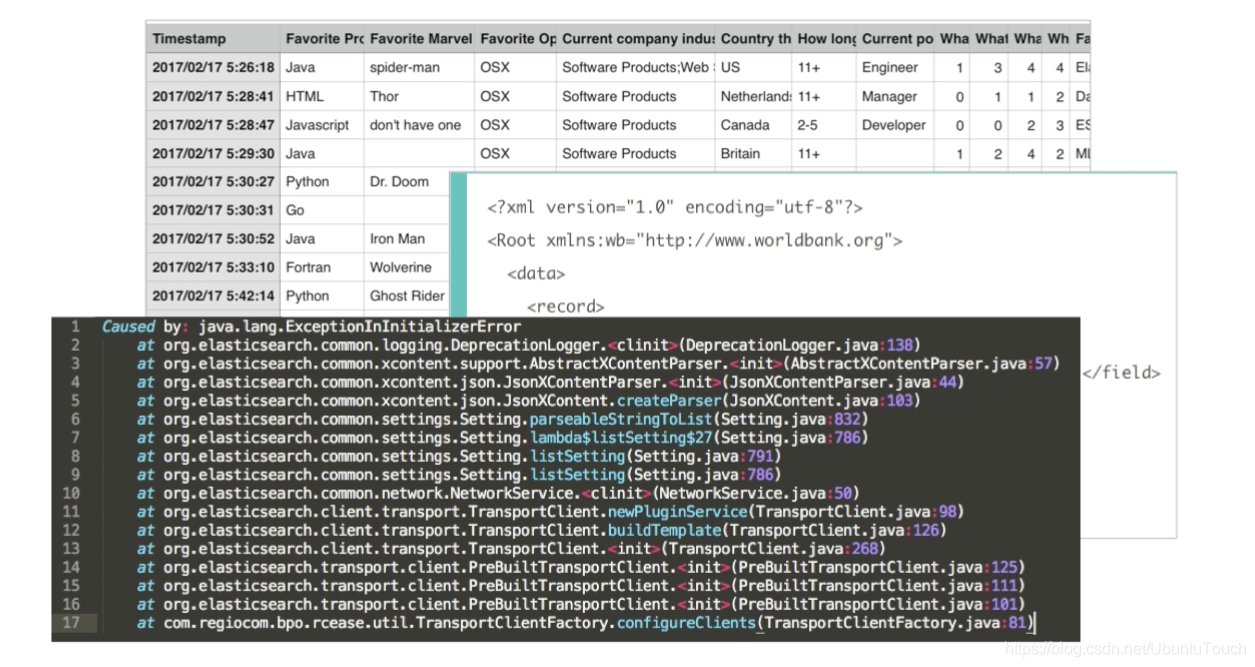
這些資料可以是一種很結構化的資料被攝,比如資料庫中的資料, 或者就是一直最原始的非結構化的資料,比如日志,對于一些非結構化的資料,我們該如何把它們結構化,并使用 Elasticsearch 進行分析呢?
結構化資料
就如上面的資料展示的那樣,在很多的情況下,資料在攝入的時候是一種非結構化的形式來呈現的,這個資料通常有一個叫做 message 的欄位,為了能達到結構化的目的,我們們需要 parse 及 transform 這個 message 欄位,并把這個 message 變為我們所需要的欄位,從而達到結構化的母的,讓我們看一個例子,假如我們有如下的資訊:
{
"message": "2019-09-29T00:39:02.9122 [Debug] MyApp stopped"
}顯然上面的資訊是一個非結構化的資訊,它含有唯一的一個欄位 message,我們希望通過一些方法把它變成為:
{
"@timestamp": "2019-09-29T00:39:02.9122",
"loglevel": "Debug",
"status": "MyApp stopped"
}顯然上面的資料是一個結構化的檔案,它更便于我們對資料進行分析,比如我們對資料進行聚合或在Kibana中進行展示,
我們接下來看一下一個典型的 Elastic Stack 的架構圖:
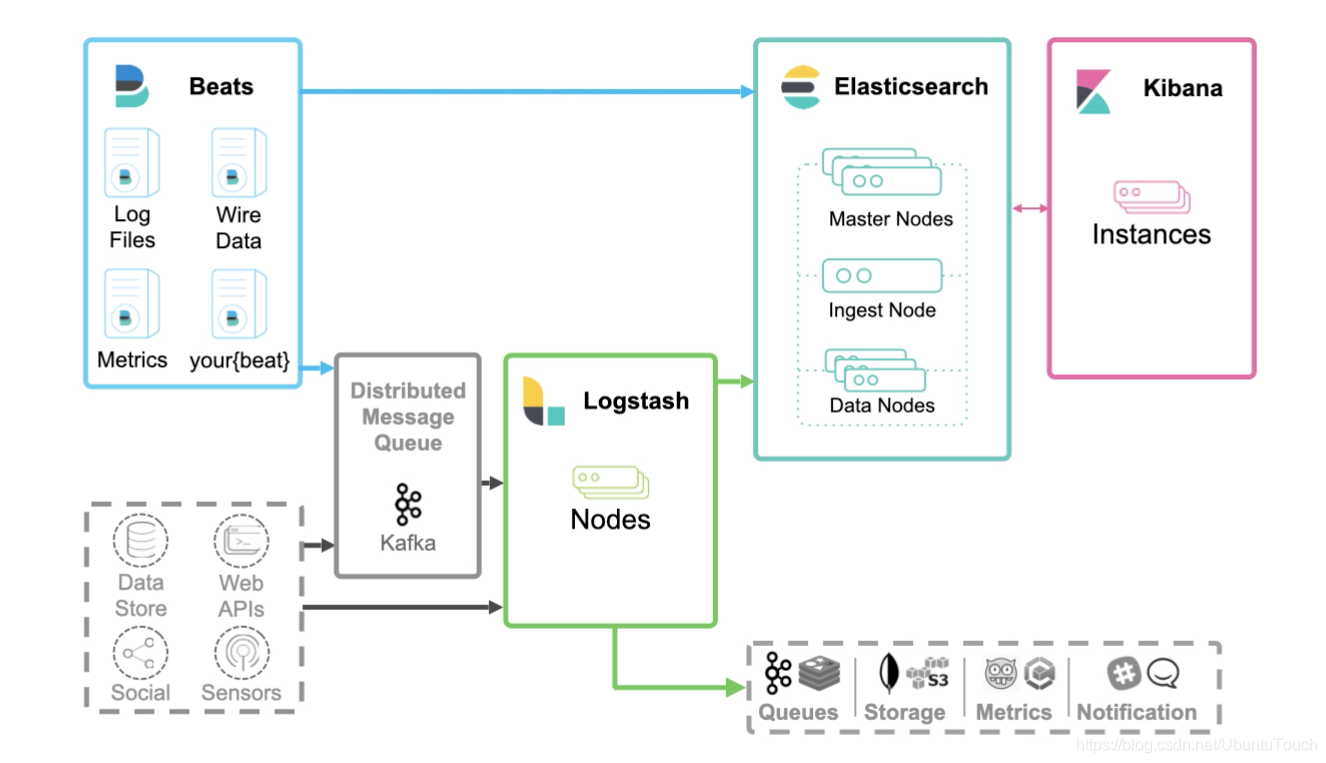
在上面,我們可以看到有兩個地方我們可以對資料進行處理:
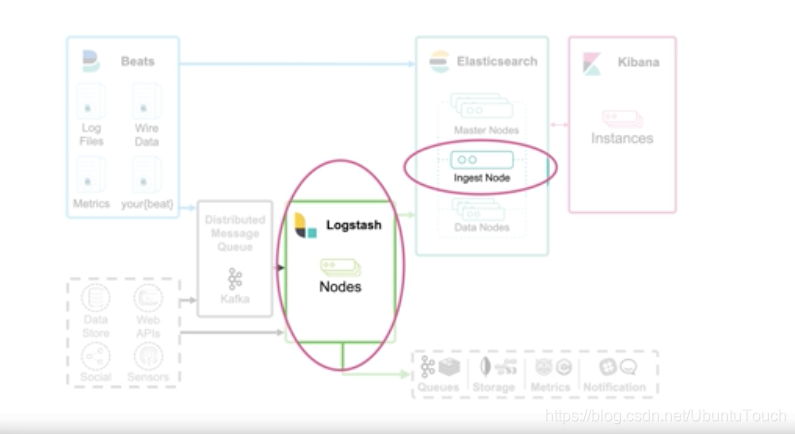
我們可以使用Logstash和Ingest node來對我們的資料進行處理,如果大家還對使用 Logstash 或者是 Ingest Node 沒法做選擇的話,請參閱我之前的文章 “我應該使用Logstash或是Elasticsearch ingest 節點?”,
如果你的日志資料不是一個已有的格式,比如 apache, nginx,那么你需要建立自己的 pipeline 來對這些日志進行處理,在今天的文章里,我們將介紹如何使用 Elasticsearch 的 ingest processors 來對我們的非結構化資料進行處理,從而把它們變為結構化的資料:
- split
- dissect
- kv
- grok
- ...
Ingest pipelines
一個Elasticsearch pipeline是一組 processors:
- 讓我們在資料建立索引之前做預處理
- 每一個 processor 可以修改經過它的檔案
- processor 的處理是在 Elasticsearch 新的 ingest node 里進行的
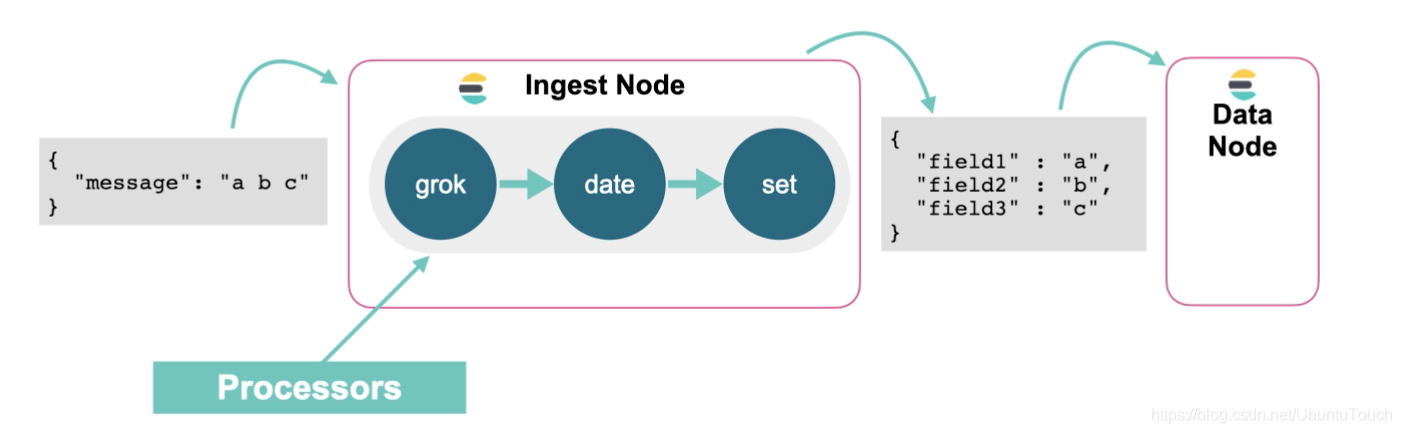
定義一個 Elasticsearch 的 ingest pipeline
我們可以使用 Ingest API 來定義 pipelines:
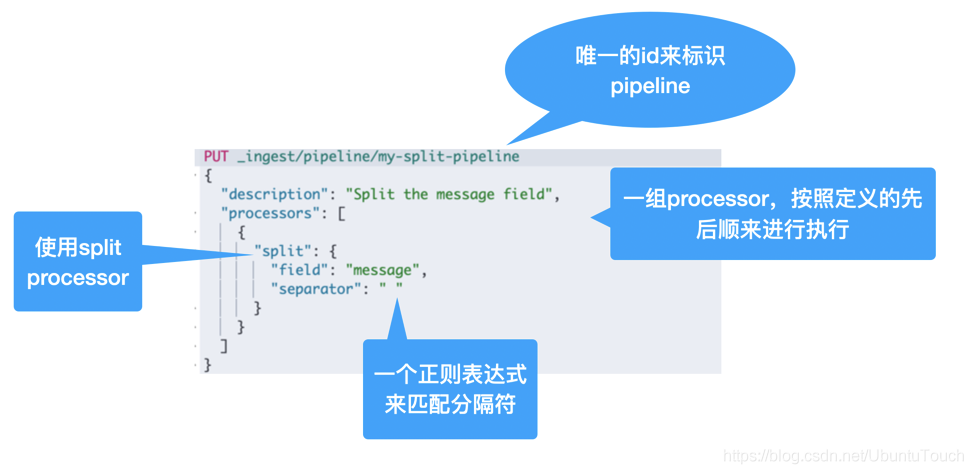
我們可以使用 _simulate 終點來進行測驗:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"split": {
"field": "message",
"separator": " "
}
}
]
},
"docs": [
{
"_source": {
"message": "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK"
}
}
]
}
上面的運行的結果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"message" : [
"2019-09-29T00:39:02.912Z",
"AppServer1",
"STATUS_OK"
]
},
"_ingest" : {
"timestamp" : "2020-04-27T08:40:43.059569Z"
}
}
}
]
}我們看到在上面的 split proocessor 中它把一個非結構化的 message 變成了一個結果話的資料,message 現在是一個陣列,那么我們該如何參考這個陣列里的資料呢?
我們接著修改 pipeline:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"split": {
"field": "message",
"separator": " "
}
},
{
"set": {
"field": "timestamp",
"value": "{{message.0}}"
}
}
]
},
"docs": [
{
"_source": {
"message": "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK"
}
}
]
}在上面我們使用了 {{message.0}} 來訪問陣列里的第一個資料,上面的命令運行的結果為:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"message" : [
"2019-09-29T00:39:02.912Z",
"AppServer1",
"STATUS_OK"
],
"timestamp" : "2019-09-29T00:39:02.912Z"
},
"_ingest" : {
"timestamp" : "2020-12-09T02:08:25.004644Z"
}
}
}
]
}我們可以看到一個叫做 timestamp 的欄位,
在實際的使用中,我們甚至可以使用 target_field 來重新被 split 后的 欄位名稱:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"split": {
"field": "message",
"separator": " ",
"target_field": "new"
}
},
{
"set": {
"field": "timestamp",
"value": "{{message.0}}"
}
}
]
},
"docs": [
{
"_source": {
"message": "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK 2000"
}
}
]
}上面運行的結果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"new" : [
"2019-09-29T00:39:02.912Z",
"AppServer1",
"STATUS_OK",
"2000"
],
"message" : "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK 2000",
"timestamp" : ""
},
"_ingest" : {
"timestamp" : "2020-12-09T02:13:43.697296Z"
}
}
}
]
}我們可以看到一個叫做 new 的欄位代替之前的 message,由于我們增加了一個新的文字 “2000”,在我們的 new 欄位輸出中,可以看到一個新增加的字串 “2000”,假如我們想把這個欄位轉換為整數,那么我們可以使用如下的辦法:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"split": {
"field": "message",
"separator": " ",
"target_field": "new"
}
},
{
"set": {
"field": "timestamp",
"value": "{{message.0}}"
}
},
{
"convert": {
"field": "new.3",
"type": "integer"
}
}
]
},
"docs": [
{
"_source": {
"message": "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK 2000"
}
}
]
}在上面,我們使用 new.3 來表想要轉換的欄位,上面的輸出結果為:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"new" : [
"2019-09-29T00:39:02.912Z",
"AppServer1",
"STATUS_OK",
2000
],
"message" : "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK 2000",
"timestamp" : ""
},
"_ingest" : {
"timestamp" : "2020-12-09T02:16:30.144772Z"
}
}
}
]
}從上面我們可以看出來 “2000” 變成了 2000,
如何使用 Pipeline
一旦你定義好一個 pipeline,如果你是使用 Filebeat 接入到 Elasticsearch 匯入資料,那么你可以在 filebeat 的組態檔中這樣使用這個 pipeline:
output.elasticsearch:
hosts: ["http://localhost:9200"]
pipeline: my_pipeline你也可以直接為你的 Elasticsearch index 定義一個默認的 pipeline:
PUT my_index
{
"settings": {
"default_pipeline": "my_pipeline"
}
}這樣當我們的資料匯入到 my_index 里去的時候,my_pipeline 將會被自動呼叫,
例子
Dissect
我們下面來看一個更為復雜一點的例子,你需要同時使用 split 及 kv processor 來結構化這個訊息:
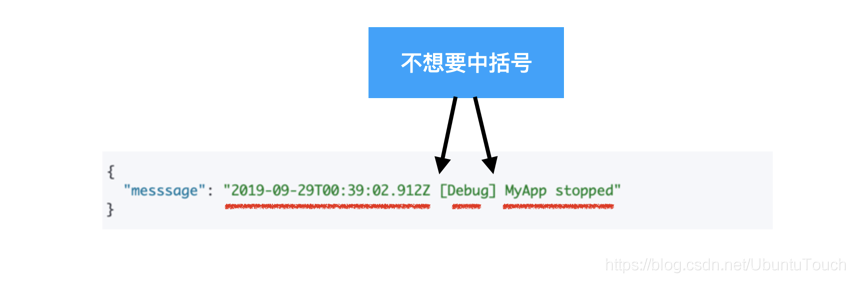
正如我們上面顯示的那樣,我們想提取上面用紅色標識的部分,但是我們并不需要資訊中中括號【 及 】,我可以使用 dissect processor:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "Example using dissect processor",
"processors": [
{
"dissect": {
"field": "message",
"pattern": "%{@timestamp} [%{loglevel}] %{status}"
}
}
]
},
"docs": [
{
"_source": {
"message": "2019-09-29T00:39:02.912Z [Debug] MyApp stopped"
}
}
]
}上面顯示的結果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"@timestamp" : "2019-09-29T00:39:02.912Z",
"loglevel" : "Debug",
"message" : "2019-09-29T00:39:02.912Z [Debug] MyApp stopped",
"status" : "MyApp stopped"
},
"_ingest" : {
"timestamp" : "2020-04-27T09:10:33.720665Z"
}
}
}
]
}我們接下來顯示一個 key-value 對的資訊:
{
"message": "2019009-29T00:39:02.912Z host=AppServer status=STATUS_OK"
}我們同樣可以使用 dissect processor 來處理:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description": "Example using dissect processor key-value",
"processors": [
{
"dissect": {
"field": "message",
"pattern": "%{@timestamp} %{*field1}=%{&field1} %{*field2}=%{&field2}"
}
}
]
},
"docs": [
{
"_source": {
"message": "2019009-29T00:39:02.912Z host=AppServer status=STATUS_OK"
}
}
]
}在上面,*及&是參考鍵修飾符,它們用來改變 dissect 的行為,上面的結果顯示:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"@timestamp" : "2019009-29T00:39:02.912Z",
"host" : "AppServer",
"message" : "2019009-29T00:39:02.912Z host=AppServer status=STATUS_OK",
"status" : "STATUS_OK"
},
"_ingest" : {
"timestamp" : "2020-04-27T14:04:38.639127Z"
}
}
}
]
}對于許多新的開發者來說,有時他們對 dissect 和 grok 的區別不是很理解,從表面上看,dissect 和 grok 有很多重疊的地方,但是 dissect 的執行速度遠遠高于 grok,所以在實際的使用中,盡量使用 dissect 來完成,但是在實際的使用中,有些情況下,我們還必須使用 grok 來完成,我們在一下的 grok 部分講到,
Script processor
盡管現有的很多的 processor 都能給我們帶來很大的方便,但是在實際的應用中,有很多的能夠并不在我們的 Logstash 或Elasticsearch預設的功能之列,一種辦法就是寫自己的插件,但是這可能是一件巨大的任務,我們可以寫一個腳本來完成這個作業,通常這個是由Elasticsearch的Painless腳本來完成的,如果你想了解更多的Painless的知識,你可以在 “Elastic:菜鳥上手指南” 找到幾篇這個語言的介紹文章,
有兩種方法可以允許Painless script:inline或者stored,
Inline scripts
在下面的例子中它展示的是一個inline的腳本,用來更新一個叫做new_field的欄位:
PUT /_ingest/pipeline/my_script_pipeline
{
"processors": [
{
"script": {
"source": "ctx['new_field'] = params.value",
"params": {
"value": "Hello world"
}
}
}
]
}在上面,我們使用 params 來把引數傳入,這樣做的好處是 source 的代碼一直是沒有變化的,這樣它只會被編譯一次,如果 source 的代碼隨著呼叫的不同而改變,那么它將會被每次編譯從而造成浪費,
Stored scripts
Scripts也可以保存于 Cluster 的狀態中,并且在以后參考 script 的 ID 來呼叫:
PUT _scripts/my_script
{
"script": {
"lang": "painless",
"source": "ctx['new_field'] = params.value"
}
}
PUT /_ingest/pipeline/my_script_pipeline
{
"processors": [
{
"script": {
"id": "my_script",
"params": {
"value": "Hello world!"
}
}
}
]
}上面的兩個命令將實作和之前一樣的功能,當我們在 ingest node 使用場景的時候,我們訪問檔案的欄位時,使用 cxt['new_field'],我們也可以訪問它的元欄位,比如 cxt['_id'] = ctx['my_field'],
我們先來做幾個練習:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"script": {
"lang": "painless",
"source": "ctx['new_value'] = ctx['current_value'] + 1"
}
}
]
},
"docs": [
{
"_source": {
"current_value": 2
}
}
]
}上面的腳本運行時會生產一個新的叫做 new_value 的欄位,并且它的值將會是由 curent_value 欄位的值加上1,運行上面的結果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"new_value" : 3,
"current_value" : 2
},
"_ingest" : {
"timestamp" : "2020-04-27T14:49:35.775395Z"
}
}
}
]
}我們接下來一個例子就是來創建一個 stored script:
PUT _scripts/my_script
{
"script": {
"lang": "painless",
"source": "ctx['new_value'] = ctx['current_value'] + params.value"
}
}
PUT /_ingest/pipeline/my_script_pipeline
{
"processors": [
{
"script": {
"id": "my_script",
"params": {
"value": 1
}
}
}
]
}上面的這個陳述句和之前的那個實作的是同一個功能,我們先執行上面的兩個命令,為了能測驗上面的 pipeline 是否作業,我們嘗試創建兩個檔案:
POST test_docs/_doc
{
"current_value": 34
}
POST test_docs/_doc
{
"current_value": 80
}然后,我們運行如下的命令:
POST test_docs/_update_by_query?pipeline=my_script_pipeline
{
"query": {
"range": {
"current_value": {
"gt": 30
}
}
}
}
在上面,我們通過使用 _update_by_query 結合 pipepline 一起來更新我們的檔案,我們只針對 current_value 大于30的檔案才起作用,運行完后:
{
"took" : 25,
"timed_out" : false,
"total" : 2,
"updated" : 2,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}它顯示已經更新兩個檔案了,我們使用如下的陳述句來進行查看:
GET test_docs/_search顯示的結果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test_docs",
"_type" : "_doc",
"_id" : "EIEnvHEBQHMgxFmxZyBq",
"_score" : 1.0,
"_source" : {
"new_value" : 35,
"current_value" : 34
}
},
{
"_index" : "test_docs",
"_type" : "_doc",
"_id" : "D4EnvHEBQHMgxFmxXyBp",
"_score" : 1.0,
"_source" : {
"new_value" : 81,
"current_value" : 80
}
}
]
}
}從上面我們可以看出來 new_value 欄位的值是 current_value 欄位的值加上1,
我們再接著看如下的例子:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"split": {
"field": "message",
"separator": " ",
"target_field": "split_message"
}
},
{
"set": {
"field": "environment",
"value": "prod"
}
},
{
"set": {
"field": "@timestamp",
"value": "{{split_message.0}}"
}
}
]
},
"docs": [
{
"_source": {
"message": "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK"
}
}
]
}在上面第一個 split processor,我們把 message 按照" "來進行拆分,并同時把結果賦予給欄位 split_message,它其實是一個陣列,接著我們通過 set processor添加一個叫做 environment 的欄位,并賦予值 prod,再接著我們把 split_message 陣列里的第一個值拿出來賦予給 @timestamp 欄位,這是一個添加的欄位,運行的結果如下:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"environment" : "prod",
"@timestamp" : "2019-09-29T00:39:02.912Z",
"message" : "2019-09-29T00:39:02.912Z AppServer1 STATUS_OK",
"split_message" : [
"2019-09-29T00:39:02.912Z",
"AppServer1",
"STATUS_OK"
]
},
"_ingest" : {
"timestamp" : "2020-04-27T15:35:00.922037Z"
}
}
}
]
}Grok processor
Grok processor 提供了一種正則匹配的方式讓我們把 pattern 和 message 進行匹配,從而提前出 message 里的結構化資料,相比較 Dissect 而言,Grok 的相率并不高,這是我們需要注意的,那么為什么我們還是需要使用 Grok呢?我們首先來看一下如下的一個例子:
157.97.192.70 2019 09 29 00:39:02.912 AppServer1 Process 11111 Init
157.97.192.70 2019 09 29 00:39:06.554 AppServer1 22222 Stopped 3.642在上面的兩個日志中,我們發現如果使用 Dissect processor,還是無能為力,這是因為 process id 在兩個不同的日志里出現的位置并不相同,但是我們可以使用 Grok 來完美地解決這個問題,
我們可以在 Kibana 中打入如下的命令來查詢現有的預設的 grok pattern:
GET /_ingest/processor/grok我們可以看到有超過 300 多個的預設的 grok patern 供我們使用:
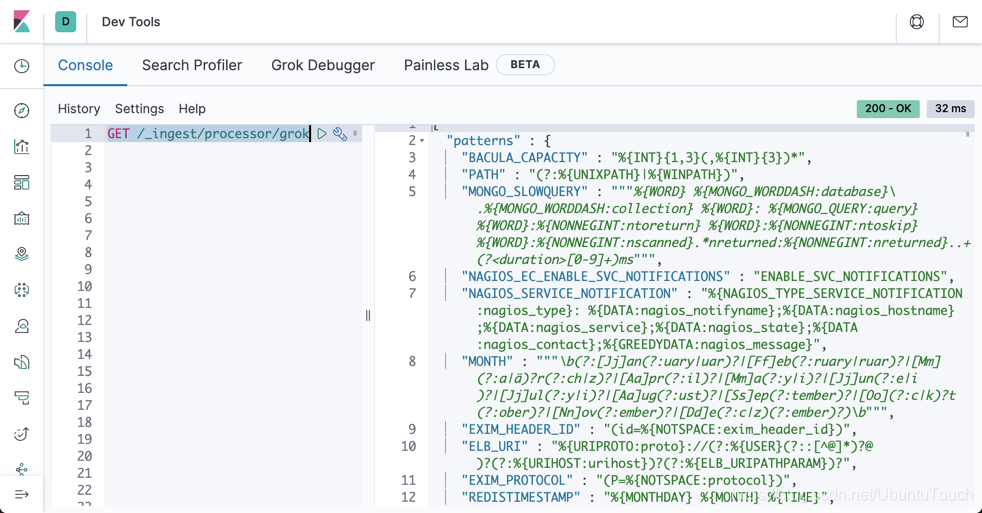
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{TIMESTAMP_ISO8601:@timestamp} %{IP:client} \\[%{WORD:status}\\] %{NUMBER:duration}"
]
}
}
]
},
"docs": [
{
"_source": {
"message": "2019-09-29T00:39:02.912Z 55.3.241.1 [OK] 0.043"
}
}
]
}上面的回傳結果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"duration" : "0.043",
"@timestamp" : "2019-09-29T00:39:02.912Z",
"client" : "55.3.241.1",
"message" : "2019-09-29T00:39:02.912Z 55.3.241.1 [OK] 0.043",
"status" : "OK"
},
"_ingest" : {
"timestamp" : "2020-04-28T00:16:52.155688Z"
}
}
}
]
}Grok processro 也對多行的事件也可以處理的很好,比如:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"grok": {
"field": "text",
"patterns": ["%{GREEDYMULTILINE:allMyData}"],
"pattern_definitions": {
"GREEDYMULTILINE": "(.|\n)*"
}
}
}
]
},
"docs": [
{
"_source": {
"text": "This is a text \n secondline"
}
}
]
}上面運行的結果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"text" : """This is a text
secondline""",
"allMyData" : """This is a text
secondline"""
},
"_ingest" : {
"timestamp" : "2020-04-28T00:31:38.913929Z"
}
}
}
]
}在上面我們可以看到 allMydata 把多行的資料都提前到同一個欄位,在上面如果我們只用其中的一種 pattern_definitions,比如 .*:
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"grok": {
"field": "text",
"patterns": ["%{GREEDYMULTILINE:allMyData}"],
"pattern_definitions": {
"GREEDYMULTILINE": ".*"
}
}
}
]
},
"docs": [
{
"_source": {
"text": "This is a text \n secondline"
}
}
]
}那么我們可以看到:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"text" : """This is a text
secondline""",
"allMyData" : "This is a text "
},
"_ingest" : {
"timestamp" : "2020-04-28T00:35:59.67759Z"
}
}
}
]
}也就是它只提前了第一行,
Date processor
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"date": {
"field": "date",
"formats": [
"MM/dd/yyyy HH:mm",
"dd-MM-yyyy HH:mm:ssz"
]
}
}
]
},
"docs": [
{
"_source": {
"date": "03/25/2019 03:39"
}
},
{
"_source": {
"date": "25-03-2019 03:39:00+01:00"
}
}
]
}在上面我們定義了兩種時間的格式,如果其中的一個有匹配,那么時間將會被正確地決議,同時被自動賦予給 @timestamp 欄位,這個和 Logstash 的 date processor 是一樣的,上面運行的結果是:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"date" : "03/25/2019 03:39",
"@timestamp" : "2019-03-25T03:39:00.000Z"
},
"_ingest" : {
"timestamp" : "2020-04-28T00:24:24.802381Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"date" : "25-03-2019 03:39:00+01:00",
"@timestamp" : "2019-03-25T02:39:00.000Z"
},
"_ingest" : {
"timestamp" : "2020-04-28T00:24:24.802396Z"
}
}
}
]
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233091.html
標籤:AI
上一篇:什么是聚集索引,非聚集索引,索引覆寫,回表,索引下推
下一篇:RBF神經網路理論與實作